本文主要是介绍【必须收藏】别再乱找TiDB 集群部署教程了,这篇保姆级教程来帮你!!| 博学谷狂野架构师,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TiDB 基础使用

TiDB dashboard使用
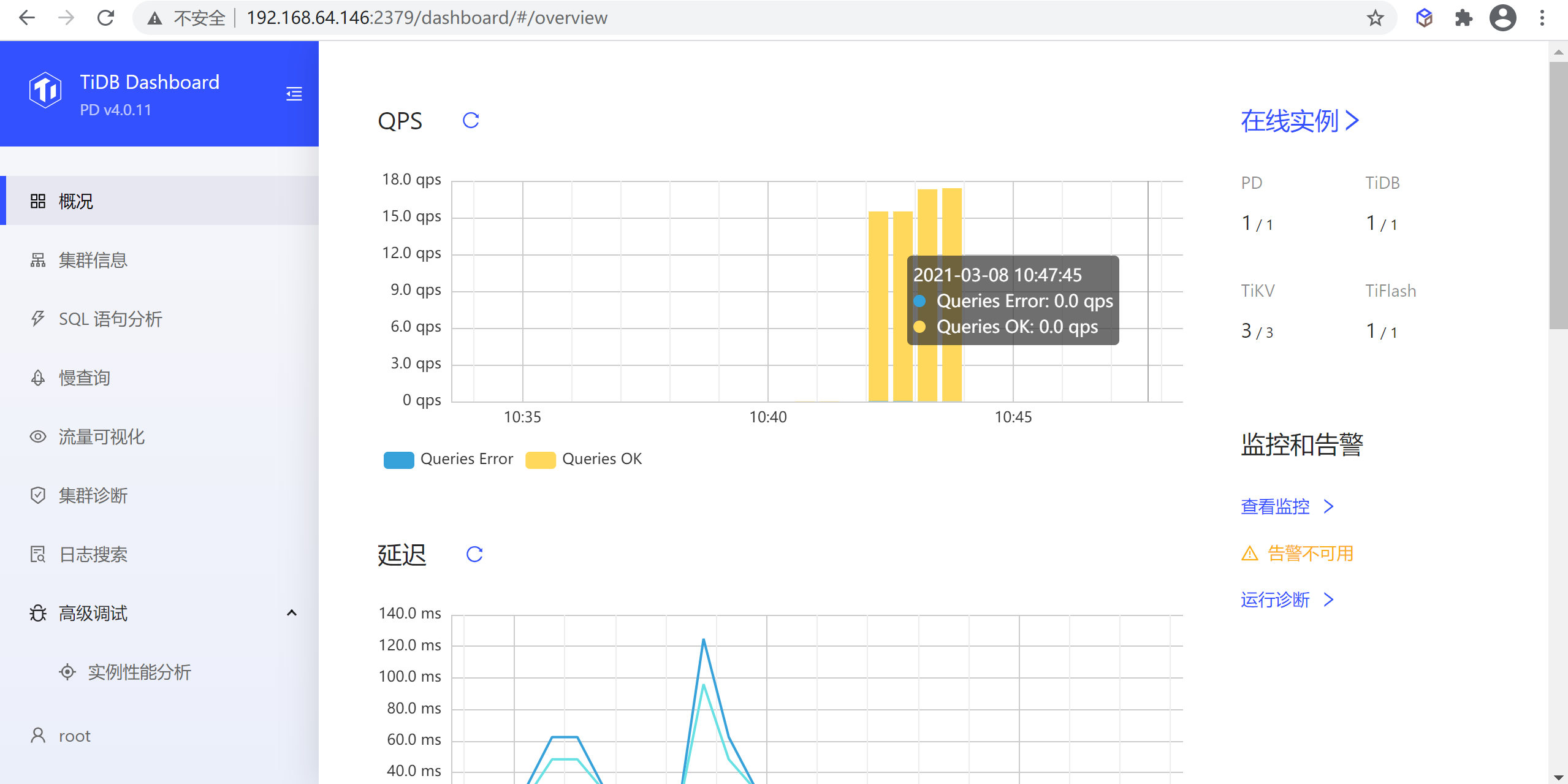
TiDB Dashboard 是 TiDB 自 4.0 版本起提供的图形化界面,可用于监控及诊断 TiDB 集群。TiDB Dashboard 内置于 TiDB 的 PD 组件中,无需独立部署。
[外链图片转存中…(img-nQFfHgkf-1679905899529)]
集群概况
查看集群整体 QPS 数值、执行耗时、消耗资源最多的几类 SQL 语句等概况信息。
该页面显示了整个集群的概况,包含以下信息:
- 整个集群的 QPS
- 整个集群的查询延迟
- 最近一段时间内累计耗时最多的若干 SQL 语句
- 最近一段时间内运行时间超过一定阈值的慢查询
- 各个实例的节点数和状态
- 监控及告警信息
QPS
该区域显示最近一小时整个集群的每秒成功和失败查询数量
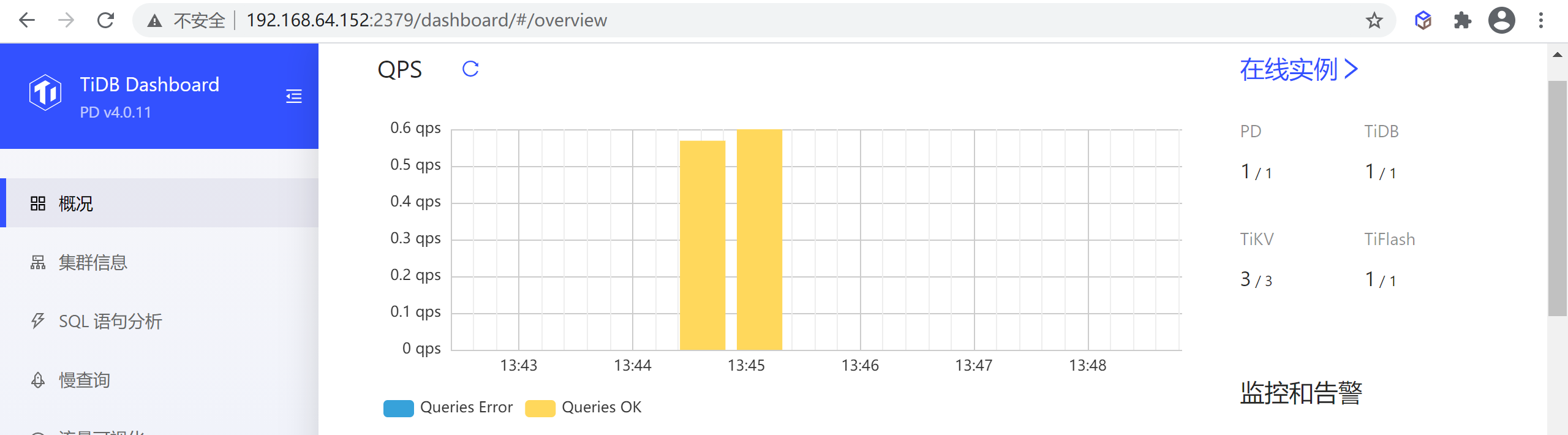
注意:该功能仅在部署了 Prometheus 监控组件的集群上可用,未部署监控组件的情况下会显示为失败。
延迟
该区域显示最近一小时整个集群中 99.9%、99% 和 90% 查询的延迟:
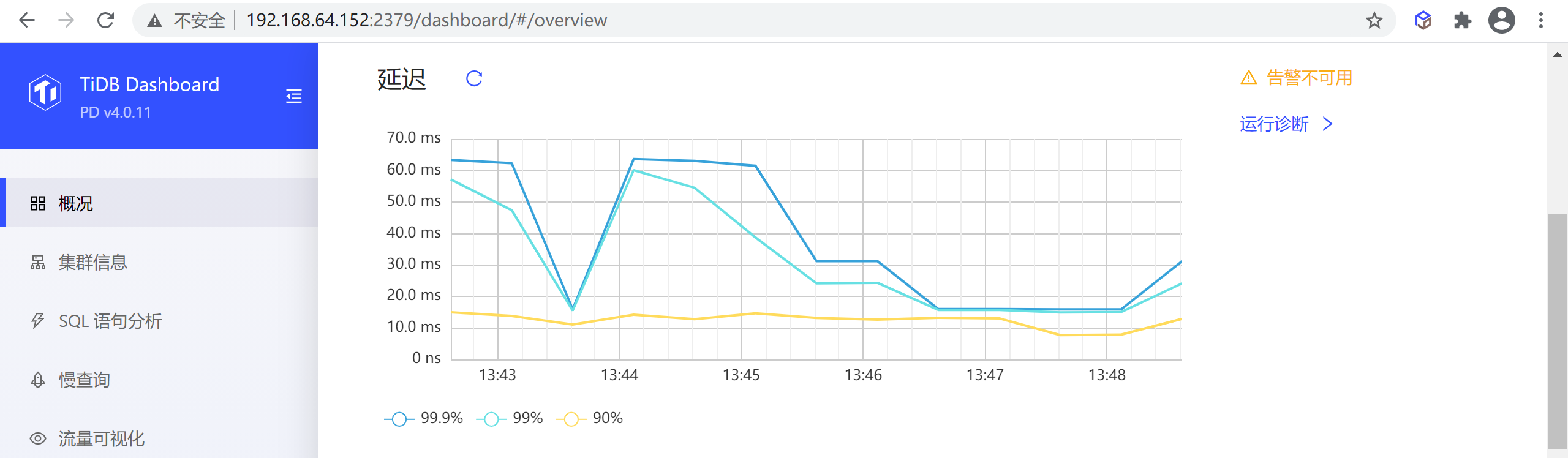
注意:该功能仅在部署了 Prometheus 监控组件的集群上可用,未部署监控组件的情况下会显示为失败。
Top SQL 语句
该区域显示最近一段时间内整个群集中累计耗时最长的 10 类 SQL 语句。查询参数不一样但结构一样的 SQL 会归为同一类 SQL 语句,在同一行中显示
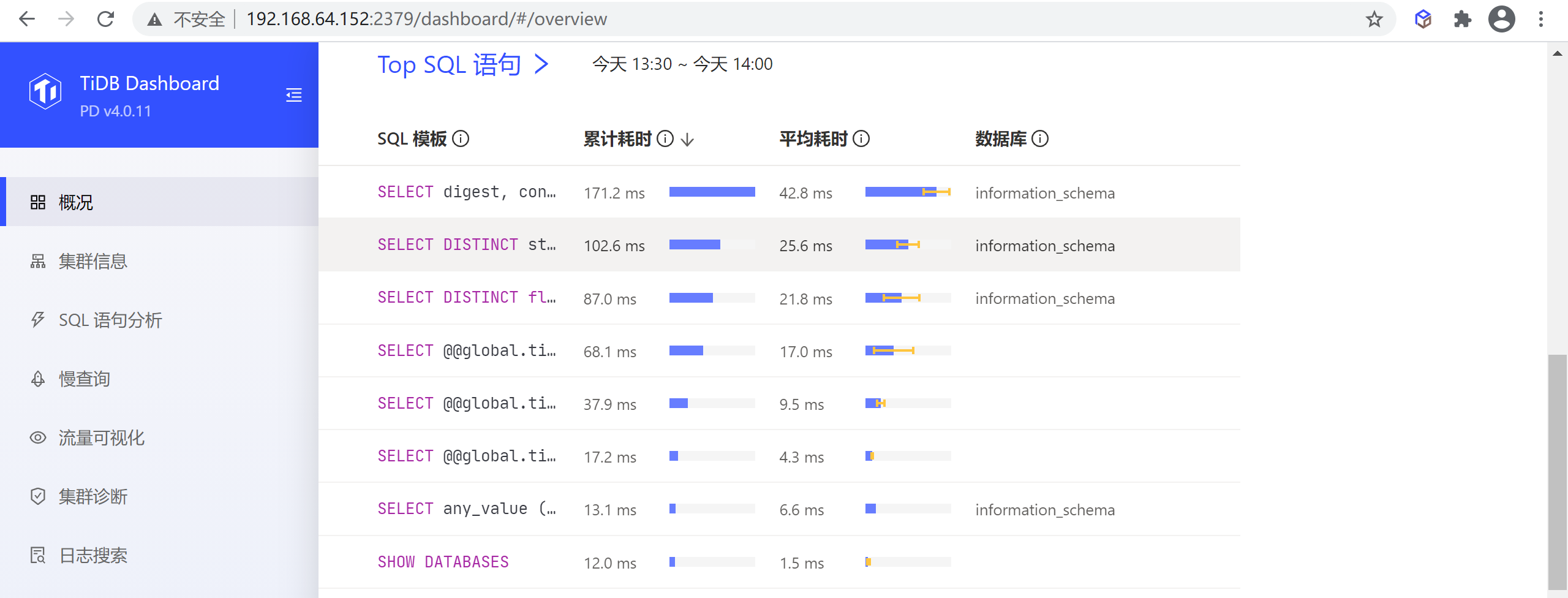
注意:该功能仅在开启了 SQL 语句分析功能的集群上可用。
最近的慢查询
该区域默认显示最近 30 分钟内整个集群中最新的 10 条慢查询
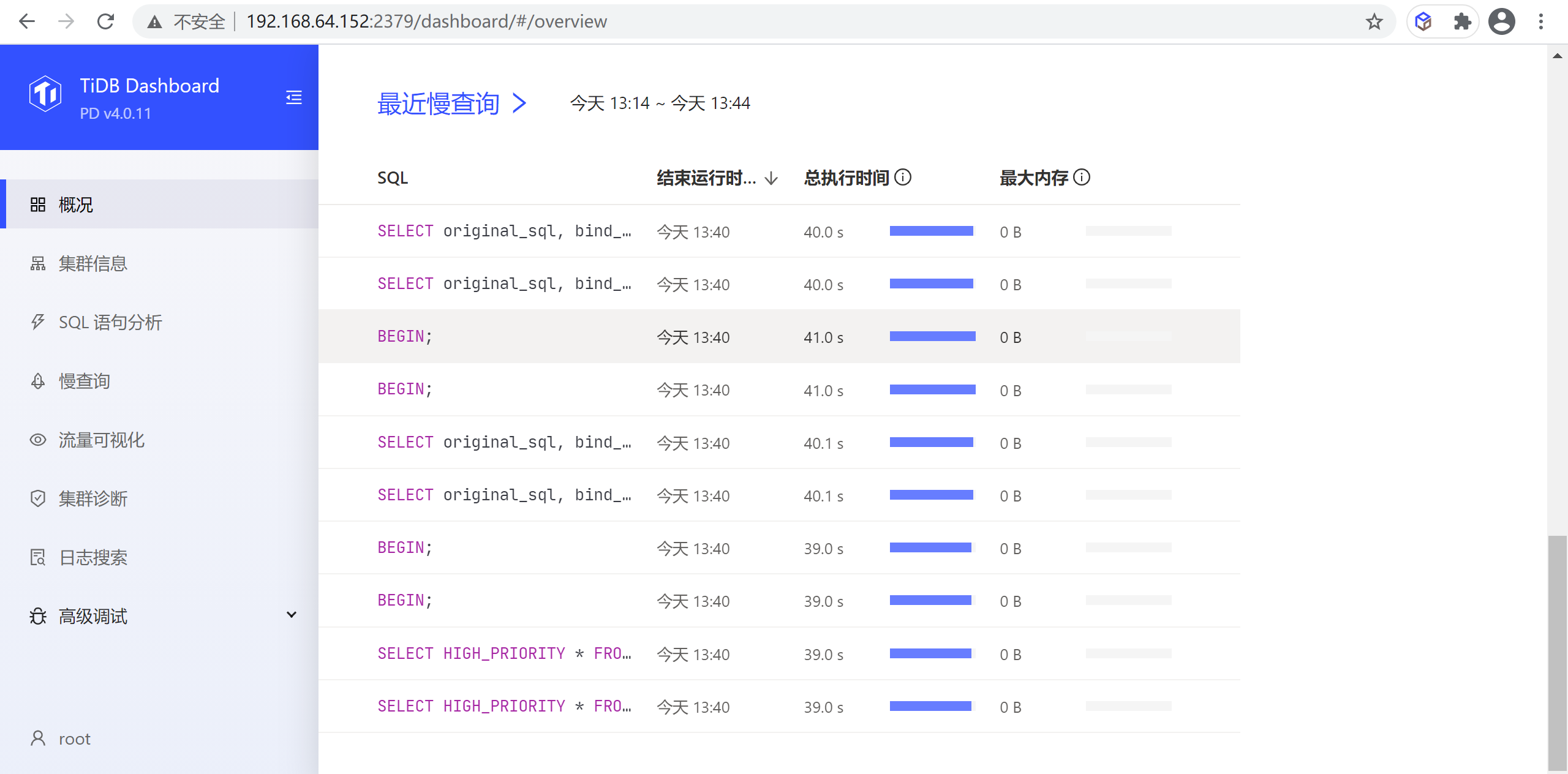
默认情况下运行时间超过 300ms 的SQL 查询即会被计为慢查询并显示在该表格中。
集群信息
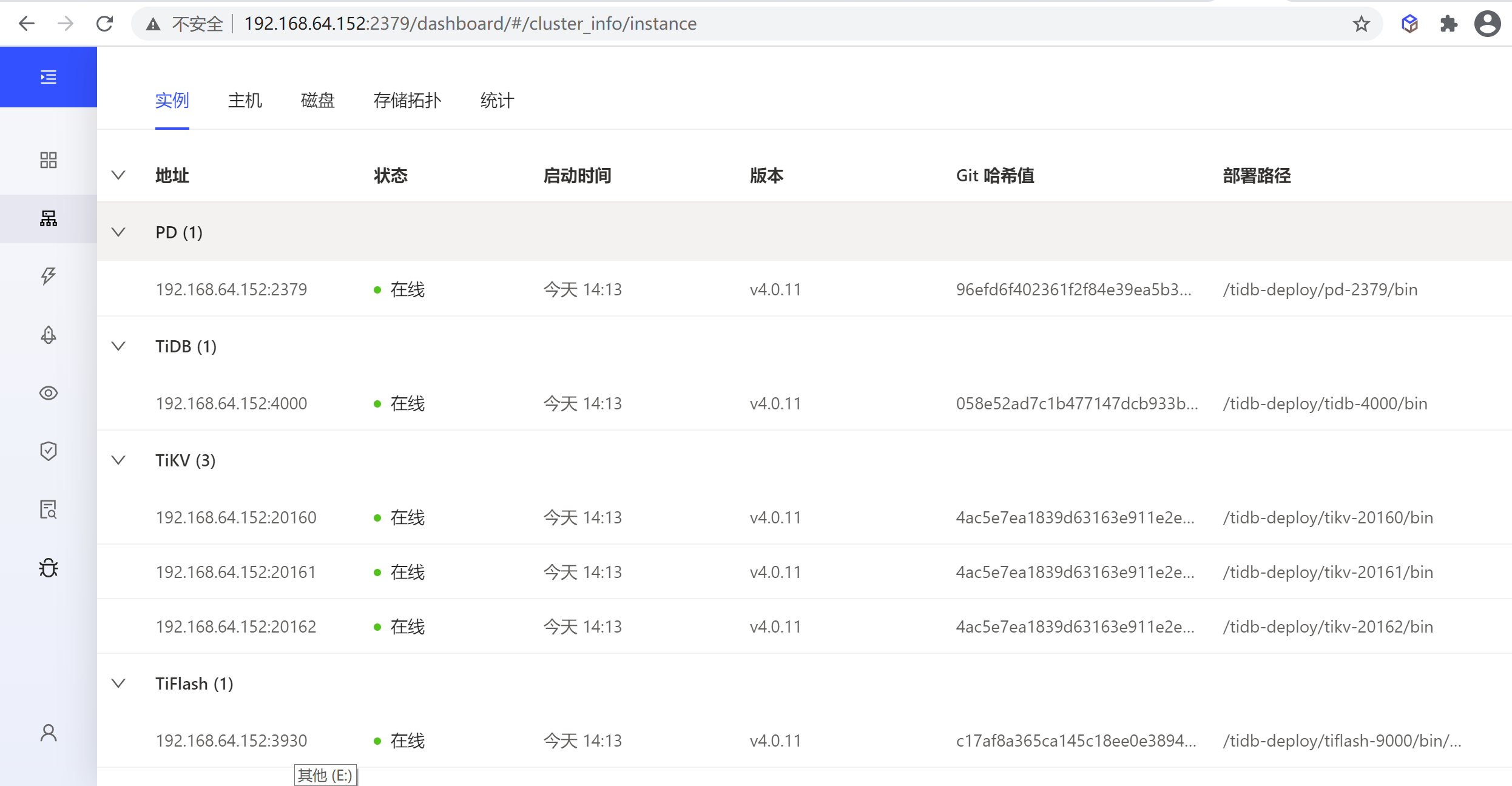
该页面上允许用户查看整个集群中 TiDB、TiKV、PD、TiFlash 组件的运行状态及其所在主机的运行状态。
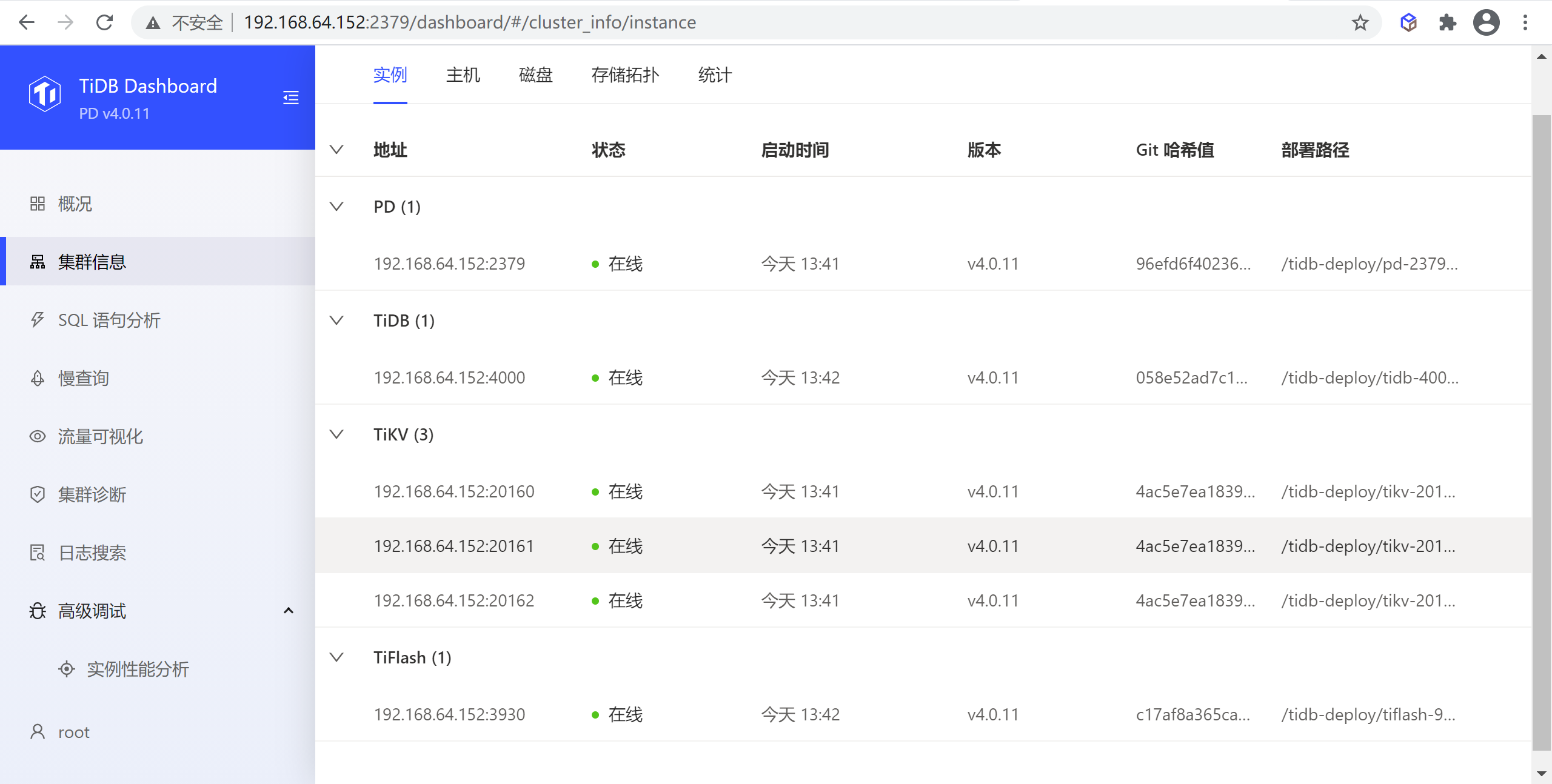
实例列表
实例列表列出了该集群中 TiDB、TiKV、PD 和 TiFlash 组件所有实例的概况信息。
表格列解释
表格包含以下列:
- 地址:实例地址
- 状态:实例的运行状态
- 启动时间:实例的启动时间
- 版本:实例版本号
- 部署路径:实例二进制文件所在目录路径
- Git 哈希值:实例二进制对应的 Git 哈希值
实例状态解释
实例的运行状态有:
- 在线 (Up):实例正常运行。
- 离线 (Down) 或无法访问 (Unreachable):实例未启动或对应主机存在网络问题。
