本文主要是介绍基于生成对抗性网络的单图像超分辨率技术综述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:A review on Single Image Super Resolution techniques using generative adversarial network
单图像超分辨率(SISR)是一种从低分辨率(LR)图像中获得高像素密度和精细细节,以获得升级和更清晰的高分辨率(HR)图像的过程。在过去的十年中,基于卷积神经网络(CNN)的SISR在生成×3大小的超分辨率图像方面取得了令人印象深刻的成果。该技术的重点是最小化真实HR图像和生成HR图像之间的𝐿1∕𝐿2损失,而不考虑图像的感知质量。为了改进,基于生成对抗网络(GAN)的SISR以合理地减少×4尺寸图像的𝐿1∕𝐿2损失来生成视觉上令人愉悦的图像,引起了研究人员的注意。GAN的基本思想是同时训练两个网络,一个生成器和一个判别器,这样生成器可以通过学习真实的HR图像分布来生成给定输入LR图像的超分辨图像。本文概述了基于GAN的SISR技术的进一步研究,因为在该领域有一些调查。不同的GAN模型在架构、算法和损失函数方面进行了分类,包括它们的优点和局限性。最后,讨论了研究的空白以及现有方法的可能解决方案。
Introduction
一、抛出问题后,提出三个GAN对于CNN的优点,论证研究界更倾向于采用GAN方法在SISR领域取得更好的性能。
1.以卷积神经网络(CNN)为主的基于深度学习的方法取得了巨大成功,但由于可以从同一LR图像中估计出多个HR图像,因此SISR仍然是一个具有挑战性的病态问题(不适定性问题)。
2.CNN网络的性能在生成大于x3大小的图像时会下降,而在基于GAN网络的SISR技术中引入对抗性损失已经实现了可信的感知质量,即使对于生成x4大小的输出HR图像也是如此。
3.可以利用基于GAN的SISR技术对自然图像的高维多模态分布进行了建模,并获得满意的感知质量。
4.基于GAN的SISR算法在很大程度上实现了LR图像的真实退化去除,包括各向同性和各向异性高斯核,而基于CNN的网络只能去除各向同性高斯核。
二、简要介绍了GAN网络
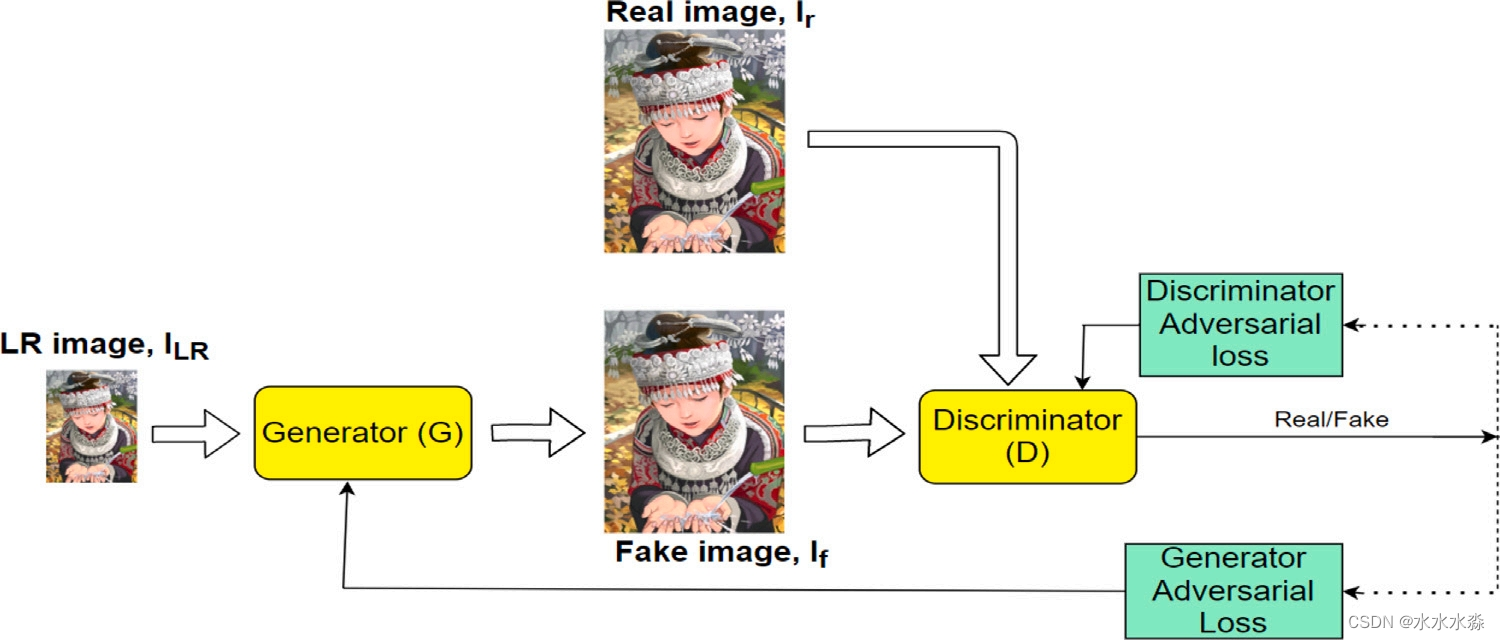
生成对抗网络(Generative Adversarial Network, GAN)[13]是一种基于深度神经网络的无监督生成算法,它将对抗损失与感知损失结合在一起,产生接近自然图像流形的超分辨输出。GAN由两个无监督神经网络组成,即生成器和鉴别器,两个网络通过极大极小优化相互竞争,目标是达到一个均衡状态,称为纳什均衡,最终导致两个网络都加强,从而产生逼真的HR图像。GAN网络的性能在很大程度上取决于超参数,包括网络的设计、训练目标的选择、正则化和训练算法。
SISR framework and fundamentals of GAN
SISR framework
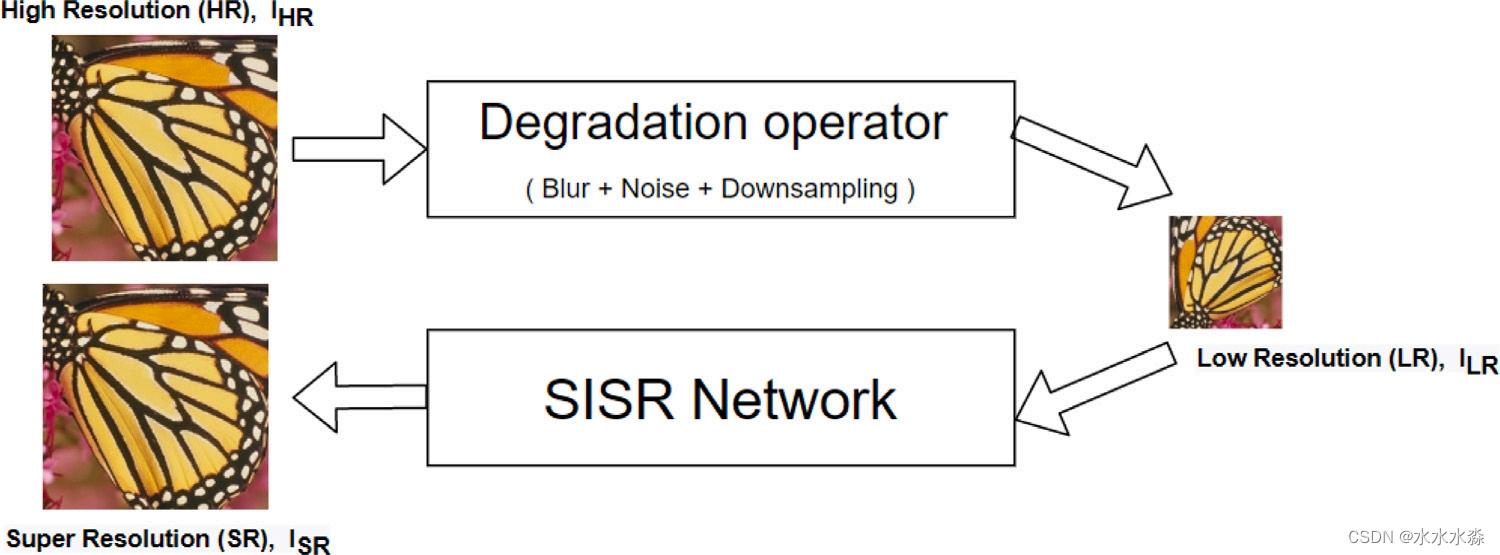
SISR可以分为传统方法和基于学习的方法。传统的方法包括基于插值的超分辨率和基于重建的超分辨率。
基于插值的方法通过使用插值核或基函数来估计高分辨率网格中的未知像素。基于重建的方法采用基于模型的方法,包括统计计算和不同类型的先验来构建HR图像。这些技术不能产生高光谱信息,并且随着输出图像比例因子的增加,性能也不理想。
基于学习的方法成功地生成了高频细节和令人信服的HR图像,在SISR领域取得了长足的进步。基于学习的方法的动机是确定要生成的图像的底层结构,并估计LR图像与相应的HR图像之间的关系。一些值得注意的基于学习的方法包括邻域嵌入方法、稀疏编码方法、随机森林方法、回归方法等。
GAN
GAN是最新的无监督生成建模技术之一,与以前的模型相比具有以下优点:
(i) GAN使用潜在代码,并且可以并行生成样本,这比完全可见信念网络(Fully Visible Belief Networks)有优势。
(ii) GAN是渐近一致的,这是优于变分自编码器(Variational Autoencoder,VAE)的一个优点。
(iii) GAN不需要在高维空间中表现不佳的马尔可夫链,这是优于玻尔兹曼机的优势。
(iv)尽管像PixelCNN这样的模型也产生了类似的结果,但大都认为GAN产生了最好的样本。
(v) GAN不需要任何近似,可以通过可微网络端到端进行训练,而其他生成模型由于近似方法而面临难以处理的函数问题。
GAN的基本框图
尽管GAN已经取得了显著的成果,但仍存在一些具有挑战性的问题,如:
1.模式崩溃和模式下降:在模式崩溃中,生成器被困到某个局部最小值,它只捕获分布的一小部分。当发生器产生几乎没有变化的均匀样品时,就会发生模态坍缩。在模式丢弃中,生成器没有忠实地对目标分布建模,并且丢失了目标分布的某些部分。Wasserstein GAN (W-GAN)和unrolled GAN解决了这些问题。知识蒸馏(Knowledge Distillation, KD)方案也通过在训练阶段改善生成器和鉴别器的平衡来帮助减少这一问题。
