本文主要是介绍统计推断——假设检验——基于秩次的非参数检验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、配对资料的符号秩和检验
1、参数检验对比非参数检验
1.1、参数检验的定义:
在总体分布类型已知(如正态分布)的条件下,对其未知参数检验。
如 检验和方差分析,都是基于总体分布为正态分布、总体方差相等的前提下对总体均数进行的检验。
1.2、非参数检验的定义:
若总体分布未知或已知总体分布与检验所要求的条件不符,经数据转换也不能使其满足参数检验的条件,这时需要采用一种不依赖于总体分布形式的检验方法。这种方法不是对参数进行检验,而是检验总体分布位置是否相同,因而称为非参数检验(nonparametric test)。
1.3、非参数检验的适用条件:
1. 总体分布类型不明
2. 总体分布呈偏态分布
3. 数据一端或两端有不确定值的资料
4. 总体方差不齐
5. 有序分类变量资料
注意点:
1.非参数检验是不依赖总体分布类型,也不对总体参数进行推断的一类统计方法。
2.非参数检验不受总体分布的限制,适用范围广,但对服从参数检验条件的资料采用非参数检验进行分析时,会降低检验效能,增加犯II类错误的概率。
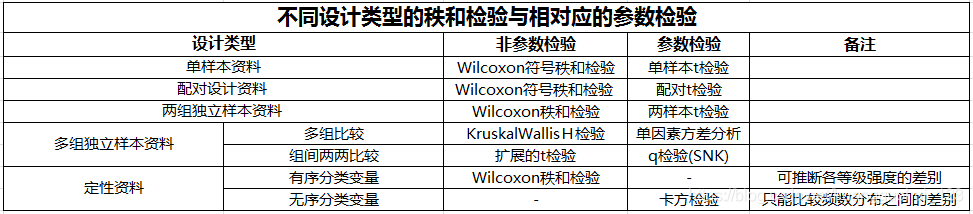
3.有序分类变量资料选用非参数检验,可推断各等级强度的差别,而用R×C列联表检验,只能比较频数分布之间的差别(卡方检验能够证明两个群组之间存在差异,但是不能揭示这个差异是什么)。
2、基于秩次的非参数检验
秩和检验(rank sum test),是一类常用的非参数检验。
秩和检验是首先将数据按从小到大,或等级从弱到强转换成秩后,再求秩和,计算检验统计量——秩和统计量,做出统计推断。
2.1、配对资料的符号秩和检验
例 对11份工业污水测定氟离子浓度(mg/L),每份水样同时采用电极法及分光光度法测定,结果见表。问就总体而言,这两种方法的测定结果有无差别?
