本文主要是介绍深度解析集成服务云的多重启动机制:数据集成更智能,业务流畅畅行无阻,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
集成方案的“点火”时刻!花式启动数据集成
在这篇文章中,我们将探讨轻易云集成服务云的集成方案启动机制,以助您在企业数据集成中灵活应对各种需求,确保数据自由流动。
启动方案是什么
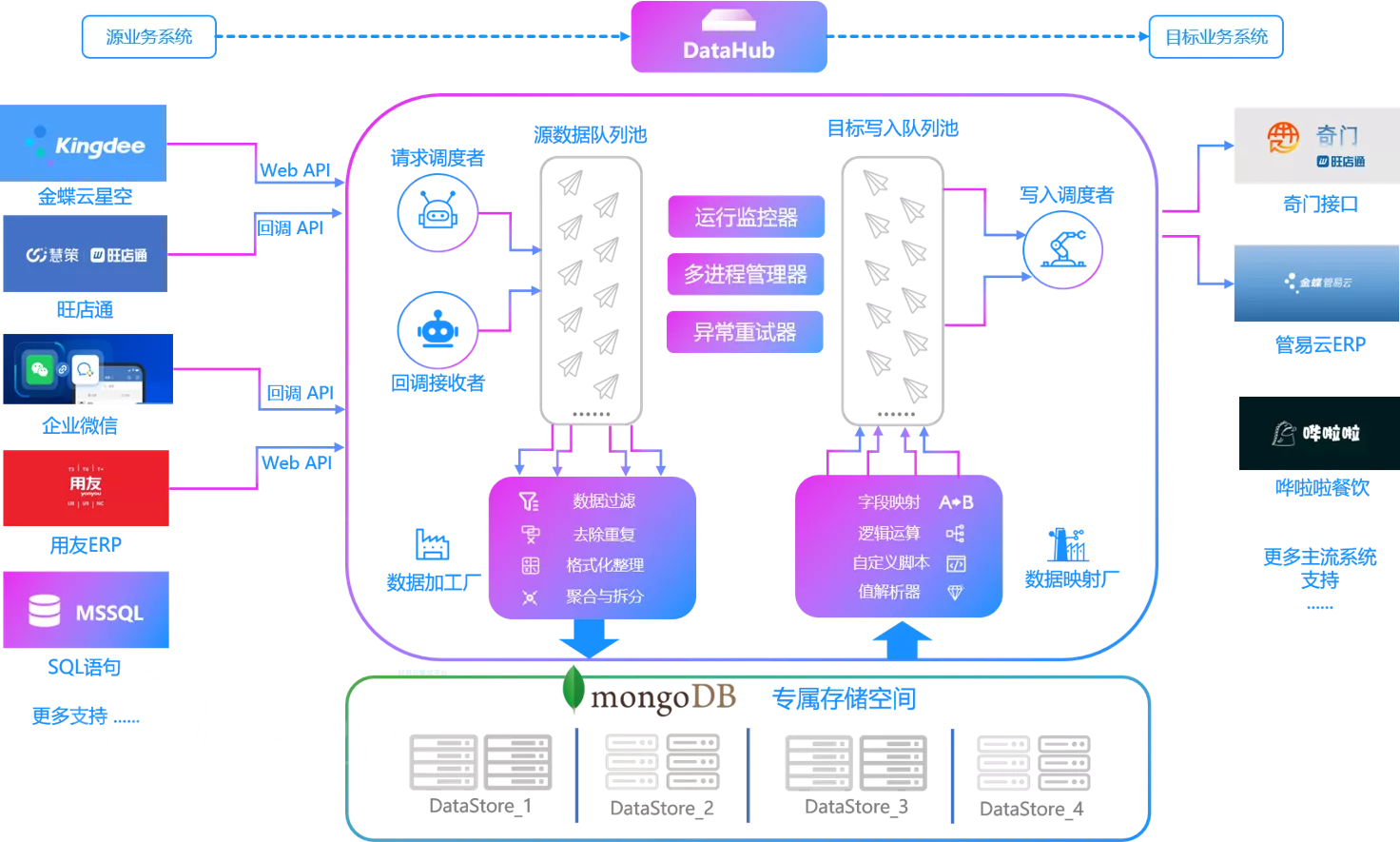
启动方案是指集成方案启动执行的方式。轻易云集成服务云提供了四种启动方式,包括人工启动、定时启动、事件触发、消息启动,允许在同一数据集成方案中设计多种启动方式,以满足不同业务需求。
1. 人工启动
这种方式仅支持手动触发执行,适用于调试、测试环境或同步时效要求较低的场景。它通常用于以下情况:
- 新建数据集成方案测试,可通过筛选条件过滤一条数据来测试集成方案的连通性。
- 历史数据迁移,用于将系统间的历史数据迁移到目标系统。
2. 定时启动
在定时启动中,集成方案会在配置的执行计划时间范围内按照执行频率启动执行。这适用于需要在特定时间点批量同步数据的场景。
3. 事件触发
事件触发方式在源系统发生与配置的事件相符的操作时触发集成方案执行。这种方式适用于同步时效要求极高或上下游业务有依赖的场景。同时,事件触发也支持人工执行,可用作事件监听或同步失败后的补偿机制。
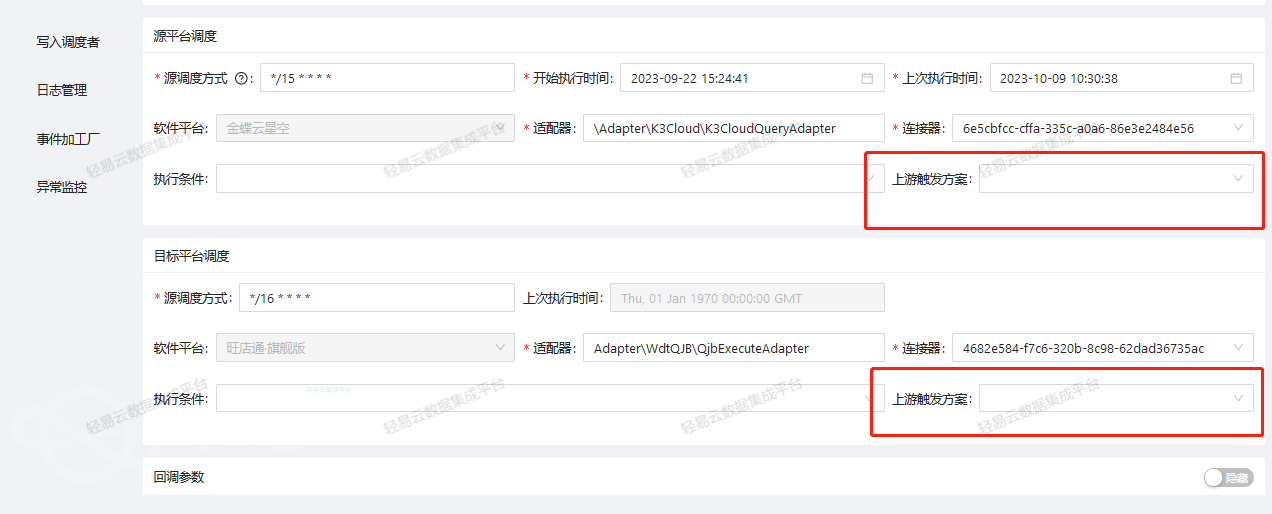
4. 消息启动
消息启动方式则在配置的“消息订阅主题”对应的消息队列中产生消息时触发执行。这适用于大批量数据异步分批处理的场景。
使用场景
现在,我们将通过两个数据集成方案的不同启动方式来更详细地介绍它们的使用场景。
No.1 数据初始化
如果您需要将demo1的全量数据一次性同步到demo2中,您可以选择“人工启动”类型的启动方案,并立即执行。这种方式还适用于以下场景:
- 新建的数据集成方案测试,通过筛选条件过滤一条数据来测试集成方案连通性。
- 系统间的历史数据迁移。
No.2 增量实时同步
如果您需要实时同步demo1中的数据到demo2,可以选择“事件触发”类型的启动方案。当demo1中点击“保存”按钮时,系统会监听到“保存(新增/修改)”事件,并立即将该条数据同步到demo2中。这种方式也适用于其他实时同步场景,如:
- 费用报销单在费控系统审核后实时同步到财务系统。
- 供应商在SRM系统新增后实时同步到ERP系统。
No.3 定时补偿
对于需要定时补偿同步失败数据或失效事件触发的情况,您可以选择“定时启动”类型的启动方案。系统将按照执行计划定时启动集成方案,将失效事件触发或其他同步失败数据补偿同步到demo2中。其他定时启动应用场景包括:
- 每日定时同步新增客户信息。
- 每月定时将会计凭证同步到报表系统。
以上是一些典型的使用场景,适用于常见的集成需求。您还可以根据不同启动方式设置多个启动方案,灵活搭配使用,确保企业数据自由流动,提高数据集成的效率。
希望本文能够帮助您更好地理解轻易云集成服务云的集成方案启动机制,并在实际应用中取得更好的效果。让数据集成变得更加轻松和高效!
在轻易云数据集成平台,我们提供全面的一站式服务,包括数据采集、实时数据传输、数据清洗、API开发、API测试、API编排以及API管理等功能。我们专注于解决大型企业系统及数据的复杂集成场景,为您的业务创新和数字化转型提供强大支持。不论您需要集成金蝶、用友、SAP、泛微、致远、ERP、MES、CRM、OA、营销中台、WMS、AI或数据库,我们的集成知识库都能为您提供实际示例和解决方案。
这篇关于深度解析集成服务云的多重启动机制:数据集成更智能,业务流畅畅行无阻的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









