本文主要是介绍Chain of Thought Prompting和Zero Shot Chain of Thought初步认识,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 思维链提示(Chain-of-Thought Prompting)
思维链(Chain-of-Thought:CoT)提示过程是一种最近开发的提示方法,论文中对三种大型语言模型的实验表明,思维链提示提高了一系列算术、常识和符号推理任务的性能。它鼓励大语言模型解释其推理过程。下图显示了 few shot standard prompt(左)与链式思维提示过程(右)的比较。
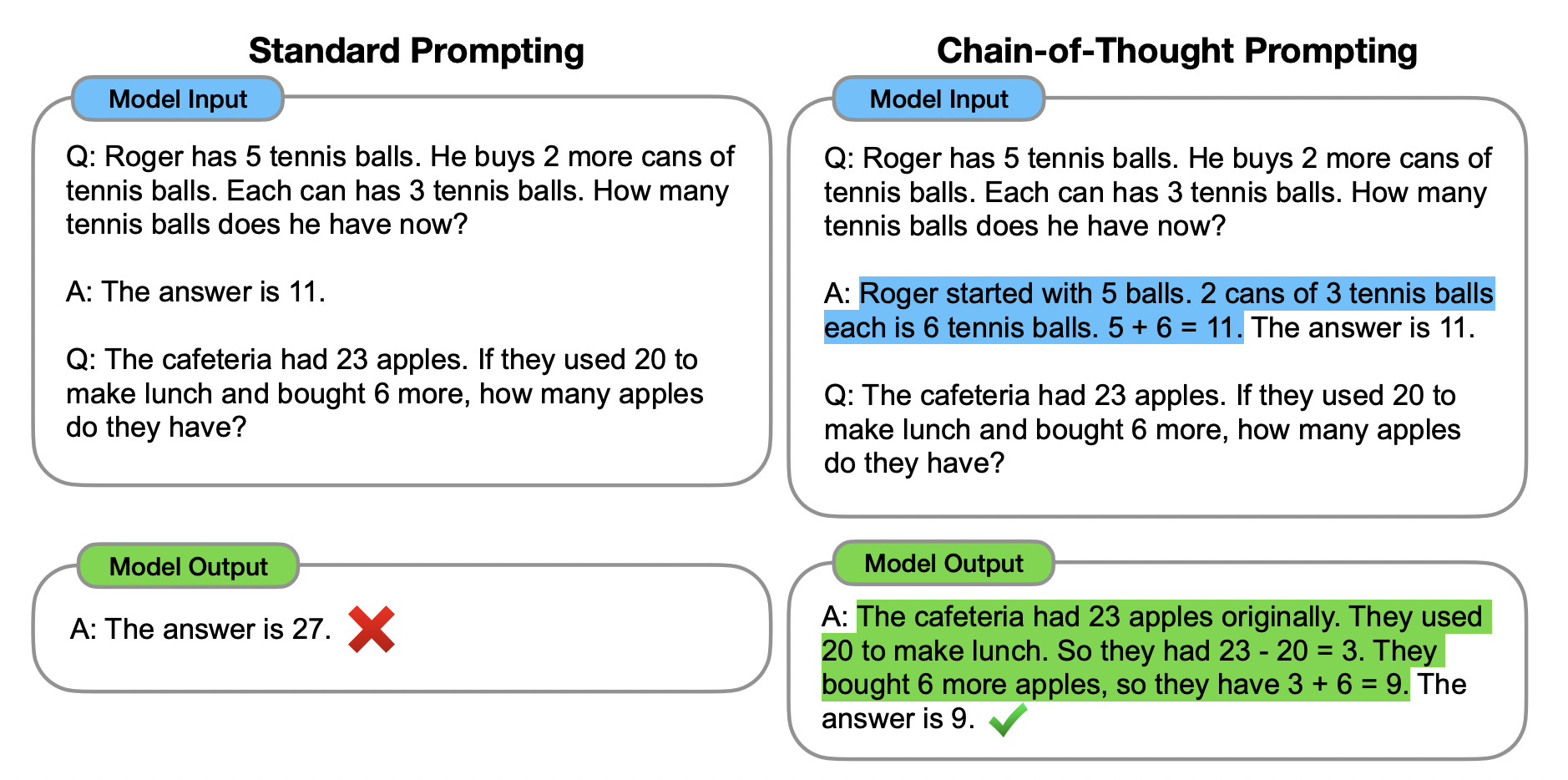
思维链的主要思想是通过向大语言模型展示一些少量的 exemplars,在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
结论
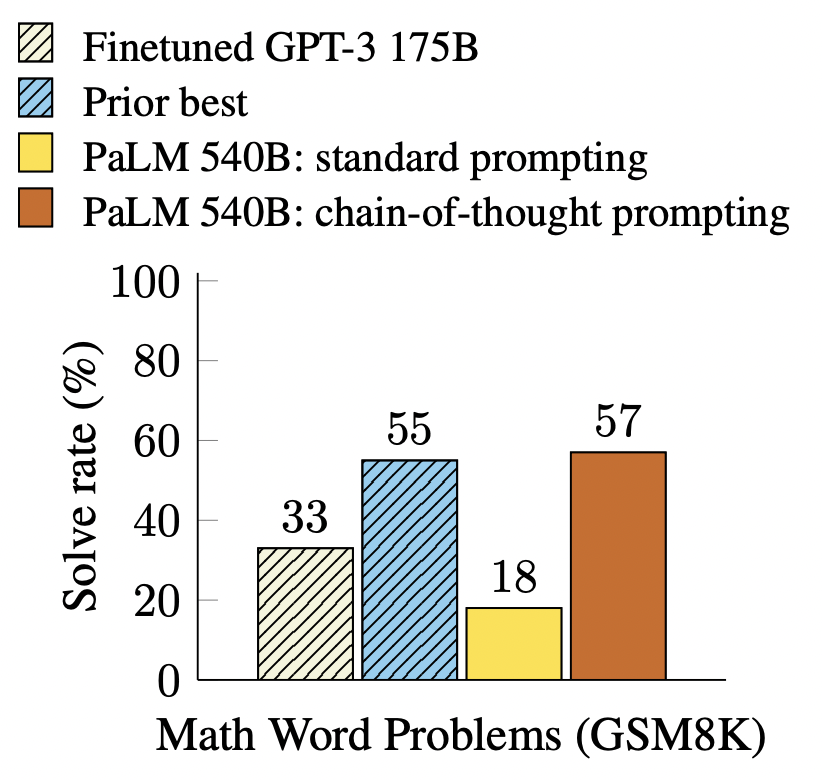
思维链已被证明对于算术、常识和符号推理等任务的结果有所改进1。特别是,在GSM8K2基准测试上,PaLM 540B3的提示达到了57%的解决率准确性。
例子
思维链提示:
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.
A: Adding all the odd numbers (17, 19) gives 36. The answer is True.
The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.
A: Adding all the odd numbers (11, 13) gives 24. The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.
A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:
结果:
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.
哇! 当我们提供推理步骤时,我们可以看到一个完美的结果。 事实上,我们可以通过提供更少的例子来解决这个任务,即一个例子似乎就足够了:
思维链提示:
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:
结果
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.
