本文主要是介绍ubuntu20.04 nerf Instant-ngp (下) 复现,自建数据集,导出mesh,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考链接
Ubuntu20.04复现instant-ngp,自建数据集,导出mesh_XINYU W的博客-CSDN博客
GitHub - NVlabs/instant-ngp: Instant neural graphics primitives: lightning fast NeRF and more
youtube上的一个博主自建数据集
https://www.youtube.com/watch?v=VsFHX8IgX1o
老样子
可以跟我继续往下走
首先得先完成
ubuntu20.04 nerf Instant-ngp-CSDN博客
的所有步骤,然后再开始
#安装OpenCV参考我的这篇
ubuntu20.04+slambook2+vscode实例配置(至第五章)_slam实例-CSDN博客
ffmpeg安装(Ubuntu20.04 )参考
2.ffmpeg安装(Ubuntu20.04 )_ubuntu安装ffmpeg-CSDN博客
其中可能需要
chmod -x ./configure
如果权限不够可以加sudo
安装ffmpeg可能会遇到的问题
# --enable-libxvid
# 解决 ERROR: libxvid not found
# 包下载地址:https://ftp.osuosl.org/pub/blfs/conglomeration/xvidcore/
tar xf xvidcore-1.3.7.tar.gz
cd xvidcore/build/generic/
基本上都是要先
chmod -x ./configure
sudo make
sudo make install
基本上按照这个就没啥问题
2.ffmpeg安装(Ubuntu20.04 )_ubuntu安装ffmpeg-CSDN博客
然后可以先看一下
youtube上的一个博主自建数据集
https://www.youtube.com/watch?v=VsFHX8IgX1o
