本文主要是介绍如何将图像嵌入到StyleGAN的潜在空间(Image2StyleGAN、StyleGAN Encoder),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如何将图像嵌入到StyleGAN的潜在空间(Image2StyleGAN、StyleGAN Encoder)
Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?
原文地址:https://arxiv.org/abs/1904.03189
原作者: Rameen Abdal、Yipeng
Qin、Peter Wonka翻译:flyfish
NVIDIA的StyleGAN借鉴了风格迁移的模型,所以叫 Style-Based Generator ,所以论文的名字叫
《A Style-Based Generator Architecture for Generative Adversarial Networks》
et al.是拉丁文简写。其一为et alibi (以及其他地方) ,相当于and elsewhere;其二为et alii (以及其他人)
,相当于and others。 e. g.是拉丁文exempli gratia的缩写,意思是“举个例子,比如”,等同于“for
example”,目的是用例子来说明前面的观点,用法与for example相同。
摘要(Abstract)
我们提出了一种有效的算法,将给定的图像嵌入到StyleGAN的潜在空间中。 这种嵌入使图像语义编辑操作可以应用于现有照片。 以在FFHQ数据集上受过训练的StyleGAN为例,我们显示了图像变形,风格迁移和表达转移的结果。 研究嵌入算法的结果可为StyleGAN潜在空间的结构提供有价值的见解。 我们提出了一组实验来测试哪些类别的图像可以嵌入,如何嵌入图像,哪些潜在空间适合嵌入,以及嵌入是否在语义上有意义。
1、说明(Introduction)
我们的贡献包括:
1)一种有效的嵌入算法,可以将给定图像映射到预训练的StyleGAN的扩展潜空间 W + W+ W+中。
2)我们研究了多个问题,以深入了解StyleGAN潜在空间的结构,例如:可以嵌入哪种类型的图像? 可以嵌入哪种类型的面部? 可以使用哪些潜在空间进行嵌入?
3)我们建议对向量使用三个基本运算来研究嵌入的质量。 结果我们可以更好地了解潜在空间以及如何嵌入不同类别的图像。 作为一个产品我们在多种面部图像编辑应用程序上获得了出色的结果,包括变形,风格迁移和表情迁移。
2、相关工作(Related Work)
1)高质量GAN(High-quality GANs)
从Goodfellow等人的开创性工作开始。 2014年,整个计算机视觉社区见证了GAN在过去几年中的快速改进。 对于图像生成任务,DCGAN是第一个里程碑,奠定了GAN体系结构作为全卷积神经网络的基础。
groundbreaking 的同义词breaking new ground; innovative; pioneering.
开辟了新的领域,开辟新天地
从那时起,为改进GAN的性能从不同方面已经进行了各种努力,例如 损失函数,正则化或规范化和架构。 但是,由于计算能力的局限性和高质量训练数据的不足,这些工作仅使用低分辨率和质量较差的数据集用于分类和识别任务进行测试
labor shortage 劳动力短缺 ; 用工荒 ; 劳力短缺 ; 民工荒
energy shortage [能源] 能源短缺 ; 能量不足 ; 能源紧张 ; 能源匮乏
oil shortage 石油不足 ; 缺油 ; 目前石油短缺 ; 过载
为解决这个问题Karras等收集了第一个高质量的人脸数据集CelebA-HQ并提出了一种训练GAN来解决高分辨率图像生成任务的渐进策略。他们的ProGAN是第一个可以以1024×1024的高分辨率生成逼真的人脸的GAN。从复杂的数据集(例如ImageNet)生成高质量图像仍然是一个挑战。为此,Brock等提出BigGAN并认为该训练的GAN极大地受益于大的batch size。他们的BigGAN可以生成涵盖不同类别的逼真样本和平滑插值。最近,Karras等收集了更多样化和更高质量的人脸数据集FFHQ,并提出了一种新的生成器体系结构,该体系结构受到神经风格迁移思想的启发,从而进一步提高了GAN在人脸生成任务上的性能。然而,由于神经网络的缺乏可解释性而对图像修改的控制仍然是一个未解决的问题。在本文中,我们通过将用户指定的图像嵌入到GAN潜在空间中来解决可解释性问题,这将产生许多潜在的应用。
argued 争论,表明
dramatically 显着地
spanning 跨度
tackle:做出坚定的努力来应对(问题或困难的任务)make determined efforts to deal with (a
problem or difficult task).