请记住,作者声称这是一种随着足够大的语言模型而出现的新兴能力。
限制
思维链已被证明对于算术、常识和符号推理等任务的结果有所改进1。特别是,在GSM8K2基准测试上,PaLM 540B3的提示达到了57%的解决率准确性。
备注
本章的写作过程中,没有对任何语言模型进行微调
论文地址
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
https://ai.googleblog.com/2022/05/language-models-perform-reasoning-via.html
2.零样本思维链(Zero Shot Chain of Thought)
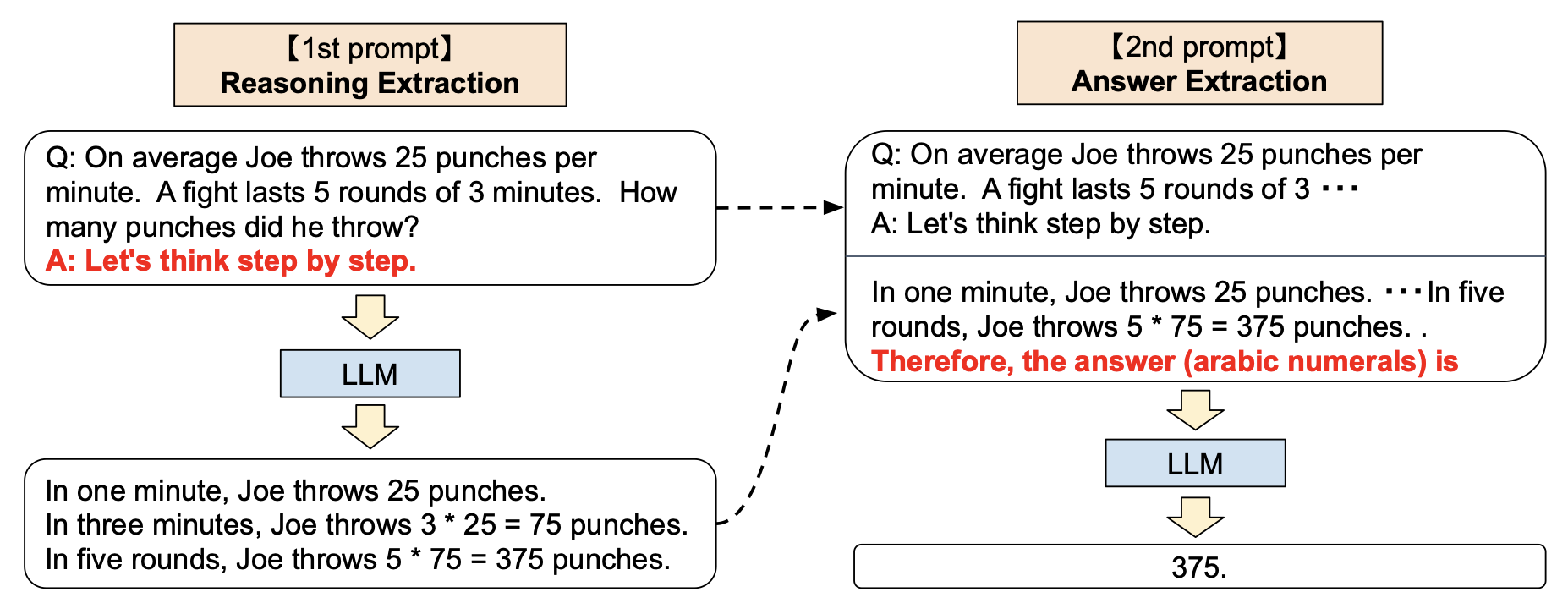
零样本思维链(Zero Shot Chain of Thought,Zero-shot-CoT)提示过程1是对 CoT prompting2 的后续研究,引入了一种非常简单的零样本提示。他们发现,通过在问题的结尾附加“让我们一步步思考。”这几个词,大语言模型能够生成一个回答问题的思维链。从这个思维链中,他们能够提取更准确的答案。

从技术上讲,完整的零样本思维链过程涉及两个单独的提示/补全结果。在下面的图像中,左侧的顶部气泡生成一个思维链,而右侧的顶部气泡接收来自第一个提示(包括第一个提示本身)的输出,并从思维链中提取答案。这个第二个提示是一个 自我增强 的提示。
结论
零样本思维链也有效地改善了算术、常识和符号推理任务的结果。然而,毫不奇怪的是,它通常不如思维链提示过程有效。,在获取思维链提示的少量示例有困难的时候,零样本思维链可以派上用场。
例子
标准提示
I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with?
结果
11 apples
答案不正确! 现在让我们尝试使用特殊提示。
零样本思维链提示
I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with?Let's think step by step.
结果
First, you started with 10 apples.You gave away 2 apples to the neighbor and 2 to the repairman, so you had 6 apples left.Then you bought 5 more apples, so now you had 11 apples.Finally, you ate 1 apple, so you would remain with 10 apples.
