本文主要是介绍实证分析 | STATA入门数据处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
STATA十八讲1-7讲
1. 常用命令
*--- 需求帮助 ---*
help
search
*--- 进入某路径 ---*
cd
*--- 设定内存 ---*
set memory 20m
*--- 打开和保存数据 ---*
clear
ues
save
*--- 导入数据 ---*
input
edit
import
*--- 重整数据 ---*
append
merge
xpose
reshape
gen
egen
rename
drop
keep
sort
encode
decode
order
by
2.命令语句
- 命令语句的格式
[by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options]
- 命令 command
只要不引起歧义,命令可以尽量只写前几个字母,如summarize可以写成sum
- 变量varlist
varlist表示一个变量,或者多个变量,多个变量之间用空格隔开
- 分类操作 by varlist
by varlist在执行时要求内存中的数据是按照by后面的变量排序的,当未排序正确时就会提示not sorted错误
sort foreign //按国产车和进口车排序
by foreign: sum price weight
- 赋值及运算 = exp
该选项主要用于给新变量负值或替换原变量的值
gen nprice = price + 10
replace nprice = nprice - 10
- 条件表达式 if exp
*只查看价格超过1 万元的进口车(同时满足两个条件)
list make price if foreign==1 & price>10000
*查看价格超过1 万元或者进口车(两个条件任满足一个)
list make price if foreign==1 | price>10000
*分类型查看价格超过1 万元的汽车的品牌和价格
by foreign, sort: list make price if price>10000
- 范围筛选 in range
如果要计算较低的前10 台车的平均价格
sort price
sum price in 1/10
- 加权 weight
sum score [weight = num] //求分数的均值,num为不同分值的人数变量,以人数进行加权
- 其他可选项 , options
不同命令有不同可选项,实现不同的功能
3. 数据
- 打开数据
use xxx.dta, clear
- 数据类型
-
数值型变量按精度区分:byte,int,long,float,double
-
字符串变量,最多可以达244个字符,一般用str#表示字符的多少,例如str#20表示有20个字符
-
日期型变量,在STATA中,1960年1月1日被认为是第0天
-
缺失值
- 数据类型的转化
字符型变量转化成数值型变量:destring
destring date, replace //把date转换成数值型* 把字符型变量中含有非数值型字符时不能进行转换
destring date, replace ignore(" ") //忽略空格,然后转换
destring price percent, gen(price2 percent2) ignore(“$ ,%”) //忽略$空格,%,并生成新变量
数值型转变量换为字符型变量:tostring
tostring year, replace
- 数据显示格式:
format - 在STATA中直接录入数据:
input
clear
input id str10 name economy
1 john 40
2 chris 80
3 jack 90
end
save economy.dta, replace
- 标签数据
label给数据/变量/变量值增加标签说明
label data "上市公司基本信息表" //给数据集设置标签
label var code "证券代码" //给变量设置标签
label define statelb 1 "国有企业" 0 "非国有企业"
label values state statelb //给变量值设置标签
- 删除数据
erase mydata.dta //删除文件时一定要带上后缀名