2. 梯度消失:梯度消失阻止生成器学习任何东西,因为鉴别器变得太成功了。Qi[1]也提出了梯度不消失的Loss-Sensitive GAN。在[2]中,提出了对极大极小损失的修正来缓解消失梯度。
3.收敛/不稳定训练:GAN网络在训练过程中可能无法收敛。Salimans等[3]提出了一种称为特征匹配的技术来获得更好的收敛性。其思想是通过最小化鉴别器中间层上的均方误差,使生成的样本与真实数据的统计量相匹配。在[4]中,通过在鉴别器输入中加入噪声给出了一个解决方案。在[5,6]中使用正则化进一步讨论了这个问题。为了在GAN模型中实现更快、更稳定的训练和更好的泛化精度,提出了不同的归一化技术,如梯度惩罚(WGAN-GP)、谱归一化、批归一化等。虽然这些技术改善了不稳定训练,但也导致了性能下降[\]。为了缓解这一问题,梯度归一化[7]被建议通过增加鉴别器对鉴别器函数施加梯度范数约束的能力来解决训练不稳定性。最近,自适应偏差调制器[\]与归一化相结合,放大像素值的标准差,使边缘信息无法区分,从而大大提高了性能。
Classification
基于GAN的SISR技术根据操作域、输出HR图像数量和网络运行时间等不同因素进行分类。图4显示了现有的基于GAN的SISR技术的上层分类。
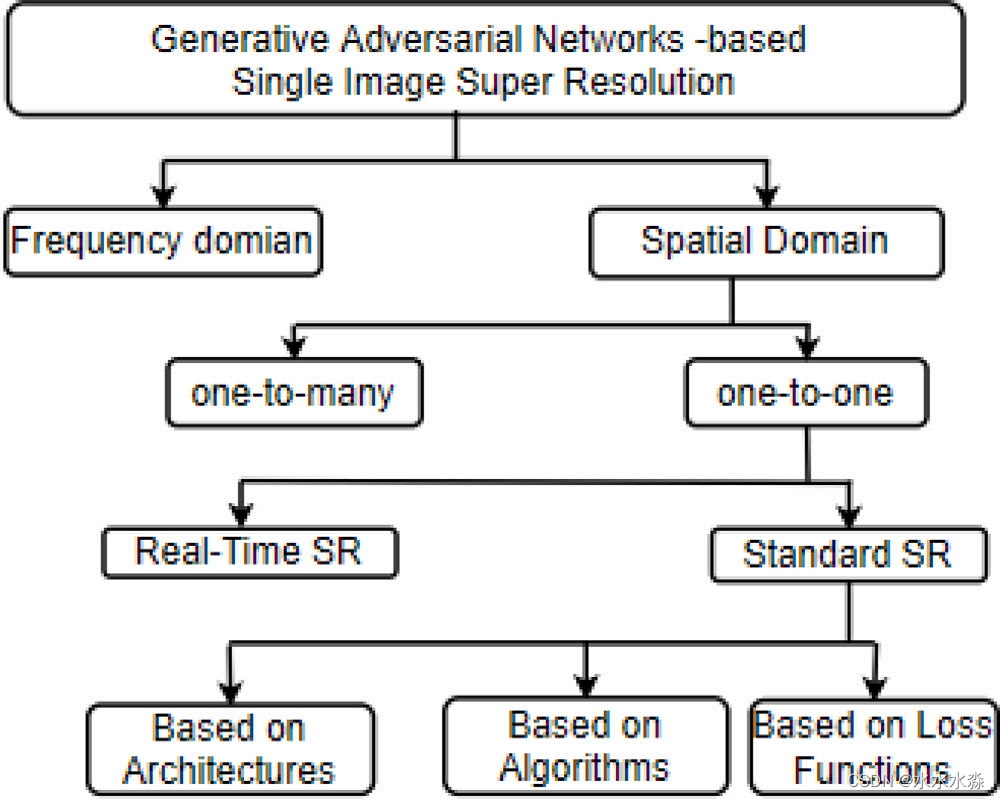
图4 基于GAN的SISR分类
根据操作域的不同,可以将不同的技术分为频域和空间域。第一类网络包括退化建模和频域重构。在[9]中,使用二维离散余弦变换(DCT)技术在频域实现HR图像的退化。Fritsche等[10]提出分别使用简单的线性低通和高通滤波器分离和处理低频和高频细节。低频成分,如颜色和内容,通过逐像素的颜色损失来保留。高频分量的学习使用对抗损失来匹配原始图像。此外,我们还尝试了一种频率能量相似度损失函数[11],得到了更好的结果,使图像的边缘更清晰、更细致、更自然。频域网络收敛更快,更稳定,并具有实时应用。但是这些网络存在一些局限性,如退化建模不灵活、数学公式复杂等,限制了它们的应用。因此,研究人员对空间域技术更感兴趣。
在空间域中,通过修改像元值在像平面上进行退化建模、退化估计和重建过程。根据生成的图像数量,基于GAN的SISR技术可以分为一对多SR和一对一SR。
一对多SR方法,即从单个LR图像生成各种可信的HR图像,是由Bahat和Michaeli[12]提出的。该方法利用图形用户界面(GUI)和神经网络后端,通过操纵现有SR网络的输入控制信号来探索HR空间。虽然它减少了重建误差,在图形、医学、监控等应用中很有用,但它需要手动操作纹理的方差和周期性来生成不同的HR图像。在[13]中,利用训练过程中高分辨率图像中可用的语义图结构信息,以无监督的方式在图像梯度流形上生成各种HR图像。在[14]中考虑的网络输入LR图像和噪声向量,利用图像的高频信息生成可信的HR图像。各种生成的HR图像通过施加一个约束,即下采样后的HR图像与原始输入的LR图像之间的像素差不能超过一个超参数的值。Park和Lee[15]建议在生成器网络的每个残差稠密块(RRDB)层之后添加按比例的逐像素噪声,从随机分布映射输出分布,生成多幅逼真的超分辨图像。每个通道自适应地学习噪声的大小,因为噪声与通道相关的缩放因子相乘,然后添加到每个RRDB层的输出中。受StyleGAN[16]的启发,由于重构图像的随机变化,在每一层输出中加入自适应高斯噪声,会产生不同的超分辨图像。PULSE[17]中引入了一种无监督方法,将生成模型的潜在空间遍历到真实的多个HR图像中。一对多SR网络是新颖的,它们中的大多数只能处理双三次下采样图像,可能不能很好地处理其他类型的退化,而且很耗时。
一对一SR方法,即从单个LR图像生成单个HR图像,由于其易于实现,耗时少,复杂性低等优点而受到广泛研究。根据运行时间的不同,一对一的SR方法可以进一步分为实时SR和标准SR。从当今世界的场景和深度网络的发展来看,需要实时和高端的计算解决方案来执行复杂的网络计算。考虑到这些需求,Krishnan和Krishnan提出了具有实时推理和低内存占用的SwiftSRGAN[18]。它在机器人、移动应用、医疗成像、云游戏、流媒体等许多领域都有重要的应用。
Standard SR classification
以下是对改进SISR网络的一些思考以及动机。
1. 不同的基本构建块以及块之间和块内层之间的不同连接可以提高网络的性能。分块提取不同层次的图像信息,这些信息可以融合得到图像细节。SRGAN中的Ledig[19]推测ResNet设计在深度网络中获得了更好的性能,但面临更长的训练和测试时间。更复杂或更简单的构建块(具有不同的深度,层数,拓扑结构和跳过连接)是否可以通过简单稳定的训练获得更好的结果?如果是,那么如何设计这样的模型?