- 已缩容下线 (Tombstone):实例上的数据已被完整迁出并缩容完毕。仅 TiKV 或 TiFlash 实例存在该状态。
- 下线中 (Offline):实例上的数据正在被迁出并缩容。仅 TiKV 或 TiFlash 实例存在该状态。
- 未知 (Unknown):未知的实例运行状态。
主机列表
主机列表列出了该集群中 TiDB、TiKV、PD 和 TiFlash 组件所有实例对应主机的运行情况。

表格列解释
表格包含以下列:
- 地址:主机 IP 地址
- CPU:主机 CPU 逻辑核心数
- CPU 使用率:主机当前 1 秒的用户态和内核态 CPU 使用率
- 物理内存:主机总计的物理内存大小
- 内存使用率:主机当前内存使用率
- 部署磁盘:主机上运行实例所在磁盘的文件系统和磁盘挂载路径
- 磁盘使用率:主机上运行实例所在磁盘的空间使用率
SQL语句分析
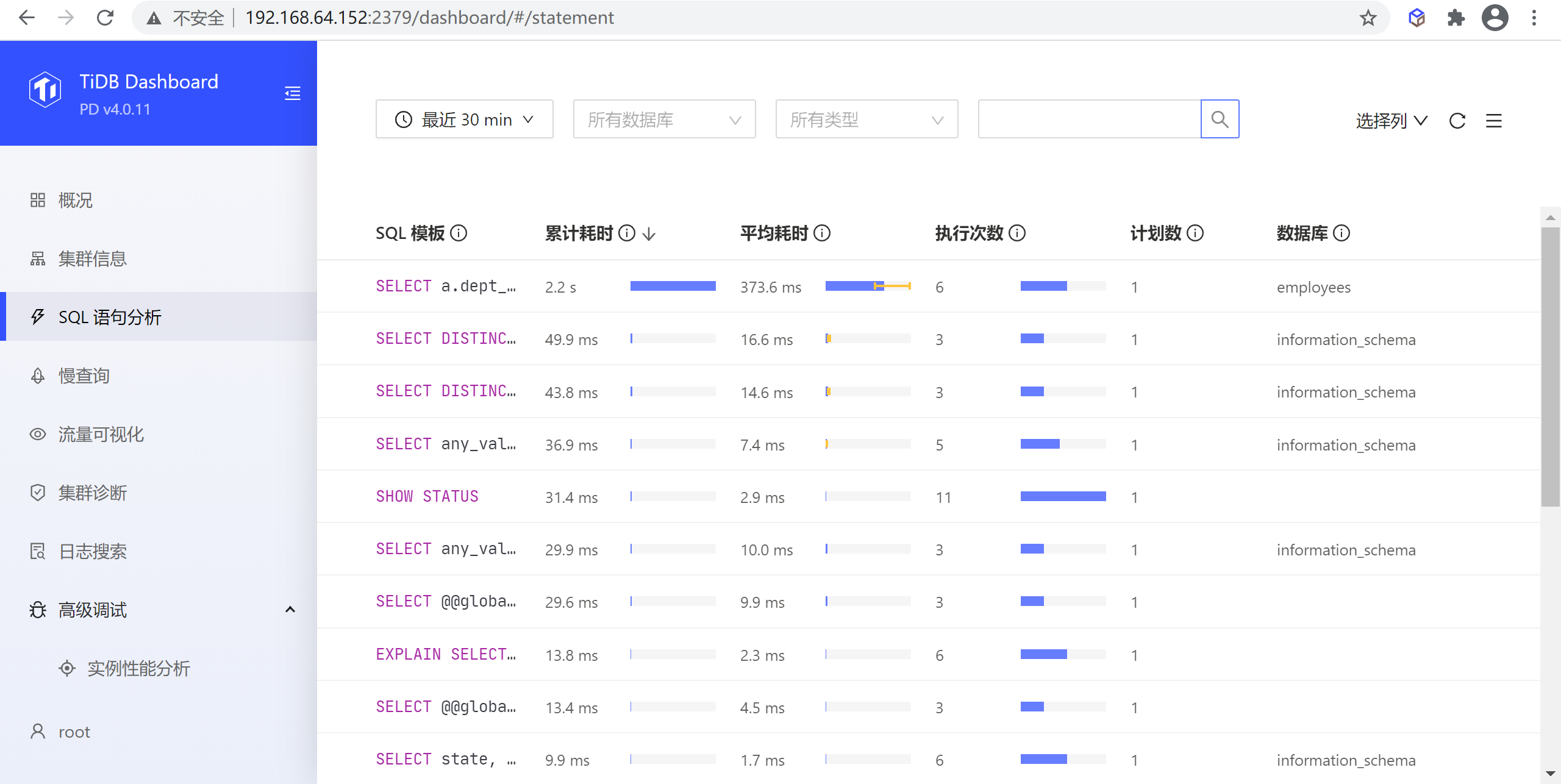
该页面可以查看所有 SQL 语句在集群上执行情况,常用于分析总耗时或单次耗时执行耗时较长的 SQL 语句。
执行列表页
在该页面中,结构一致的 SQL 查询(即使查询参数不一致)都会被归为同一个 SQL 语句,例如 SELECT * FROM employee WHERE id IN (1, 2, 3) 和 select * from EMPLOYEE where ID in (4, 5) 都属于同一 SQL 语句 select * from employee where id in (...)。
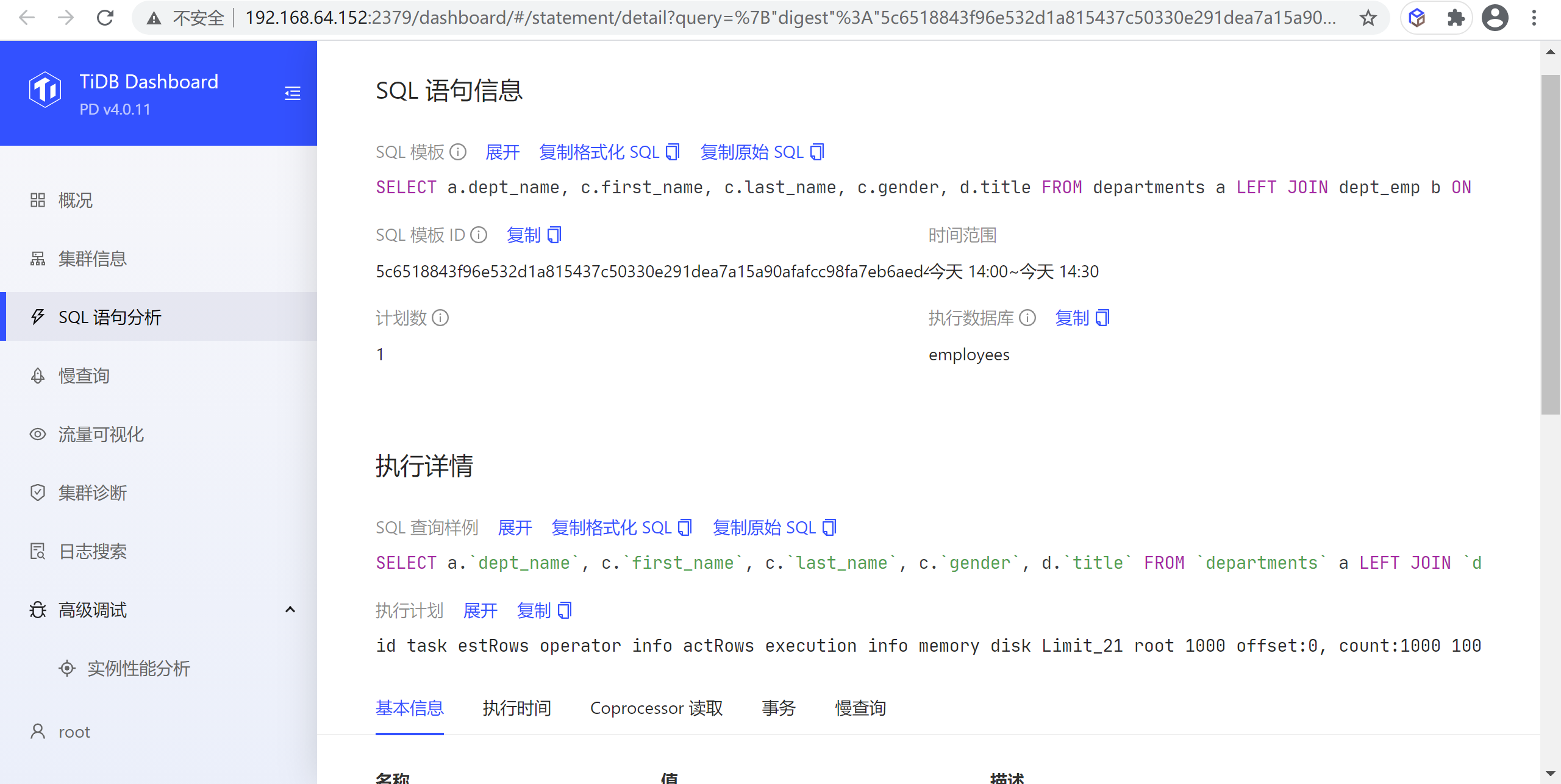
执行详情页面
在列表中点击任意一行可以进入该 SQL 语句的详情页查看更详细的信息,这此信息包括三大部分:
- SQL 语句概况:包括 SQL 模板,SQL 模板 ID,当前查看的时间范围,执行计划个数以及执行所在的数据库(下图区域 1)
- 执行计划列表:如果该 SQL 语句有多个执行计划,则显示该列表,可以选择不同的执行计划,在列表下方会显示选中的执行计划详情;如果只有一个执行计划,则该列表不显示(下图区域 2)
- 执行计划详情:显示选中的执行计划的详细信息,具体见下一小节(下图区域 3)
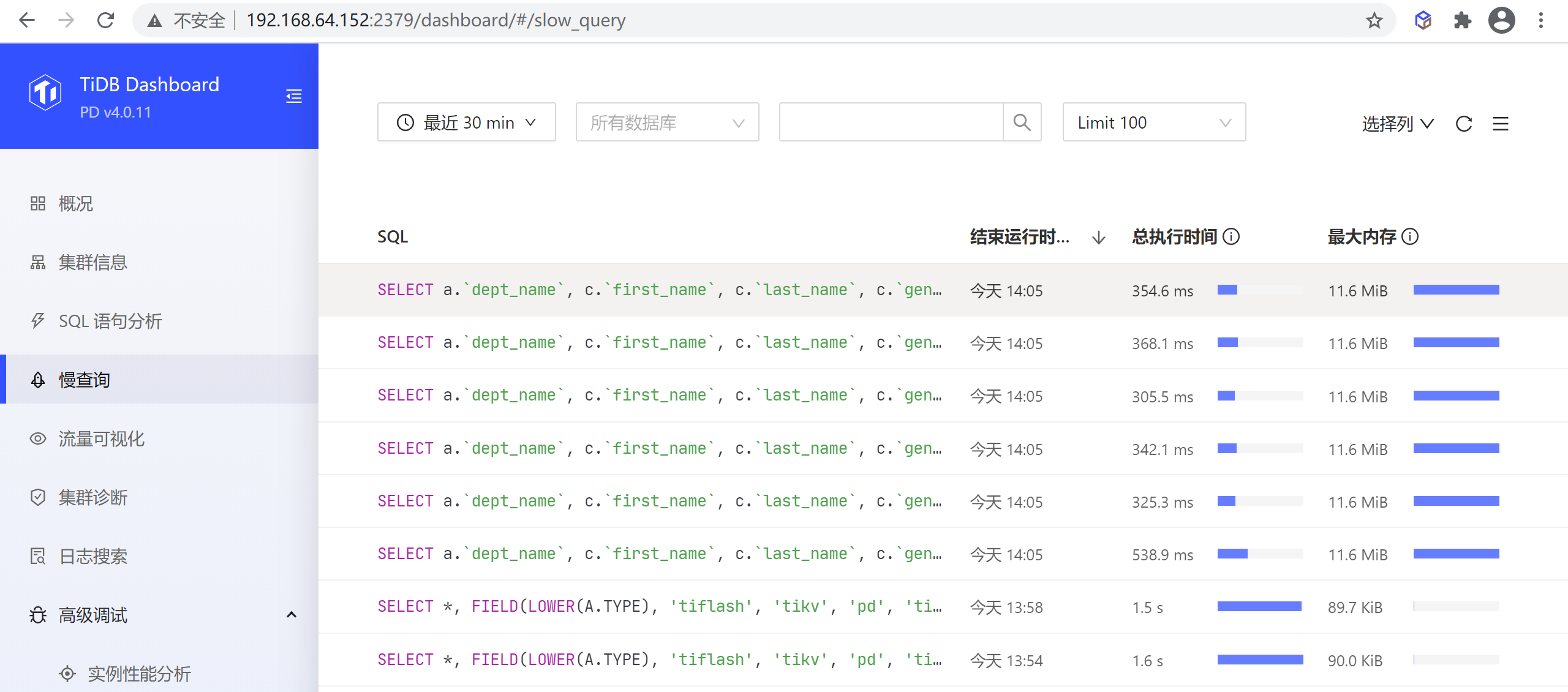
慢查询
该页面上能检索和查看集群中所有慢查询。
默认情况下,执行时间超过 300ms 的 SQL 查询就会被视为慢查询,被记录到慢查询日志中,并可通过本功能对记录到的慢查询进行查询。可调整 tidb_slow_log_threshold SESSION 变量或 TiDB slow-threshold 参数调整慢查询阈值。
若关闭了慢查询日志,则本功能不可用。慢查询日志默认开启,可通过修改 TiDB 配置 enable-slow-log 开启或禁用。
慢查询列表页
可按时间范围、慢查询语句关联的数据库、SQL 关键字、SQL 类型、显示的慢查询语句数量等条件过滤,筛选慢查询句。如下所示,默认显示 30 分钟内最近 100 条慢查询。
查看执行详情
在列表中点击任意一行可以显示该慢查询的详细执行信息,包含:
- SQL:慢查询 SQL 文本(
- 执行计划:慢查询的执行计划