4. 数据整理
- 连接数据
纵向合并数据
use male, clear
append using female.dta
横向合并数据
merge 1:1 code year using mydata.dta, nogen keep(1 3) //1对1横向合并
- 数据重整
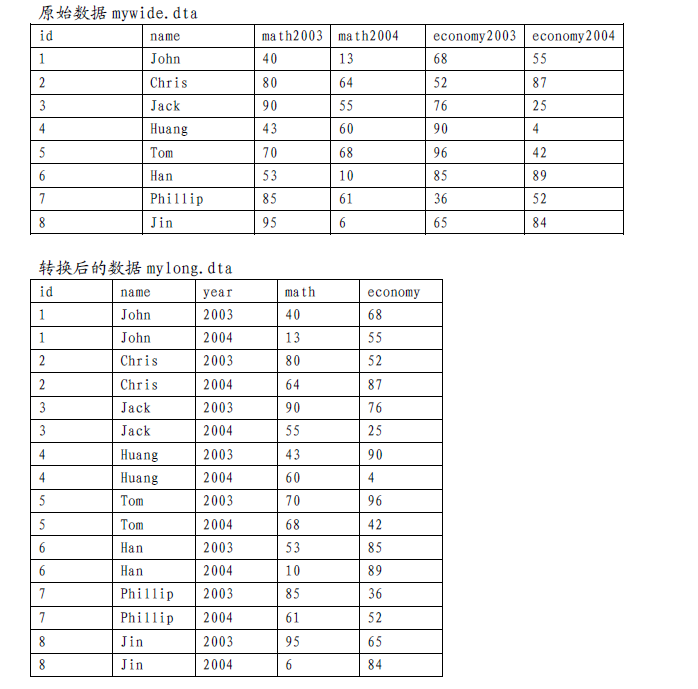
*--- 数据重整,宽变长 ---*
use mywide.dta, clear
reshape long math economy, i(id name) j(year)
save mylong.dta, replace*--- 数据重整,长变宽 ---*
use mylong.dta, clear
reshape wide math economy, i(id name) j(year)
save mywide.dta, replace
将多列数据变一列:stack
stack var1-var6, into(x) clear
drop _stack
- 数据转置
行列互换
use math.dta, clear
xpose, clear
5. 函数与运算符
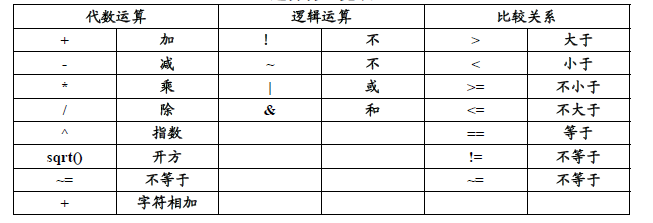
- 运算符
- 函数概览
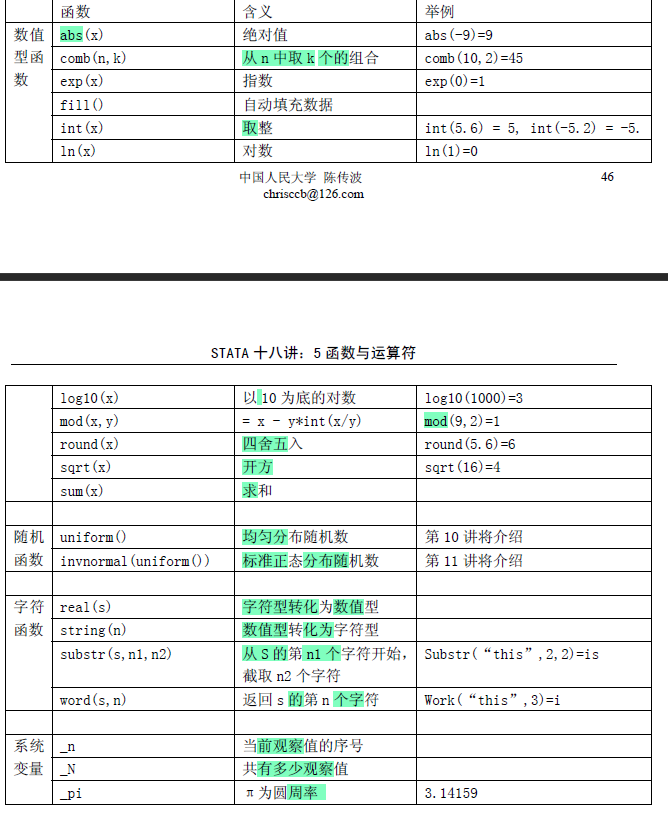
- 数学函数
- 三角函数、指数和对数函数
gen y1 = sin(x)
gen y2 = exp(x)
gen y3 = ln(x)
- 取整和四舍五入
*--- 取整 ---*
int(x) //取整,不论后面的小数是什么,只取小数点前的数值*--- 四舍五入 ---*
round(x) // 四舍五入取整
round(x, .01) //保留两位小数四舍五入
- 求和及求均值gen和egen
gen y = sum(x) //求列累积和
egen y = sum(x) //求列总和
egen y = rsum(x y z) //求x+y+z总和
egen y = rowmean(x y z) //求(x+y+z)/3
egen y = rowsd(x y z) //求x y z的方差
egen y = rowmim(x y z) //求x y z的最小值
egen y = rowmax(x y z) //求x y z的最大值
egen y = mean(x) //求列均值
egen y = median(x) //求列中位数
egen y = std(x) //求变异系数,与方差不同
- 字符函数
gen year = substr(enddate,1,4) //从enddate字符1开始取,取4个字符赋给year
gen y = strpos(s1, s2) != 0 //strpos(s1, s2)返回字符s2在s1中的位置,如果s1中找不到s2,则返回0,将该判断再赋给y
- 分类操作
by x, sort: gen z = y[1] //按照x分组,生成一个新变量z=y的第一个观察值
bysort x: gen z = y[1]
bysort x(y): gen z = y[1] //按照x分组,分组后按照y排序,生成一个新变量z=y的第一个观察值
6. 程序
- 暂元
暂元是程序中的临时变量,分为暂元名和暂元内容两部分,类似于变量名和变量值
local v3 "price length weight" // 将price length weight 这组字符赋给暂元名v3
list `v3' in 1/5glocal v3 "price length weight" // 将price length weight 这组字符赋给暂元名v3
list $v3 in 1/5
global与local的区别
global为全局暂元,local为局域暂元
7. 流程语句
- 循环语句:
forvalues
forvalues i = 1/5 {
display `i'
}forvalues i = 4 (-0.2) 0 {
display `i'
}
- 循环语句:
foreach
按照变量循环
foreach v of varlist var1-var6 {
replace `v' = 0 if `v' == .
}
这篇关于实证分析 | STATA入门数据处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