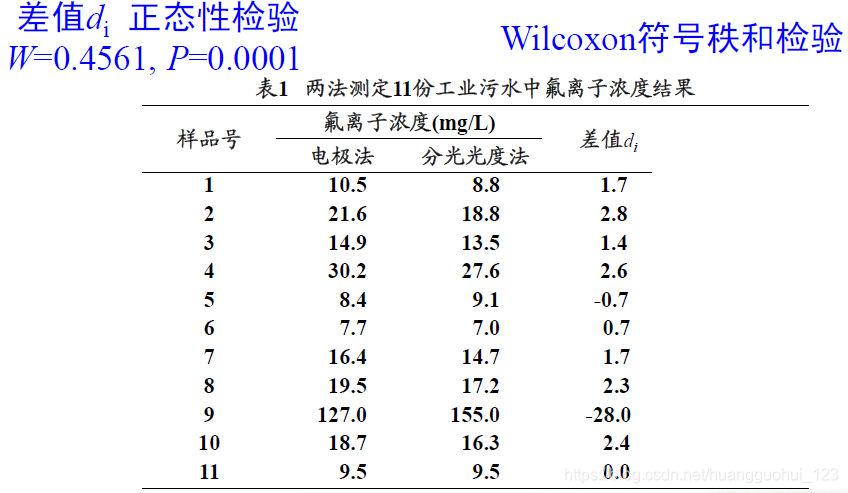
注意:首先需要进行正态性检验(对差值进行正态性检验),这边我们运用到的是Shapiro–Wilk W检验,详细介绍可见《统计推断——正态性检验》。得到
=0.4561,
=0.0001,则差值
不符合正态分布,则不能使用配对
检验进行分析。
Wilcoxon符号秩和检验
1. 建立检验假设,确定检验水准
:差值的总体中位数等于0
:差值的总体中位数不等于0
2. 计算检验统计量值
(1) 求差值d
(2) 编秩:依差值的绝对值由小到大编秩 ; 差值为0,不编秩,且总的对子数相应减少;差值的绝对值相等,称为相持(tie),取平均秩。
| 样本号 | 氟离子浓度(mg/L) | 差值di | 差值di的绝对值 | 秩次-排序号 | 秩次-平均秩次 | 秩次-最终(加正负) | T+ | T- | |
| 电极法 | 分光光度法 | ||||||||
| 1 | 10.5 | 8.8 | 1.7 | 1.7 | 4 | 4.5 | 4.5 | 43.5 | -11.5 |
| 2 | 21.6 | 18.8 | 2.8 | 2.8 | 9 | 9 | 9 | ||
| 3 | 14.9 | 13.5 | 1.4 | 1.4 | 3 | 3 | 3 | ||
| 4 | 30.2 | 27.6 | 2.6 | 2.6 | 8 | 8 | 8 | ||
| 5 | 8.4 | 9.1 | -0.7 | 0.7 | 1 | 1.5 | -1.5 | ||
| 6 | 7.7 | 7 | 0.7 | 0.7 | 2 | 1.5 | 1.5 | ||
| 7 | 16.4 | 14.7 | 1.7 | 1.7 | 5 | 4.5 | 4.5 | ||
| 8 | 19.5 | 17.2 | 2.3 | 2.3 | 6 | 6 | 6 | ||
