本文主要是介绍cs231n作业Assignment1 knn,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
k-Nearest Neighbor (kNN) exercise
kNN分类器包含两个阶段:
1.训练阶段:
kNN分类器获取训练数据集,并进行存储
2.测试阶段:
kNN分类器将每个测试图像与所有训练图像进行比较,计算出两者之间的距离。找出k张距离最近的训练图像,在这k张距离最近的训练图像中,选择标签类别占多数的类别,作为测试图像的类别。
k值的交叉验证
通过交叉验证得到最优的k值
# Run some setup code for this notebook.import random
import numpy as np
from cs231n.data_utils import load_CIFAR10
import matplotlib.pyplot as plt#使matplotlib图形以内联方式显示在笔记本中而不是显示在新窗口中有点神奇。
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'#更神奇的是,笔记本将重新加载外部python模块;
#参见http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
%load_ext autoreload
%autoreload 2
# 下载原生数据 CIFAR-10 data.
cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'# 清除变量以防止多次加载数据(这可能导致内存问题)
try:del X_train, y_traindel X_test, y_testprint('Clear previously loaded data.')
except:passX_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)# 作为检查,我们打印出训练和测试数据的大小。
print('Training data shape: ', X_train.shape)
print('Training labels shape: ', y_train.shape)
print('Test data shape: ', X_test.shape)
print('Test labels shape: ', y_test.shape)
输出
Training data shape: (50000, 32, 32, 3)
Training labels shape: (50000,)
Test data shape: (10000, 32, 32, 3)
Test labels shape: (10000,)
通过训练数据和测试数据的大小可知:每张图片像素都是32 x 32 x 3,训练集有50000张,测试集有10000张。
# 展示数据集的一些例子
# 我们从每一类均展示几个例子
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
num_classes = len(classes)#一共10个类别
samples_per_class = 7#每个类别展示7个例子
for y, cls in enumerate(classes):#enumerate是python内置的一个枚举函数#y,cls=0,plane;y,cls=1,car.....y,cls=9,truckidxs = np.flatnonzero(y_train == y)#numpy.flatnonzero()该函数输入一个矩阵,返回矩阵中元素y的位置(index)#y_train的类型为np.ndarray#每一类所在的位置,例如plane所在位置分别为[29 30...49994]#另外一共50000个训练集,10个种类,每类有5000个。idxs = np.random.choice(idxs, samples_per_class, replace=False)#从得到的每一类idxs中随机抽取7个不重复的图片位置for i, idx in enumerate(idxs):#(i,idx)为(0,29341) ...(6,12493)(0,49401)...(6,30738)...#一共7*10类=70个值plt_idx = i * num_classes + y + 1#建立索引值:1,11,21,...61,2,12,22,...,62,3,......10,20,30,...70plt.subplot(samples_per_class, num_classes, plt_idx)#行数:从每一类中随机抽取的7个例子,列数:10个类别,索引值plt.imshow(X_train[idx].astype('uint8'))# 按unit8的类型显示x_train中下标为idx的元素plt.axis('off')#不显示坐标尺寸if i == 0:plt.title(cls)
plt.show()
输出:

为了更有效地执行代码,从训练集中选5000张作为训练实例,测试集中选500作为测试实例:
# 在本练习中,对数据进行子采样以提高代码执行效率
num_training = 5000#训练集是5000
mask = list(range(num_training))#[0,1,2,...,4999]的list
X_train = X_train[mask]#X_train[mask]是是(5000,3072)的np.ndarray
y_train = y_train[mask]num_test = 500#测试集是500
mask = list(range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]# 将图像数据进行张量变形,重塑为行
X_train = np.reshape(X_train, (X_train.shape[0], -1))#-1代表不知道要给列设置为几
