本文主要是介绍python-arima模型statsmodels库实现-有数据集(续)-statsmodels-0.9.0版本,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
python-arima模型statsmodels库实现-有数据集(续)
这篇博客是上一篇python-arima模型statsmodels库实现的续集,上一篇采用的statsmodels版本应该要高一点,如果使用低版本的statsmodels代码会有bug,这一篇则是针对statsmodels-0.9.0版本的代码。
代码如下:
#coding=gbk
import numpy as np
import pandas as pd
import os
from numpy import NaN
from numpy import nan
import matplotlib.pyplot as plt
import statsmodels.api as sm #acf,pacf图
from statsmodels.tsa.stattools import adfuller #adf检验
from pandas.plotting import autocorrelation_plot
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.stats.diagnostic import acorr_ljungboximport statsmodels.api as sm
import matplotlib as mpl
path="E:/data/china_data.xlsx"
# 为了控制计算量,我们限制AR最大阶不超过6,MA最大阶不超过4。plt.style.use('fivethirtyeight')
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['font.serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
df=pd.read_excel(path)
#print(df)
#help(df)#for index, row in df.iterrows():df=df.replace(NaN, "null")
# print(index, row)
print(df)
def f(column):r=0inde1=0index2=len(column)-1for i in range(len(column)):# print(column[len(column)-i-1])if column[len(column)-i-1] is "null" and r==1:index2=ireturn index1,index2if column[len(column)-i-1]!= "null" and r==0:index1=ir=1return index1,index2#df['时间(年)']=pd.to_datetime(df['时间(年)'])print(df.columns)
print(df[df.columns[0]])
indexz=df.columns[0]def adf_test(data):#小于0.05则是平稳序列# print("data:",data.values)data_z=np.array(list(data.values))#print(data_z.reshape(-1,))t = adfuller(data_z.reshape(-1,))print("p-value:",t[1])
def box_pierce_test(data):#小于0.05,不是白噪声序列print(acorr_ljungbox(data, lags=1)) def stability_judgment(data):fig = plt.figure(figsize=(12,8))ax1=fig.add_subplot(211)fig = sm.graphics.tsa.plot_acf(data,lags=5,ax=ax1)ax2 = fig.add_subplot(212)fig = sm.graphics.tsa.plot_pacf(data,lags=5,ax=ax2)plt.show()def model_fit(data,df,index,length,index1,index2):data_diff=df[["时间(年)",index]][length-index2:length-index1]# sm.tsa.arma_order_select_ic(data_diff,max_ar=6,max_ma=4,ic='aic')['aic_min_order'] # AIC#对模型进行定阶pmax = int(len(data) / 10) #一般阶数不超过 length /10qmax = int(len(data) / 10)if pmax>4:pmax=6if qmax>4:qmax=4bic_matrix = []print("data",data)# help(sm.tsa.arima.ARIMA)for p in range(pmax +1):temp= []for q in