先建文件夹,将视频命名为VID.MP4,然后我的colmap2nerf.py是位于~/nerf_instant-ngp/instant-ngp/scripts/,--video_fps 2的2是指一秒几帧
~/nerf_instant-ngp/instant-ngp/scripts/colmap2nerf.py --video_in VID.MP4 --video_fps 2 --run_colmap --aabb_scale 16
随后输入两个y,就可以将视频转换为图片.
随后将生成的transform.json和image文件夹复制到与instant-ngp/scripts/的data下,我的是复制到
data/myvideo/one
然后就在~/nerf_instant-ngp/instant-ngp目录下打开终端,输入
./instant-ngp data/myvideo/one ./instant-ngp data/myvideo/six即可出现下面(自己拍的视频,尽可能多角度)
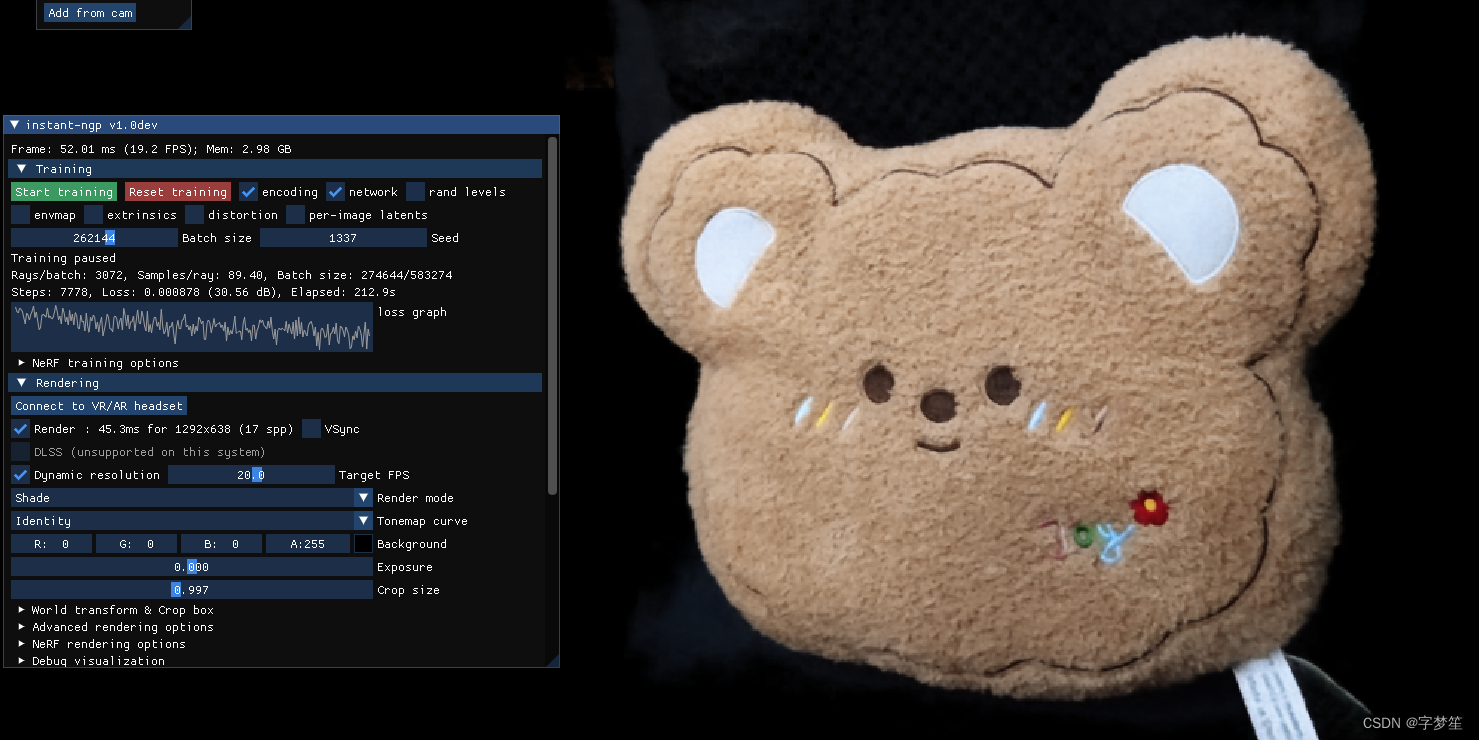
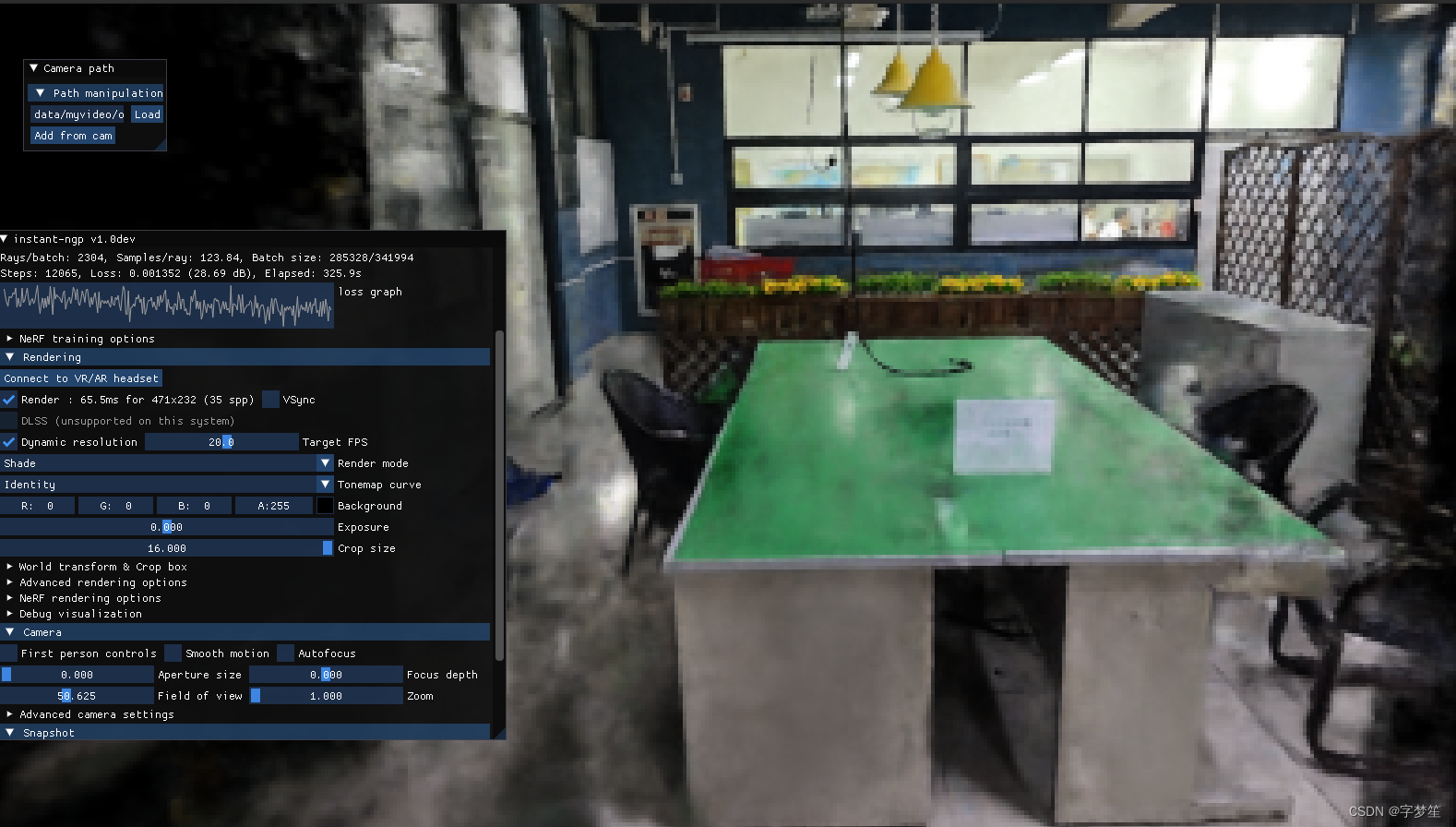
另外,渲染的效果还是可以的,相对于源码来说还是有点模糊,我一些参数也没有设置,直接就拉进来进行渲染,速度是非常快的。
在拍摄中注意重建的质量取决于colmap2nerf.py能够从图像中提取准确的相机参数。如果要效果好点的话,需要注意几点:
- 尽量光线比较充足均匀;
- 拍摄物体尽量覆盖所有的视角;
- 采用防抖动设备,避免在拍摄过程中图像失真;
- 图像分辨率尽量要高;神经辐射场NeRF之Instant-ngp环境搭建与应用
导出和大小的调试可以参考下面这个
英伟达NeRF项目Instant-ngp在Windows下的部署,以及数据集的制作(适合小白的保姆级教学)-CSDN博客
2023.10.12
这篇关于ubuntu20.04 nerf Instant-ngp (下) 复现,自建数据集,导出mesh的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