2)潜在空间嵌入( Latent Space Embedding)
通常,有两种现有方法可将实例从图像空间嵌入到潜在空间:
i)学习将给定图像映射到潜在空间的编码器(例如Variational Auto-Encoder);
ii)选择一个随机的初始潜在代码,并使用梯度下降对其进行优化。
在它们之间,第一种方法通过执行通过编码器神经网络的前向传播,提供了图像嵌入的快速解决方案。 但是,通常存在超出训练数据集的问题。 在本文中,我们决定在第二个基础上
作为更通用,更稳定的解决方案。 作为并发开发的工作,Github存储库stylegan-encoder还证明了基于优化的方法可以带来非常高视觉质量的嵌入。
在它们之间,第一种方法通过执行编码器神经网络的前向传递,提供了图像嵌入的快速解决方案。 但是,通常存在超出训练数据集的问题。 在本文中,我们决定以第二种方法为基础,以提供更通用,更稳定的解决方案。 作为并发开发的工作,Github上的stylegan-encoder还证明了基于优化的方法可以嵌入非常高的视觉质量。
3)感知损失和风格迁移 (Perceptual Loss and Style Transfer )
传统上,在像素空间中测量两个图像之间的低级相似度使用的是L1 / L2损失函数。 在过去的几年中,受复杂图像分类成功的启发,Gatys等人观察到,VGG图像分类模型的学习滤波器是出色的通用特征提取器,并建议使用提取特征的协方差统计来感知图像之间的高级相似性,然后将其形式化为 知觉损失(Perceptual Loss )
为了证明他们强大的方法,他们在风格迁移方面取得了令人鼓舞的结果。具体地说,他们认为VGG神经网络的不同层以不同的比例提取了图像特征,可以分为内容和样式。为加速初始算法, Johnson等提出训练神经网络来解决的优化问题,可以实时的将给定图像的风格迁移到另一张图像中。他们方法的唯一局限性是他们需要为不同样式的图像训练单独的神经网络。 最后,Huang和Belongie 通过自适应实例规范化( adaptive instance normalization)解决了这个问题。 结果是他们可以实时迁移任意风格。
3、什么样的图像嵌入到StyleGAN潜在空间?(What images can be embedded into the StyleGAN latent space?)
trivial:几乎没有价值或重要性 of little value or importance.
我们着手研究是否可以将图像嵌入StyleGAN潜在空间的问题。 这个问题并非微不足道,因为我们最初对面部和其他GAN进行嵌入的实验结果导致不再能够识别为同一个人的面部。 由于FFHQ数据集的改进的可变性和StyleGAN体系结构的卓越质量,人们重新希望将现有图像嵌入潜在空间成为可能。
3.1、 嵌入各种图像类别的结果(Embedding Results for Various Image Classes)
为了测试我们的方法,我们收集了一个小规模的数据集,其中包含25种不同的图像,涵盖5个类别(即面部,猫,狗,汽车和绘画)。 数据集的详细信息显示在补充材料中。 我们使用StyleGAN提供的代码对面部图像进行预处理。 该预处理包括注册到规范的面部位置(canonical face position)。