2. SR技术需要低分辨率和高分辨率图像对来训练网络,并使用不同的复杂退化和下采样函数。然而,这样的图像对在实际应用中是不可用的。通过降采样(主要是双三次)得到的LR图像,假设可用的HR图像是无噪声的。这些假设阻碍了网络的实际应用。在没有相应的HR图像可用性的情况下,是否可以设计出在现实场景中工作的有效退化模型来超分辨率噪声和模糊图像?是否可以将SISR的任何特性集成到SRGAN或基于gan的SISR算法的其他部分的设计中,例如添加先验知识,特征提取和融合,以缓解其他SISR问题,如大规模因子SISR生成,对真实图像的鲁棒性方法,多尺度特征提取等?
3.在SRGAN中,将内容损失与基于特征空间的新型对抗损失函数相结合,大大提高了超分辨率任务。是否存在基于其他属性的其他损失函数,可以进一步改进任务?是否存在不同损失函数的其他组合,使最终结果保留更多的图像细节?
基于GAN-SISR体系结构的分类
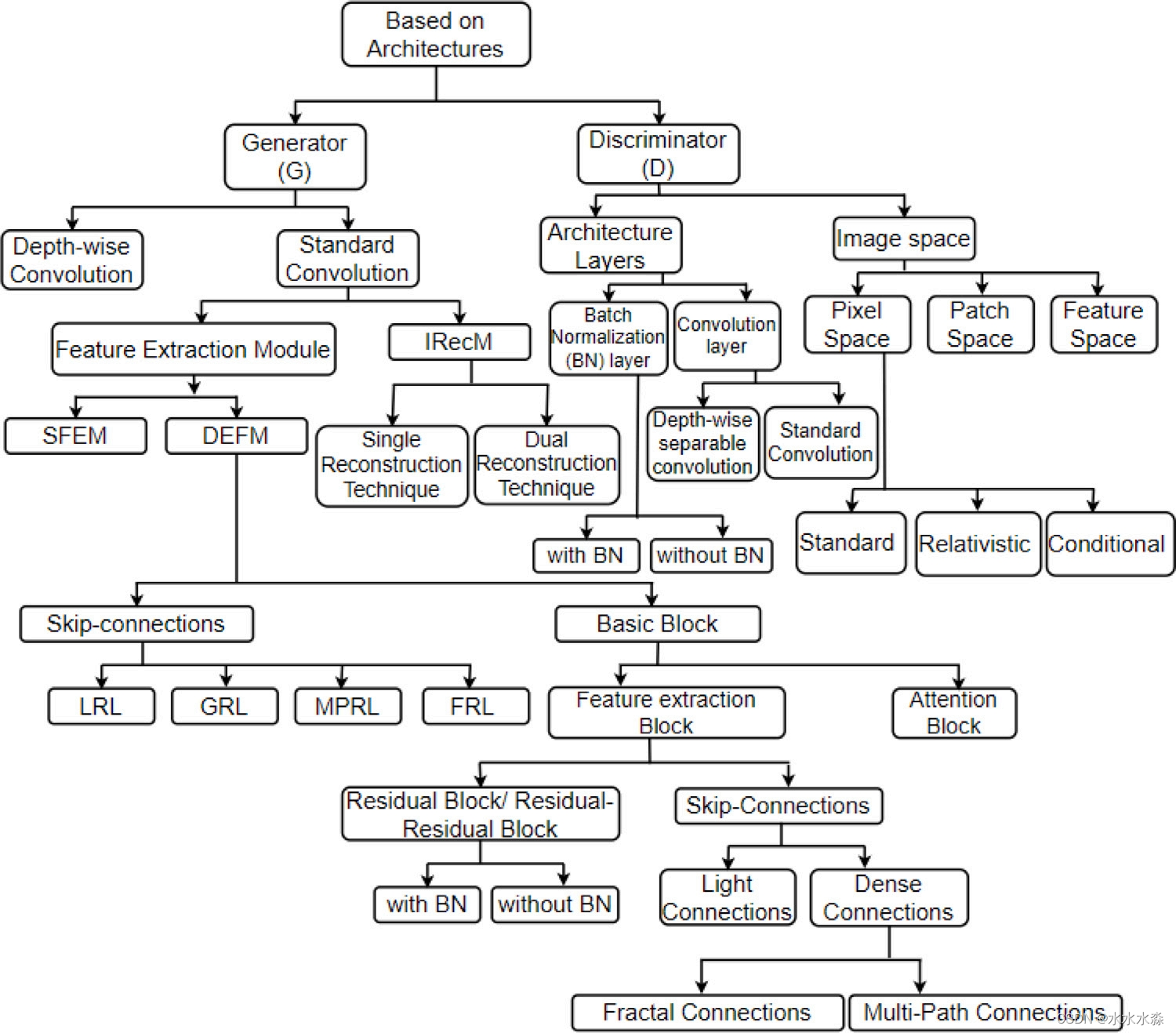
图5 基于GAN-SISR体系结构的分类
Generator——生成网络部分
任何深度网络的基本操作都是它所执行的卷积。考虑到所涉及的计算量,不同的网络主要涉及两种类型的卷积,即深度可分离卷积和标准卷积。
深度可分卷积由涉及两个步骤。在第一步中,它执行独立于通道相互作用的空间卷积,称为深度卷积,并对每个通道分别应用滤波器。然后,对没有空间相互作用的通道相互作用进行建模,称为点向卷积,其中1 × 1卷积将输出投影为深度卷积输出的线性组合,如图6a所示。它通过减少网络中涉及的参数和数学运算的数量,提高了网络表示和提取图像特征的能力,降低了算法的复杂度。虽然它具有更高的网络效率,但会牺牲网络的性能。标准卷积一次完成深度卷积和点卷积,如图6b所示。虽然这种卷积有更大的计算需求,但由于它给出了重要的结果而被广泛研究。
采用标准卷积,GAN的生成器网络可以进一步分类。根据要实现的功能,生成器网络分为两个模块:特征提取模块和图像重建模块。特征提取模块用于识别和提取图像的边缘、形状、纹理等特征。图像重构模块利用特征提取模块获得的特征对输出的HR图像进行重构。考虑到提取的特征类型,特征提取模块分为两种类型。一种是浅特征提取模块(Shallow Feature Extraction Module, SFEM),另一种是深特征提取模块(Deep Feature Extraction Module, DFEM)。SFEM提取边缘、轮廓等底层特征,主要由级联的一层或两层卷积构成。DFEM提取纹理、形状等高级特征,主要由跳跃连接和基本块组成。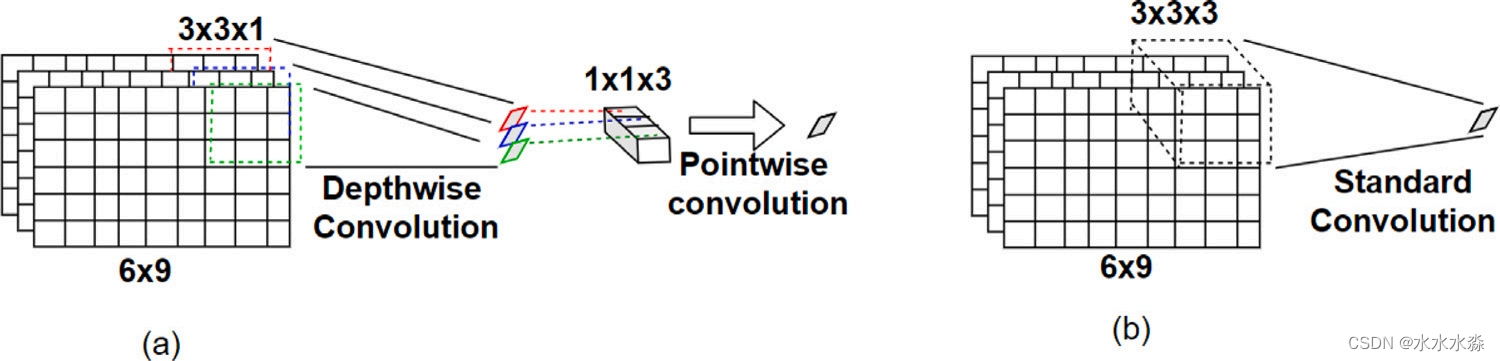
图6 (a)深度可分离卷积(b)标准卷积
在ResNet中首次引入的Skip-connections用于加速神经网络层间的信息传播。这些连接在深度网络的训练中是有效的,因为梯度信息的反向传播变得更容易和更快,从而缓解了梯度消失和梯度爆炸的问题。跳过连接作为身份映射函数来保留前一层的信息,并使网络学习残差信息。多个远距离跳跃连接聚合来自不同残差块的中间特征,以改善最终图像特征。
根据其模式,可将跳跃连接分为局部剩余连接(LRC)、全局剩余连接(GRC)、多路径剩余连接(MPRC)和分形剩余连接(FRC)。这些连接中的每一个都对应于一种特定类型的特征学习,因此分别负责局部残差学习(LRL)、全局残差学习(GRL)、多路径残差学习(MPRL)和分形残差学习(FRL)。这些连接如图7所示。
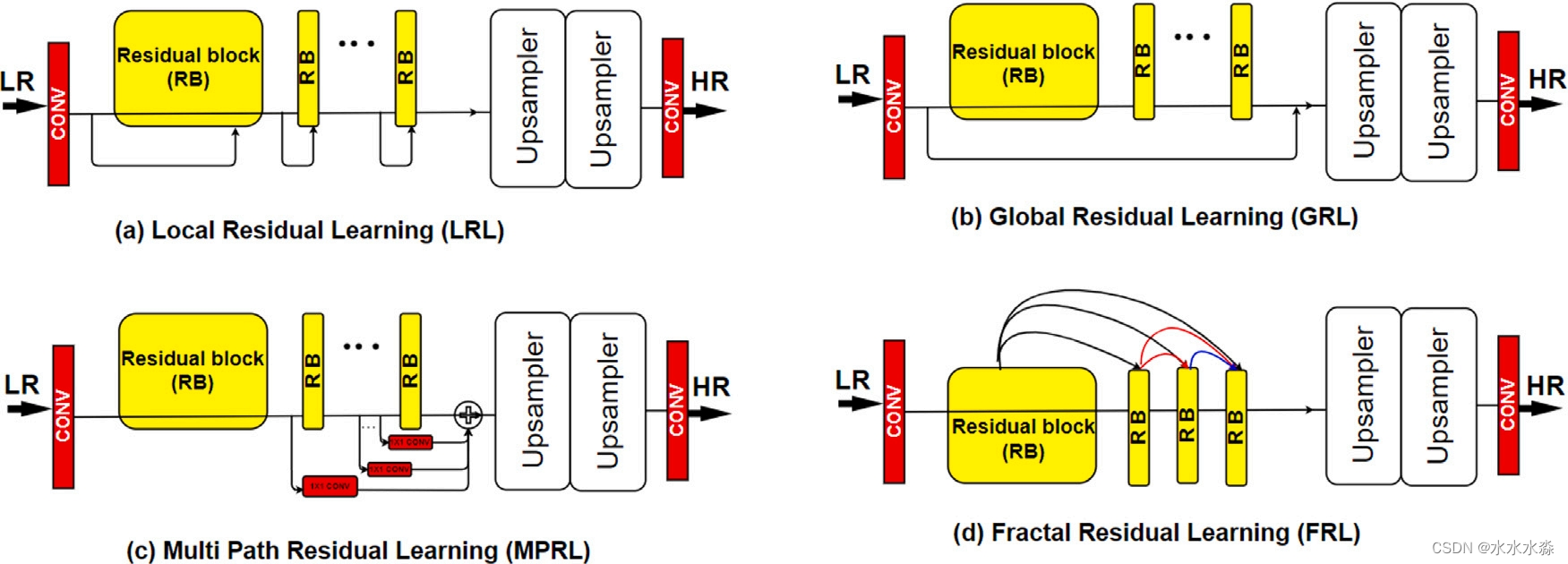
图7 不同类型的跳跃连接
在网络中使用基本块从图像中提取不同层次的信息。根据需要提取的信息,基本块可以分为两种类型,即特征提取块和注意块。特征提取块通常被级联以形成深度网络。各种特征提取块及其改进变体如图8所示。每个特征提取块主要由残差块/残差块中的残差块和跳跃连接组成。
残差块(RB)是不同层的组合,如卷积层、批处理归一化(BN)层等,每层执行特定的任务。可进一步分为带BN的残差块和不带BN的残差块。SRGAN网络[19]中的残差块中含有BN层,如图8(a)所示,以提高网络的性能和学习能力。在SRFeat[20]中,如图8(b)所示,将具有BN层的16个残差块应用于LR空间维度,以提取深度特征,从而实现高效的训练过程、内存使用和快速推理。但由于训练和测试数据集的均值和方差的合理差异,这一层可能会产生一些令人不快的伪影。这限制了网络的泛化能力。因此,大多数网络为了训练稳定,减少高频成分损失,更自然的纹理和一致的性能而去除BN层。SRCGAN[21]架构在残差块中去除了BN层,如图8(c)所示,在每个残差块中加入残差缩放层作为最后一层,缩小特征映射,有助于稳定训练过程。
具有更多层数和连接的深层网络在SISR中表现出了良好的性能,尽管它们在网络训练中需要更多的资源、计算和技巧。Wang等[22]基于SRResNet的基本架构,在SRGAN中引入了比原始残差块更深层、更复杂的结构(Enhanced-SRGAN)。它采用残差密集块(residual -in- residual Dense Block, RRDB)作为基本构建块,具有密集连接和多级残差网络,如图8(d)所示。RRDB提高了原始纹理的恢复能力和语义信息的表达能力,减少了输出图像中不需要的伪影。此外,它还减轻了SRGAN中存在的模态崩溃和梯度消失问题。Chen等[23]提出了一种名为Cascading Residual - Residual Block (CRRB)的特征提取模块,如图8(e)所示,该模块由1个CIB(Cascading Inception Block)和4个CRB(Cascading Residual Block)组成。CIB采用不同尺度的卷积核提取多尺度信息。CRB将低级信息提取为高级信息。Prajapati等人[24]提出了一种采用新型基本块生成SR图像的模型DUS - GAN,如图8(f)所示,该模型提取并学习了LR输入图像的丰富特征。
通过将密集块的输入连接到相应块的输出,可以在残差块中建立残差连接。特征提取块中的跳跃连接可以分为轻连接和密集连接。如图8(c)所示,光连接有助于梯度信息的轻松流动,并有效地从LR图像中提取分层特征表示。根据连接模式,密集连接可进一步分为分形连接和多径连接。分形连接如图8(g)所示,多径连接如图8(h)所示。这些连接提高了网络的学习和训练速度。注意块通常用于在处理数据以保留特定信息时关注某些因素。如图8(e)所示,Chen等人[23]提出了一种通道注意块,从LR图像中提取关键特征,并将其融合到下一阶段特征中,以较少的参数获得合理的性能。

图8 基于GAN的不同SISR网络架构