- 其他分类好的 SQL 执行信息
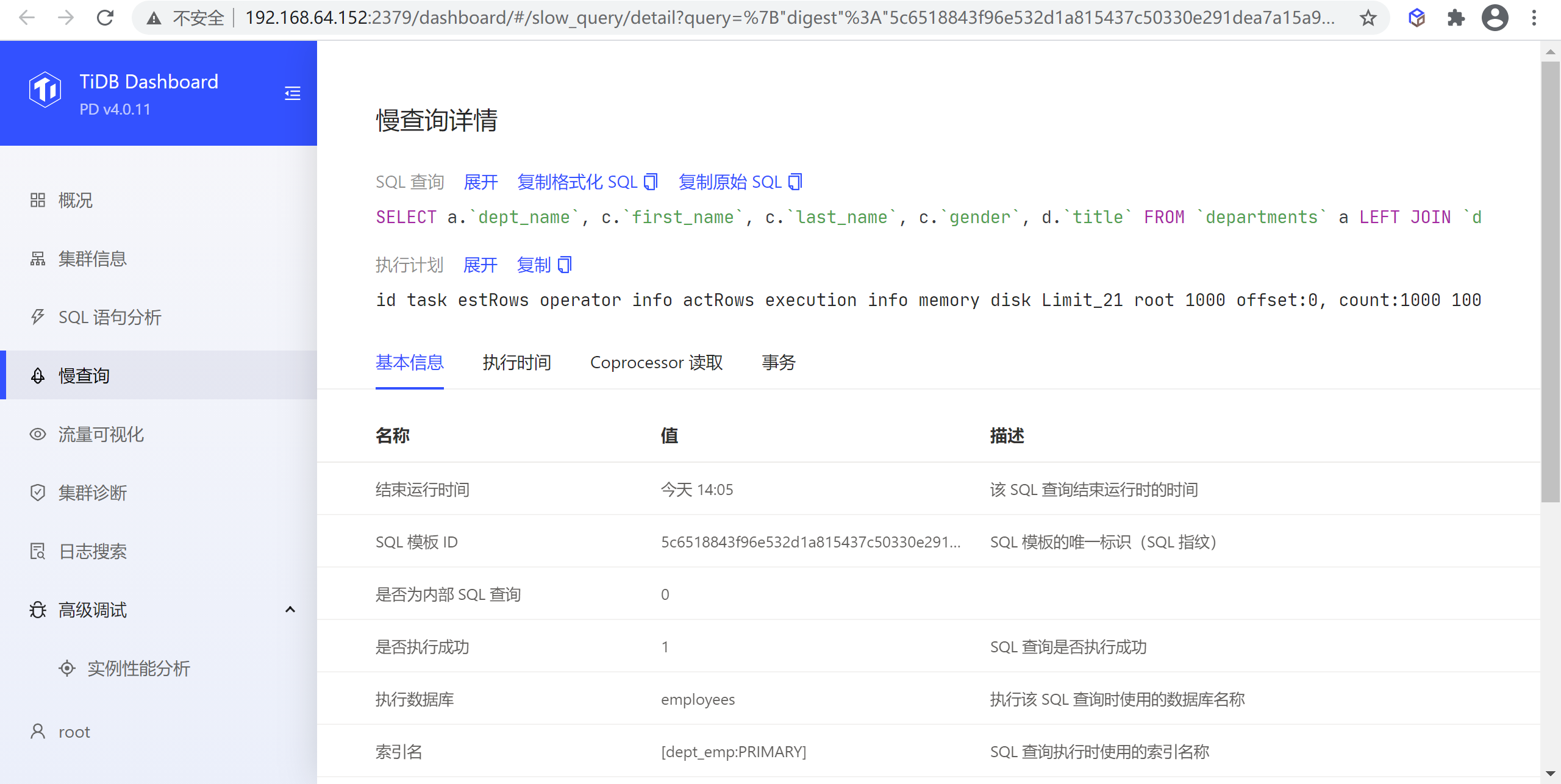
点击展开 (Expand) 链接可以展开相应项的完整内容,点击复制 (Copy) 链接可以复制完整内容到剪贴板。
集群诊断页面
集群诊断是在指定的时间范围内,对集群可能存在的问题进行诊断,并将诊断结果和一些集群相关的负载监控信息汇总成一个诊断报告。诊断报告是网页形式,通过浏览器保存后可离线浏览和传阅。
生成诊断报告
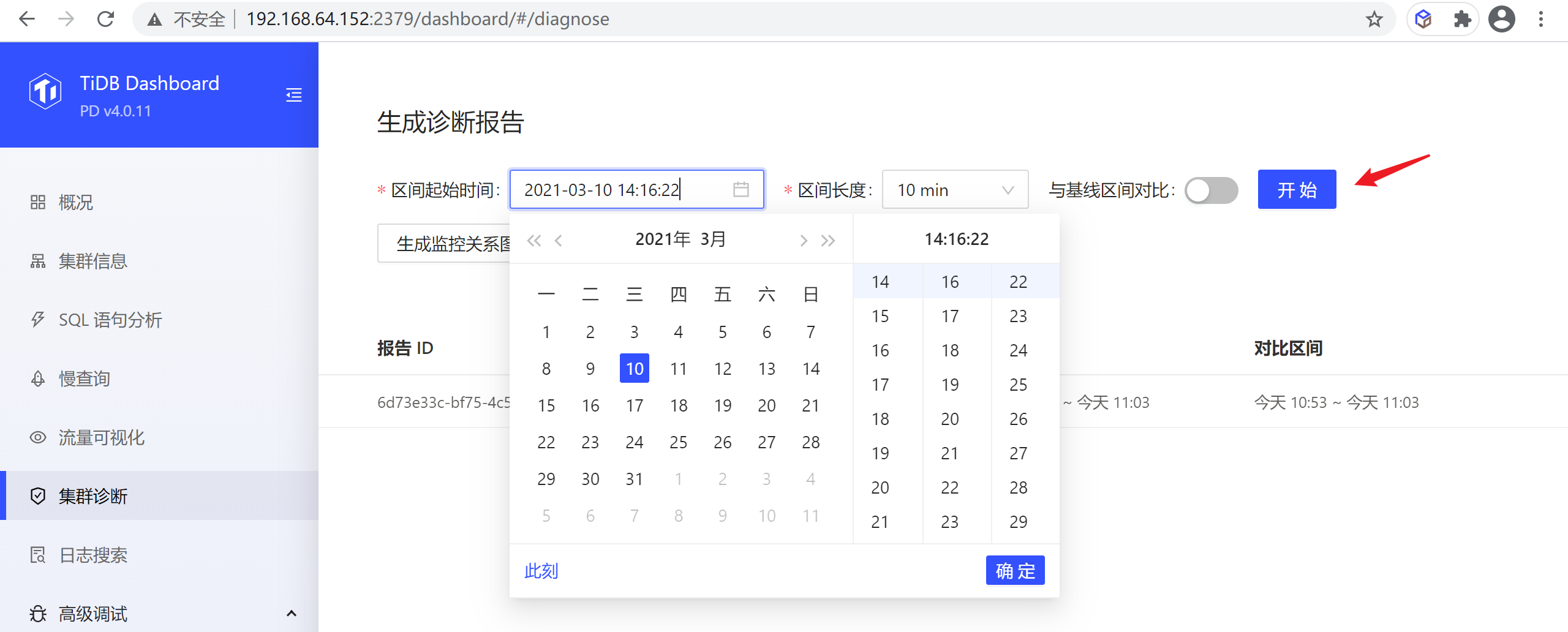
如果想对一个时间范围内的集群进行诊断,查看集群的负载等情况,可以使用以下步骤来生成一段时间范围的诊断报告:
- 设置区间的开始时间
- 设置区间长度,例如 10 min 。
- 点击开始。
建议生成报告的时间范围在 1 min ~ 60 min 内,目前不建议生成超过 1 小时范围的报告。
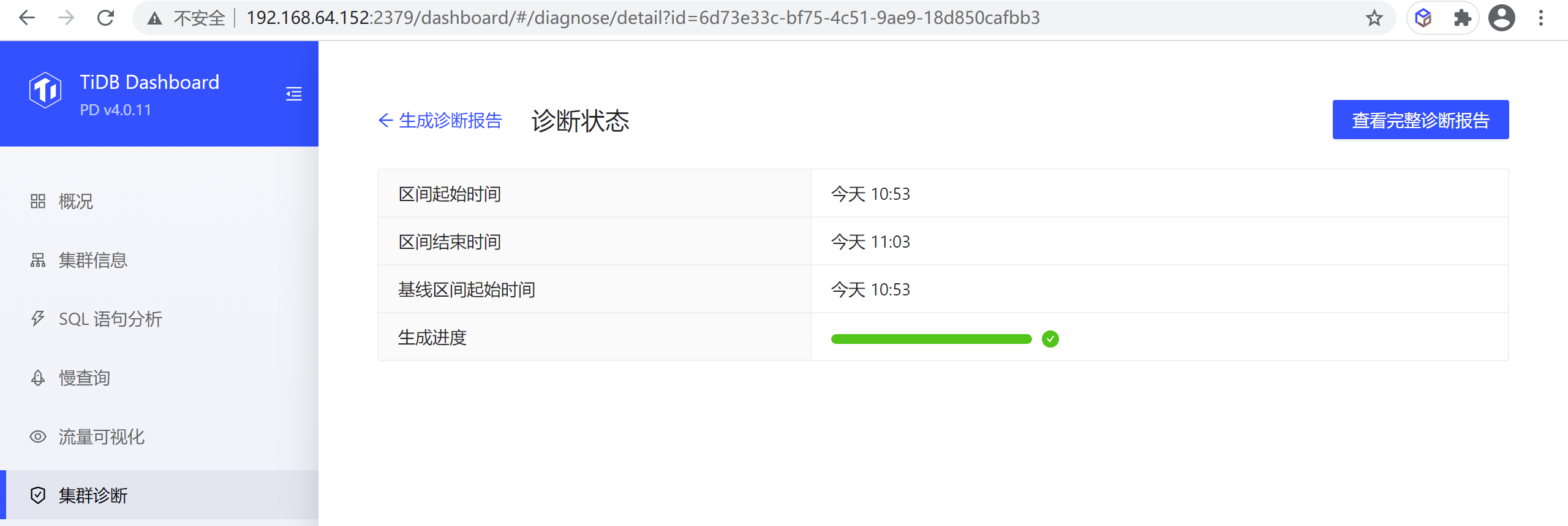
点击开始 (start) 后,会看到以下界面,生成进度 (progress) 是生成报告的进度条,生成报告完成后,点击查看报告 (View Full Report) 即可。
TIDB集群部署
环境要求
操作系统建议配置
TiDB 作为一款开源分布式 NewSQL 数据库,可以很好的部署和运行在 Intel 架构服务器环境、ARM 架构的服务器环境及主流虚拟化环境,并支持绝大多数的主流硬件网络。作为一款高性能数据库系统,TiDB 支持主流的 Linux 操作系统环境。
| Linux 操作系统平台 | 版本 |
|---|---|
| Red Hat Enterprise Linux | 7.3 及以上 |
| CentOS | 7.3 及以上 |
| Oracle Enterprise Linux | 7.3 及以上 |
| Ubuntu LTS | 16.04 及以上 |
服务器建议配置
TiDB 支持部署和运行在 Intel x86-64 架构的 64 位通用硬件服务器平台或者 ARM 架构的硬件服务器平台。对于开发,测试,及生产环境的服务器硬件配置(不包含操作系统 OS 本身的占用)有以下要求和建议:
开发及测试环境
| 组件 | CPU | 内存 | 本地存储 | 网络 | 实例数量(最低要求) |
|---|---|---|---|---|---|
| TiDB | 8 核+ | 16 GB+ | 无特殊要求 | 千兆网卡 | 1(可与 PD 同机器) |
| PD | 4 核+ | 8 GB+ | SAS, 200 GB+ | 千兆网卡 | 1(可与 TiDB 同机器) |
| TiKV | 8 核+ | 32 GB+ | SSD, 200 GB+ | 千兆网卡 | 3 |
| TiFlash | 32 核+ | 64 GB+ | SSD, 200 GB+ | 千兆网卡 | 1 |
| TiCDC | 8 核+ | 16 GB+ | SAS, 200 GB+ | 千兆网卡 | 1 |
生产环境
| 组件 | CPU | 内存 | 硬盘类型 | 网络 | 实例数量(最低要求) |
|---|---|---|---|---|---|
| TiDB | 16 核+ | 32 GB+ | SAS | 万兆网卡(2 块最佳) | 2 |