| 9 | 127 | 155 | -28 | 28 | 10 | 10 | -10 | ||
| 10 | 18.7 | 16.3 | 2.4 | 2.4 | 7 | 7 | 7 | ||
| 11 | 9.5 | 9.5 | 0 | 0 | - | - | - | ||
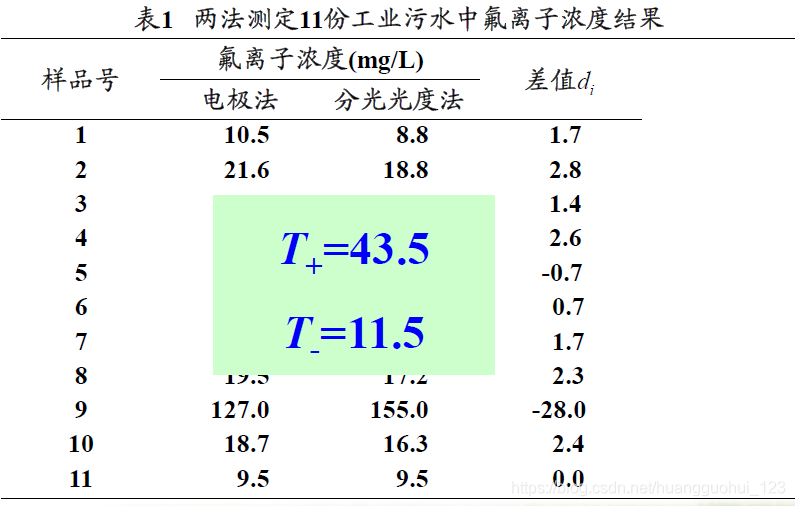
| 编秩步骤: 1、先求差值di,并且di的绝对值,再升序排序。 2、排除差值di等于0,不参与编秩,总体的对子数也应该相应减少。 3、对差值相等的样本取平均秩次,如样本5和样本6,di的绝对值均为0.7,所以取平均秩次:(1+2)/2=1.5。 4、根据差值di的正负号,赋予秩次正负号。 5、正负秩分别相加求和:T+=43.5,T-=11.5。 | |||||||||
(3) 分别求正、负秩和:=43.5,
=11.5
(4) 确定统计量:
=43.5或
=11.5(统计量取这两个数中的任意一个数均可)
3. 确定P值,做出推断
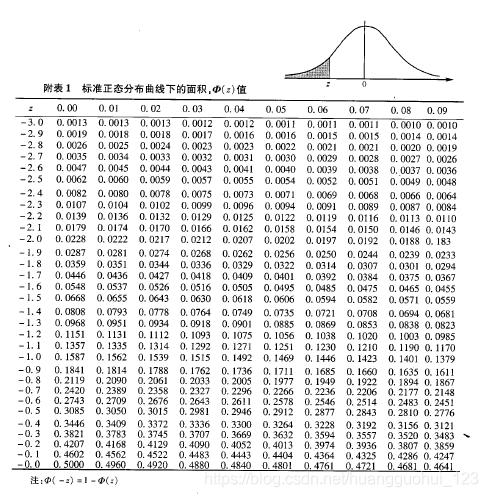
(1) 查表法(≤50)
根据(非零对子数)和
值,查
界值
由=10(第11份样本
,不参与统计),
=11.5或
=43.5,查表,得双侧
>0.10。按照
=0.05水准不拒绝
,故据此资料尚不能认为两法测定结果有差别。
Wilcoxon配对符号秩和检验的基本思想
在配对样本中,由于随机误差的存在,各对差值的产生不可避免,假定两种处理的效应相同,则差值的总体分布为对称分布,并且差值的总体中位数为0。若此假设成立,样本差值的正秩和与负秩和应相差不大,均接近 (总秩和的一半),即
仅为抽样误差所致;当正负秩和相差悬殊,超出抽样误差可解释的范围时,则有理由怀疑该假设,从而拒绝
。
以下是总秩和的计算公式,其中表示非零对子数(即
不为0),注意:此处的总秩和表示
和
绝对值之和。
(2) 正态近似法(>50):作正态近似检验