图像重建模块将SFEM和DFEM得到的最终特征图上采样到更高的分辨率。单重构技术(Single Reconstruction Technique )和双重构技术(Dual Reconstruction Technique)是实现最终图像重构的两种方法。SISR网络中的单重构技术主要由亚像素卷积层和卷积层组成,如图8(f)所示,这有助于特征学习。一些网络[186]还涉及特征映射的维度缩放,这是通过9 × 9滤波器和tanh激活函数来实现的,以产生RGB三通道图像。由于可以通过学习图像高频成分的残差来提高图像分辨率,DRSR[189]如图8(g)所示,将来自基网络的特征映射同时通过两个不同的上采样器,即双三次插值函数和亚像素卷积运算,得到两个不同的超分辨率特征映射。利用两个上采样点的优势,将两个超分辨特征图连接起来,得到最终的定量和定性的更好的超分辨图像。这种通过两个不同的上采样器获得最终HR图像的方法被称为双重构技术。
Discriminator——辨别网络部分
GAN的另一个网络是辨别网络,如图9所示。它既可以根据其结构中存在的不同层进行分类,也可以根据图像的特征来确定输入图像的真实感。鉴别器的结构主要包括批处理归一化层和卷积层两层。

图9 为每个卷积层提供具有核大小(k)、特征映射数(n)和步幅(s)的鉴别器网络
有使用BN层的辨别网络,以提高网络的学习能力和改进训练过程,而一些网络不使用BN层,因为它们会在输出图像中产生伪影。接下来,主要使用两种类型的卷积层,即深度可分离卷积层和标准卷积层。具有深度可分离卷积的鉴别器[168]主要用于MobileNet架构,以确保在实时应用中以更少的内存需求实现更快的操作。标准卷积判别器由于考虑图像像素间的空间关系,被广泛用于提取图像的有用特征。为了确定输入图像为真实图像的概率,比较了输入图像和参考图像的不同图像空间。根据检测的图像空间类型,鉴别器可分为:像素空间鉴别器、补丁空间鉴别器和特征空间鉴别器。考虑像素空间的鉴别器可分为标准鉴别器、相对论鉴别器和条件鉴别器。标准鉴别器被训练来区分真实或虚假的图像,使用由生成的图像和真实图像之间的感知相似性引起的内容损失。它估计输入图像为真实的概率。该鉴别器由于存在梯度消失问题,不能进行最优训练。尽管LSGAN[25]和WGAN[26]方法在寻找更好的损失函数以提高网络稳定性方面取得了成功,但计算成本较高。相对论GAN使得网络更加稳定,生成的图像质量更好,输出图像的边缘更清晰,纹理更细致。相对论判别器(RD)估计给定真实数据比假数据更真实的概率,相对论平均判别器(RaD)估计给定真实数据比所有假数据的平均值更真实的概率。除了增加生成的数据是真实的概率外,RaD还降低了真实数据是真实的概率。
RealSR[27]实现的Patch discriminator具有固定接受野的全卷积结构。它考虑了局部特征的局部补丁损失,最终损失是所有局部补丁损失的平均值,保证了全局特征的一致性。与MFAGAN一样,由于涉及的参数较少,使得训练更加快速和稳定。这些鉴别器会产生不存在于原始图像中的无意义高频噪声。利用特征空间鉴别器在特征域对合成图像和真实图像进行区分,解决了这一问题。Park等[28]提出了feature discriminator network来去除SR图像中不需要的高频噪声,并根据图像的结构性高频特征来区分图像的真假。在此鉴别网络的帮助下,训练生成器生成有意义的高频图像细节,而不是不必要的噪声。
有些网络采用不同的方法与鉴别器网络相结合,以获得理想的结果。在CRB[29]中,在判别器损失中加入了一个梯度惩罚项,以获得更快、更稳定的网络训练。在AMPRN[30]中,为了保留高频细节,开发了对抗梯度网络,该网络包含两个梯度层和一个基于vgg的鉴别器。梯度层的目的是使原始真实图像的梯度分布(纹理细节)与估计的假图像等效。它使生成的SR图像既准确又逼真,分别使用像素级内容损失和梯度损失。文献[31]将两个分别处理图像空间和高频细节的鉴别器与质量评估(Quality Assessment, QA)网络相结合以改善结果。QA网络根据人类感知(MOS)对生成的图像进行估计并给出质量分数,并进一步使用该分数对图像进行改进。该方法能够更有效、更稳健地消除LR图像噪声。
基于GAN-SISR算法的分类
基于GAN的SISR网络可以根据不同的算法进行分类,以获得改进的结果,如图10所示。根据网络中对输出图像进行改进的部分,算法可以分为退化处理算法、特征提取算法和基于先验的算法。
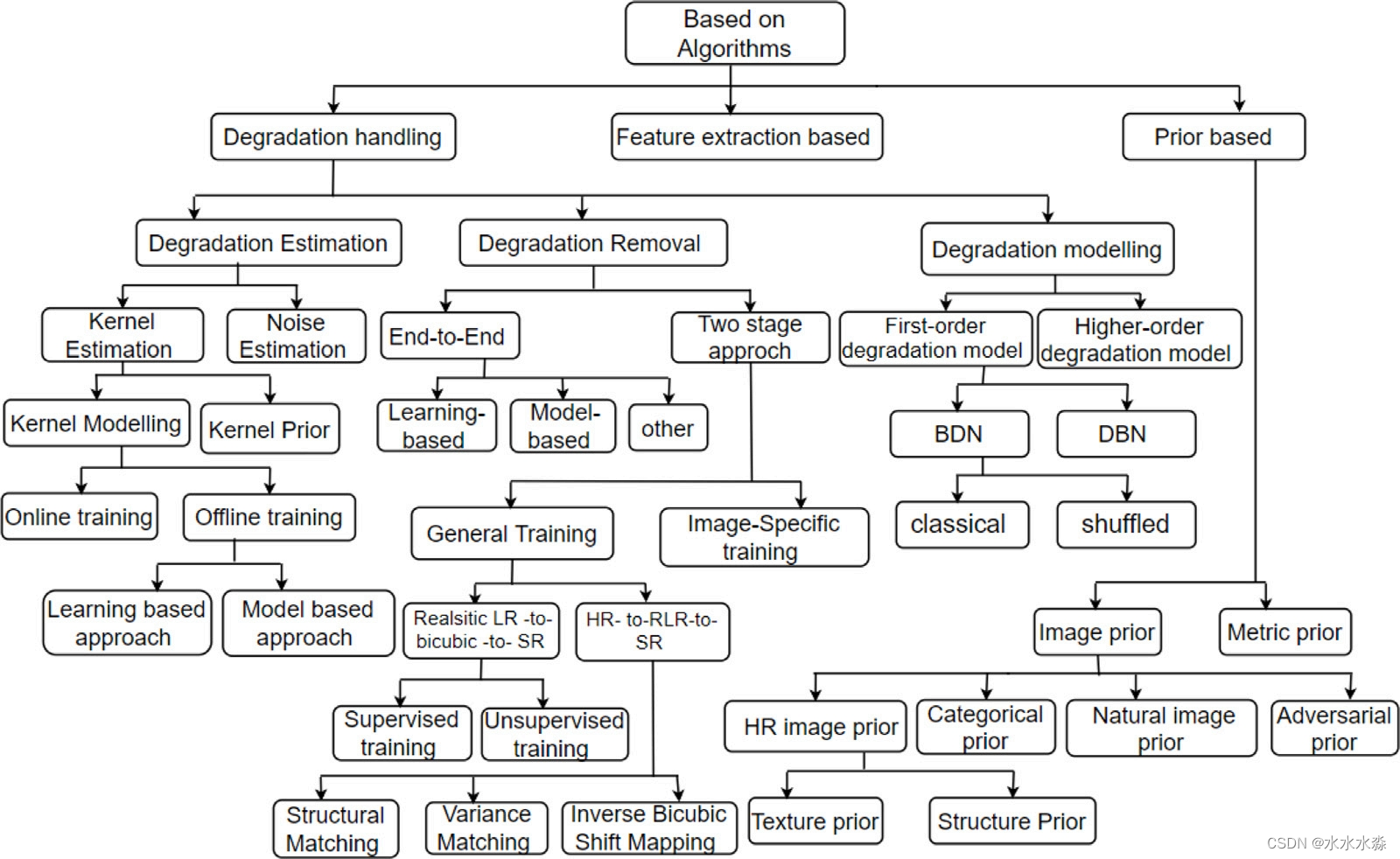
图10 基于GAN-SISR算法的分类
退化处理算法
退化处理算法可以分为退化估计算法、退化去除算法和退化建模算法,目的是改进LR图像中去除退化、估计退化和建模退化的技术,以用于HR图像重建。导致真实图像退化的主要因素有三个:模糊、噪声和降采样。基于CNN的网络中LR图像的退化估计依赖于手工制作的图像先验,并且仅限于某些退化(主要是各向同性高斯核),并且在应用于真实图像时主要由于训练数据(LR/HR)假设而失败。基于GAN的退化估计算法在很大程度上克服了这些问题。
退化估计任务可分为核估计算法和噪声估计算法。用于近似LR图像中存在的不同核的不同方法包括执行核建模和为核估计找到核先验的网络。
根据训练的类型,核建模网络可以分为在线训练方法和离线训练方法。在线训练是指根据单输入测试LR图像的退化情况对模型参数进行调整和更新。
在离线训练核估计网络中,模型权值由外部数据决定。这些网络从相应的真实LR图像生成真实核,并分为基于学习的方法和基于模型的方法。 Zhou和sstrunk[207]提出了使用真实LR图像的基于学习的核建模SR (KMSR)。它使用核估计算法从真实LR照片中提取核,并训练GAN生成类似的真实分布核以构建核池。这些生成的核进一步用于降级真实的HR图像以生成相应的LR图像。生成的LR-HR对用于训练SR网络。该模型由于采用迭代算法,速度较慢,不能用于实时求解。Yamac等人[209]给出了一种基于模型的KernelNet方法,该方法分别在核估计技术和扩展核池方面对KernelGAN和KMSR进行了改进。它提供了一个非迭代的解决方案,更好的重建精度,更低的计算复杂度和实时使用。
噪声估计算法包括一个退化模型,该模型估计LR图像中的真实噪声分布以及模糊核,以获得真实的LR图像。这些LR图像与HR图像(从真实源图像中获得)配对,得到真实的SR图像。从真实LR图像中提取方差在一定范围内的噪声块,并将其加入到下采样的HR图像中,使其更接近真实LR图像。但是当使用不同的数据集时,性能会下降。
退化去除算法可以分为两种方法,即端到端方法和两阶段方法。端到端方法直接将LR图像转换为HR图像,不需要任何中间图像;两阶段方法将LR图像转换为HR图像,分两个步骤,涉及中间域图像。
端到端方法提高了网络的有效性和效率,主要包括基于学习的方法和基于模型的方法。基于学习的方法主要学习从LR图像到其HR估计的映射。这些方法由于并行计算而速度快,由于改进了网络的训练而精度和效率高。这些方法包括保持LR和HR图像分布之间域一致性的网络,如超分辨率残差循环生成对抗网络(SRResCycGAN)[212],以处理现实世界的退化。然而,该方法需要不同的模型来处理不同的LR域退化。为了处理SR任务中单个模型内的多个LR域退化(即双三次LR、双线性LR、最近邻LR、真实LR和HR), StarGAN提出了一种深度超分辨率残星生成对抗网络(SR2*GAN)。训练模型将随机输入域图像转换为随机目标域图像,在测试阶段将目标域固定为HR域,从盲LR域生成超分辨图像。因此,与其他基于GAN的模型相比,生成器被训练来学习不同领域之间的映射,并获得合理的感知质量和良好的PSNR/SSIM,而其他基于GAN的模型更关注感知质量,降低PSNR/SSIM。