| PD | 4核+ | 8 GB+ | SSD | 万兆网卡(2 块最佳) | 3 |
| TiKV | 16 核+ | 32 GB+ | SSD | 万兆网卡(2 块最佳) | 3 |
| TiFlash | 48 核+ | 128 GB+ | 1 or more SSDs | 万兆网卡(2 块最佳) | 2 |
| TiCDC | 16 核+ | 64 GB+ | SSD | 万兆网卡(2 块最佳) | 2 |
| 监控 | 8 核+ | 16 GB+ | SAS | 千兆网卡 | 1 |
环境准备
准备一台部署主机,确保其软件满足需求:
- 推荐安装 CentOS 7.3 及以上版本
- Linux 操作系统开放外网访问,用于下载 TiDB 及相关软件安装包
最小规模的 TiDB 集群拓扑
| 实例 | 个数 | IP | 配置 |
|---|---|---|---|
| TiKV | 3 | 192.168.64.146 | 避免端口和目录冲突 |
| TiDB | 1 | 192.168.64.146 | 默认端口 全局目录配置 |
| PD | 1 | 192.168.64.146 | 默认端口 全局目录配置 |
| TiFlash | 1 | 192.168.64.146 | 默认端口 全局目录配置 |
| Monitoring & Grafana | 1 | 192.168.64.146 | 默认端口 全局目录配置 |
安装TiUP
什么是TiUP
从 TiDB 4.0 版本开始,TiUP 作为新的工具,承担着包管理器的角色,管理着 TiDB 生态下众多的组件,如 TiDB、PD、TiKV 等。用户想要运行 TiDB 生态中任何组件时,只需要执行 TiUP 一行命令即可,相比以前,极大地降低了管理难度。
安装TiUP组件
使用普通用户登录中控机,以 tidb 用户为例,后续安装 TiUP 及集群管理操作均通过该用户完成
TiUP 安装过程十分简洁,无论是 Darwin 还是 Linux 操作系统,执行一行命令即可安装成功:
COPYcurl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
该命令将 TiUP 安装在 $HOME/.tiup 文件夹下,之后安装的组件以及组件运行产生的数据也会放在该文件夹下。同时,它还会自动将 $HOME/.tiup/bin 加入到 Shell Profile 文件的 PATH 环境变量中,这样你就可以直接使用 TiUP 了。

配置TiUP环境
重新声明全局环境变量
COPYsource .bash_profile
检查TiUP 工具是否安装
COPYwhich tiup

安装 cluster 组件
COPYtiup cluster
升级cluster组件
如果机器已经安装 TiUP cluster,需要更新软件版本
COPYtiup update --self && tiup update cluster
预期输出
“Update successfully!”字样。

编辑部署文件
请根据不同的集群拓扑,编辑 TiUP 所需的集群初始化配置文件。
常见的部署场景
最小拓扑架构