X_test = np.reshape(X_test, (X_test.shape[0], -1))#reshape函数会根据原矩阵的形状自动调整。
print(X_train.shape, X_test.shape)
输出:
以X_train.shape为例:第一维大小为X_train.shape[0]即变为5000 而第二维为-1表示列不知道多少,所以根据剩下纬度进行计算,即32x32x3=3027。所以最终形状为(5000,3272)。
(5000, 3072) (500, 3072)
from cs231n.classifiers import KNearestNeighbor# 创建一个knn分类器实例
# 注意训练knn分类器是一个空操作
# 分类器只对训练数据进行存储,不做进一步处理。
classifier = KNearestNeighbor()
classifier.train(X_train, y_train)
测试阶段
现在我们用kNN分类器对测试数据进行分类。
回想一下,我们可以把这个过程分为两个步骤:
1.首先,我们必须计算所有测试示例和所有训练示例之间的距离。
2.在给定这些距离中,对于每个测试示例,我们找到与其距离最近的k个的训练示例,并标注它们的类别。
让我们从计算所有训练和测试示例之间的距离矩阵开始。例如,如果有 N_train训练示例和 N_test测试示例,这个阶段应该生成一个 N_test x N_train矩阵,其中每个元素 [i, j] 表示第i个测试样本到第j个训练样本之间的距离。
距离度量:采用欧式距离
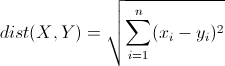
首先,打开cs231n/classifier /k_nearest_neighbor.py并实现compute_distances_two_loops函数,该函数对所有(测试、训练)示例使用一个(非常低效的)双循环,并一次计算一个测试样本到所有训练样本的距离矩阵。
def compute_distances_two_loops(self, X):"""利用一个嵌套循环,计算X中的每一个测试点和self.X_train中的每一个训练点之间的距离。输入:- X: 包含测试数据的shape为(num_test,D)的一个numpy array。返回:- dists: 一个shape为(num_test, num_train) 的numpy array,其中dists[i, j]表示ith测试点和jth训练点之间的Euclidean距离."""num_test = X.shape[0]num_train = self.X_train.shape[0]dists = np.zeros((num_test, num_train))for i in range(num_test):for j in range(num_train):###################################################################### TODO: ## 计算ith测试点和jth训练点的l2距离,然后存储在dists[i, j]。 ## 不能使用一个对维数的循环,也不能使用np.linalg.norm() ####################################################################### *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****dists[i,j]=np.sqrt(np.sum(np.square(X[i]-self.X_train[j])))# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return distsdists[i,j]:测试样本i到训练样本j的欧氏距离
np.square( X[i] - self.X_train[j] ):第i个测试样本 - 第j个训练样本后所得到的矩阵,再对矩阵中每个元素进行平方。(每一行所有元素代表该样本的特征,下标i表示第i个样本,X[i]即所在矩阵的行即第i个样本的所有特征)。 eg:[1, 2] - [2, 3] = [-1, -1],再进行平方(square)得:[1, 1]
np.sum( np.square( X[i] - self.X_train[j] ) ):由于axis=none,对输入数组的所有元素全部加起来。eg:np.sum([1, 1]) = 2
np.sqrt( np.sum( np.square( X[i] - self.X_train[j] ) ) ):对得到的张量进行开平方根。eg:np.sqrt(np.sum([1, 1])) = 1.4142135623730951
dists[i,j] = np.sqrt( np.sum(np.square(X[i] - self.X_train[j])) ):即为测试样本i到训练样本j的欧氏距离公式。
得到一个(500, 5000)的dists矩阵。
# 打开cs231n/classifiers/k_nearest_neighbor.py 并实现compute_distances_two_loops# 测试你实现的compute_distances_two_loops函数
dists = classifier.compute_distances_two_loops(X_test)
print(dists.shape)
# 我们可视化这个距离矩阵: 每一行是一个单独的测试样本和
#它到所有训练样本的距离。plt.imshow(dists, interpolation='none')
plt.show()#纵坐标表示500张测试图片,横坐标表示5000张训练图片。越黑表示距离越接近,越亮表示距离越远。

请注意距离矩阵中的结构,可以看出其中某些行或列更亮。(请注意,使用默认颜色方案时,黑色表示低距离,而白色表示高距离。)
是什么导致了这些行或列可以区分亮度?