为了更好地了解潜在空间的结构和属性,研究大量图像类别的嵌入是有益的。 我们选择猫,狗和绘画的面部,因为它们与人脸具有相同的整体结构,但绘画风格却截然不同。 选择汽车是因为它们与面部没有结构相似性。
depict描述;描画
图1显示了针对收集的测试数据集中的每个图像类别的一个示例的嵌入结果。 可以看出,嵌入的奥巴马面孔具有很高的感知质量,并且忠实地再现了输入。 但是,应注意的是,嵌入的面部略微光滑,没有细微的细节。

图1:
第一行:输入图像。
第二行:将图像嵌入到StyleGan潜在空间的结果。
slightly adv. 些微地,轻微地;纤细地,瘦小的 faithfully adv. 忠实地;如实地;诚心诚意地;深信着地
有趣的是,超越面部,我们发现尽管StyleGAN生成器是在人脸数据集上进行训练的,但嵌入算法仍能够远远超出人脸。 如图1所示,尽管比人脸稍微差一点,但我们可以获得合理且相对高质量的猫,狗,甚至是绘画和汽车的嵌入物。 这揭示了算法的有效嵌入能力以及生成器学习到的滤波器的一般性。
generality 一般性、概论、普遍性、大部分;
另一个有趣的问题是预训练的潜在空间的质量如何影响嵌入的。 为了进行这些测试,我们还使用了StyleGAN训练汽车,猫等。如补充材料中所示,这些结果的质量明显较低。
conduct
v. 组织,实施,进行;指挥(音乐);带领,引导;举止,表现;传导(热或电)
n. 行为举止;管理(方式),实施(办法);引导
3.2、面部图像嵌入的鲁棒性如何?(How Robust is the Embedding of Face Images?)
1)仿射变换(Affine Transformation )
如图2和表1所示,StyleGAN嵌入的性能对仿射变换(平移,调整大小和旋转)非常敏感。
其中,迁移似乎性能最差,因为它可能无法产生有效的面部嵌入。 对于调整大小和旋转,结果是有效的面部。但是它们模糊不清和丢失了许多细节,这些细节仍然比常规嵌入更糟。 从这些观察中,我们认为GAN的泛化能力对仿射变换很敏感,这意味着学习到的表示在一定程度上仍取决于规模和位置。

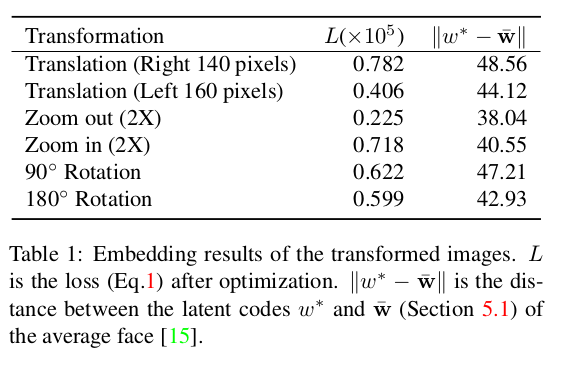

图2:
第一行:输入图像。
第二行:嵌入的结果。
(a)标准嵌入结果。
(b)向右平移140像素。
©向左平移160像素。
(d)缩小2倍。
(e)放大2倍。
(f)90◦旋转。
(g)180◦旋转。
blurry 模糊的
2)嵌入缺陷图像(Embedding Defective Images)
如图3所示,
StyleGAN嵌入的性能对于图像缺陷非常强大。 可以观察到,不同面部特征的嵌入彼此独立。 例如,移开鼻子对眼睛和嘴巴的嵌入没有明显影响。 一方面,这种现象对于一般的图像编辑应用程序是有益的。 另一方面,它表明潜在空间( latent space)不会迫使嵌入的图像成为完整的面部,即它不会修补丢失的信息。


图3:
有缺陷的图像嵌入的压力测试结果。
第一行:输入图像。
第二行:嵌入的结果。
inpaint 修补 (某个去除水印软件的名字) defect n. 缺点,缺陷;不足之处 vi. 变节;叛变 defective
adj. 有缺陷的;不完美的 n. 有缺陷的人;不完全变化词
3.3、选择哪个潜在空间?(Which Latent Space to Choose?)