当>50时,
统计量服从均数为
,标准差为
的正态分布。这个时候我们可以用以下公式做正态近似检验,其中,
表示计算出来的当前统计量,
表示非零对子数,0.5表示连续性校正系数。当相持的情况较多的时候,则计算出来的
统计量会偏小,需要校正,
表示第
次相持的个数,如上面,第一次相持为0.7,相持的个数为2,第二次相持为1.7,相持的个数也为2。

二、两组独立样本比较的秩和检验
推断连续型变量资料或有序分类变量资料的两个独立样本代表的两个总体分布是否有差别
1、两组连续型变量资料的秩和检验
例 用两种药物杀灭钉螺,采集了14批活钉螺,随机分为两组分别用甲、乙药物,用药后清点钉螺的死亡数,并计算每批钉螺的死亡率(%),结果见表。问两种药物杀死钉螺的效果有无差别?
Wilcoxon秩和检验
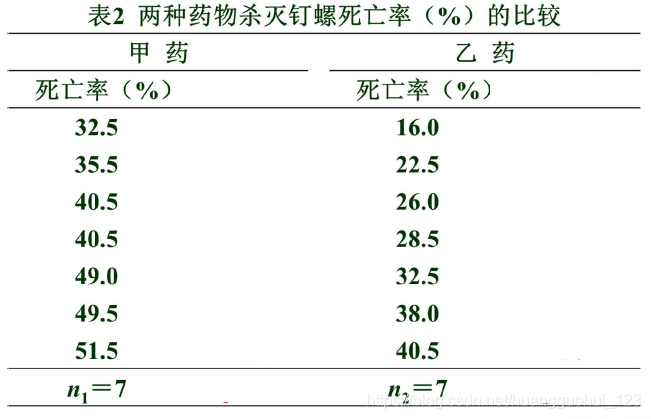
注意:在以上两个独立样本当中,由于样本的例数太小,数据分布的类型难以判断,这边我们使用非参数检验的wilcoxon秩和检验进行分析。
1. 建立检验假设,确定检验水准
:两种药物杀灭钉螺死亡率的总体中位数相等
:两种药物杀灭钉螺死亡率的总体中位数不相等
2. 计算检验统计量值
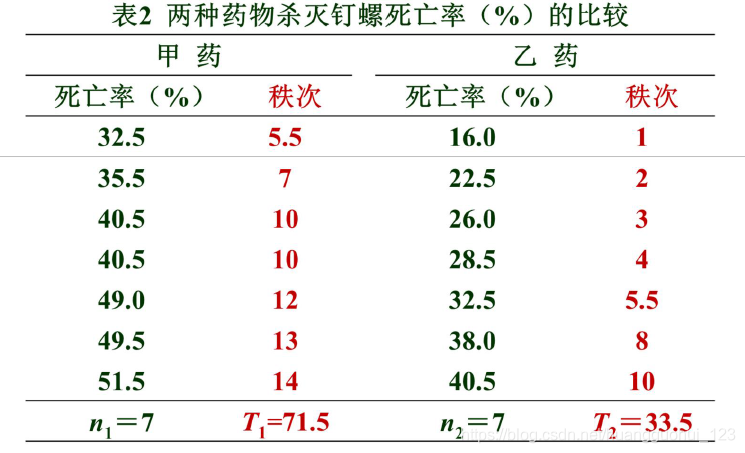
(1) 编秩:将两组数据混合,由小到大统一编秩;不同组遇到相同数据取平均秩次。
(2) 求各组秩和:以样本例数较小者为,其秩和为
。
(3) 确定统计量:若
,则
,若
,则
,若
,则
或者
3. 确定P值,做出推断
(1) 查表法
当≤10,且
≤10时,查
界值表。
双侧0.01<<0.02 (查表口诀:内大外小,如果当前统计量
值位于查表的
界值之内,则
值大于相应的概率值
,如果当前统计量
值位于查表的
界值之外,则
值小于相应的概率值
),界值表可看文末附表。
按照=0.05水准,拒绝
,可以认为两种药物杀灭钉螺的效果有差别。
