本文主要是介绍POSIT-DRMM(18’Google),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Deep Relevance Ranking Using Enhanced Document-Query Interactionshttps://github.com/nlpaueb/deep-relevance-ranking.
Introduction
在DRMM(它使用对上下文不敏感的术语编码和查询-文档术语交互)的基础上,整个模型中注入了丰富的对上下文敏感的编码。并研究了多种变体。都为基于交互的神经检索模型。
预备知识
DRMM(匹配直方图):
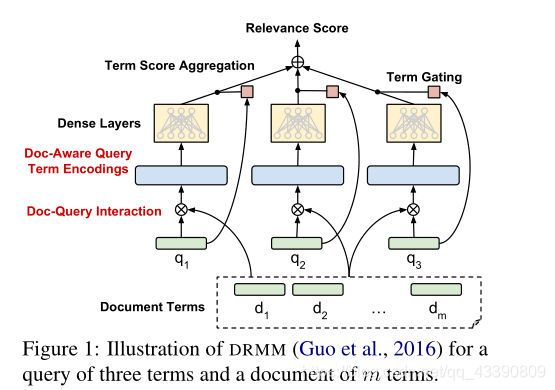
PACRR和PACRR-DRMM
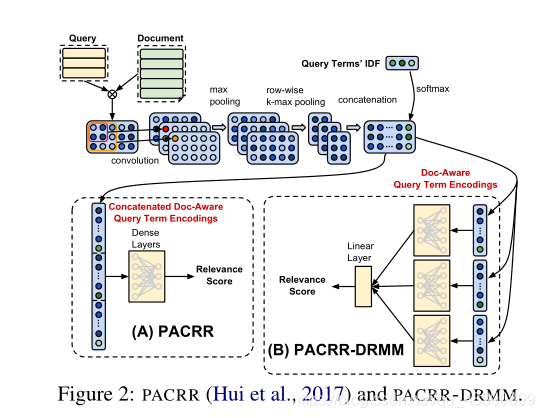
PACRR:首先计算q和d的相似度矩阵,然后卷积—max pooling----按行取k-max pooling—形成多个(filter的数量)矩阵—将所有矩阵行进行连接送入Dense layers—得到匹配得分
PACRR-DRMM:将每一行用一个独立的MLP评分,最后通过线性层汇总
ABEL-DRMM
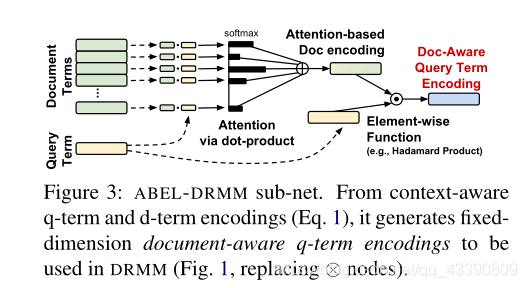
Context-sensitive Term Encodings
与PACRR不同,ABEL-DRMM将交互信息融入在编码之后,具体地:
首先使用Bi-LSTM编码q和d(pre-train embedding),然后将原始编码和输出的隐藏状态结合,作者认为这个空间中的相似性已经是上下文敏感的:
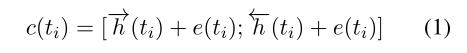
形式上:
给定文档 d d d={ d 1 d_1 d1,…, d m d_m dm}和查询 q q q={ q 1 q_1 q1,…, q n q_n qn},首先计算每一个 d j d_j dj对 q i q_i qi的注意力分数(点乘):
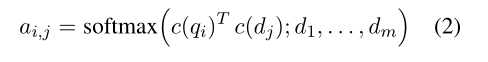
得到 d d d对 q q q的关注表示:
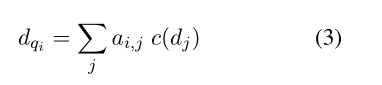
然后结合q得到doc-aware query 编码(可以使用多种函数代替:比如;欧氏距离的平方)(L2正则化):
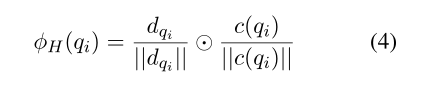
直观地说,如果文档包含一个或多个与 q i q_i qi相似的terms d j d_j dj,attention机制将会更加强调这些terms
POSIT-DRMM
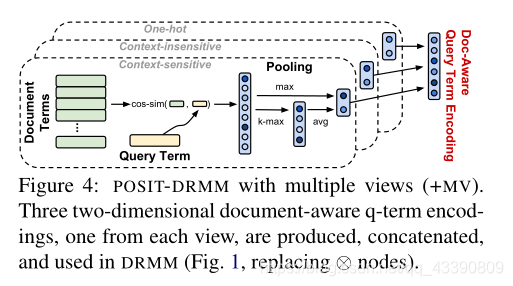
出发点
既希望模型奖励q-term和文档之间的最大number匹配,也奖励(几个q-term和文档之间的)平均匹配,以奖励具有更高匹配密度的文档。ABEL-DRMM的doc-aware q-term 评分没有考虑到这一点,因为注意力总和隐藏了单个或多个 term 是否高度相似匹配。
细节
首先,使用余弦相似度计算每一个 d j d_j dj对 q i q_i qi的注意力分数(注意,没有softmax):
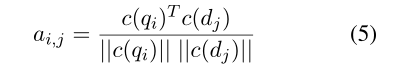
接下来并不加权,而是连接这些注意力分数:
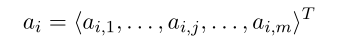
然后再 a i a_i ai上应用两个pooling操作创造一个 q i q_i qi的2维doc-aware编码:
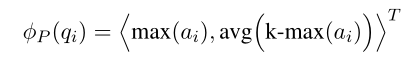
多view
第二个view是将pre-train的q和d的嵌入看作另外2个维度
第三个view是q和d的one-hot向量作为2个维度
实验
https://github.com/nlpaueb/deep-relevance-ranking.
任务:re-rank
dataset :TREC ROBUST 2004 and BioASQ
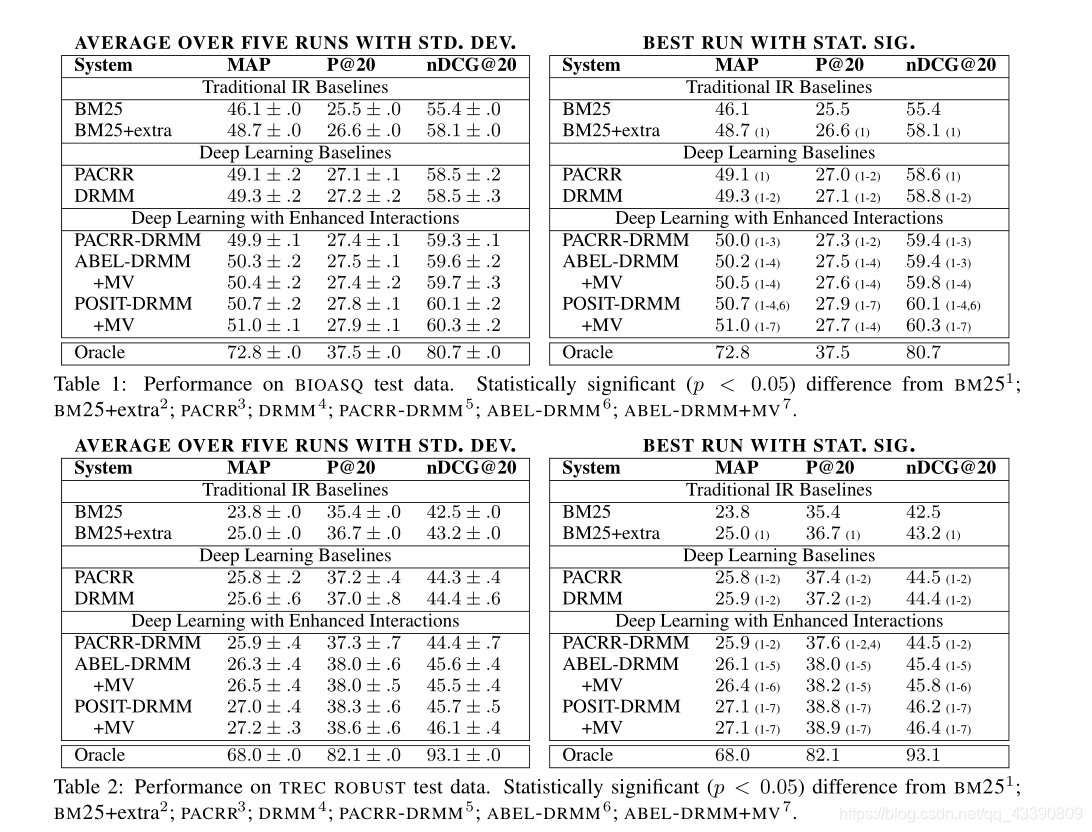
结果:
attention 可视化:

这篇关于POSIT-DRMM(18’Google)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