你的答案是:predict_labels函数。
def predict_labels(self, dists, k=1):"""给定一个所有测试点的所有训练点之间距离的矩阵预测每个测试点的分类标签输入:- dists: 一个shape为(num_test, num_train) 的numpy array,其中dists[i, j]表示ith测试点和jth训练点之间的Euclidean距离.返回:- y: 一个shape为 (num_test,)的numpy array包含测试集的预测标签,其中y[i]表示测试点X[i]的预测标签。"""num_test = dists.shape[0]y_pred = np.zeros(num_test)for i in range(num_test):# 一个长度为k的列表,用于存储距离ith测试集的k个最近邻域closest_y = []########################################################################## TODO: ## 利用距离ith测试集的k个最近邻域, ##并根据self.y_train找到这k个近邻对应的标签 ## 将这些标签存储到closest_y ## 提示: 利用函数numpy.argsort. ########################################################################### *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****closest_y=self.y_train[np.argsort(dists[i,:])[:k]]# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****########################################################################## TODO: ## Now that you have found the labels of the k nearest neighbors, you ## need to find the most common label in the list closest_y of labels. ## Store this label in y_pred[i]. Break ties by choosing the smaller ## label. ########################################################################### *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****y_pred[i]=np.argmax(np.bincount(closest_y))# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return y_prednumpy.argsort()函数是将()中的元素从小到大排列,提取其对应的index(索引),然后输出。此处的索引值即为从小到大距离最近的训练样本。
例如:
第一行最小值1index为1,其次是2index为2,最后是3index为0。
第二行最小值6index为0,其次是7index为2,最后是8index为1。
import numpy as np dists=np.array([[3,1,2],[6,8,7]])
print(dists)
for i in range(2):closest_y = np.argsort(dists[i,:])print(closest_y)
输出:
[[3 1 2][6 8 7]]
[1 2 0]
[0 2 1]
np.argsort(dists[i]):返回的是测试样本距离所有训练样本从小到大的索引值(即第几类训练样本,例如3,…)。
np.argsort(dists[i])[:k]:表示取前k个,即k个最近邻的训练样本
根据self.y_train找到这k个近邻对应的标签即self.y_train[point](例如self_train[3]就是第3类bird),将这些标签存储到closest_y。
第二部分:已找到k个最近领对应的类别标签,找到其中出现最多的那个类别标签。
y_pred[i]=np.argmax(np.bincount(closest_y))np.bincount(closest_y):对cloest_y中前k个向量进行计数。
例如:
假如cloest_y向量中排名前五的数字分别为[1,1,1,3,2],那么np.bincount()将会返回索引在该数组内出现的次数:array([0, 3, 1, 1])因为[1,1,1,3,2]中最大数字为3,故bincount()结果有4个数字,索引值为0~3,数组表示0出现0次,1出现3次,2出现1次,3出现1次。这时候取最大值下标np.argmax(),正好得到索引值1,就是我们希望的结果。
np.argmax(np.bincount(closest_y)):返回最大值的下标index,即得到closest_y中出现次数最多的那个元素。(且如果有元素出现次数最多有相同的情况,则选择编号较小的那个元素)。
最后保存在y_pred[i]中,表示测试样本X[i]的预测类别(即预测结果)。
# 请实现函数predict_labels并执行以下代码:
# 我们令k = 1 (也就是最近邻).
y_test_pred = classifier.predict_labels(dists, k=1)# 计算预测正确的样本的比例
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
输出:
Got 137 / 500 correct => accuracy: 0.274000
Now lets try out a larger k, say k = 5:
y_test_pred = classifier.predict_labels(dists, k=5)
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
Got 139 / 500 correct => accuracy: 0.278000
You should expect to see a slightly better performance than with k = 1.
这篇关于cs231n作业Assignment1 knn的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