Wilcoxon秩和检验的基本思想
假设含量为与
的两个样本(
),来自同一总体或分布相同的两个总体,则
样本的秩和
与其理论秩和
(当
,则为
)相差不大,即
仅为抽样误差所致。当二者相差悬殊,超出抽样误差可解释的范围时,则有理由怀疑该假设,从而拒绝
。
(2)正态近似法
以下公式,表示计算出来的当前统计量,0.5表示连续性校正系数,
表示第
次相持的个数,如上面,第一次相持为32.5,相持的个数为2,第二次相持为40.5,相持的个数也为3。

2、两组有序分类变量资料的秩和检验
例 某医科大学营养教研室为了解居民体内核黄素营养状况,于某年夏冬两个季节收集成年居民口服5mg核黄素后4小时的负荷尿,测定体内核黄素含量,结果见表,试比较该地居民夏冬两个季节体内核黄素含量有无差别?
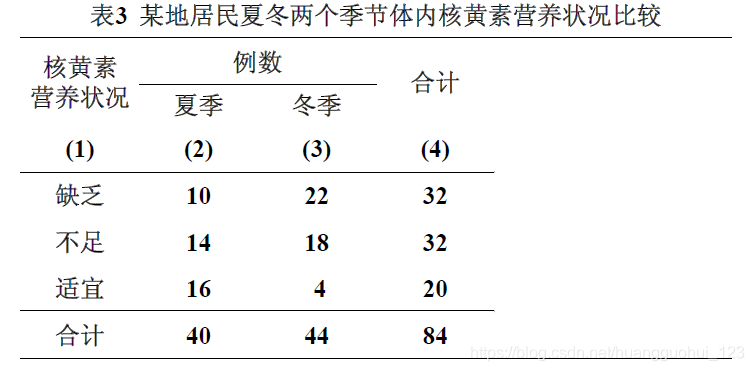
1. 建立检验假设,确定检验水准
:夏冬两个季节居民体内核黄素含量的,总体分布位置相同
:夏冬两个季节居民体内核黄素含量的,总体分布位置不同
2. 计算检验统计量值
(1) 编秩:将两组数据合并,按等级由小到大统一编秩。先计算各等级合计数,并确定各等级秩次范围,求出各等级的平均秩次。
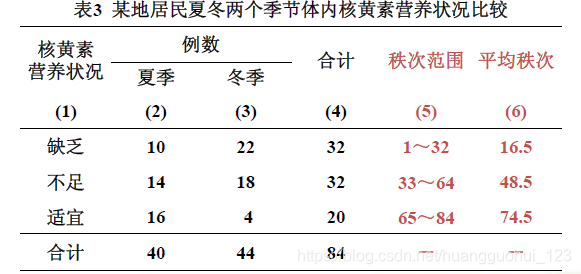
例如:“缺乏”平均秩次为(1+32)/2=16.5。
(2) 求各组秩和:各等级的平均秩次分别乘以各组在各等级的例数,再求和,即得到各组秩和。
,
,
(3) 确定统计量值:若
,则
,若
,则
,若
,则
或者
。
则。
3. 确定P值,做出推断
=40,超出
界值表的使用范围,用正态近似法。其中,
表示第
次相持的个数,三次次相持个数分别为32,32,20,
表示校正后的
值。
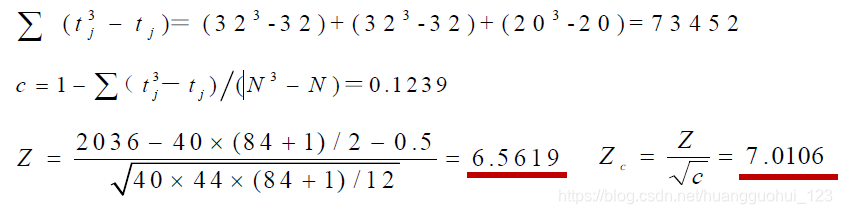
查标准正态分布表可知,<0.001。按照
=0.05水准,拒绝
