本文主要是介绍论文阅读:Seg4Reg Networks for Automated Spinal Curvature Estimation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Seg4Reg Networks for Automated Spinal Curvature Estimation
用于自动脊柱曲率估计的Seg4Reg网络
来源:腾讯优图AASCE第一名
源代码:https://github.com/hust-linyi/Seg4Reg
摘要
在本文中,我们提出了一种新的管道来进行精确的脊柱弯曲度估计。该框架名为Seg4Reg,包含两个深度神经网络,分别专注于分割和回归。基于分割模型产生的结果,回归网络直接从分割掩模预测Cobb角。为了缓解训练集和测试集之间出现的领域漂移问题,我们还在网络结构中引入了领域适配模块。最后,通过集成不同模型的预测,我们的方法在测试集中达到了21.71SMAPE。
介绍
青少年特发性脊柱侧弯(AIS)是脊柱侧弯的最常见形式,通常会影响至少10岁的儿童。如何准确估计脊柱弯曲在AIS的治疗计划中起着重要作用。目前AIS评估的临床标准依赖于医生的Cobb角测量。这种手动干预过程通常会使操作耗时并产生不可靠的结果。最近,深度神经网络在各种图像分类任务中取得了惊人的成就。如何将这些深度模型应用于脊柱曲率估计问题成为自动AIS评估的热点问题。BoostNet[5]用于自动地标估计的框架,该框架将卷积神经网络(ConvNet)的强大特征提取功能与统计方法相结合,以适应X射线图像的可变性。为了缓解遮挡问题,利用多视图X射线的特征已经开发了MVC-Net(多视图相关网络)[6]和 MVE-Net(多视图外推网)[1]。
【6】:Automated comprehensive Adolescent Idiopathic Scoliosis assessment using MVC-Net基于MVC-Net的青少年特发性脊柱侧凸综合自动化评估(2018MIA)
【1】An automated and accurate spine curve analysis system.一种自动化、准确的脊柱曲线分析系统。(2019access)
目前,估计Cobb角的方法有两种:
(A)预测地标,然后预测角度[5,6]
(B)回归角值[1]
第一种方法能够产生高精度的角度结果,但在很大程度上依赖于地标预测,这意味着坐标上的小错误可能会导致角度预测的大错误。相反,角度回归方法更稳定,但可能缺乏生成精确预测的能力。在本文中,我们探索了上述两个方向在MICCAI AASCE 2019挑战中的可能性,我们的实验结果表明,回归策略的表现优于里程碑式的方法。我们将在以下几节中进行更详细的介绍。
2、提出的方法
我们在图1中显示了我们的pipeline。整个过程由两个网络构成:一个用于分割,另一个用于回归。分段网络的结构类似于PSPNet[7],而回归部分采用传统的分类模型。
【7】Pyramid scene parsing network(2017cvpr)

图1.我们的管道概述。我们首先使用分割网络对X射线进行处理。请注意,我们使用提供的地标来形式化真实掩码。然后,将预测的掩模送到回归模型进行角度值预测。
2.1、预处理
我们观察到训练集和测试集之间存在明显的域差距(如图2所示)。
为了缓解这个问题,我们首先对这两个集合应用直方图均衡化,使它们在视觉上相似。考虑到测试图像的数量有限,我们决定手动裁剪这些x光片,以去除头骨,并将脊柱保持在适当的范围内。此外,我们还应用随机缩放(0.85到1.25)和随机旋转(−45◦到45◦)在训练过程中。我们尝试在输入图像中加入高斯噪声来缓解过拟合,但没有效果。