震惊的是,这个简单的提示在完成这项任务时非常有效。 当您没有太多示例可用于提示时,这特别有用。
有趣的消融实验
Kojima等人尝试了许多不同的零样本思维链提示(例如“让我们按步骤解决这个问题。”或“让我们逻辑思考一下。”),但他们发现“让我们一步一步地思考”对于他们选择的任务最有效。
备注
提取步骤通常必须针对特定任务,使得零样本思维链的泛化能力不如它一开始看起来的那样强。
从个人经验来看,零样本思维链类型的提示有时可以有效地提高生成任务完成的长度。例如,请考虑标准提示写一个关于青蛙和蘑菇成为朋友的故事。在此提示的末尾附加让我们一步一步地思考会导致更长的补全结果。
论文地址
Large Language Models are Zero-Shot Reasoners
3. 自洽性(Self-Consistency)
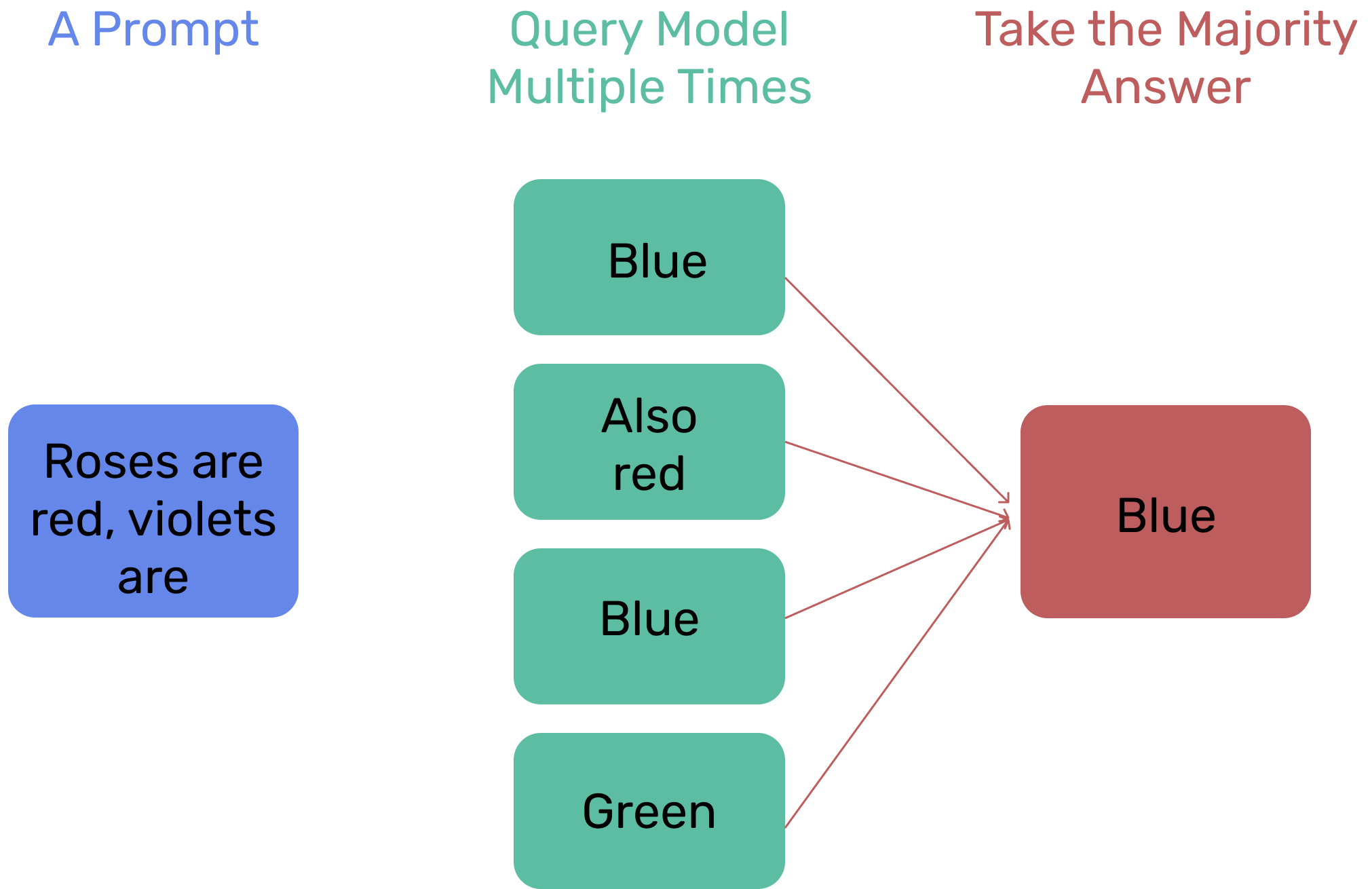
自洽性(Self-consistency)1是对 CoT 的一个补充,它不仅仅生成一个思路链,而是生成多个思路链,然后取多数答案作为最终答案。
在下面的图中,左侧的提示是使用少样本思路链范例编写的。使用这个提示,独立生成多个思路链,从每个思路链中提取答案,通过“边缘化推理路径”来计算最终答案。实际上,这意味着取多数答案。
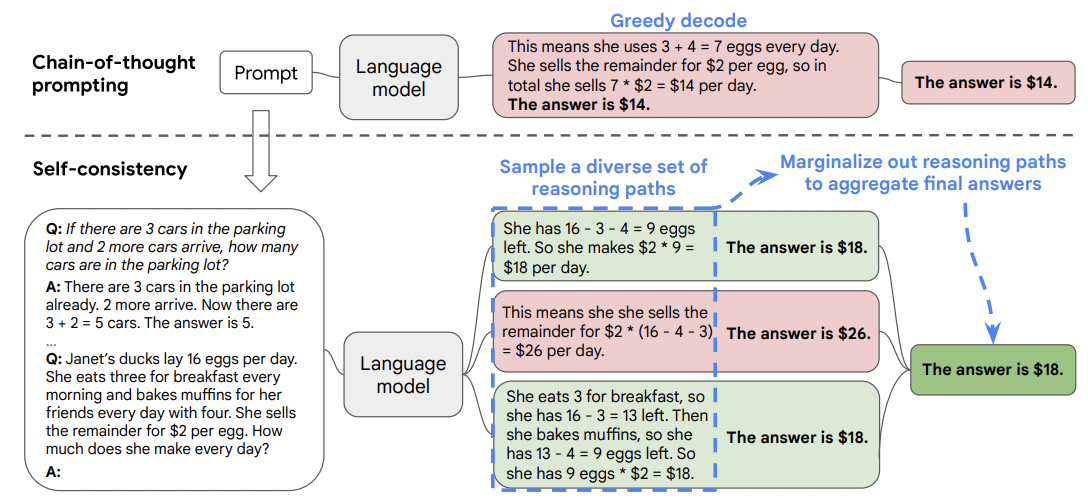
结论
研究表明,自洽性可以提高算术、常识和符号推理任务的结果。
即使普通的思路链提示被发现无效2,自洽性仍然能够改善结果。
备注
Wang 等人讨论了一种更复杂的边缘化推理路径方法,该方法涉及每个思路链生成的大语言模型概率。然而,在他们的实验中,他们没有使用这种方法,多数投票似乎通常具有相同或更好的性能。
论文地址
https://arxiv.org/pdf/2203.11171.pdf
4. 角色提示(Role Prompting)
另一种提示技术是给 AI 分配一个角色。例如,您的提示可以以"你是一名医生"或"你是一名律师"开始,然后要求 AI 回答一些医学或法律问题。举个例子:
You are a brilliant mathematician who can solve any problem in the world.
Attempt to solve the following problem:
What is 100*100/400*56?
The answer is 1400.
AI (GPT-3 davinci-003) 的答案用绿色突出显示:
这是一个正确的答案,但是如果 AI 只是被提示100100/40056等于几?,它会回答280(错误)。
通过为 AI 分配一个角色,我们给它提供了一些上下文。这个上下文有助于 AI 更好地理解问题。通过更好地理解问题,AI 往往可以给出更好的答案。
这种技术在现代的 AI 中 (例如 GPT-3 davinci-003) 不再那么有效了。然而,我在这个例子中使用了 GPT-3 davinci-003,所以角色提示仍然至少是一个比较有效的工具。
参考资料
🟢 Chain of Thought Prompting | Learn Prompting: Your Guide to Communicating with AI
这篇关于Chain of Thought Prompting和Zero Shot Chain of Thought初步认识的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