在StyleGan中有多种潜在空间可以用来被嵌入,两个明显的候选是 初始化潜在空间 Z Z Z(the initial latent space Z)和中间潜在空间 W W W(the intermediate latent space W)
通过将512维向量 z ∈ Z z\in Z z∈Z经过完全连接的神经网络来获得512维向量 w ∈ W w \in W w∈W
我们工作的一个重要见解是,不可能容易地直接将其嵌入到 W W W或 Z Z Z中。
因此,我们建议将其嵌入到扩展的潜在空间 W + W + W+中。 W + W + W+是18个不同的512维 w w w向量的级联,每个StyleGAN体系结构的一层都可以通过AdaIn接收输入。 如图5(c)(d)所示,直接嵌入W不会产生合理的结果。 另一个有趣的问题是,学习到的网络权重对于结果有多重要。
我们在图5(b)(e)中回答了这个问题,该图显示嵌入网络的过程,该网络可以简单地用随机权重初始化。


图5:
(a)原始图像。将结果嵌入到原始空间 W W W中:
(b)在网络层中使用随机权重;
© 使用 W ‾ \overline{\mathbf{W}} W初始化;
(d)使用随机初始化。将结果嵌入到 W + W+ W+空间中:
(e)在网络层中使用随机权重;
(f)使用 W ‾ \overline{\mathbf{W}} W初始化;
(g)使用随机初始化。
4、嵌入的意义何在?(How Meaningful is the Embedding?)
我们提出了三个测试来评估嵌入是否在语义上有意义。 这些测试中的每一个都可以通过对向量w i的简单潜在代码操纵来进行,并且这些测试对应于计算机视觉和计算机图形学中的语义图像编辑应用程序:变形,表达传递和风格迁移。 如果最终的操作产生了高质量的图像,我们认为测试成功。
4.1、变形(Morphing)
图像变形是计算机图形学和计算机视觉领域的一个长期研究课题
给定两个具有各自潜在向量(latent vector) w 1 w_1 w1和 w 2 w_2 w2的嵌入图像
通过线性插值计算变形(morphing) w = λ w 1 + ( 1 − λ ) w 2 , λ ∈ ( 0 , 1 ) w=\lambda w_{1}+(1-\lambda) w_{2}, \lambda \in(0,1) w=λw1+(1−λ)w2,λ∈(0,1)
以及使用新代码w生成随后的图像。 如图4所示,我们的方法在人脸图像(行1,2,3)之间生成高质量的变形,但在类别内(行4)和类间(行5)变形中的非人脸图像上均失败


图4:
在两个嵌入图像(最左边和最右边的)之间变形。
有趣的是,可以观察到在类间变形的中间图像中存在人脸轮廓,这表明StyleGAN的潜在空间结构专用于人脸。 因此,我们推测非面部图像实际上是通过以下方式嵌入的。 最初的图层会创建一个类似人脸的结构,但随后的图层会在此结构上绘画,因此不再可识别。
虽然对变形本身的广泛研究超出了本文的范围,但我们相信面部变形的结果是很好的,可能会优于目前的技术水平。我们把这次调查留到以后的工作中去做。
4.2、风格迁移(Style Transfer)
给定两个潜码w_1和w_2,风格迁移通过交叉操作进行计算 ,我们展示了嵌入式风格化图像与其他人脸图像之间的风格转换结果(图6),以及来自不同类别的嵌入式图像之间的风格转换结果(图8)。


图6:第一列:风格图像
第二列:使用来自VGG-16的conv4_2层的风格损失(style loss)的嵌入风格化图像;
第三到第六列:通过用嵌入风格图像替换最后9层基础图像的潜码(latent code)来进行风格迁移。


图8:嵌入风格图像(第一列)和嵌入内容图像(第一行)之间的风格迁移。
更具体地说,在图8中,我们保留前9层的嵌入内容图像的潜代码(对应于空间分辨率 4 2 − 6 4 2 4^{2}-64^{2} 42−642),并用后9层的样式图像的潜代码(对应于空间分辨率 4 2 − 102 4 2 4^{2}-1024^{2} 42−10242)覆盖潜代码。
我们的方法能够迁移低层特征(如颜色和纹理),但不能忠实地保持非人脸图像(第二列图8)的内容结构,尤其是绘画。这一现象表明,StyleGAN的泛化和表达能力更可能存在与较高空间分辨率相对应的风格层中
4.3、表情迁移与人脸再现(Expression Transfer and Face Reenactment)
(Historical reenactment) 说明从英文翻译而来-历史重现是一种教育或娱乐活动Historical
reenactment (or re-enactment)
给定三个输入向量 w 1 、 w 2 、 w 3 w_1、w_2、w_3 w1、w2、w3,表达式转移被计算为 w = w 1 + λ ( w 3 − w 2 ) w=w_{1}+\lambda\left(w_{3}-w_{2}\right) w=w1+λ(w3−w2),其中
w 1 w_1 w1是目标图像的潜代码,
w 2 w_2 w2对应于源图像的中性表达,
而 w 3 w_3 w3对应于更独特的表达式。
例如, w 3 w_3 w3可以对应于同一个人的笑脸, w 2 w_2 w2可以对应于一张没有表情的脸。
neutral-expression的意思 A blank expression is a facial expression
characterized by neutral positioning of the facial features.
