本文主要是介绍Reinforcement Learning for Solving the Vehicle Routing Problem,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Reinforcement Learning for Solving the Vehicle Routing Problem
这个工作开发了一个使用强化学习来解决大规模组合优化问题的框架,并将其应用到VRP问题中。为了这个目的,考虑使用Markov Decision Process来建模问题,最优解可以看做序列决策,这就可以使用通过RL来增加decode 期望序列的概率来产生次优解。一个天然的想法是通过考虑每个样本独立的来找到一个特定于问题的解。此外,所学习的策略不适用于除训练中使用的实例以外的实例; 计算对问题设置的干扰很小,也需要从头开始重建策略。
Pointer Network可以通过decode solution来解VRP问题,但是问题是其假设系统是静态的。但是实际中,需求随着时间改变,例如,一个节点被访问之后其需求变为0. 该方法可以同时处理静态和动态元素。在每一个时间步,静态元素的embedding作为RNN decoder的输入,RNN的输出和动态元素embedding送入到attention中,这形成了可以在下一个决策点选择的可行目标的分布。
提议的框架利用了一种自我驱动的学习过程,该过程仅需要基于生成的输出来计算奖励;只要可以观察到奖励并验证生成的序列的可行性,就可以学习所需的元算法。例如,如果一个人不知道如何解决VRP,但可以计算给定解决方案的成本,则可以使用的方法提供解决问题所需的信号。与大多数经典的启发式方法不同,它对问题的更改具有鲁棒性,这意味着当输入以任何方式更改时,它都可以自动调整解决方案。使用经典启发式方法进行VRP,必须重新计算整个距离矩阵,并且必须从头开始重新优化系统,这通常是不切实际的,尤其是在问题规模较大的情况下。相反,提出的框架不需要明确的距离矩阵,只有网络的前馈通道会根据新数据更新路线。
Neural Combinatorial Optimization
[32]介绍了指针网络Pointer Network的概念,该网络最初是受序列到序列模型启发的。 由于它不依赖于编码器序列的长度,因此指针网络使该模型能够应用于组合优化问题,其中输出序列的长度由源序列确定。 他们以有监督的方式使用Pointer Network体系结构,以从基础事实最佳(或启发式)解决方案中找到接近最佳的旅行推销员问题(TSP)旅行。 这种对监督的依赖使Pointer Network无法找到比训练期间提供的更好的解决方案。
The Model
给定一个输入集合: X = { x i , i = 1 , . . . , M } X=\{x^i, i=1,...,M\} X={xi,i=1,...,M}, 允许一些元素在decoding步骤中改变。VPR中,customer属于的需求可能会随着时间改变吗;如,已被访问过,新的客户到达,需求改变。将每个 输入 x i x_i xi表示为输入序列 { x t i = ( s i , d t i ) , t = 0 , 1 , . . . } \{x^i_t = (s^i, d_t^i), t=0,1,...\} {xti=(si,dti),t=0,1,...},其中 s i , d i s_i, d_i si,di分别为静态和动态元素, x i t x_i^t xit为输入i在时间t的状态。 s i s_i si为customer i的位置, d t i d_t^i dti为时间t的需求。 X t X_t Xt为时间所有输入状态。
从 X 0 X_0 X0中的任意输入开始,使用指针 y 0 y_0 y0引用该输入。 在每个
