本文主要是介绍决策树挑出好西瓜【人工智能】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、决策树
- 二、ID3决策树及实现
- 1.西瓜样本
- 2.决策树实现
- 三、Sklearn决策树实现
- 1.数据集
- 2.导入库
- 3.数据转换
- 4.建立模型并训练
- 四、参考文献
一、决策树
决策树(decision tree):是一种基本的分类与回归方法,此处主要讨论分类的决策树。
在分类问题中,表示基于特征对实例进行分类的过程,可以认为是if-then的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
决策树通常有三个步骤:特征选择、决策树的生成、决策树的修剪。
用决策树分类:从根节点开始,对实例的某一特征进行测试,根据测试结果将实例分配到其子节点,此时每个子节点对应着该特征的一个取值,如此递归的对实例进行测试并分配,直到到达叶节点,最后将实例分到叶节点的类中。
下图为决策树示意图,圆点——内部节点,方框——叶节点
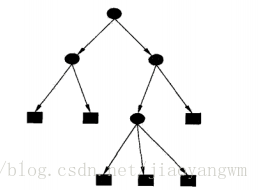
- 决策树学习的目标:根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
- 决策树学习的本质:从训练集中归纳出一组分类规则,或者说是由训练数据集估计条件概率模型。
- 决策树学习的损失函数:正则化的极大似然函数
- 决策树学习的测试:最小化损失函数
- 决策树学习的目标:在损失函数的意义下,选择最优决策树的问题。
- 决策树原理和问答猜测结果游戏相似,根据一系列数据,然后给出游戏的答案。

上图为一个决策树流程图,正方形代表判断模块,椭圆代表终止模块,表示已经得出结论,可以终止运行,左右箭头叫做分支。
决策树的优势在于数据形式非常容易理解。
二、ID3决策树及实现
1.西瓜样本

2.决策树实现
- 计算初始信息熵
- 计算信息增益
- 按照信息增益的大小排序
- 选取最大的信息增益的特征,以此特征作为划分节点
- 该特征从特征列表删除,继续返回到上一步筛选,重复操作,知道特征列表 = 0
1.导入包
#导入模块
import pandas as pd
import numpy as np
from collections import Counter
from math import log2
2.数据的获取处理操作
#数据获取与处理
def getData(filePath):data = pd.read_excel(filePath)return datadef dataDeal(data):dataList = np.array(data).tolist()dataSet = [element[1:] for element in dataList]return dataSet
3.获取属性名称
#获取属性名称
def getLabels(data):labels = list(data.columns)[1:-1]return labels
4.获取类别标记
#获取属性名称
def getLabels(data):labels = list(data.columns)[1:-1]return labels
#获取类别标记
def targetClass(dataSet):classification = set([element[-1] for element in dataSet])return classification
5.叶节点标记
#将分支结点标记为叶结点,选择样本数最多的类作为类标记
def majorityRule(dataSet):mostKind = Counter([element[-1] for element in dataSet]).most_common(1)majorityKind = mostKind[0][0]return majorityKind
6.计算信息熵
#计算信息熵
def infoEntropy(dataSet):classColumnCnt = Counter([element[-1] for element in dataSet])Ent = 0for symbol in classColumnCnt:p_k = classColumnCnt[symbol]/len(dataSet)Ent = Ent-p_k*log2(p_k)return Ent
7.子数据集构建
#子数据集构建
def makeAttributeData(dataSet,value,iColumn):attributeData = []for element in dataSet:if element[iColumn]==value:row = element[:iColumn]row.extend(element[iColumn+1:])attributeData.append(row)return attributeData
8.计算信息增益
#计算信息增益
def infoGain(dataSet,iColumn):Ent = infoEntropy(dataSet)tempGain = 0.0attribute = set([element[iColumn] for element in dataSet])for value in attribute:attributeData = makeAttributeData(dataSet,value,iColumn)tempGain = tempGain+len(attributeData)/len(dataSet)*infoEntropy(attributeData)Gain = Ent-tempGainreturn Gain
9.选择最优属性
#选择最优属性
def selectOptimalAttribute(dataSet,labels):bestGain = 0sequence = 0for iColumn in range(0,len(labels)):#不计最后的类别列Gain = infoGain(dataSet,iColumn)if Gain>bestGain:bestGain = Gainsequence = iColumnprint(labels[iColumn],Gain)return sequence
10.建立决策树
#建立决策树
def createTree(dataSet,labels):classification = targetClass(dataSet) #获取类别种类(集合去重)if len(classification) == 1:return list(classification)[0]if len(labels) == 1:return majorityRule(dataSet)#返回样本种类较多的类别sequence = selectOptimalAttribute(dataSet,labels)print(labels)optimalAttribute = labels[sequence]del(labels[sequence])myTree = {optimalAttribute:{}}attribute = set([element[sequence] for element in dataSet])for value in attribute:print(myTree)print(value)subLabels = labels[:]myTree[optimalAttribute][value] = \createTree(makeAttributeData(dataSet,value,sequence),subLabels)return myTree
def main():filePath = 'E:\Ai\watermelon\watermalon.xls'data = getData(filePath)dataSet = dataDeal(data)labels = getLabels(data)myTree = createTree(dataSet,labels)return myTree




三、Sklearn决策树实现
1.数据集
2.导入库
导入相关库
import pandas as pd
import graphviz
from sklearn.model_selection import train_test_split
from sklearn import treef = open('C:/Users/86199/Jupyter/watermalon.csv','r')
data = pd.read_csv(f)x = data[["色泽","根蒂","敲声","纹理","脐部","触感"]].copy()
y = data['好瓜'].copy()
print(data)

3.数据转换
#将特征值数值化
x = x.copy()
for i in ["色泽","根蒂","敲声","纹理","脐部","触感"]:for j in range(len(x)):if(x[i][j] == "青绿" or x[i][j] == "蜷缩" or data[i][j] == "浊响" \or x[i][j] == "清晰" or x[i][j] == "凹陷" or x[i][j] == "硬滑"):x[i][j] = 1elif(x[i][j] == "乌黑" or x[i][j] == "稍蜷" or data[i][j] == "沉闷" \or x[i][j] == "稍糊" or x[i][j] == "稍凹" or x[i][j] == "软粘"):x[i][j] = 2else:x[i][j] = 3y = y.copy()
for i in range(len(y)):if(y[i] == "是"):y[i] = int(1)else:y[i] = int(-1)
#需要将数据x,y转化好格式,数据框dataframe,否则格式报错
x = pd.DataFrame(x).astype(int)
y = pd.DataFrame(y).astype(int)
print(x)
print(y)

4.建立模型并训练
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2)
print(x_train)
训练结果:
#决策树学习
clf = tree.DecisionTreeClassifier(criterion="entropy") #实例化
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test)
print(score)

四、参考文献
1.决策树挑出好西瓜(基于ID3、CART)
2.决策树挑出好西瓜
3.【机器学习】 - 决策树(西瓜数据集)
这篇关于决策树挑出好西瓜【人工智能】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[Day 73] 區塊鏈與人工智能的聯動應用:理論、技術與實踐](/front/images/it_default2.jpg)



