本文主要是介绍Kubernetes APIServer高可用与性能优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前的apiserver其实讲解的差不多了,其实就是认证,鉴权,准入,以及限流。这是apiserver里面最核心的能力,当然还有一些比如watch的缓存,除了承担上面的职责之外,它还承担的了重要的角色就是保护etcd,apiserver是唯一 一个可以访问etcd这样一个组件,因为我可以收敛从外面过来的请求,从apiserver同一个客户端以长连接连接到etcd里面,有效的减小etcd的压力。
同时它具有基于内存的缓存机制,有些读操作你直接到apiserver了,它其实是通过ringbuffer来实现的,如果你去读它的代码。
优化参数
kube-apiserver 推荐优化的参数如下:
--default-watch-cache-size:默认值 100;用于 List-Watch 的缓存池;建议 1000 或更多;--delete-collection-workers:默认值 1;用于提升 namesapce 清理速度,有利于多租户场景;建议 10;--event-ttl: 默认值 1h0m0s;用于控制保留 events 的时长;集群 events 较多时建议 30m,以避免 etcd 增长过快;--max-mutating-requests-inflight: 默认值 200;用于 write 请求的访问频率限制;建议 800 或更高;--max-requests-inflight: 默认值 400;用于 read 请求的访问频率限制;建议 1600 或更高;--watch-cache-sizes: 系统根据环境启发式的设定;用于 pods/nodes/endpoints 等核心资源,其他资源参考 default-watch-cache-size 的设定; K8s v1.19 开始,该参数为动态设定,建议使用该版本。
启动APIserver示例

很多参数都是默认配置好了,很少需要自己提供一长串的apiserver的参数。
构建高可用的多副本的apiserver

高可用最常用的模式是冗余部署+负载均衡。
任何的硬件是不可靠的,内存,硬盘,网卡都会坏。所以不能相信基础架构这个层面是完全可靠的。那么我们就要为这种可能出现的过程做准备。
如果你一个节点坏了,那么我能不能多准备几个节点,然后冗余部署多部署几个节点。
apiserver也一样通过冗余部署来实现apiserver的高可用。但是apiserver本身是无状态的rest server。
apiserver要做的事情就是接受请求,然后将请求存下来,这是apiserver唯一要做的事情,所以它本身是无状态的,无状态的服务管理就会变的非常的简单,所以换容易就可以实现扩容和缩容。
说白了apiserver的高可用就是冗余部署+负载均衡。
预留充足的CPU、内存资源
随着集群中节点数量不断增多,APIServer对CPU和内存的开销也不断增大。过少的CPU资源会降低其处理效率,过少的内存资源会导致 Pod被 OOMKilled,直接导致服务不可用。在规划API Server 资源时,不能仅看当下需求,也要为未来预留充分。
如果是通过kubeadm部署的,kubelet将apiserver拉起来的,每个apiserver就被封装为pod,那么我就可以做探活的,因为apiserver里面是支持存活性探测和就绪性探测,那我要去get一个真正的url,然后根据返回的状态决定是否重启。
既然是以pod的方式运行,那么就可以做资源限额的配置,我可以限制你的cpu,限制你的资源。
在早期运行生产化集群,集群规模小,给apiserver预留的cpu memory都很小,然后跑着跑着集群规模越来越大,内存就爆了,天天oom,这个时候就需要去变更将内存扩出来。
然后跑着跑着发现集群越来越慢,因为cpu有限制,给了它很小的cpu,不能够让它高效的跑,所以这个时候要去调整cpu,所以在生产化部署的时候,要预留好集群规模未来有多大,它会使用多少cpu和内存,预留出来,这里面就不要想着省钱了,因为apiserver如此重要。
善用速率限制(RateLimit)

还要确保我的apiserver不会被oom kill掉,在确保它性能基础之上还得限流,通过inflight来保证apiserver的一个总体的并发的requests,确保它不会被压死。
然后配合APF,通过这种方式来确保我做了一个精细化的限流,初始阶段就使用默认的配置就好了,后面随着业务的变更再去做调整。