更详细的说明
为了消除噪声(例如背景噪声),我们在差分潜码通道(the channels of difference latent code)的 L 2 L2 L2范数上启发式地设置了一个下限阈值,在该阈值以下,通道被零向量替代。 对于上述实验,阈值的选定值为1。我们对生成的向量进行归一化,以控制特定方向上的表情强度。 这样的码(code)相对独立于源面部(source face),可用于迁移表情(图7)。 我们相信这些表达转移结果也具有很高的质量。 补充材料和随附的视频中提供了其他结果。


图7:
表情迁移的结果。第一行显示IMPA-FACES3D[24]数据集中的参考图像。
在在各行之后,每个示例中的中间图像是嵌入的图像,其表情逐渐迁移。
分别指向引用表情(在右侧)和相反方向(在左侧)。更多结果包含在辅助材料
eliminate v. 消除 / 根除 / 不加考虑 / 杀死
heuristic adj. 启发的 / 启发式的 / 探索的 / 试验性的 n. 启发式步骤 / 探索性步骤 / 启发式教育法
resultant n. 合成速率 / 合成矢量 / 结果 / <化学>生成物 adj. 因而发生的 / 结果的 / 合成的
supplementary adj. 补充的 n. 增补物 / 补充者 / <英>补充提问
accompany v. 陪伴 / 为…伴奏 / 兼带 / 伴奏
resultant的意思
In mathematics, the resultant of two polynomials is a polynomial expression of their coefficients, > which is equal to zero if and only if the polynomials have a common root (possibly in a field extension),or, equivalently, a common factor (over their field of coefficients). In some older texts, >> the resultant is also called eliminant.
5、嵌入算法 (Embedding Algorithm)
我们的方法遵循一个简单的优化框架,将给定的图像嵌入到预先训练的生成器的流形(manifold)上。从合适的初始化w开始,我们搜索一个最优的向量 w ∗ w^{*} w∗,该向量最小化度量给定图像和由 w ∗ w^{*} w∗生成的图像之间的相似度的损失函数,算法1给出了该方法的伪代码。这项工作的一个有趣的方面是,并不是所有的设计选择都会带来好的结果,而使用设计选择进行试验可以进一步深入了解嵌入过程。

straightforward adj. 简单的 / 易做的 / 易懂的 / 坦率的
manifold adj. <正式><文>多种多样的 / 多方面的 n. 歧管 / 多支管 / 集合管 / 复印本
insight n. 洞察力 / 洞悉 / <精神病学>顿悟 / 自知力
converged 收敛
converge v. 从不同方向聚集 / 使汇聚 / 趋同 / <数>收敛
percept n. <哲>知觉对象 / 认知 / 感知 / 认识
5.1、初始化(Initialization)
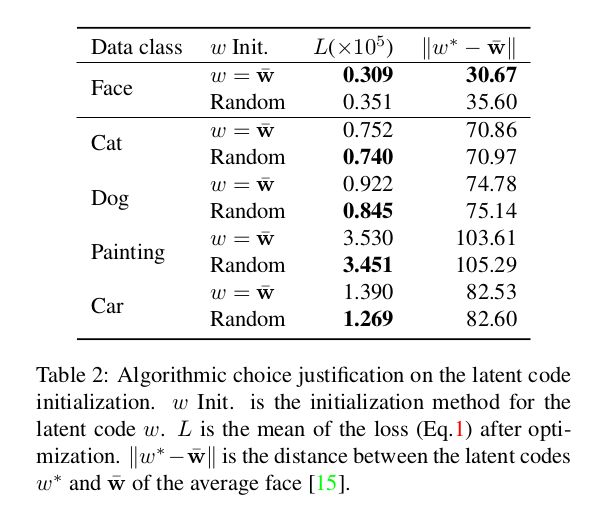
