本文主要是介绍十大数据可视化站点 改变审视世界角度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、全球黑客活动
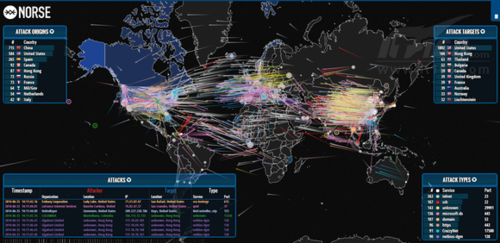
从黑客活动开始踏上可视化数据工具体验之旅。这份迷人的地图由安全供应商Norse打造,其本质是一套反映全球范围内黑客攻击频率的快照。它利用Norse的“蜜罐”攻击陷阱显示出所有实时渗透攻击活动。(稍等一会儿,DDoS攻击就会点亮你的屏幕!)闪光的霓虹线段与炫丽的彩虹配色营造出了互联网时代下的科技战争氛围。
不过大家别被眼前的美景所迷惑,每一条线代表的都是一次攻击活动,借此可以了解每一天、每一分钟甚至每一秒世界上发生了多少次恶意渗透。全球实际攻击活动总量要远远高于这份地图所能显示的结果——怎么样,有没有觉得很可怕?
官方网站:http://map.ipviking.com/?_ga=1.106938115.1477390587.1388686673
二、实时推文
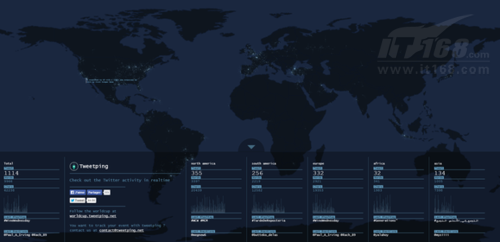
下面再来看点温和的内容,Twettping.net提供的地图显示出目前全球范围内实时发出的推文信息,每一条个人推文都会在地图上点亮一个仅仅闪光几秒的光点,随后又会有更多光点陆续亮起。热点地图显示出世界上哪些地区推文发送活动最为活跃。屏幕下方的统计数据显示的是这些长度为140字节的文本来自何方、最后记录下的@回复与摘要标签。
Tweetping地图看得久了有种强烈的催眠效果,通过观察可以感受到社交媒体网络到底有多受欢迎。就在我查看的这段时间里,该站点每分钟追踪到的推文数量已经超过了3500条。
官方网站:http://tweetping.net/
三、#HashtagsFTW
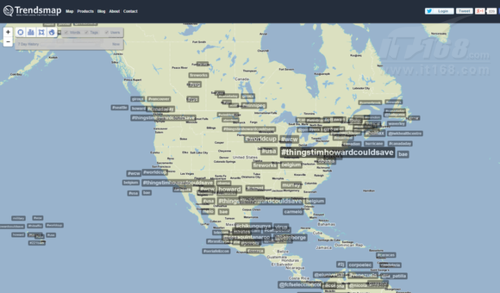
那么这些推文到底在聊些什么内容?Trendsmap能够显示目前世界范围内正在进行的讨论话题,并以地图形式向用户展示。摘要标签的涵盖范围越广,参与讨论的人数就越多。Trendsmap还拥有一些独特的功能,例如旧金山有哪些Twitter用户实际来自非洲——大家甚至可以在回家的路上了解全世界对于某条新闻的反应。
官方网站:http://trendsmap.com/
四、Digital Shadow
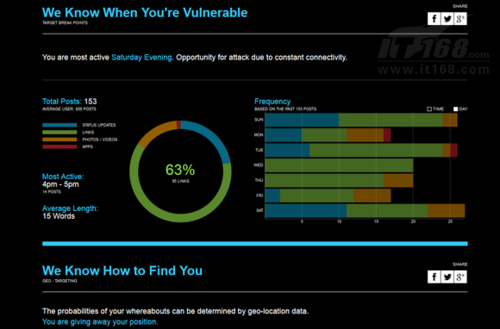
并不是所有社交共享内容都安全无忧。为了给《看门狗》这款游戏造势,育碧用Digital Shadow演示了在获得Facebook账户访问权限之后、他们能从应用里提取到多少个人信息。
在允许Digital Shadow访问我们的个人账户后,它会深入挖掘并显示所有获取到的数据:用户最亲近的好友、用户职业、用户当前位置、最常使用的词汇以及发布动态的时间、朋友们最常购买的商品、用户的年龄与教育背景、甚至包括个人的实际价值。如果下一次有应用想要与大家的Facebook账户相关联,请慎重考虑自己的决定。
官方网站:https://digitalshadow.com/
五、数据无处不在
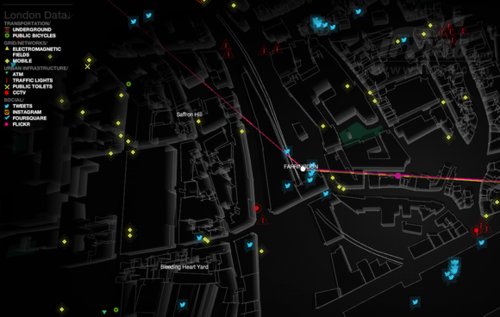
又一个与《看门狗》紧密相关的网站——We Are Data,旨在显示用户能够在公共环境中所能查找到的全部公开数据。We Are Data能够提供来自柏林、巴黎以及伦敦各个街区上细致入微的具体信息。该站点可以显示出当前所有用户的具体位置与操作活动,其范围涵盖Twitter、Foursquare、Instagram、Flicker、开放移动线路、交通指示灯、闭路电视与ATM机位置外加明显的电磁区域。更可怕的是,就连列车的实时位置也会随着其行进而在轨道上不断改变。
点击某个Twitter图标即可查看来自特定位置的个人用户的姓名与特定推文内容,这实在让人有些不寒而慄。We Are Data的目的正是向我们演示获取这些数据有多么轻松。
作者:王玉圆
来源:IT168
原文链接:十大数据可视化站点 改变审视世界角度
这篇关于十大数据可视化站点 改变审视世界角度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