基于模型的方法具有算法可解释性,可以在MAP (maximum a posteriori)框架下处理具有不同比例因子、模糊核和噪声的SISR任务。展开超分辨率生成对抗网络(USRGAN),通过半二次分裂算法处理多次退化。通过引入退化约束(HR图像应符合退化过程)和先验约束(HR图像应具有自然特征),使HR估计更加清晰、清晰。这些网络缺乏一个标准的评估标准,因为它们通常是用特定的退化(双三次退化)来训练的,而没有考虑噪声水平和模糊核。这个问题可以通过引入模糊核和噪声水平以及LR图像作为输入来解决,但它会产生维度不匹配的问题。Lin等]发表了一种使用维度拉伸和多尺度鉴别器处理维度不匹配和多重退化问题的模型。在维度拉伸策略中,模糊核向量和噪声被拉伸成与LR图像大小相同的退化图,并作为输入馈送到生成器。多尺度鉴别器是由三种结构相同的鉴别器组合而成,保证了输出图像的局部细节丰富和全局一致性,边缘清晰。
其他端到端方法包括基于积分梯度(FAIG)的滤波器属性方法,通过一个统一的网络来估计和消除输入图像的退化,与早期的两个分支网络相比,该网络可以执行退化预测和条件恢复功能。FAIG为每个特定的退化(例如模糊,噪声)找到少量(至少1%)判别滤波器来预测和消除输入图像的退化。FAIG沿着参数空间中的路径累积梯度,将网络功能的变化归因于滤波器参数的变化,这与早期的集成梯度(IG)不同,后者利用图像空间中的路径。该方法只考虑一个离散层次的退化,不能很好地处理复杂和实际的退化。
端到端训练网络过度拟合退化模型,不能推广到其他退化。为了解决这个问题,提出了先将源域图像映射到中间域图像,然后将中间域图像上采样到HR域的方法。考虑到所需的训练数据集,提出了将网络分为两个阶段的两阶段方法作为一般训练方法和特定于图像的训练方法。一般的训练方法包括两个步骤,即领域学习和图像重建。领域学习任务可以再次分为将真实LR转换为双三次LR的网络和将HR转换为现实LR的网络。图像重建任务是将领域学习任务中生成的LR重建为高分辨率图像。
特征提取算法
Hsu和Huang将特征提取方法扩展到分辨率感知特征提取和表示。分辨率感知网络以LR和HR/SR图像为输入,学习和区分LR和HR/SR图像的特征。降低了训练复杂度,提高了图像重建质量。最近Cheng等人提出了一种基于GAN (MFAGAN)的内存高效多尺度特征聚合网络,提取并融合粗尺度和多尺度特征,重建输出的SR图像。该网络使用较少的参数,从而降低了计算复杂度和内存使用量。PatchGAN鉴别器使MFAGAN的训练更快、更稳定。该网络在不影响输出图像质量性能的情况下降低了内存访问成本并提高了推理速度。
基于先验的算法
不同的基于GAN的SISR网络使用先验来增强估计的HR图像的视觉效果。利用不同先验类型的网络可以分为图像先验网络和度量先验网络。根据图像的类型,图像先验可以分为四种类型:(i) HR图像先验;(ii)分类先验;(iii)自然图像先验;(iv)对抗先验。利用HR图像先验来保留输出HR图像的纹理和结构细节。RefSR(基于参考的超分辨率)利用先前的HR参考图像来保留估计SR图像中的纹理细节。估计的SR图像与输入的LR图像进行内容匹配,并借助参考HR图像恢复纹理细节。它缓解了不适定的SR问题,并估计了具有逼真纹理的图像。与早期基于CNN的方法相比,该方法还放松了参考HR图像与输入LR图像在内容上相似的假设,利用了相似的纹理补丁,并剔除了不相似的纹理补丁。
通过在SR过程中加入结构先验来消除输出图像中的结构畸变,进一步改进了感知驱动的SR方法。SPSR (structure - preserving SR)网络由一个梯度分支和一个SR分支组成,通过梯度损失,利用HR梯度图作为二阶约束的结构先验重构SR图像。梯度图对应于局部区域的锐度。通过网络的梯度分支从输入的LR图像梯度图中得到HR梯度图,并与SR分支融合得到结构引导的SR图像。梯度损失限制了相邻像素的二阶关系,对应于生成的SR图像与真地HR图像的梯度图之间的距离。同时,利用结构保持损失函数保留了部分图像复杂纹理模式中丰富的局部结构信息。
基于GAN-SISR损失函数的分类
根据LR和HR图像中的映射类型,将损失函数分为一对多损失函数和一对一损失函数,如图11所示。为了实现LR-HR对的灵活映射,扩大HR空间并简化训练过程,引入了一对多MAE损失。在best-buddy GAN中提出了一种best-buddy loss,以实现对生成的HR图像的灵活监督。具体来说,每个估计的高分辨率补丁由不同比例的高分辨率补丁监督。
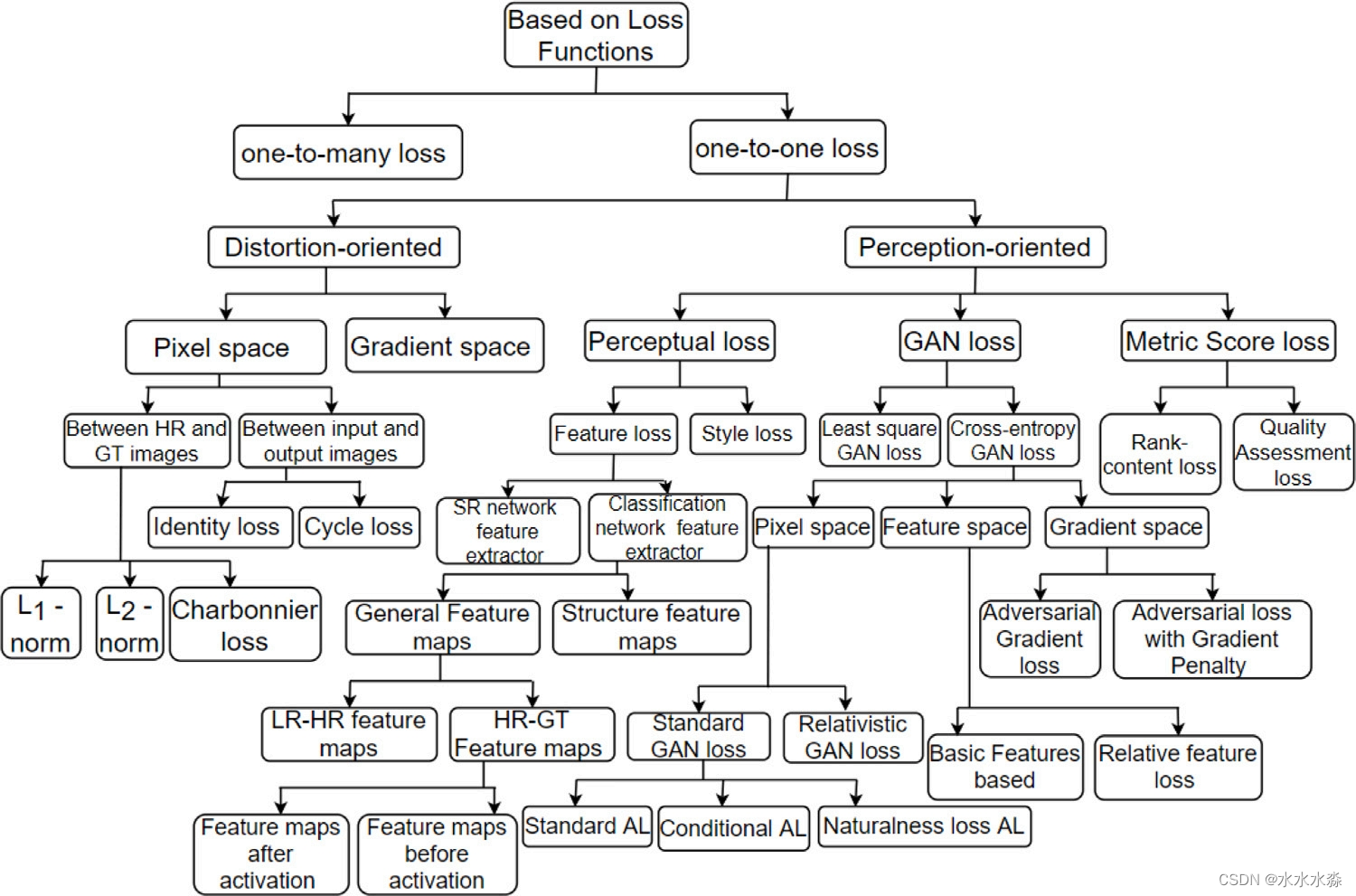
图11 基于GAN-SISR损失函数的分类
目前应用最广泛的一对一映射损失可分为面向失真的损失和面向感知的损失。面向失真的损失在图像空间中工作,主要针对LR-HR图像的内容匹配。它们可以进一步分为像素空间损失和梯度空间损失。在表1中总结了不同的面向失真的损失函数。像素空间损失度量的是两幅图像像素值之间的差异。像素损失是基于考虑计算的两幅图像进行分类的。在估计的HR图像和真实图像之间计算一种类型的像素损失,在网络的双三次上采样LR图像和估计的HR图像之间计算另一种类型的像素损失。根据所使用的范数,损失可分为𝐿1 -范数损失、𝐿2 -范数损失和Charbonnier损失,其公式如表1所示。这些损失限制了真实图像和伪生成图像的低频结构相似。然而,损失惩罚随机变化和高频细节提供了不足的边缘和纹理细节。

为了缓解这些问题,建立了一类新的像素损失,计算生成图像与放大后的输入LR图像之间或缩小后的生成图像与输入LR图像之间的距离,以获得与LR图像一致的输出图像,而不会损害高频细节。根据网络的流向,包括身份损失和周期损失,如表1所示。身份损失旨在保留输出图像中的颜色,这是生成的SR图像与双三次上采样的LR图像之间的绝对区别。一种类似的损失称为插值损失,使用Sobel算子掩模来消除输出图像中低频区域不需要的伪影和尖锐边缘周围的环形效应。掩模在高频区域具有低值,在低频区域具有高值。双三次插值在低频区域工作得很好,但在图像的高分辨率区域会产生模糊。插值损失𝐿的设计使得双三次插值被鼓励在低频区域,只是为了保持图像锐利的边缘和没有伪像。在Cycle loss中,输入的LR图像经过generator得到生成的SR图像,再次使用函数(被认为是第二个generator)进行下采样,得到LR图像。这种损失的周期一致性特性有助于获得更好的结果。
为了进一步优化生成器网络,抑制图像平滑区域中不需要的高频细节,引入了梯度空间中的损失,负责图像的结构配置。梯度信息不包含直接的像素值,而是包含像素值之间的局部变化关系,这是在伪生成图像中获得锐利边缘和纹理细节所必需的。梯度损失是真实图像的梯度映射与对应的伪生成图像之间的距离。总变差损失是另一种梯度空间损失,它是图像中相邻像素之间绝对差的总和。这种损失有助于保留像素值的局部变化,以增加纹理信息,并在生成的图像中施加空间平滑性。