图2所示。训练集与测试集的比较。很明显,这两个集合存在着巨大的域差距。
对于分割任务,我们在提供的地标坐标上构建了groundtruth掩码。值得注意的是,我们发现添加另一个类“骨间间隙”有助于分割模型的最佳表现。我们认为这样的操作可以使训练过程规范化,从而使最终的预测更精确。
2.2、网络结构
我们按照[7]的说明来设计我们的细分网络。特征提取完成后,PSPNet[7]利用不同的池化核来捕获不同的接受域。为了保持feature map的大小,我们还将不同膨胀率的膨胀卷积添加到pooling金字塔中。如图1所示,我们使用2、4、6作为膨胀率,对卷积后的输出进行求和。
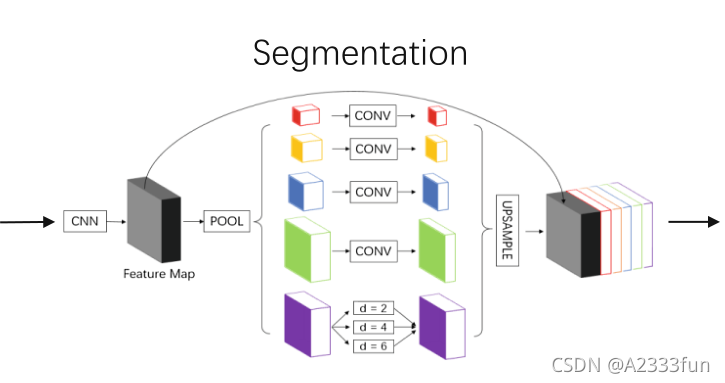
对于主干结构,我们简单地采用resnet - 50[4]和ResNet-101作为基本特征提取器(图3)。
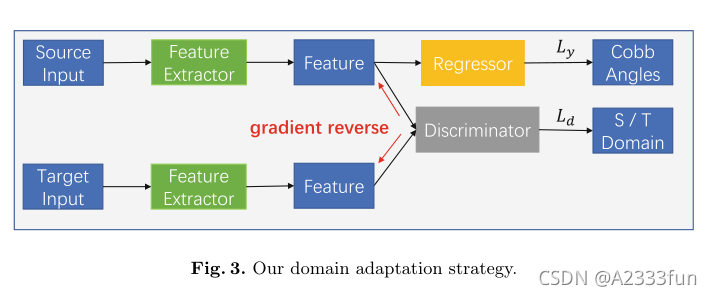
图3:我们的领域适应策略
在分类部分,我们直接使用最近的分类网络来执行回归任务。使用基于ImageNet的预训练是因为我们发现它在有限的训练样本下有很大的帮助。考虑到训练集和测试集之间的域差距,我们对[3]中的方法进行了改进。这个想法非常简单,它添加了一个鉴别器分支,并在反向传播过程中逆转其梯度,因此最终的损失函数可以形式化为:

其中λ在我们的实验中设为1。
2.3、网络训练
我们使用Adam作为初始学习率为3e−3的两个网络的默认优化器。β1和β2分别设为0.9和0.999。我们还使用了权值衰减(1e−5)和余弦退火策略。对于分割模型,我们运行每个网络50个纪元,而90个epoch似乎是更好的选择的回归模型。我们将分割输入调整为1024×512,回归输入调整为512×256。在4个NVIDIA P40 gpu上,批量大小为32。
3、实验结果
我们报告我们的实验结果在本地验证和在线测试集。注意,我们没有使用交叉验证。
3.1、本地验证
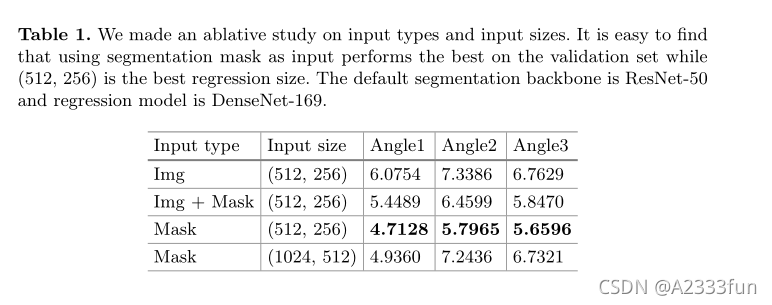
在这一部分中,我们报告了模型预测和groundtruth标签之间的L1距离。从表1可以看出,segmentation mask是最好的输入类型,(512,256)是最好的输入大小。
在表2中,我们比较了改进后的版本与PSPNet和DeepLab V3+[2]的性能。我们可以发现,增加一个膨胀金字塔从而提高了以往PSPNet的性能。有趣的是,PSPNet在PASCAL VOC分割任务中取得了与DeepLab V3+相当的性能,大大超过了DeepLab V3+。我们认为DeepLab的失败可以归因于有限的训练数据和我们的参数调优策略。

表2:PSPNet和DeepLab V3+的分割性能。
3.2、在线测试
我们将在线测试结果形式化到表3中。我们可以看到,我们的膨胀金字塔提高了在线SMAPE 0.48。此外,考虑到EfficientNet-b5的ImageNet性能比DenseNet-169更好,这是很正常的。加入域自适应模块后,单模型性能提高到26.15。在模型集成阶段,考虑模型的验证分数,对不同的模型输出赋予不同的权重。主要集成了ResNet系列、DenseNet系列和EfficientNet系列。这个策略帮助我们将SMAPE评分提高到22.25。

表3:PSPNet和DeepLab V3+的分割性能。
在在线测试阶段,我们重新考察了3个角度在训练集中的分布。从图4中我们可以很容易地发现,角2和角3比角2小得多。而且,Angle2有很多值都接近于零。根据这样的现象,我们减少的角度小于4◦到零,这带来了我们21.71 SMAPE。
这篇关于论文阅读:Seg4Reg Networks for Automated Spinal Curvature Estimation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)