,接受
,故可认为夏冬两个季节居民体内核黄素含量有差别。
三、多组独立样本比较的秩和检验
1、定量变量多组独立样本的秩和检验(Kruskal-Wallis H检验)
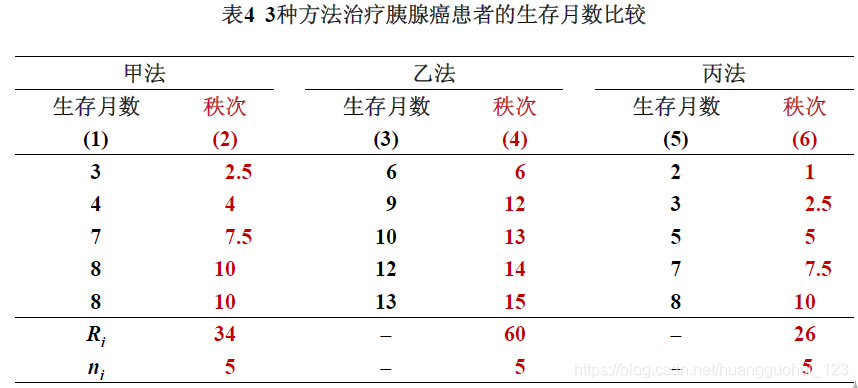
例4 某医院用3种不同方法治疗15例胰腺癌患者,每种方法各治疗5例。治疗后生存月数见表,问这3种方法对胰腺癌患者的疗效有无差别?
根据日常经验:生存时间是不符合正态分布的。

1. 建立检验假设,确定检验水准
:3种方法治疗后患者生存月数的总体中位数相等
:3种方法治疗后患者生存月数的总体中位数不全相等
2. 计算检验统计量值
(1) 编秩 将三组数据合并,其余步骤同两组定量变量资料
(2) 求各组秩和:
,
,
(3) 确定检验统计量值 :
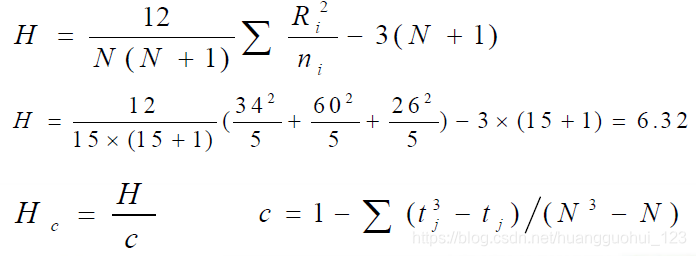
算出 。
3. 确定值,做出推断
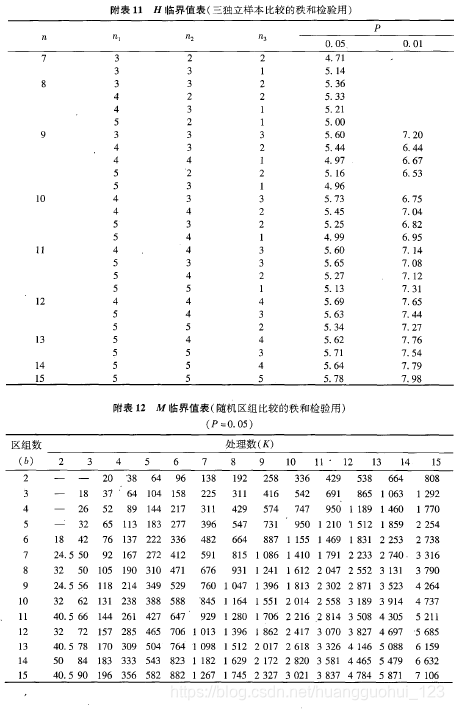
(1) 查界值表
当组数=3,且各组例数
时,可查
界值表得到
值。
,
<0.05。按照
=0.05水准,拒绝
,接受
,故可认为3种方法治疗后胰腺癌患者的生存月数有差别。
(2) 查界值表
当组数或各组例数超出界值表时,由于
成立时
值近似地服从
的
分布(
表示组数),此时可由
界值表得到
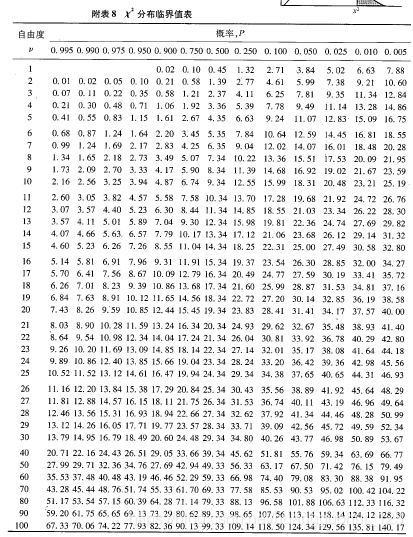
值。
2、有序变量多组独立样本的秩和检验
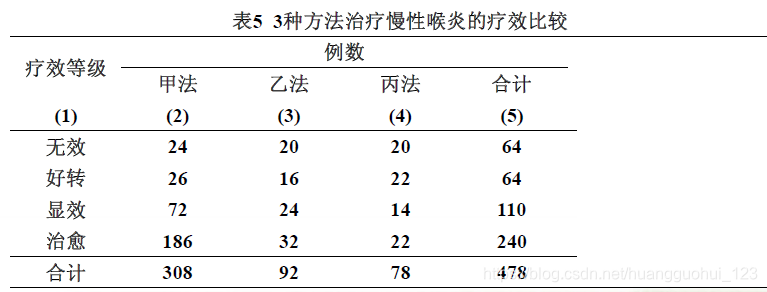
例 某医院用3种方法治疗慢性喉炎,结果见表,问这3种方法的疗效是否有差别?
1. 建立检验假设,确定检验水准
:3种治疗方法治疗效果的总体分布位置相同
:3种治疗方法治疗效果的总体分布位置不全相同
2. 计算检验统计量值
(1) 编秩 同两组有序分类变量资料