面向失真的损失虽然提供了更高的PSNR值,但没有考虑图像的视觉质量,因此提供令人愉悦的视觉结果的面向感知的损失受到了广泛的关注。这些损失分为感知损失、GAN损失和Metric score 损失,如表2所示。感知损失是特征损失和风格损失的结合。特征损失限制了图像的语义信息和空间信息。需要约束的特征可以从SR任务网络和图像分类任务网络中提取。期望SR任务的特征提取器比图像分类任务的特征提取器能更好地反映特征。
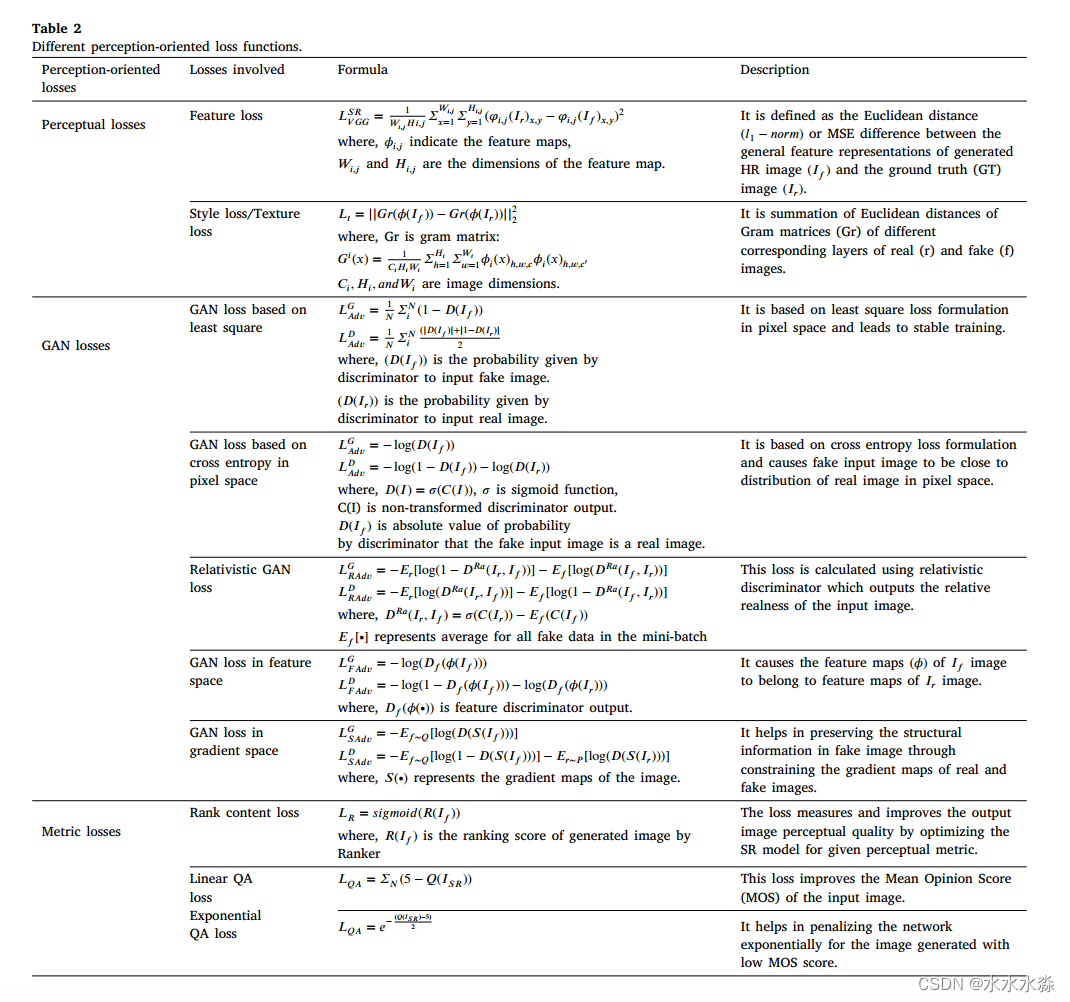
使用图像分类网络(主要是VGG网络)获得的特征图来获取VGG损失。损失可按一般特征和结构特征计算。一般特征损失比较真实和虚假图像之间的卷积特征映射,以鼓励图像之间的感知一致性。在网络的升级后的输入LR图像和生成的HR图像之间,可以在没有真实图像的情况下计算损失。另一种计算VGG损失的方法是在生成的HR图像和真实图像之间进行计算。在SRGAN中,通过预训练深度网络中激活后的特征,计算生成的HR图像和真实图像在特征上的感知特征损失,并最小化两个激活特征之间的距离。这些激活的特征是稀疏的,并且由于监督弱和重建亮度不一致而导致性能较差。为了缓解这些问题并生成更清晰边缘的感知上令人愉悦的超分辨率图像。Wang等人提出了ESRGAN,一种不同的方法来应用感知损失,即激活前的特征,因为与激活后的特征相比,这些特征包含更多信息。
GAN损失通过包含GAN的生成成分来鼓励超分辨图像驻留在自然图像流形上。通常,它计算生成器生成的图像与真实图像之间的差距。基于该公式,GAN损失由对抗生成器损失和对抗鉴别器损失组合而成,可分为基于最小二乘的GAN损失和基于交叉熵的GAN损失。基于最小二乘的GAN损失导致训练稳定,如表2所示。基于交叉熵的GAN损失算法主要应用于图像的像素空间、特征空间和梯度空间。
基于度量分数的损失包括等级-内容损失和质量评估(QA)损失。对于等级-内容损失,提出了一种可以学习不同感知度量行为的可微模型Ranker。通过学习秩方法,训练秩器来模拟不同的感知度量。为了去除不愉快的噪声,提高生成的SR图像的感知质量,提出了QA网络,该网络为SR图像提供MOS分数𝑄(𝐼𝑆𝑅)。利用该分数计算如表2所示的QA损失,以进一步提高图像的视觉质量。图像的MOS值范围为1 ~ 5。MOS值越高,感知质量越高。QA损失本质上可以是线性的,也可以是指数的,它有助于惩罚网络对低MOS分数生成的图像进行惩罚,以改善图像的视觉性能。
Datasets

Metrics
PSNR是最流行的重建图像质量评估(IQA)指标,通过图像之间的最大像素值(MAX)和均方误差(MSE)来定义。采用MSE作为损失函数,计算生成的SR图像和ground truth图像之间逐像素的差异,没有考虑视觉感知,因此在真实场景中性能较差。


SSIM (Structural Similarity Index)是另一个衡量图像之间结构相似性的客观度量,从亮度、对比度和结构方面进行评估(Eq.(25))。它从人类视觉系统的角度来评价重建质量,在一定程度上可以达到较好的感性评价要求,但不能准确测量。

主观度量是基于人的感知,当SR作为图像生成问题时,用于测量重建图像的感知质量。感知损失或对抗学习被纳入提高生成逼真纹理和其他细节的能力。MOS (Mean Opinion Score)测试是一种常见且可靠的主观图像质量评估方法,它要求人们为被测图像分配感知质量分数。
根据训练后的深度网络在深度特征上的差异,提出LPIPS (Learned Perceptual Image Patch Similarity),如Eq.(26)所示。无参考图像质量评估(NR-IQA)指标是在真实图像不可用时采用的。其中包括NIMA(神经图像评估),Ma分数(Eq. (28)), NIQE(自然图像质量评估器,方程(27)),BRISQUE(盲/无参考图像空间质量评估器),PIQE(基于感知的图像质量评估器)。NIQE利用在自然图像中观察到的统计规律的可测量偏差,而不暴露于扭曲的图像。不同的度量标准表述如下。


 感知指数(PI)结合了Ma评分和NIQE的无参考图像质量度量:
感知指数(PI)结合了Ma评分和NIQE的无参考图像质量度量:
 Challenges with possible solutions
Challenges with possible solutions
尽管基于GAN的SISR算法取得了显著的成果,但为了进一步发展,还需要解决一些问题。这里列出了其中一些问题以及可能的解决方案。
1. 尽管基于GAN的SISR任务表现出了很好的性能,但在减少参数数量、计算复杂度和网络深度等方面仍有待改进,以加快模型的速度。对于实时应用,需要进一步的研究,以实现减少内存和能量消耗,提高图像质量的网络。
2. GAN中使用的大多数损失函数要么主要改进主观度量,要么主要改进客观度量。因此,需要探索同时满足定量保真度和定性保真度的损失函数。
3.另一个重要的问题是设计更有效的架构来防止梯度消失和梯度爆炸问题,并在输出图像中保留有意义的信息。
4. 迄今为止使用的大多数指标都假设具有高质量的LR-HR配对数据集的可用性。但是,大多数使用的数据集往往是通过人工降级获得的,并且缺乏统一的、公认的SR任务指标。感性品质,指的是真实的形象或与原始形象一致的身份,仍然是一个有待探讨的问题。
5. 端到端训练的网络过度拟合了它们所训练的退化模型,并且不能推广到现实世界的退化。需要一些方法来提高它们的训练能力和泛化能力。
6. 设计一种能够产生真实LR的退化模型仍然是图像超分辨率中构建鲁棒网络的一个挑战。
7. 虽然针对特定图像的SR方法在训练数据不可用的情况下实现了更快的推理,但在处理大量测试图像时,其实际可行性和实用性仍是一个问题。
这里列出了一些可能的解决方案,以应对上述挑战或缓解问题。现有算法中的问题可以通过对现有方法进行调整或提出新的方法来解决。未来可以实现的一些解决方案如下。
1. 通过在网络中加入无BN层的深度可分离卷积层,可以实现具有较少参数的轻量级架构,从而减少内存和能量需求。
2. 可以设计一个适当组合不同加权损失的损失函数,以同时改善面向感知和面向扭曲的度量。
3.在网络中加入残差块之间的分形连接,包括短距离到长距离的连接,可以与自注意块一起去除输出HR图像中不必要的伪影。
4. 可以开发一种获取图像感知质量的盲图像质量评价方法。
5. 在具有自正则化损失的不同应用中,提出了一种高效、稳定、易于训练的神经网络——启发神经网络,可用于超分辨率任务,以获得更好的效果。
6. 结合不同类型的模糊核、下采样和噪声的真实退化模型可以提高网络的鲁棒性。
7. 设计更轻量化的模块和改进训练策略以更好地收敛,可以提高实际应用的网络速度。
Conclution
本文详细介绍了近年来以氮化镓为基础的各种SISR技术的分类。这项工作主要分为三类,包括架构、算法和在不同网络中使用的损失函数。
讨论了网络中不同层的深度和跳跃连接对网络的影响。为了提高HR重建的准确性,提出了多种损失函数,包括面向扭曲的和面向感知的。
虽然目前取得了令人满意的结果,但仍存在许多潜在的问题。对LR图像的真实退化进行建模和学习以训练SR网络是这些方法的主要问题之一。不同的数据集和指标实践在最近的网络已汇编与简要说明。文中还提到了一些主要挑战及其可能的解决方案,为在这一领域工作的研究人员提供了进一步的方向。