最基本的集群拓扑,包括 tidb-server、tikv-server、pd-server,适合 OLTP 业务。
增加 TiFlash 拓扑架构
包含最小拓扑的基础上,同时部署 TiFlash。TiFlash 是列式的存储引擎,已经逐步成为集群拓扑的标配。适合 Real-Time HTAP 业务。
增加 TiCDC 拓扑架构
包含最小拓扑的基础上,同时部署 TiCDC。TiCDC 是 4.0 版本开始支持的 TiDB 增量数据同步工具,支持多种下游 (TiDB/MySQL/MQ)。相比于 TiDB Binlog,TiCDC 有延迟更低、天然高可用等优点。在部署完成后,需要启动 TiCDC,通过 cdc cli 创建同步任务。
增加 TiDB Binlog 拓扑架构
包含最小拓扑的基础上,同时部署 TiDB Binlog。TiDB Binlog 是目前广泛使用的增量同步组件,可提供准实时备份和同步功能。
增加 TiSpark 拓扑架构
包含最小拓扑的基础上,同时部署 TiSpark 组件。TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求而推出的产品。TiUP cluster 组件对 TiSpark 的支持目前为实验性特性。
混合部署拓扑架构
适用于单台机器,混合部署多个实例的情况,也包括单机多实例,需要额外增加目录、端口、资源配比、label 等配置。
单机极简部署
部署主机软件和环境要求:
- 部署需要使用部署主机的 root 用户及密码
- 部署主机关闭防火墙或者开放 TiDB 集群的节点间所需端口
单机极简拓扑
| 实例 | IP | 开放端口 |
|---|---|---|
| grafana | 192.168.64.152 | 3000 |
| pd | 192.168.64.152 | 2379/2380 |
| prometheus | 192.168.64.152 | 9090 |
| tidb | 192.168.64.152 | 4000/10080 |
| tiflash | 192.168.64.152 | 9000/8123/3930/20170/20292/8234 |
| tikv | 192.168.64.152 | 20160/20180 |
| tikv | 192.168.64.152 | 20161/20181 |
| tikv | 192.168.64.152 | 20162/20182 |
编辑配置文件
按下面的配置模板,编辑配置文件,命名为
topo.yaml
user: "tidb":表示通过tidb系统用户(部署会自动创建)来做集群的内部管理,默认使用 22 端口通过 ssh 登录目标机器replication.enable-placement-rules:设置这个 PD 参数来确保 TiFlash 正常运行host:设置为本部署主机的 IP
COPY# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:user: "tidb"ssh_port: 22deploy_dir: "/tidb-deploy"data_dir: "/tidb-data"# # Monitored variables are applied to all the machines.
