本文主要是介绍零基础入门数据挖掘 - 二手车交易价格预测 赛题理解和EDA,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
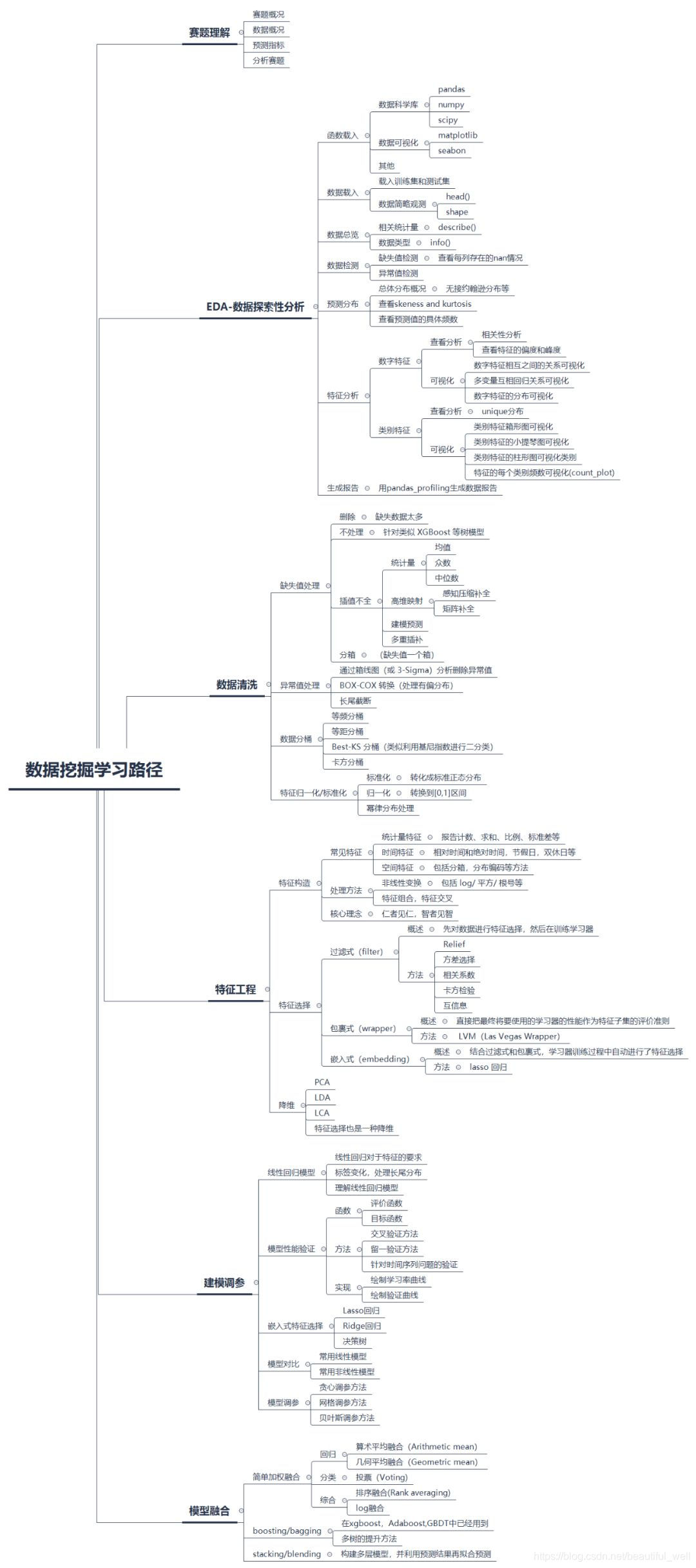
这个是DataWhale在本次数据挖掘竞赛提供的学习思路图。
赛题以预测二手车的交易价格为任务,数据集报名后可见并可下载,该数据来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取15万条作为训练集,5万条作为测试集A,5万条作为测试集B,同时会对name、model、brand和regionCode等信息进行脱敏。


不同的评价指标关注的点不同

赛题理解究竟是理解什么:回归问题,根据二手车的一些特征做预测。有了赛题理解后能做什么:对数据EDA。赛题背景中可能潜在隐藏的条件:数据缺失、漂移,对特征工程中时序分析的处理。
EDA定义:1、理解数据的特征;2、考虑是什么类型的数据:结构化、非结构化等;3、选取重要度特征;
4、找到异常点 5、为问题寻找合适的方法。
绘图方法: 1、画数据的原始图像是否有规律。 2、画数据的统计图(平均图、盒图、残差图)。3、离散图说明特征。
量化方法:1、预测区间估计。2、数值的度量。3、数据分布的类型。
时序图:便于观察数据特点,例如,是否具有周期性,震荡性。
直方图:便于观察数据分布。
密度曲线图:可以理解为概率密度函数。
箱型图:便于查看数据的异常状况,以便不同数据间分布的对比。
相关性分析:1、定类变量:名义型变量;性别 。
2、定序变量:不仅分类,还按某种特征排序;两值的差无意义;教育程度 。
3、定距变量:可比较大小、差有意义的变量。
| 定类 | 定序 | 定距 | |
| 定类 | 卡方类测量 | 卡方类测量 | Eta系数 |
| 定序 | Spearman 相关系数 同序-异序对测量 | Spearman相关系数 | |
| 定距 | Pearson相关系数 |