我们研究了初始化的两种设计选择,第一种选择是随机初始化。在这种情况下,独立于均匀分布 U [ − 1 , 1 ] \mathcal{U}[-1,1] U[−1,1]对每个变量进行采样。第二种选择的动机是观察到到平均潜伏向量w̄的距离可以用来识别低质量的人脸。因此,我们建议使用w̄作为初始化,并期望优化收敛到更接近 w ∗ w∗ w∗的向量 W ‾ \overline{\mathbf{W}} W。
justifiable adj. 情有可原的 / 无可非议的 / 能辩护的 / 可辩解的
experimenting adj. 乐于尝试的 v. [试验] 实验;尝试(experiment的ing形式)
independently adv. 单独地 / 自立地 / 独立地 / 客观公正地
为了评估这两种设计方案,我们比较了优化后的潜码 w ∗ w^{*} w∗和 W ‾ \overline{\mathbf{W}} W之间的损失值和距离 ∥ w ∗ − w ‾ ∥ \left\|w^{*}-\overline{\mathbf{w}}\right\| ∥w∗−w∥。
如表2所示,初始化用于人脸图像嵌入的 w = w ‾ w=\overline{\mathbf{w}} w=w不仅使优化后的 w ∗ w^{*} w∗更接近 W ‾ \overline{\mathbf{W}} W,而且实现了低得多的损失值。
然而,对于其他类别的图像(例如狗),随机初始化被证明是更好的选择。
直观地,该现象表明该分布只有一簇面部( one cluster of faces),其他实例(例如,狗、猫)是围绕簇的散乱的点,没有明显的模式。质量结果如图5(F)(G)所示。
人脸聚类(face cluster)
achieve v. 达到 / 取得 / 实现 / 成功
5.2、损失函数(Loss Function)
为了在优化期间测量输入图像和嵌入图像之间的相似性,我们采用了损失函数是 V G G − 16 VGG-16 VGG−16感知损失(perceptual loss )和逐像素(pixel-wise )MSE损失的加权组合
w ∗ = min w L p e r c e p t ( G ( w ) , I ) + λ m s e N ∥ G ( w ) − I ∥ 2 2 w^{*}=\min _{w} L_{p e r c e p t}(G(w), I)+\frac{\lambda_{m s e}}{N}\|G(w)-I\|_{2}^{2} w∗=wminLpercept(G(w),I)+Nλmse∥G(w)−I∥22
I ∈ R n × n × 3 I \in \mathbb{R}^{n \times n \times 3} I∈Rn×n×3 是输入图像
G ( ⋅ ) G(·) G(⋅) 生成器的预训练模型
N N N是图像中标量的数量(i.e. N = n × n × 3 ) N=n \times n \times 3) N=n×n×3),
w w w是要优化的潜在代码
λ m s e = 1 \lambda_{m s e}=1 λmse=1是为了获得良好的性能而根据经验得出的。
对于等式1中的感知损失项 L percept ( ⋅ ) L_{\text {percept}}(\cdot) Lpercept(⋅),我们使用:
L percept ( I 1 , I 2 ) = ∑ j = 1 4 λ j N j ∥ F j ( I 1 ) − F j ( I 2 ) ∥ 2 2 L_{\text {percept}}\left(I_{1}, I_{2}\right)=\sum_{j=1}^{4} \frac{\lambda_{j}}{N_{j}}\left\|F_{j}\left(I_{1}\right)-F_{j}\left(I_{2}\right)\right\|_{2}^{2} Lpercept(I1,I2)=j=1∑4Njλj∥Fj(I1)−Fj(I2)∥22
I 1 , I 2 ∈ R n × n × 3 I_{1}, I_{2} \in \mathbb{R}^{n \times n \times 3} I1,I2∈Rn×n×3 是输入图像
其中 F j F_j Fjj 表示VGG16中的conv1_1, conv1_2, conv3_2, conv4_2各层输出的feature map
N j N_j Nj是第 j j j层输出中的标量数, λ j = 1 \lambda_{j}=1 λj=1对于所有 j j j都是根据经验获得的,以获得良好的性能。
empirically adv. 以经验为依据地
empiricism n. <哲>经验主义 / 经验论
我们对感知损失以及逐像素的MSE损失的选择来自以下事实:仅逐像素的MSE损失无法找到高质量的嵌入。 因此,感知损失充当某种正则化器,以将优化引导到潜在空间的正确区域。
我们进行了消融研究,以证明我们在公式1中选择的损失函数是合理的。如图9所示,单独使用像素级MSE损失项(列2)可以很好地嵌入常规颜色,但不能捕捉非面部图像的特征。此外,它还具有平滑效果,即使对于人脸也不会保留细节。
我们进行消融研究以证明我们在等式1中选择损失函数的合理性。 如图9所示,仅使用像素级MSE损失项(第2列)可以很好地嵌入一般颜色,但无法捕捉非面部图像的特征。 此外,它具有平滑效果,即使人脸也无法保留细节。

图9:损失函数的算法选择理由。每行分别显示测试数据集中五个不同类的图像结果
从左到右,每列显示:
(1)原始图像;
(2)仅pixel-wise MSE损失;
(3)仅VGG-16 conv3_2 层上的感知损失;
(4)pixel-wise MSE损失和VGG-16 conv3_2。
(5)仅感知损失(公式2);
(6)我们的损失函数(公式1)。
更多结果包含在补充材料中。
ablation study(消融研究、消融学习、消融实验) quora的解释
ablation study知乎上通俗易懂的解释
为了提升baseline的性能,给它加了两个模块A,B 为了验证A、B两个模块是不是真的都有用,你需要做ablation study。
实验1:在baseline的基础上加上模块A,看效果。 实验2:在baseline的基础上加上模块B,看效果。
实验3:在baseline的基础上同时加上模块AB,看效果。 然后结果可能是,实验1和实验2的结果都不如实验3,那么说明AB都是有用的;
然而也有可能你会发现实验1的结果和实验3一样,甚至更好。这就说明你的想法是有问题的,模块B其实并没有起到作用,提升只来自于模块A。
注解:
相当于遵守奥卡姆剃刀原则,如无必要,勿增实体即简单有效原理。切勿浪费较多东西去做,用较少的东西,同样可以做好的事情。
简单和复杂的方法都能达到同样的效果,选择简单的方法。
有趣的是,由于在像素空间工作的均方误差损失忽略了特征空间的差异,其在非人脸图像(如汽车和油画)上的嵌入结果倾向于预先训练的StyleGAN的平均人脸。