monitored:node_exporter_port: 9100blackbox_exporter_port: 9115server_configs:tidb:log.slow-threshold: 300tikv:readpool.storage.use-unified-pool: falsereadpool.coprocessor.use-unified-pool: truepd:replication.enable-placement-rules: truereplication.location-labels: ["host"]tiflash:logger.level: "info"pd_servers:- host: 192.168.64.146tidb_servers:- host: 192.168.64.146tikv_servers:- host: 192.168.64.146port: 20160status_port: 20180config:server.labels: { host: "logic-host-1" }- host: 192.168.64.146port: 20161status_port: 20181config:server.labels: { host: "logic-host-2" }- host: 192.168.64.146port: 20162status_port: 20182config:server.labels: { host: "logic-host-3" }tiflash_servers:- host: 192.168.64.146monitoring_servers:- host: 192.168.64.146grafana_servers:- host: 192.168.64.146
执行集群部署命令
命令格式
COPYtiup cluster deploy <cluster-name> <tidb-version> ./topo.yaml --user root -p
参数解释
- 参数
<cluster-name>表示设置集群名称 - 参数
<tidb-version>表示设置集群版本,可以通过tiup list tidb命令来查看当前支持部署的 TiDB 版本 - 参数:
--user root通过 root 用户登录到目标主机完成集群部署,该用户需要有 ssh 到目标机器的权限,并且在目标机器有 sudo 权限。也可以用其他有 ssh 和 sudo 权限的用户完成部署。
检查TiDB最新版本
可以通过执行
tiup list tidb来查看 TiUP 支持的版本
COPYtiup list tidb
经过执行发现 最新可用的TiDB版本是 v4.0.11
执行部署命令
COPYtiup cluster deploy tidb-cluster 4.0.11 ./topo.yaml --user root -p
下面输入
y继续后输入密码进行安装界面
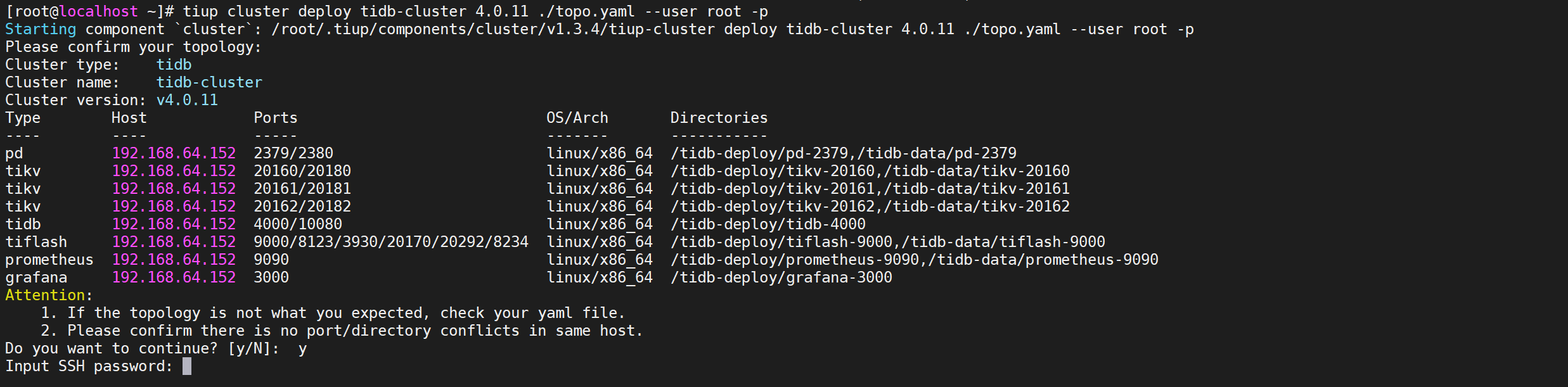
进入安装界面,等待安装即可
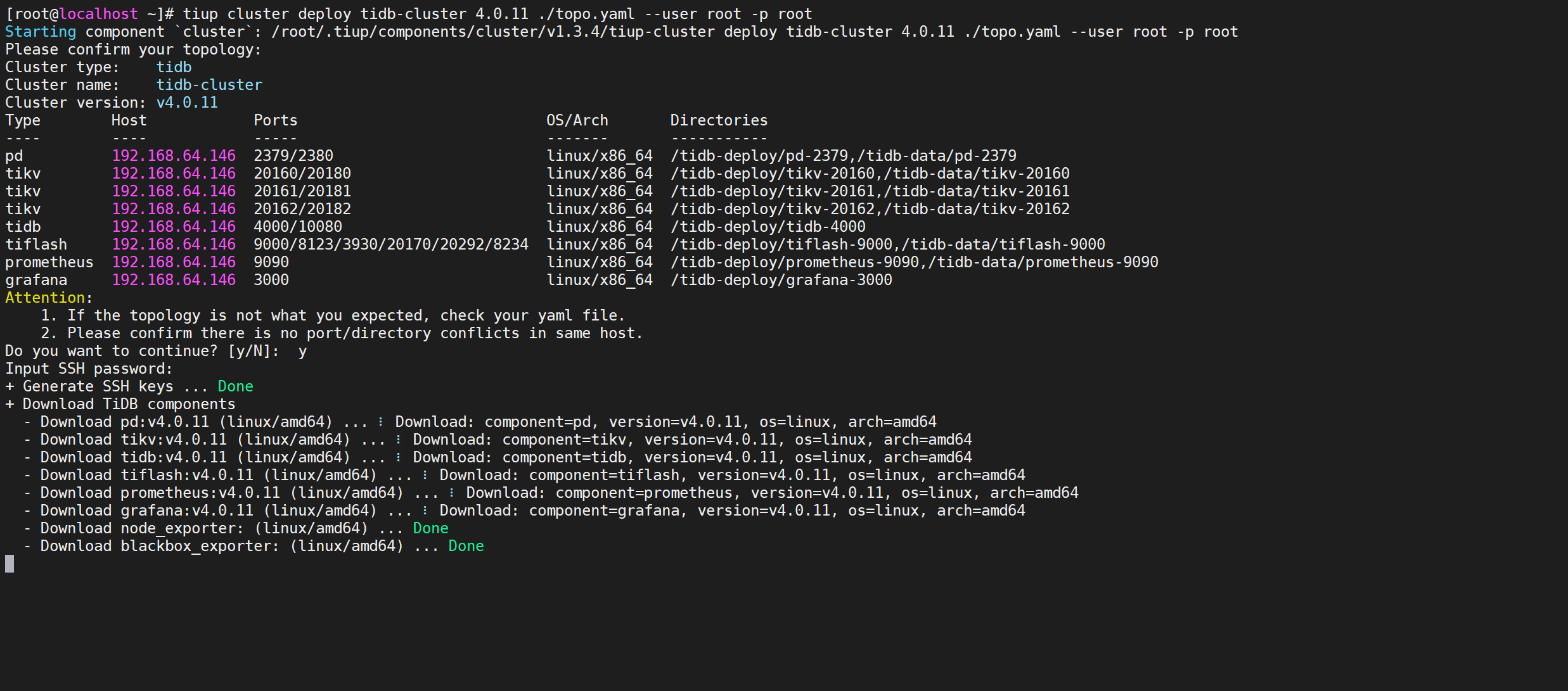
如果出现
deployed successfully表示部署成功,集群名称是tidb-cluster
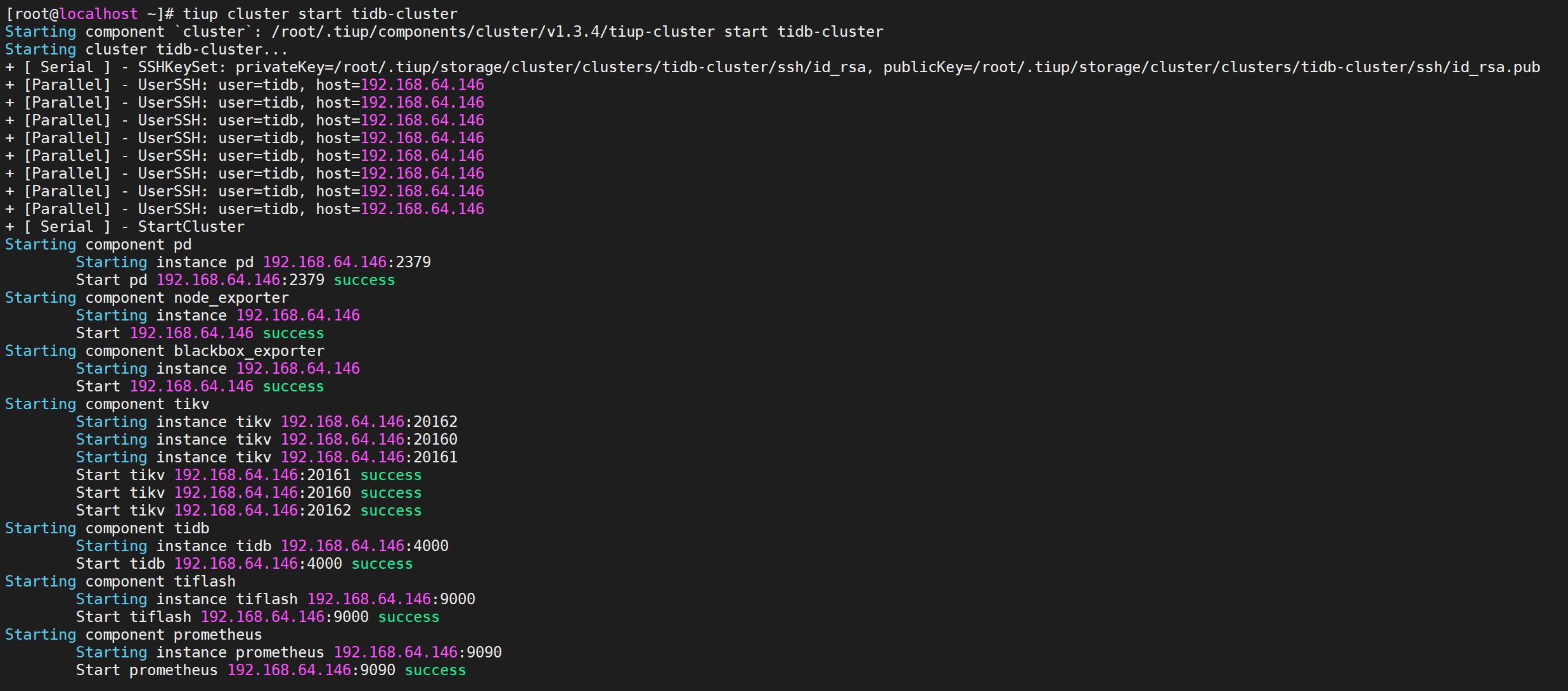
启动集群
COPYtiup cluster start tidb-cluster
查看节点状态
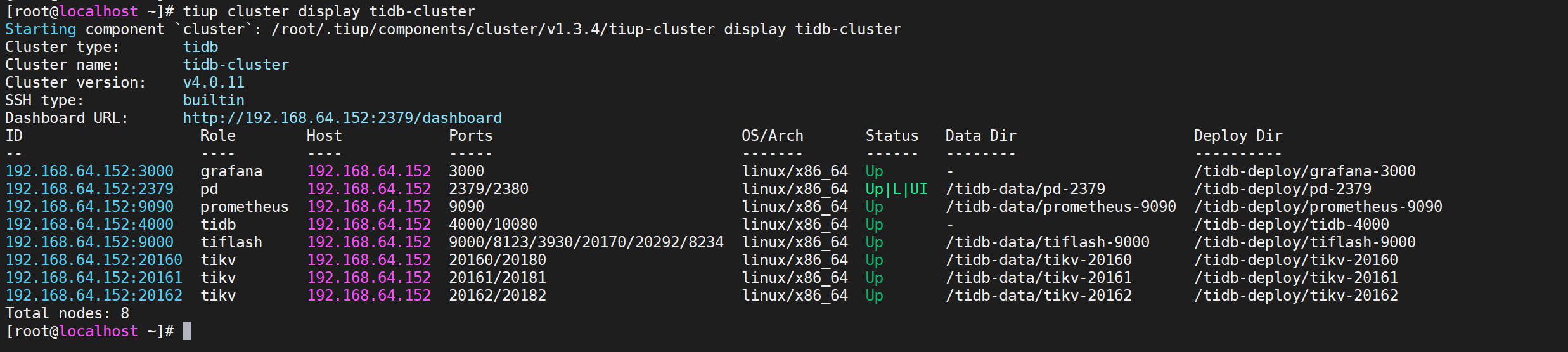
