本文主要是介绍LLaVA:大型语言和视觉助手,图片识别和理解能力让人惊叹,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01简介
视觉指令调整:针对多模式 GPT-4 级别功能而构建的大型语言和视觉助手。
视觉聊天:构建多模式 GPT-4 级聊天机器人 构建了包含 30 个未见过的图像的评估数据集:每个图像都与三种类型的指令相关联:对话、详细描述和复杂推理。这导致了 90 个新的语言图像指令,我们在这些指令上测试 LLaVA 和 GPT-4,并使用 GPT-4 对它们的响应进行评分,从 1 到 10 分。报告每种类型的总分和相对分数。总体而言,与 GPT-4 相比,LLaVA 获得了 85.1% 的相对分数,表明所提出的自指导方法在多模态设置中的有效性。
构建了包含 30 个未见过的图像的评估数据集:每个图像都与三种类型的指令相关联:对话、详细描述和复杂推理。这导致了 90 个新的语言图像指令,我们在这些指令上测试 LLaVA 和 GPT-4,并使用 GPT-4 对它们的响应进行评分,从 1 到 10 分。报告每种类型的总分和相对分数。总体而言,与 GPT-4 相比,LLaVA 获得了 85.1% 的相对分数,表明所提出的自指导方法在多模态设置中的有效性。
Science QA:LLaVA 与 GPT-4 协同作用的新 SoTA
 仅 LLaVA 就达到了 90.92%。我们使用纯文本的 GPT-4 作为判断,根据它自己之前的答案和 LLaVA 答案来预测最终答案。这个“GPT-4 作为判断”方案产生了新的 SOTA 92.53%。
仅 LLaVA 就达到了 90.92%。我们使用纯文本的 GPT-4 作为判断,根据它自己之前的答案和 LLaVA 答案来预测最终答案。这个“GPT-4 作为判断”方案产生了新的 SOTA 92.53%。
视觉指令跟随示例
OpenAI GPT-4 技术报告中两个示例的视觉推理

光学字符识别 (OCR)
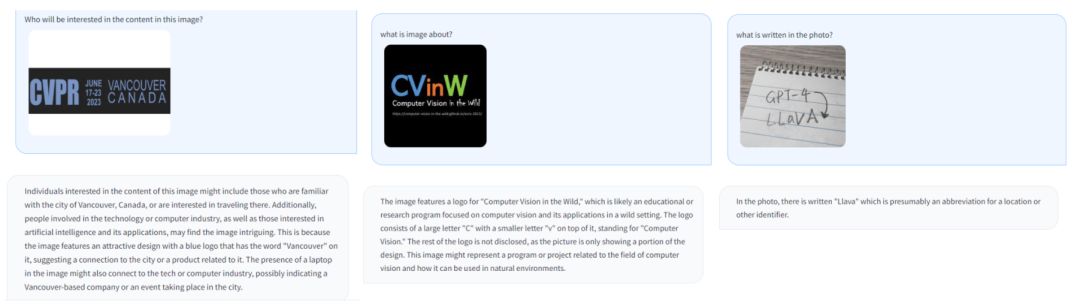
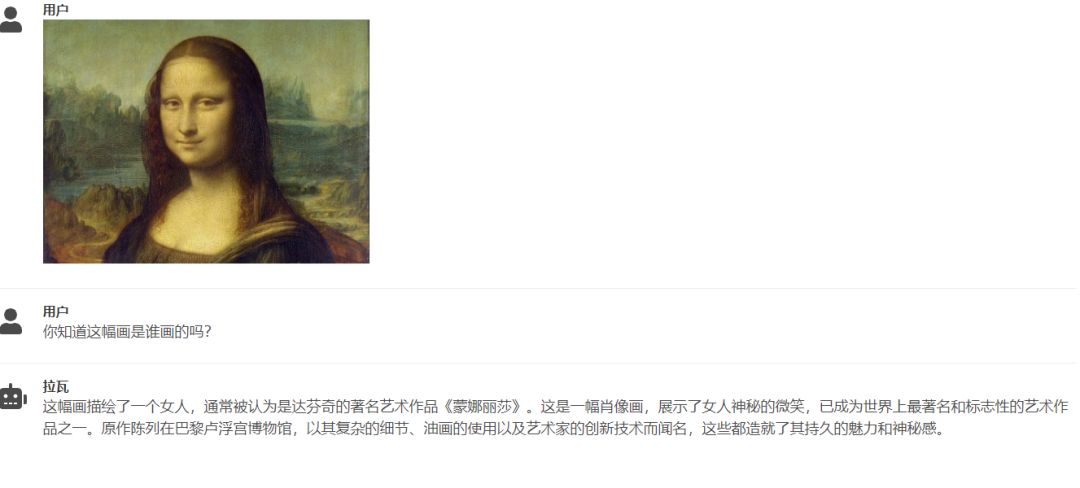
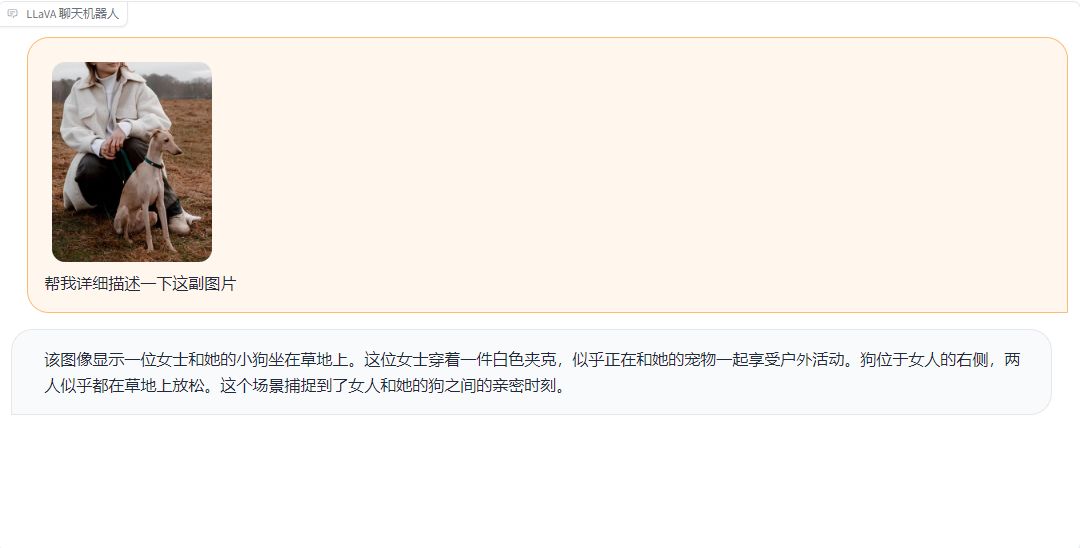
效果展示

02安装
- 克隆此存储库并导航到 LLaVA 文件夹
git clone https://github.com/haotian-liu/LLaVA.gitcd LLaVA
2. 安装包
conda create -n llava python=3.10 -yconda activate llavapip install --upgrade pip # enable PEP 660 supportpip install -e .
3.安装附加包
pip install ninjapip install flash-attn --no-build-isolation
升级到最新的代码库
git pullpip uninstall transformerspip install -e .
03演示
要运行我们的演示,您需要在本地准备 LLaVA 检查点。请按照此处的说明下载检查点。
渐变网页用户界面
要在本地启动 Gradio 演示,请一一运行以下命令。如果您计划启动多个模型工作人员以在不同检查点之间进行比较,则只需启动控制器和 Web 服务器一次。
启动控制器
python -m llava.serve.controller --host 0.0.0.0 --port 10000
启动 gradio Web 服务器。