设置合适的缓存大小 --watch-cache-sizes

apiserver本身还是一个缓存,apiserver去get etcd对象的时候,它会有一个本地的cache,这个watch-cache本身是ring buffer。
也就是它从etcd里面拿到数据会存到自己的ringbuffer里面,只要这个ringbuffer没有满,那么所有的信息都会被缓存掉。如果ringbuffer满的话,之前存在的信息就会被覆盖掉。
所以ringbuffer就是环状的内存结构,所以设置合适的缓存大小,比如watch-cache-size,是apiserver的一个参数,通过调节这个参数来调节apiserver这边缓存有多大,你集群越大,建议设置的watch-size越大,这样的话apiserver多去拿缓存数据,那么可以有效的减少对etcd的压力,只要本地有,它就不去查了。

注意:apiserver是允许客户端忽略缓存的,比如要list一个对象,这个对象里面没有加resourceversion,这个时候客户端告诉apiserver说,我是不信任你的缓存的,我要最新数据,这个时候apiserver是穿透的,它要从etcd里面拉取最新的数据。
所以客户端尽量写resourceversion,这样有效的利用apiserver的缓存。
客户端尽量使用长连接

优先使用侦听,少用轮询,后端是分布式的存储,分布式存储支持的并发很弱,然后你又不相信我的apiserver的缓存,你要一直来list这个数据,其实我要将这个请求丢到etcd,etcd很累,它会跟不上,既然etcd和apiserver都支持长连接,支持监听机制,那么建议客户端使用监听机制来获取最新的数据,而不是一直来轮询,一直轮询就会导致我这边压力过大。
监听的话还ok,最多支持一些长连接,如果单实例支持不了那么多长连接,比如几十万,那么还可以横向扩展,通过横向扩展来分散这种并发连接的压力。
所以通过这种机制有效的减少对服务器端的压力。
这里也说明了,为什么apiserver做缓冲的作用非常的大。你想如果没有apiserver,你客户端10w个pod都要去watch某个对象的话,那么你watch的是etcd,那么etcd就需要支持那么多的并发。
如果长连接当中有apiserver这一环,那么相当于这10w个连接可能均分到10个apiserver里面去。
然后apiserver到etcd里面就是一个很少的一个并发的连接了,因为它的连接时复用的。apiserver挡在etcd和客户端之间,有效的减少了对etcd这种访问。
如何访问apiserver
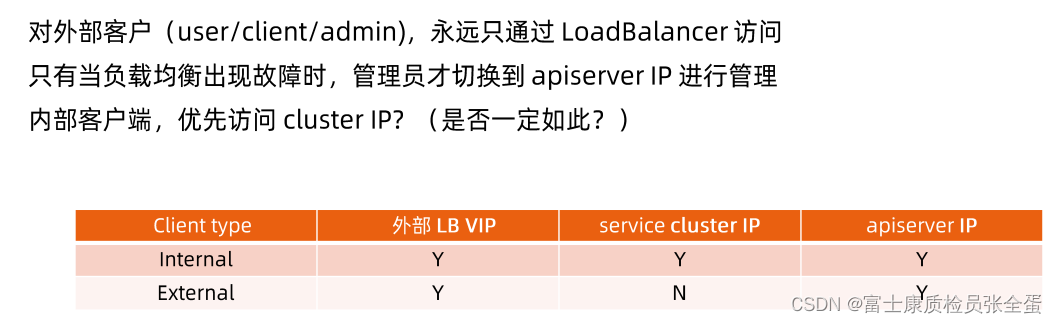
不同云下面,负载均衡可能是不一样的,在内部我们通过clusterIP访问的,有时候集群的外部会配置负载均衡,给一个VIP就行了。
同一个apiserver会有不同的访问入口,一个是从负载均衡上面过来的,一个是从集群的kube-proxy过来的。
我们所有控制平面的组件希望是用同一个访问入口,要么使用负载均衡的VIP,要么使用kube-proxy提供的service的cluster IP。
假设有两个入口,一个入口通的,一个入口坏了。这样就会产生一个问题。整个集群都是自动化的,但是这些组件访问apiserver的时候,它访问的入口不一样。一半工作,一半不工作就会导致你的状态汇报不上来,那节点就宕机了,显示offline或者unknown,但是你的控制器是活的,那么就会驱逐pod,和之前说过的etcd场景就非常的类似了,我们一定要避免这种场景的发生。
所以建议访问入口用同一个。
搭建多租户的kubernetes集群