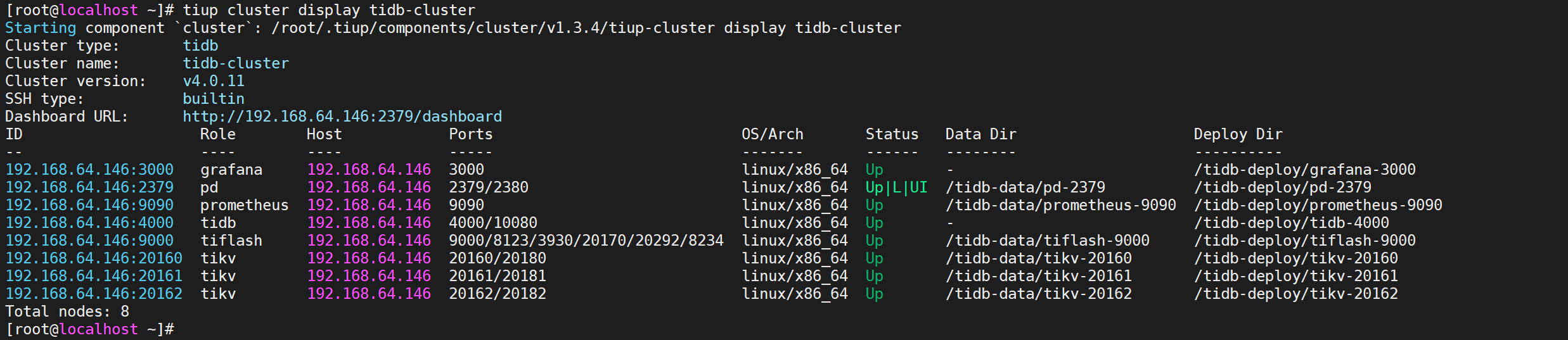
COPYtiup cluster display tidb-cluster
所有节点都是Up状态说明都已经启动就绪了
测试TiDB集群
Mysql连接集群
TiDB的连接端口默认是4000, 密码是空,可用使用Mysql客户端以及第三方工具进行连接
安装MySql客户端
COPYyum -y install mysql
MySql客户端连接
访问 TiDB 数据库,密码为空
COPYmysql -h 192.168.64.146 -P 4000 -u root

第三方客户端访问Mysql
使用SQLyog访问TiDB
创建TiDB连接
连接后就可以操作数据库了
访问Grafana监控
通过 http://{grafana-ip}:3000 访问集群 Grafana 监控页面,默认用户名和密码均为 admin。
访问Dashboard
通过 http://{pd-ip}:2379/dashboard 访问集群 TiDB Dashboard监控页面,默认用户名为 root,密码为空。
查看集群列表
COPYtiup cluster list

查看集群拓扑
COPYtiup cluster display tidb-cluster
TiDB扩缩容
当前集群部署拓扑
| 实例 | IP | 端口 | 存储路径 | 部署路径 |
|---|---|---|---|---|
| grafana | 192.168.64.152 | 3000 | – | /tidb-deploy/grafana-3000 |
| pd | 192.168.64.152 | 2379/2380 | /tidb-data/pd-2379 | /tidb-deploy/pd-2379 |
| prometheus | 192.168.64.152 | 9090 | /tidb-data/prometheus-9090 | /tidb-deploy/prometheus-9090 |
| tidb | 192.168.64.152 | 4000/10080 | – | /tidb-deploy/tidb-4000 |
| tiflash | 192.168.64.152 | 9000/8123/3930/20170/20292/8234 | /tidb-data/tiflash-9000 | /tidb-deploy/tiflash-9000 |
| tikv | 192.168.64.152 | 20160/20180 | /tidb-data/tikv-20160 | /tidb-deploy/tikv-20160 |
| tikv | 192.168.64.152 | 20161/20181 | /tidb-data/tikv-20161 | /tidb-deploy/tikv-20161 |
| tikv | 192.168.64.152 | 20162/20182 | /tidb-data/tikv-20162 | /tidb-deploy/tikv-20162 |
扩容TiKV节点
需要扩容一个TiKV节点
| 实例 | IP | 端口 | 存储路径 | 部署路径 |
|---|---|---|---|---|
| tikv | 192.168.64.152 | 20163/20183 | /tidb-data/tikv-20163 | /tidb-deploy/tikv-20163 |
编写扩容脚本
在 scale-out.yaml 文件添加扩容拓扑配置