range(qmax+1):try:# ARIMA(train_data, order=(1,1,1))# print(sm.tsa.arima.ARIMA(data,order=(p,1,q)).fit())temp.append(sm.tsa.ARIMA(data,order=(p,1,q)).fit().bic)# print(temp)except:temp.append(None)# temp.append(sm.tsa.arima.ARIMA(data,order=(p,1,q)).fit().bic)bic_matrix.append(temp)bic_matrix = pd.DataFrame(bic_matrix) #将其转换成Dataframe 数据结构print("bic_matrix",bic_matrix)p,q = bic_matrix.stack().astype(float).idxmin() #先使用stack 展平, 然后使用 idxmin 找出最小值的位置print(u'BIC 最小的p值 和 q 值:%s,%s' %(p,q)) # BIC 最小的p值 和 q 值:0,1model = sm.tsa.ARIMA(data, order=(p,1,q)).fit()model.summary() #生成一份模型报告predictions_ARIMA_diff = pd.Series(model.fittedvalues, copy=True)print(predictions_ARIMA_diff)model.forecast(5) #为未来5天进行预测, 返回预测结果, 标准误差, 和置信区间for index, column in df.iteritems():if index==indexz:continueindex1,index2 =f(column)length=len(column)# print("index1 index2:",index1,index2)# print(column[length-index2-1:length-index1])print(index)df[index]=df[index].replace( "null",0)df[index].astype('float')df[str(index)+"diff1"]=df[index].diff(1)df[str(index)+"diff2"]=df[index+"diff1"].diff(1)# 一阶差分还原# tmpdata2:原数据# pred:一阶差分后的预测数据#df_shift = tmpdata2['ecpm_tomorrow'].shift(1)#predict = pred.add(df_shift)# predict = pred + df_shift# print(index2-index1)#print(df[["时间(年)",index]][length-index2:length-index1])adf_test(df[[index]][length-index2:length-index1])box_pierce_test(df[[index]][length-index2:length-index1])model_fit(df[[index]][length-index2:length-index1],df,index,length,index1,index2)## model_fit(data,p,q)stability_judgment(df[[index]][length-index2:length-index1])stability_judgment(df[[str(index)+"diff1"]][length-index2:length-index1])# stability_judgment(df[[str(index)+"diff2"]][length-index2:length-index1])plt.plot(df[["时间(年)"]][length-index2:length-index1],df[[index]][length-index2:length-index1],label="diff0")plt.plot(df[["时间(年)"]][length-index2:length-index1],df[[str(index)+"diff1"]][length-index2:length-index1],label="diff1")# plt.plot(df[["时间(年)"]][length-index2:length-index1],df[[str(index)+"diff2"]][length-index2:length-index1],label="diff2")# df[["时间(年)",index]][length-index2:length-index1].plot(x=indexz,y=index,figsize=(9,9))plt.xlabel("时间(年)")plt.ylabel(index)plt.legend()plt.show()os.system("pause")运行结果如下:
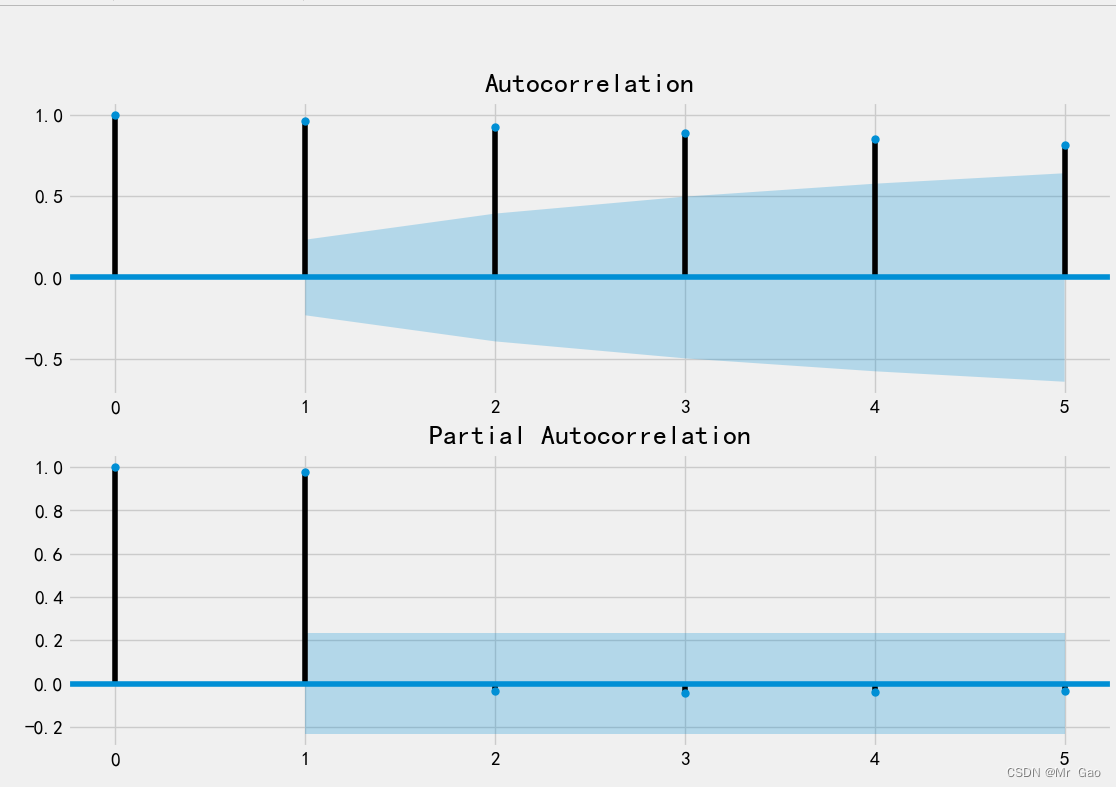
大家可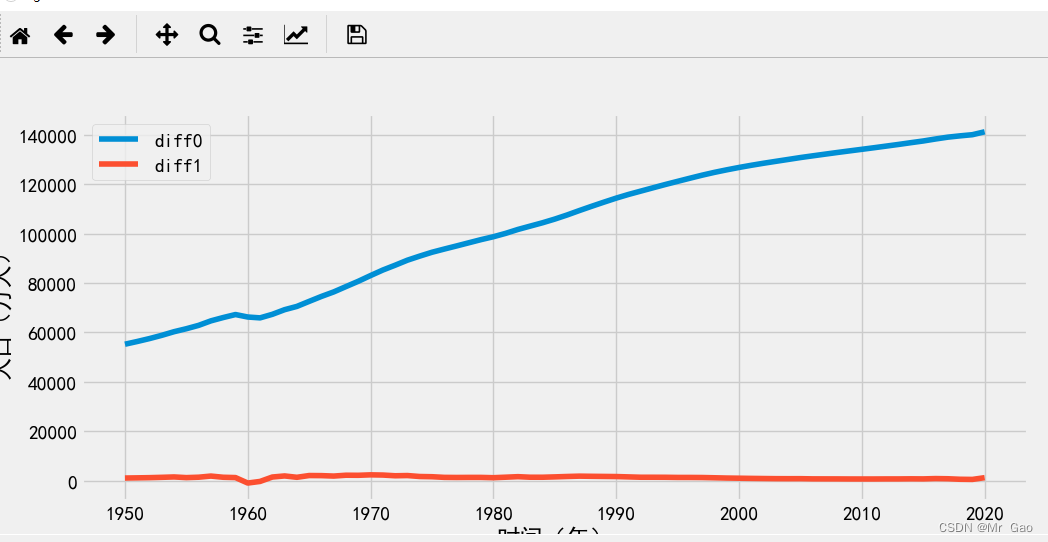
大家可以学习一下哈。
这篇关于python-arima模型statsmodels库实现-有数据集(续)-statsmodels-0.9.0版本的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