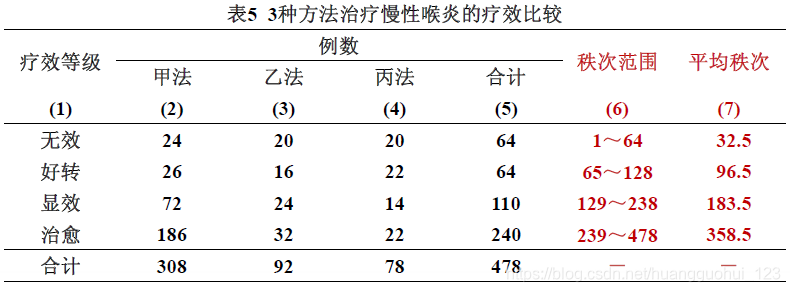
(2) 求各组秩和:各组各等级的频数与平均秩次的乘积之和。
(3) 确定检验统计量值 :
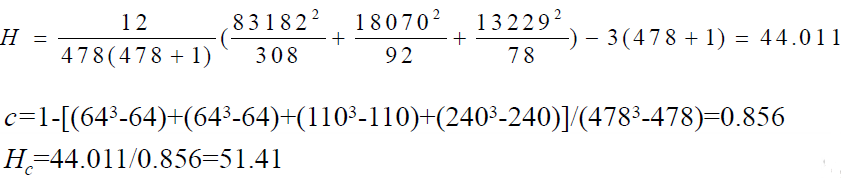
3. 确定值,做出推断
=3,各组例数均大于5,可由
查
界值表,得
<0.005。按照
=0.05水准,拒绝
,接受
,故可认为3种方法治疗慢性喉炎的效果有差别。
3、多个独立样本间的多重比较
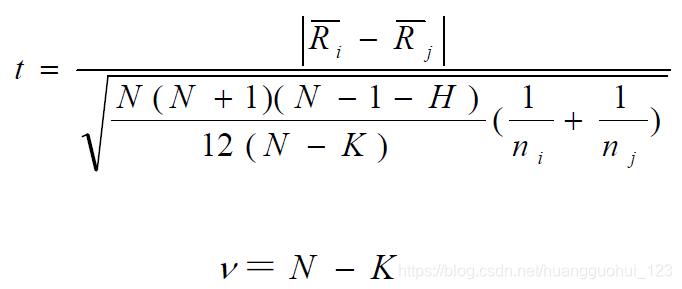
和
分别表示两对比组各自的平均秩次,
和
分别表示两对比组的样本量,
和
分别表示为总体处理的
值和组数,注意,K不是2。
例 对例5资料做三个样本间的两两比较。
1. 建立检验假设,确定检验水准
:第
种与第
种方法疗效的总体分布位置相同
:第
种与第
种方法疗效的总体分布位置不同
2. 计算检验统计量值
(1) 求各组平均秩次,注意,此处和上面各疗效的平均秩次是不一样的。
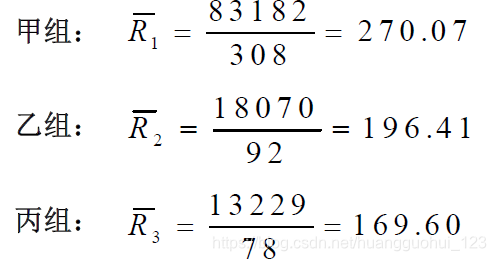
(2)列出两两比较计算表,求得值
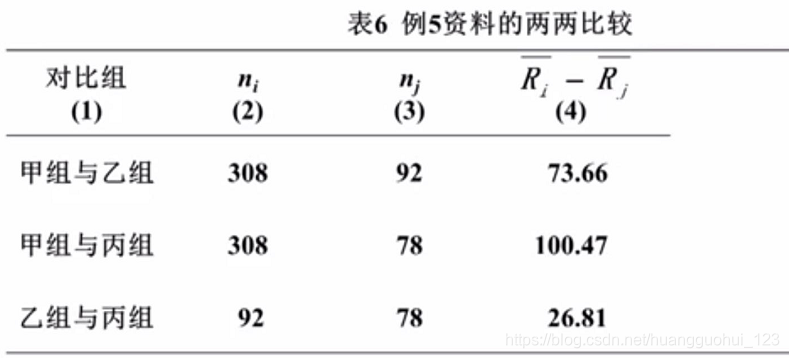
基于以上的值,我们可以计算出甲组和乙组的值。

同理可以算出其余对比组的值。
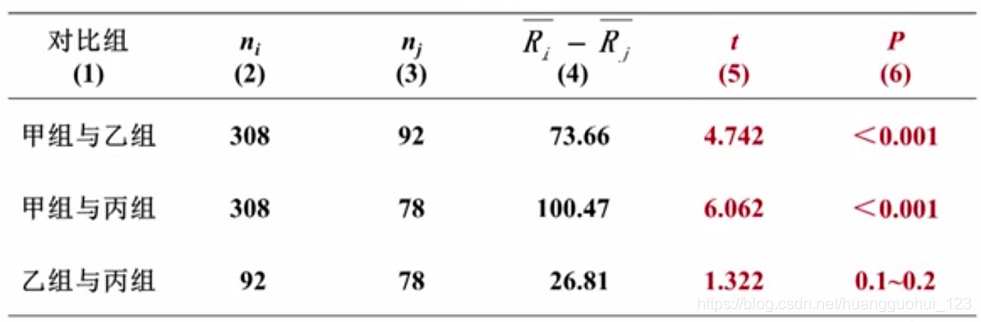
3. 确定值,做出推断
以(三组自由度相同)查
界值表,得
值。按照
=0.05水准,甲组与乙组、甲组与丙组比较,均拒绝
;而乙组与丙组比较不拒绝
,故可认为3种方法治疗慢性喉炎疗效的差别主要存在于甲法与其他两法之间,而乙法与丙法间的疗效尚不能认为有差别。
【附表】


这篇关于统计推断——假设检验——基于秩次的非参数检验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