代码实战:
数据概览:1、describe种有每列的统计量,个数count、平均值mean、方差std、最小值min、中位数25%50%75%
以及最大值。2、info通过info来了解数据每列的type,有助于了解
是否存在处理Nan以外的特殊符号异常。
判断缺失与异常:1、使用is_null函数查看缺失 2、使用value_count函数查看数据情况。
绘制数据分布: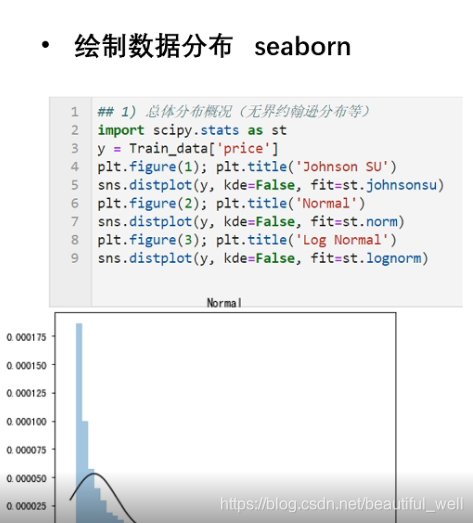
统计数值变量相关性热力图: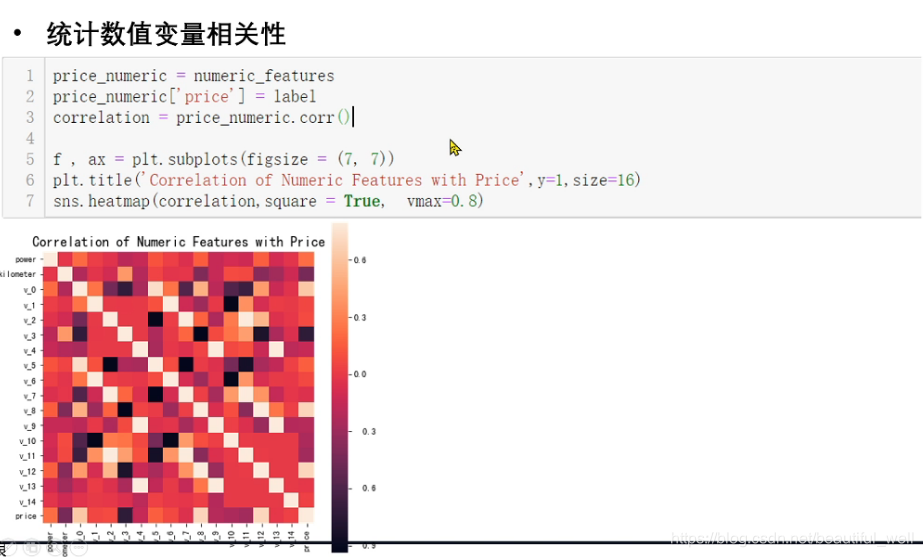
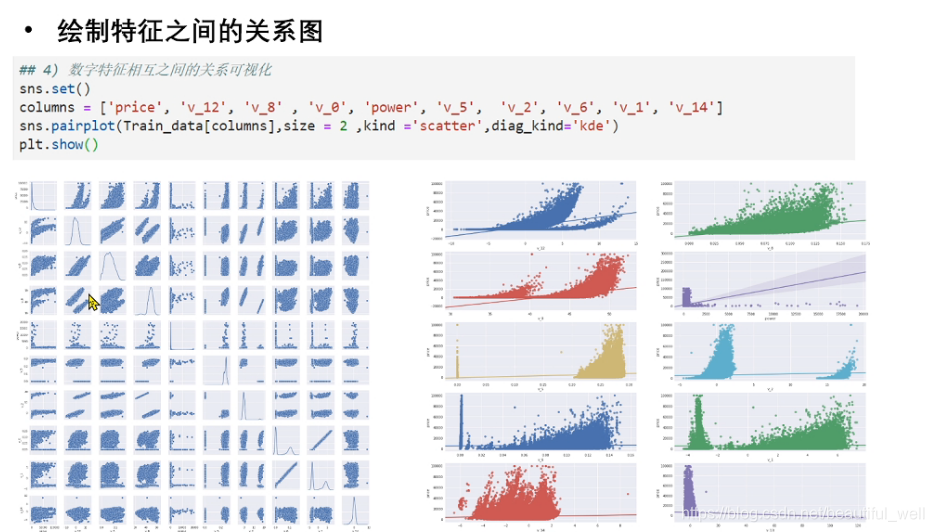
绘制特征之间的关系图:数字特征相互之间的关系可视化
绘制类别分布图

这篇关于零基础入门数据挖掘 - 二手车交易价格预测 赛题理解和EDA的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