文献标注
[1]Guo-Jun Qi, Loss-sensitive generative adversarial networks on lipschitz densities, Int. J. Comput. Vis. 128 (5) (2020) 1118–1140.
[2]Leon A. Gatys, Alexander S. Ecker, Matthias Bethge, Image style transfer using convolutional neural networks, in: Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, 2016, pp. 2414–2423.
[3]Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, Xi Chen, Improved techniques for training gans, Adv. Neural Inf. Process.
Syst. 29 (2016).
[4] Martin Arjovsky, Léon Bottou, Towards principled methods for training generative adversarial networks, 2017, arXiv preprint arXiv:1701.04862.
[5] Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen, Progressive growing of gans for improved quality, stability, and variation, 2017, arXiv preprint
arXiv:1710.10196.
[6] Kevin Roth, Aurelien Lucchi, Sebastian Nowozin, Thomas Hofmann, Stabilizing training of generative adversarial networks through regularization, Adv.
Neural Inf. Process. Syst. 30 (2017).
[7] Jie Liu, Jie Tang, Gangshan Wu, AdaDM: Enabling normalization for image super-resolution, 2021, arXiv preprint arXiv:2111.13905.
[8]Yi-Lun Wu, Hong-Han Shuai, Zhi-Rui Tam, Hong-Yu Chiu, Gradient normalization for generative adversarial networks, in: Proceedings of the IEEE/CVF
International Conference on Computer Vision, 2021, pp. 6373–6382.
[9]Jae Woong Soh, Gu Yong Park, Junho Jo, Nam Ik Cho, Natural and realistic single image super-resolution with explicit natural manifold discrimination,
in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 8122–8131.
[10] Manuel Fritsche, Shuhang Gu, Radu Timofte, Frequency separation for real-world super-resolution, in: 2019 IEEE/CVF International Conference on
Computer Vision Workshop (ICCVW), IEEE, 2019, pp. 3599–3608.
[11] Zetao Jiang, Yongsong Huang, Lirui Hu, Single image super-resolution: Depthwise separable convolution super-resolution generative adversarial network,
Appl. Sci. 10 (1) (2020) 375.
[12] Yuval Bahat, Tomer Michaeli, Explorable super resolution, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
2020, pp. 2716–2725.
[13] Marcel C. Buhler, Andrés Romero, Radu Timofte, Deepsee: Deep disentangled semantic explorative extreme super-resolution, in: Proceedings of the Asian
Conference on Computer Vision, 2020.
[14] Mohamed Abderrahmen Abid, Ihsen Hedhli, Christian Gagné, A generative model for hallucinating diverse versions of super resolution images, 2021,
arXiv preprint arXiv:2102.06624.
[15]Sieun Park, Eunho Lee, One-to-many approach for improving super-resolution, 2021, arXiv preprint arXiv:2106.10437.
[16]Tero Karras, Samuli Laine, Timo Aila, A style-based generator architecture for generative adversarial networks, in: Proceedings of the IEEE/CVF Conference
on Computer Vision and Pattern Recognition, 2019, pp. 4401–4410.
[17] Sachit Menon, Alexandru Damian, Shijia Hu, Nikhil Ravi, Cynthia Rudin, Pulse: Self-supervised photo upsampling via latent space exploration of generative
models, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 2437–2445.