这个问题通过测量特征空间中的图像相似性的感知损失(列3,5)来解决。由于我们的嵌入任务要求嵌入的图像在所有比例下都接近输入,因此我们发现匹配VGG-16网络多层上的特征(第5列)比只使用单层(第3列)效果更好。这进一步激励我们将像素方向的MSE损失与感知损失相结合(列4、6),因为像素方向的MSE损失可以被视为像素尺度上的最低水平的感知损失。图9的第6列显示了我们最终选择的嵌入结果(像素MSE+多层感知损失),它在不同的算法选择中实现了最佳性能。
5.3、其他参数(Other Parameters)
我们使用学习率为0.01的Adam优化器,
在我们的所有实验中, β 1 = 0.9 , β 2 = 0.999 , \beta_{1}=0.9, \beta_{2}=0.999, β1=0.9,β2=0.999, and ϵ = 1 e − 8 \epsilon=1 e^{-8} ϵ=1e−8。
艾米斯。我们使用5000步梯度下降阶梯来优化-。
在32 GB NVIDIA Titan V100 GPU上每张图像所需时间不到7分钟
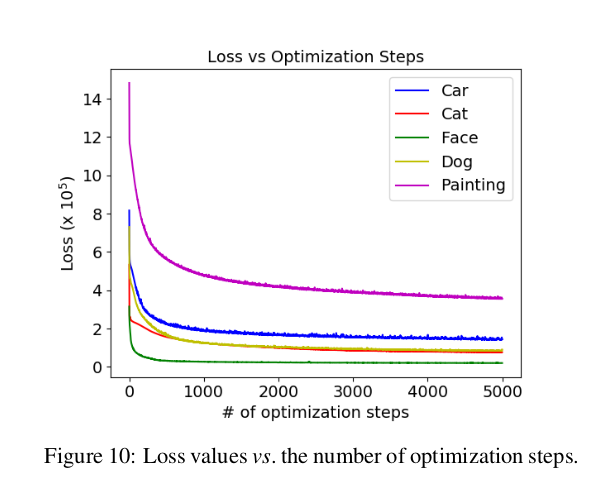
为了证明我们选择的5000步优化是合理的,我们调研了损失函数作为迭代次数的函数的变化。如图10所示,在1000步优化左右人脸图像的损失值下降最快,并且收敛。猫、狗和汽车图像在3000步优化左右收敛较慢;而绘画曲线最慢,在5000步优化左右收敛。在所有的实验中我们选择优化了5000步的损失函数。
迭代嵌入(Iterative Embedding)
我们测试了该方法对迭代嵌入的鲁棒性,即我们迭代地将嵌入结果作为新的输入图像,然后再次进行嵌入。重复此过程七次。如图11所示,虽然保证了输入图像在第一次嵌入后存在于模型分布中,但随着迭代嵌入次数的增加,本文方法的性能逐渐退化(丢失更多细节)。出现这种现象的原因可能是所采用的优化方法在局部最优点附近收敛速度慢。对于人脸以外的嵌入,随机初始潜码也可能是退化的一个因素。总之,这些观察结果表明,尽管“完美”嵌入很难达到,但我们的嵌入方法可以很容易地在模型分布上达到合理的“良好”嵌入。

6、结论(Conclusion)
我们提出了一种有效的算法将给定的图像嵌入到StyleGAN的潜在空间中。该算法支持语义图像编辑操作(semantic image editing operation)如图像变形、风格迁移和表情迁移。我们还利用该算法对StyleGan潜在空间进行了多方面的研究。我们提出了实验来分析什么类型的图像可以嵌入,它们是如何嵌入的,以及嵌入的意义有多大。我们工作的重要结论是在扩展的潜在空间 W + W+ W+中嵌入效果最好,并且任何类型的图像都可以嵌入。然而,只有面的嵌入在语义上是有意义的。
我们的框架仍然有几个局限性。首先,我们继承预先训练的StyleGan中存在的图像伪影。
我们在补充资料中进行了说明。其次,优化需要几分钟时间,对于交互式编辑来说,可以在一秒钟内工作的嵌入算法会更有吸引力。
注解:
图像伪影(image artifact )图像就像有一滴水的效果,该bug在StyleGan2中修复。
在未来的工作中,我们希望扩展我们的框架以处理静态图像之外的视频。 此外,我们想探索在三维数据(例如点云或网格)上训练的GAN中的嵌入。
artifact n. 人工制品 / 手工艺品
这篇关于如何将图像嵌入到StyleGAN的潜在空间(Image2StyleGAN、StyleGAN Encoder)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