公司有很多的部门和客户,如何让这些不同的部门,客户有比较好的方式去共享同一个集群。
在k8s里面,租户是一个虚的概念,它本身没有租户的概念,k8s它所提供的是一个一个的基础能力,这个基础能力能够支持你的多租户需求。
构建多租户的平台其实就是如何将这些能力组织起来。
多租户集群,特别是apiserver这边,最重要的部分就是受信了,就包含认证和鉴权,认证就是禁止匿名访问。你要和企业的认证系统集成。
授权就是不同的用户放到不同的namespace里面去,那么它们之间权限彼此隔离。
资源隔离
有些项目上是有GPU的,别人的作业不能过来,这种方式就是我在部署的时候,通过taint约束别人不使用这批节点。可以通过nodeselect来决定某些业务去某些特定的节点,这样在资源落地的时候就已经和别人隔离的。
应用访问隔离就是应用部署在k8s里面,那么还需要去添加一些安全策略,不是所有人都可以访问我的web服务的。一个防火墙策略就禁止其他人访问80端口。
也可能说约束某类用户访问某一个url的某一个请求,比如你可以get我的haol这个路径,这个就是通过更加高级的策略去控制的。
一个集群如果是多租户的,那样就要设计到共享资源,那样就需要对资源的配额做一个管理了,就是谁能够使用多少资源,这个resourcequota如何管控。
认证

如果使用LDAP,那么就要和认证服务去做集成。
授权

对于生产系统,RBAC更加合适,理论上没有必要去开发自己的webhook了。
RBAC
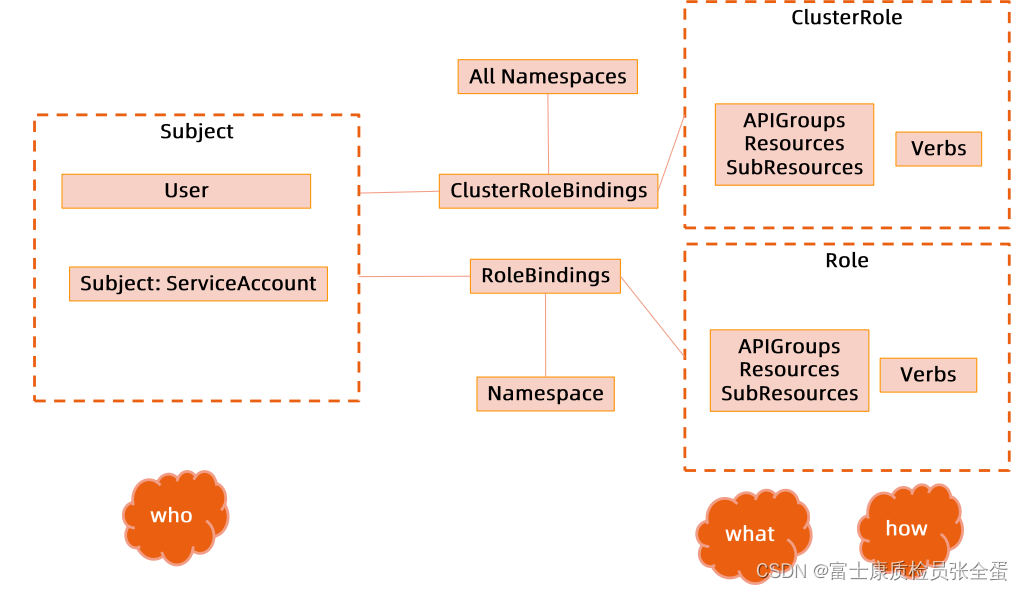
RBAC就是通过几个对象,role,clusterrole,rolebinding,clusterrolebinding来定义谁,也就是授权主体能够对哪些对象进行什么样操作的一个业务目标
规划系统角色

要去规划整个生产化集群的时候就要去想集群有哪些角色,管理员角色,普通用户角色。
然后systemaccount就是我们所说的系统账户,服务账户。k8s会为每个namespace去创建sa,因为有个sa的admin-plugin,它会去watch你的所有namespace创建,请求。
然后namespace创建好了之后,sa就被创建出来了。
sa本身会有一个对应的token,存在了sa相关的secret里面,那么有了token就可以配合授权来完成用k8s帮你颁发证书来访问apiserver的这样一个目的。
这篇关于Kubernetes APIServer高可用与性能优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