[18] Koushik Sivarama Krishnan, Karthik Sivarama Krishnan, SwiftSRGAN–rethinking super-resolution for efficient and real-time inference, 2021, arXiv preprint
arXiv:2111.14320
[19]Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz,
Zehan Wang, et al., Photo-realistic single image super-resolution using a generative adversarial network, in: Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition, 2017, pp. 4681–4690.
[20]Seong-Jin Park, Hyeongseok Son, Sunghyun Cho, Ki-Sang Hong, Seungyong Lee, Srfeat: Single image super-resolution with feature discrimination, in:
Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 439–455.
[21]Jiaojiao Qiao, Huihui Song, Kaihua Zhang, Xiaolu Zhang, Qingshan Liu, Image super-resolution using conditional generative adversarial network, IET
Image Process. 13 (14) (2019) 2673–2679.
[22]Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, Chen Change Loy, Esrgan: Enhanced super-resolution generative adversarial
networks, in: Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018.
[23]Jianqiang Chen, Yali Zhang, Xiang Hu, Calvin Yu-Chian Chen, Cascading residual–residual attention generative adversarial network for image super
resolution, Soft Comput. 25 (14) (2021) 9651–9662.
[24]Kalpesh Prajapati, Vishal Chudasama, Heena Patel, Kishor Upla, Kiran Raja, Raghavendra Ramachandra, Christoph Busch, Direct unsupervised
super-resolution using generative adversarial network (DUS-GAN) for real-world data, IEEE Trans. Image Process. 30 (2021) 8251–8264.
[25]Xudong Mao, Qing Li, Haoran Xie, Raymond Y.K. Lau, Zhen Wang, Stephen Paul Smolley, Least squares generative adversarial networks, in: Proceedings
of the IEEE International Conference on Computer Vision, 2017, pp. 2794–2802.
[26] Martin Arjovsky, Soumith Chintala, Léon Bottou, Wasserstein generative adversarial networks, in: International Conference on Machine Learning, PMLR,
2017, pp. 214–223.
[27]Xiaozhong Ji, Yun Cao, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, Real-world super-resolution via kernel estimation and noise injection, in:
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020, pp. 466–467.
[28]Seong-Jin Park, Hyeongseok Son, Sunghyun Cho, Ki-Sang Hong, Seungyong Lee, Srfeat: Single image super-resolution with feature discrimination, in:
Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 439–455.
[29]Jianqiang Chen, Yali Zhang, Xiang Hu, Calvin Yu-Chian Chen, Cascading residual–residual attention generative adversarial network for image super
resolution, Soft Comput. 25 (14) (2021) 9651–9662.
[30] Qianqian Wang, Quanxue Gao, Linlu Wu, Gan Sun, Licheng Jiao, Adversarial multi-path residual network for image super-resolution, IEEE Trans. Image
Process. 30 (2021) 6648–6658.
[31] Kalpesh Prajapati, Vishal Chudasama, Heena Patel, Kishor Upla, Kiran Raja, Raghavendra Ramachandra, Christoph Busch, Direct unsupervised
super-resolution using generative adversarial network (DUS-GAN) for real-world data, IEEE Trans. Image Process. 30 (2021) 8251–8264.
这篇关于基于生成对抗性网络的单图像超分辨率技术综述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