python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload您刚刚启动了 Gradio Web 界面。现在,您可以打开 Web 界面,并将 URL 打印在屏幕上。您可能会注意到模型列表中没有模型。别担心,我们还没有推出任何劳模。当您启动模型工作人员时,它将自动更新。这是在 GPU 上执行推理的实际工作程序。每个工作人员负责 中指定的单个模型--model-path。
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b等到进程完成加载模型,您会看到“Uvicorn running on ...”。
现在,刷新您的 Gradio Web UI,您将在模型列表中看到刚刚启动的模型。您可以根据需要启动任意数量的工作程序,并在同一 Gradio 界面中比较不同模型检查点。请保持不变,并将和--controller修改为每个worker的不同端口号。--port--worker
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port <different from 40000, say 40001> --worker http://localhost:<change accordingly, i.e. 40001> --model-path <ckpt2>
如果您使用的是带有 M1 或 M2 芯片的 Apple 设备,则可以使用标志指定 mps 设备--device:--device mps。
多个 GPU,当 GPU VRAM <= 24GB 时
如果您的 GPU 的 VRA 小于 24GB(例如 RTX3090、RTX 4090 等),您可以尝试使用多个 GPU 运行它。如果您有多个 GPU,我们最新的代码库将自动尝试使用多个 GPU。您可以指定要使用哪些 GPU CUDA_VISIBLE_DEVICES。下面是使用前两个 GPU 运行的示例。
CUDA_VISIBLE_DEVICES=0,1 python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b
(4位、8位推理、量化)
您可以使用量化位(4 位、8 位)启动模型工作线程,这样您就可以在减少 GPU 内存占用的情况下运行推理,从而有可能在具有低至 12GB VRAM 的 GPU 上运行。请注意,使用量化位进行的推理可能不如全精度模型准确。只需将--load-4bit或附加--load-8bit到您正在执行的
模型工作器命令即可。下面是使用 4 位量化运行的示例。python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b --load-4bit
(LoRA 权重,未合并)
您可以启动具有 LoRA 权重的模型工作线程,无需将它们与基本检查点合并,以节省磁盘空间。会有额外的加载时间,而推理速度与合并检查点相同。未合并的 LoRA 检查点在型号名称中没有lora-merge,并且通常比合并的检查点小得多(小于 1GB)(7B 为 13G,13B 为 25G)。要加载未合并的 LoRA 权重,您只需传递一个附加参数--model-base,它是用于训练 LoRA 权重的基础 LLM。您可以在模型动物园中检查每个 LoRA 权重的基础 LLM 。
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1-0719-336px-lora-vicuna-13b-v1.3 --model-base lmsys/vicuna-13b-v1.3
这篇关于LLaVA:大型语言和视觉助手,图片识别和理解能力让人惊叹的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