解码时间t(t = 0,1,…), y t + 1 y_{t+1} yt+1指向可用输入 X t X_t Xt之一,它确定下一解码器步骤的输入; 该过程一直持续到满足终止条件为止。
终止条件是特定于问题的,表明生成的序列满足可行性约束。 例如,在这项工作中考虑的VRP中,终止条件是没有更多需求可以满足。此过程将生成一个长度为T, Y = { y t , t = 0 , . . . , T } Y = \{y_t,t = 0,...,T\} Y={yt,t=0,...,T}的序列,该序列可能与输入长度M相比具有不同的序列长度。这是由于以下事实: 车辆可能必须多次返回仓库加满货物。 还使用符号 Y t Y_t Yt表示到时间t为止的解码序列,即 Y t = { y 0 , . . . , y t } Y_t =\{y_0,...,y_t\} Yt={y0,...,yt}。 找到一种随机策略 π π π,该策略以满足损失约束的同时最小化损失目标的方式生成序列 Y Y Y。 最优策略 π ∗ π^* π∗将以概率1生成最优解。目标是使 π π π尽可能接近 π ∗ π^* π∗。使用概率链规则分解生成序列 Y Y Y的概率,即 P ( Y ∣ X 0 ) P(Y | X_0) P(Y∣X0),如下所示:
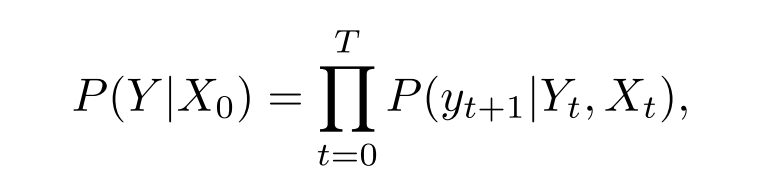
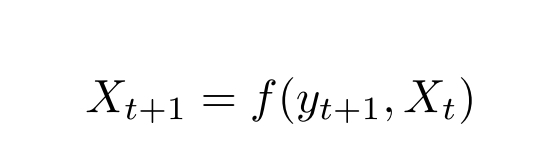
是使用状态转换函数f对问题表示的递归更新。
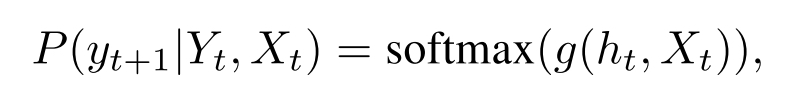
其中g是输出输入大小的向量的仿射函数, h t h_t ht是RNN解码器的状态,该状态汇总先前解码的步长 y 0 , . . . , y t y_0,...,y_t y0,...,yt。
该模型可以处理更经典的静态设置以及动态更改的组合优化问题。在静态组合优化中, X 0 X_0 X0完全定义了要解决的问题。例如,在VRP中, X 0 X_0 X0包括所有客户位置及其需求以及仓库位置。然后,剩余需求会根据车辆目的地及其负载进行更新。考虑到这一点,通常存在定义明确的马尔可夫转移函数f,如在(2)中定义的,足以更新决策点之间的动态。但是,模型也可以应用于状态转换函数未知和/或易受外部噪声影响的问题,因为训练并未明确使用转换函数。但是,了解此转换函数有助于模拟训练算法与之交互的环境。
Limitations of Pointer Networks

图1举例说明了为什么在编码器中使用RNN是限制性的。 假设在第一个决策步骤中,策略将车辆发送给客户1,结果满足了其需求,即 d 0 1 ? ≠ d 1 1 d^1_0?\neq d_1^1 d01?=d11<然后在第二个决策步骤中,需要使用新的d1重新计算整个网络以便选择下一个顾客。 动态元素使网络的前向传递变得复杂,因为当输入改变时,应该进行编码器/解码器更新。 在反向传播以累积梯度期间,情况甚至更糟,因为需要记住动态元素何时发生变化。 为了解决这种复杂性,要求模型对于输入序列是不变的,以便更改任何两个输入的顺序不会影响网络。 在第3.2节中,提出了一个满足此属性的简单网络。
The Proposed Neural Network Model
仅当输入传达顺序信息时,才需要RNN。 例如,在文本翻译中,必须捕获单词的组合及其相对位置,以使翻译准确。 但在输入集中没有有意义的顺序时,为什么需要在编码器中将它们用于组合优化问题? 例如,在VRP中,输入是一组未排序的客户位置及其各自的需求,它们的订单没有意义。 任何随机排列都包含与原始输入相同的信息。 因此,在的模型中,只需要忽略编码器RNN,而直接使用嵌入式输入而不是RNN隐藏状态。 通过这种修改,许多计算复杂性消失了,而没有降低模型的效率。