COPYvi scale-out.yaml
COPYtikv_servers:- host: 192.168.64.152ssh_port: 22port: 20163status_port: 20183deploy_dir: /tidb-deploy/tikv-20163data_dir: /tidb-data/tikv-20163config:server.labels:host: logic-host-4
执行扩容命令
命令格式
COPYtiup cluster scale-out <cluster-name> scale-out.yaml -p
- cluster-name:TiDB集群名称
- p:使用密码方式登录当前机器
执行命令
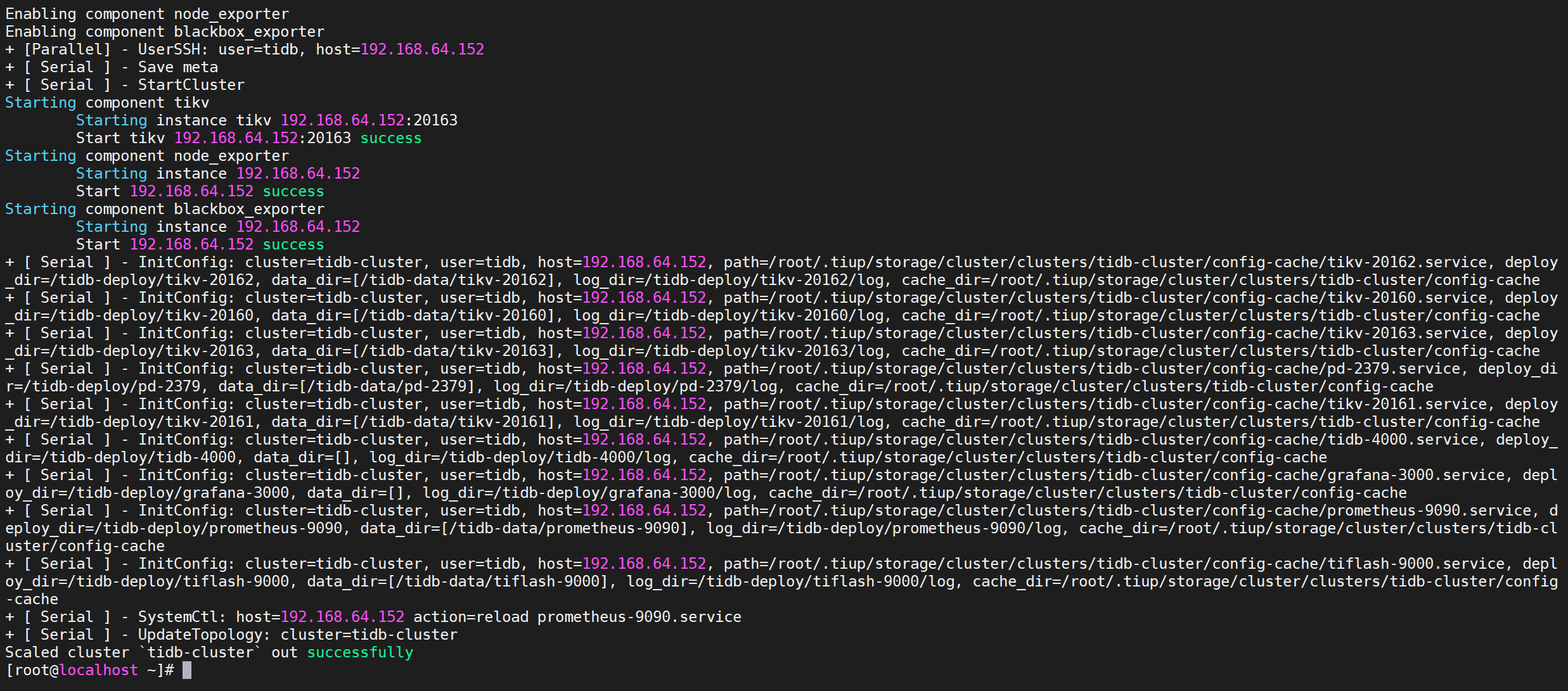
COPYtiup cluster scale-out tidb-cluster scale-out.yaml -p
输入命令后,确认输入机器密码

出现
successfully表示节点扩容成功
验证扩容信息
查看节点信息
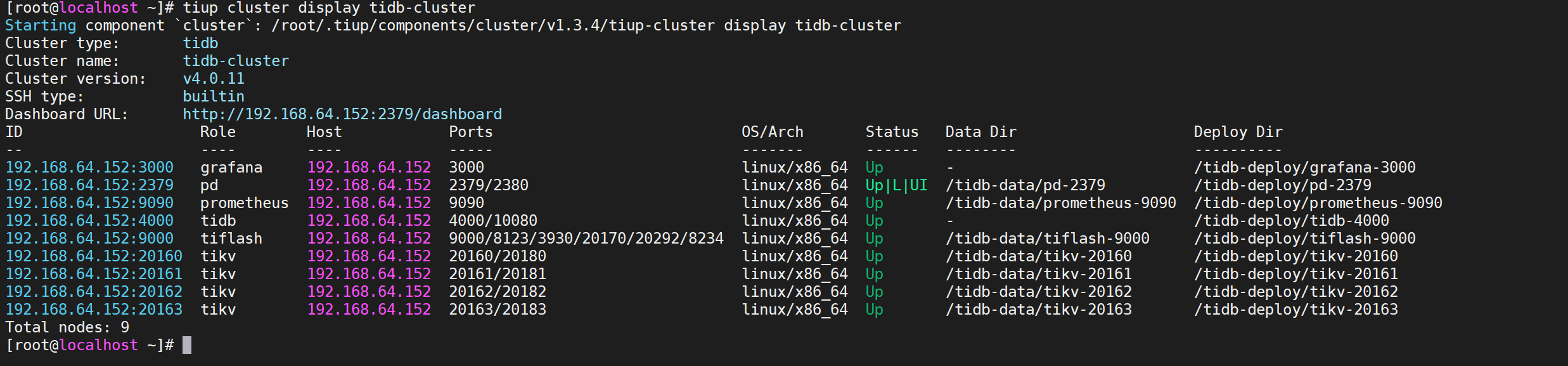
COPYtiup cluster display tidb-cluster
我们看到Tikv已经增加了一个节点
通过dashboard查看
也可以看到扩容的节点信息
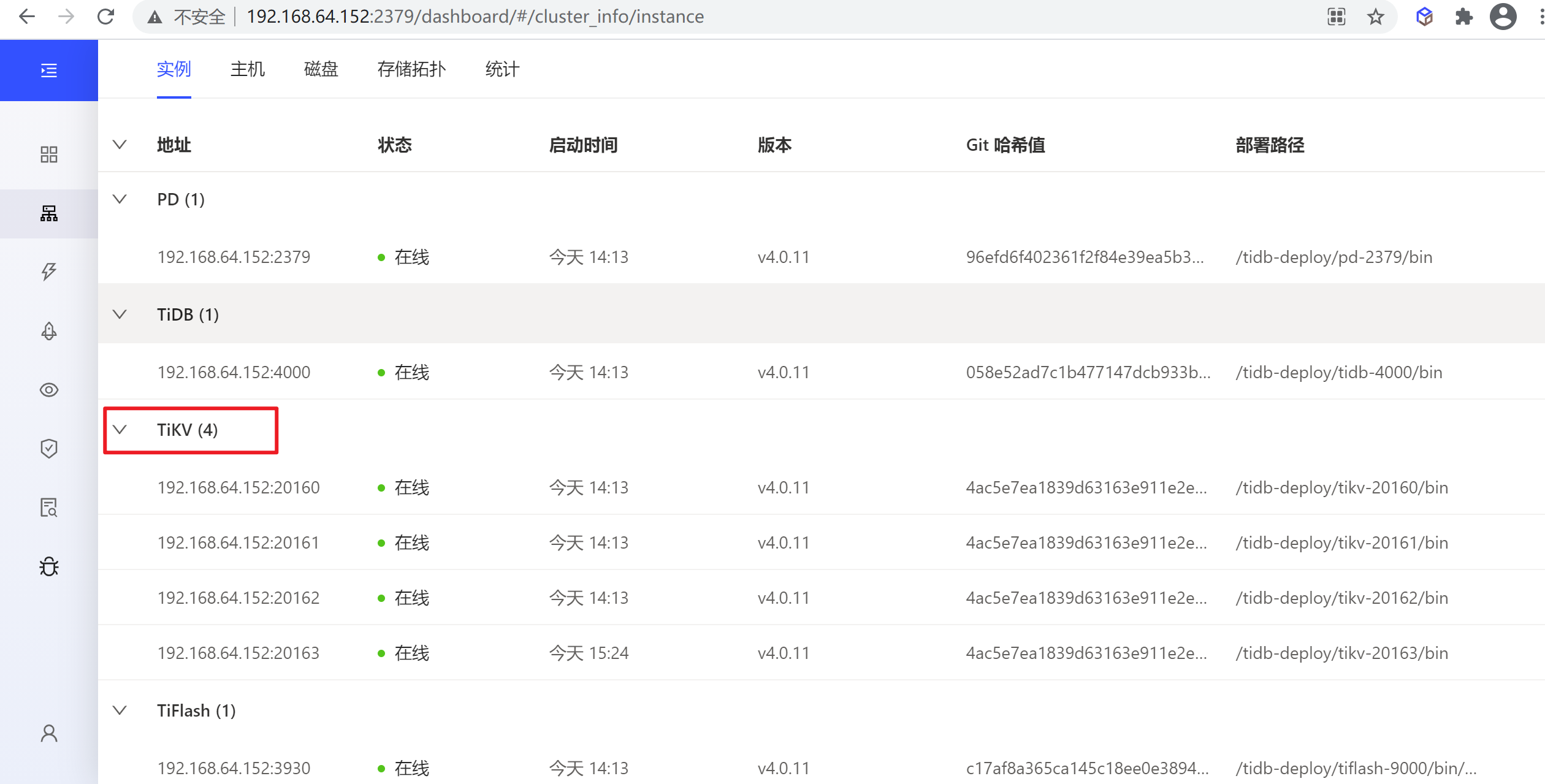
缩容TiKV节点
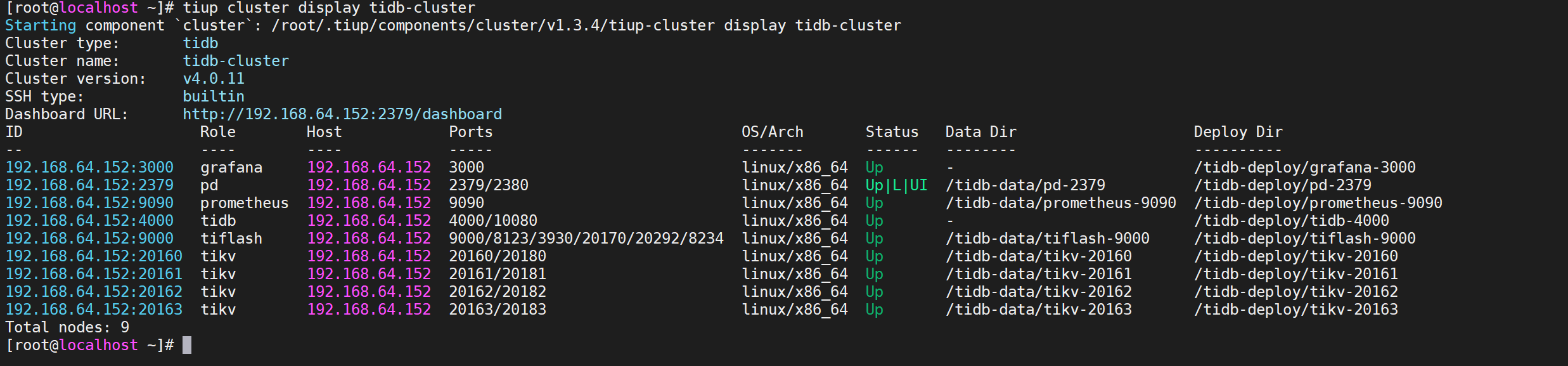
查看节点信息
COPYtiup cluster display tidb-cluster
当前TiKV是4个节点
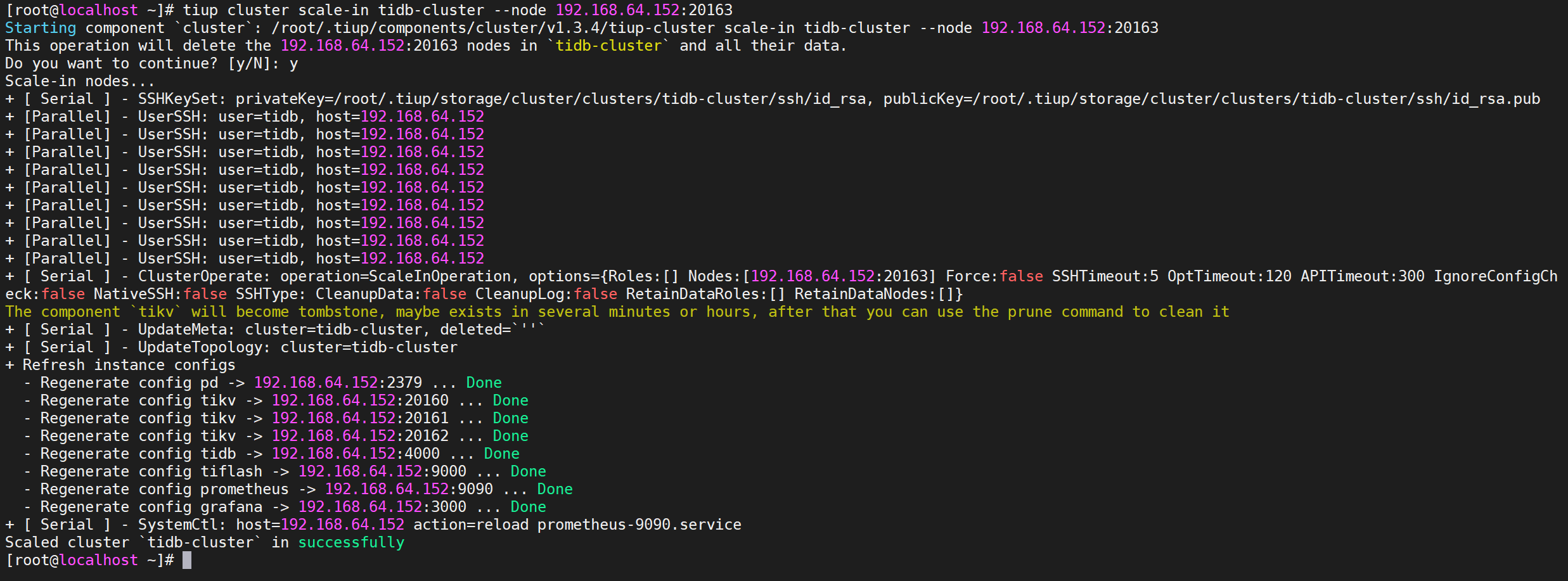
执行缩容操作
缩容命令
COPYtiup cluster scale-in <cluster-name> --node 192.168.64.152:20163
参数解释
- cluster-name:集群名称
- node:需要删除的节点地址
执行命令
COPYtiup cluster scale-in tidb-cluster --node 192.168.64.152:20163
出现确认操作后,输入y确认执行就可以执行缩容操作了
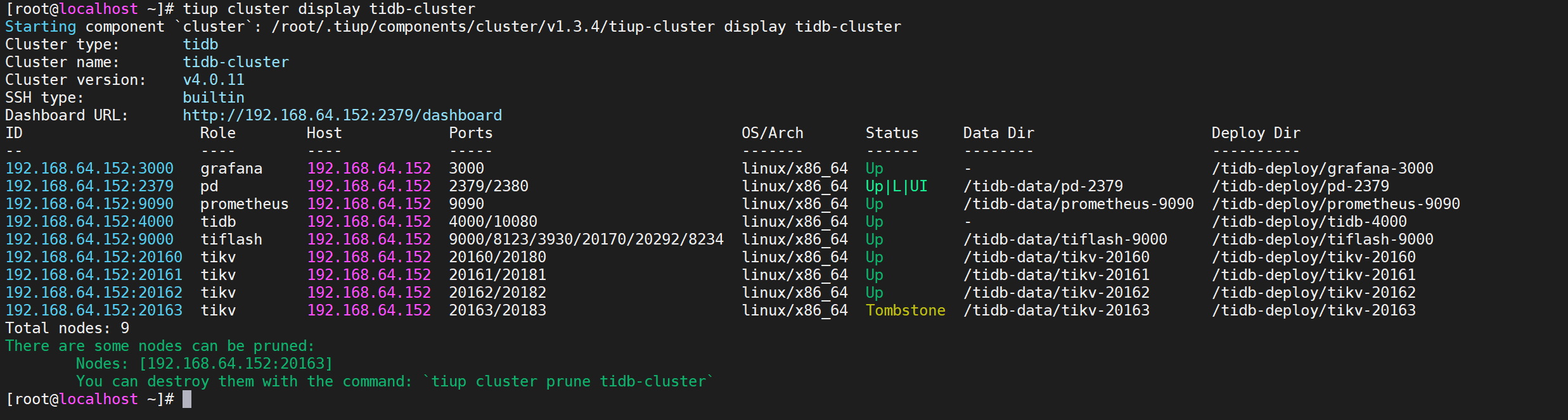
验证缩容信息
查看节点信息
COPYtiup cluster display tidb-cluster
我们看到需要缩容的节点状态是
Tombstone说明已经下线,下线需要一定时间,下线节点的状态变为Tombstone就说明下线成功
通过dashboard查看
也可以看到缩容的节点已经不存在了,说明缩容成功
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:http://www.baiyp.ren/TIDB%E9%9B%86%E7%BE%A4%E9%83%A8%E7%BD%B2.html
更新于:2021年5月27日
集群部署
TIDB
本文由
传智教育博学谷狂野架构师教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
这篇关于【必须收藏】别再乱找TiDB 集群部署教程了,这篇保姆级教程来帮你!!| 博学谷狂野架构师的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