第一个是一组将输入映射到D维向量空间的嵌入。 可能有多个嵌入,它们对应于输入的不同元素,但它们在输入之间共享。 模型的第二个组件是一个解码器,它在每个解码步骤都指向一个输入。 使用RNN对解码器网络进行建模。 注意,将静态元素作为输入提供给解码器网络。 动态元素也可以是解码器的输入,但是在VRP上的实验并未提出任何改进建议,因此,动态元素仅用于attention层
Attention Mechanism
注意机制是一种用于处理输入的不同部分的可微结构。 图2说明了方法中使用的注意力机制。 在解码器的第i步,利用基于上下文的注意力机制来瞥一眼,使用可变长度对齐向量 a t a_t at从输入中提取相关信息。 换句话说, a t a_t at指定每个输入数据点在下一解码步骤 t t t中可能有多少相关。
其中 x ˉ t i = ( s ˉ i , d ˉ t i ) \bar{x}_t^i = (\bar{s}^i, \bar{d}^i_t) xˉti=(sˉi,dˉti)是embediing input i, h t ∈ R D h_t \in R^D ht∈RD是RNN cell在decoding step t的memory state,对齐向量 a t a_t at:
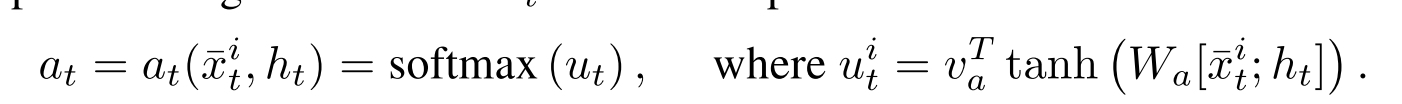
“;”:拼接向量,通过组合context vector c t c_t ct来计算条件概率:
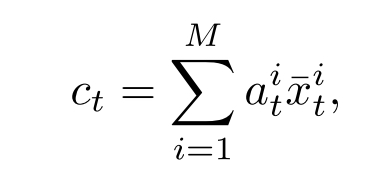
使用嵌入式输入,然后使用softmax函数将值归一化,如下所示:
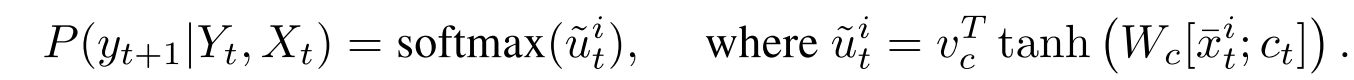
为了训练网络,使用了众所周知的策略梯度方法。 要使用这些方法,用参数θ参数化随机策略π。 策略梯度方法使用相对于策略参数的预期收益梯度的估计值来迭代地改进策略。 原则上,策略梯度算法包含两个网络:(i)一个参与者网络,该参与者网络在任何给定的决策步骤中预测下一个动作的概率分布;以及(ii)一个批评者网络,该批评者网络从给定的任何事件实例的给定状态估计奖励
Computational Experiment
假定车辆在时间0处位于仓库,因此解码器的第一个输入是仓库位置的嵌入。 在每个解码步骤,车辆将从客户节点或仓库中进行选择,以进行下一步。 在访问了客户节点i之后,需求和车辆负载更新如下:
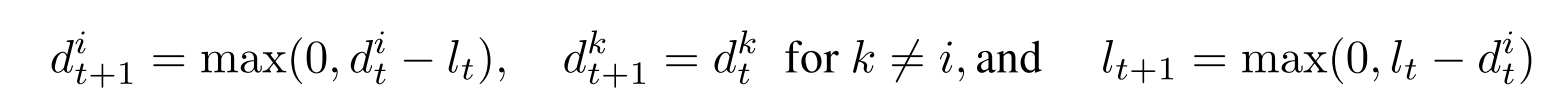
这是VRP状态转换函数(2)的明确定义。
在此实验中,采用了两种不同的解码器:(i)贪婪,其中在每个解码步骤中,选择概率最高的节点(客户或仓库)作为下一个目的地,以及(ii)波束搜索(BS) ),它会跟踪最可能的路径,然后选择行程最小的路径。结果表明,通过应用波束搜索算法,可以在仅稍微增加计算时间的情况下提高解决方案的质量。
为了更快地进行训练并生成可行的解决方案,使用了一种掩蔽方案,该方案将不可行解决方案的对数概率设置为-∞,或者在满足特定条件的情况下强制采用解决方案。在VRP中,使用以下mask程序:
- 不允许访问零需求的节点;
- 如果车辆的剩余负载正好为0,则所有客户节点都将被屏蔽;
- 掩盖了需求大于当前车辆负载的客户。请注意,在这种掩盖方案下,车辆在访问时必须满足客户的所有需求。但是注意到,如果建模的情况允许分批交货,则可以放宽条件。的确,宽松的掩蔽允许分批交货,因此该解决方案可以将给定客户的需求分配到多条路线中。实际上,此属性是一种吸引人的行为,在许多实际应用程序中都存在,但是在经典VRP算法中经常被忽略。在下一部分的所有实验中,不允许拆分需求。
这篇关于Reinforcement Learning for Solving the Vehicle Routing Problem的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






