本文主要是介绍AI算力基础 _Systolic Array的实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
阅读总结
Google的TPU是AI_ASIC芯片的鼻祖,从论文的作者数量之庞大,及论文少有的出现了致谢,就可以看出一定是历经了一番磨砺才创造出来。该论文发表在 2017 年,让我们回到那个年代,一同看看是什么样的背景诞生了如此伟大的艺术品~
0. 背景
作者:H.T.Kung 1982.
年份:1982.
标题:《Why Systolic Architecture?》
关键词:
cost-effectiveness:成本高效益
concurrency:并发性
decompose:分解
massive parallelism:大规模并行
Why Systolic Architecuture? H.T.Kung 1982
Systolic architectures, which permit multiple computations for each memory access, can speed execution of compute-bound problems without increasing I/O requirements.
Systolic architectures, which permit multiple computations for each memory access, can speed execution of compute-bound problems without increasing I/O requirements.
Systolic 结构,在不增加 IO 需求前提下,加速 compute-bound 问题的解决.

0.1 Key architectual issues in designing special-purpose systems
①Simple and regular design:可以降低设计成本,通过模块化实现成本与性能成比例;
Simple and regular design
②Concurrency and communication:由于器件速度的限制,可通过大量并行和降低路由成本加快运算速度;
Concurrency and communication
③Balancing computation with I/O:I/O制约了最大运算速率,所以需要分解运算以减少I/O,平衡I/O需求、系统规模、存储大小之前的关系,探寻I/O带宽对速度的影响
Balancing computation with I/O
0.2 Systolic architectures: the basic principle
脉动阵列的基本原理
基本定义
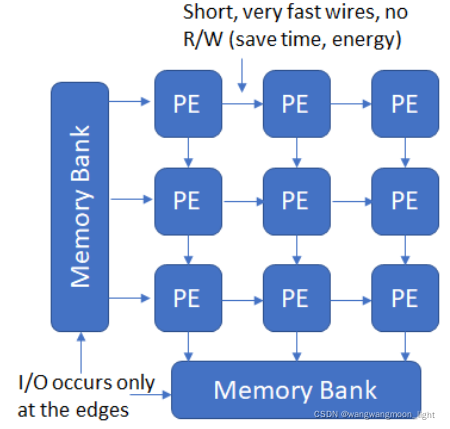
A systolic system consists of a set of interconnected cells, each capable of performing some simple operation.
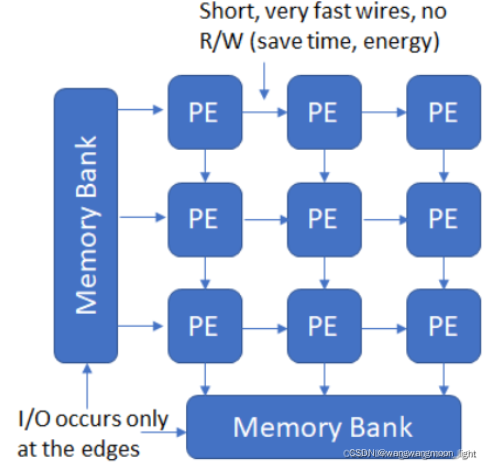
Cells in a systolic system are typically interconnected to form a systolic array or a systolic tree. Information in a systolic system flows between cells in a pipelined fashion, and communication with the outside world occurs only at the “boundary cells.” For example, in a systolic array, only those cells on the array boundaries may be I/O ports for the system.
计算任务分类
Computational tasks can be conceptually classified into two families-compute-bound computations and I/O-bound computations
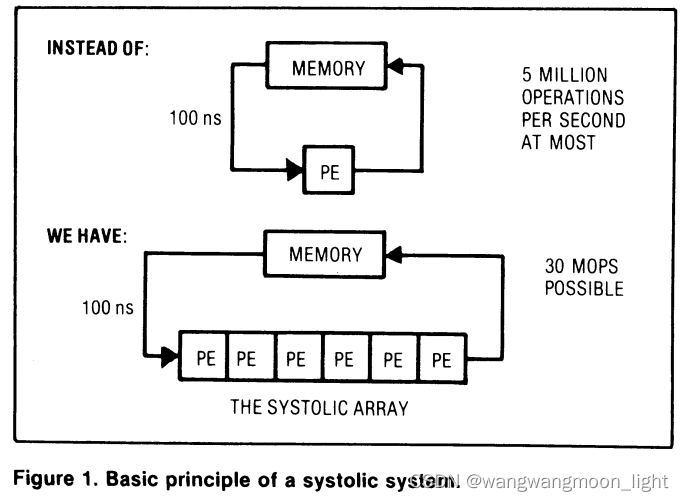
如图,将传统的单个处理单元替换为PE阵列,数据从MEMORY中流出,并沿着PE阵列流过每个PE,实现重复使用。
0.3 A family of systolic designs for the convolution computation

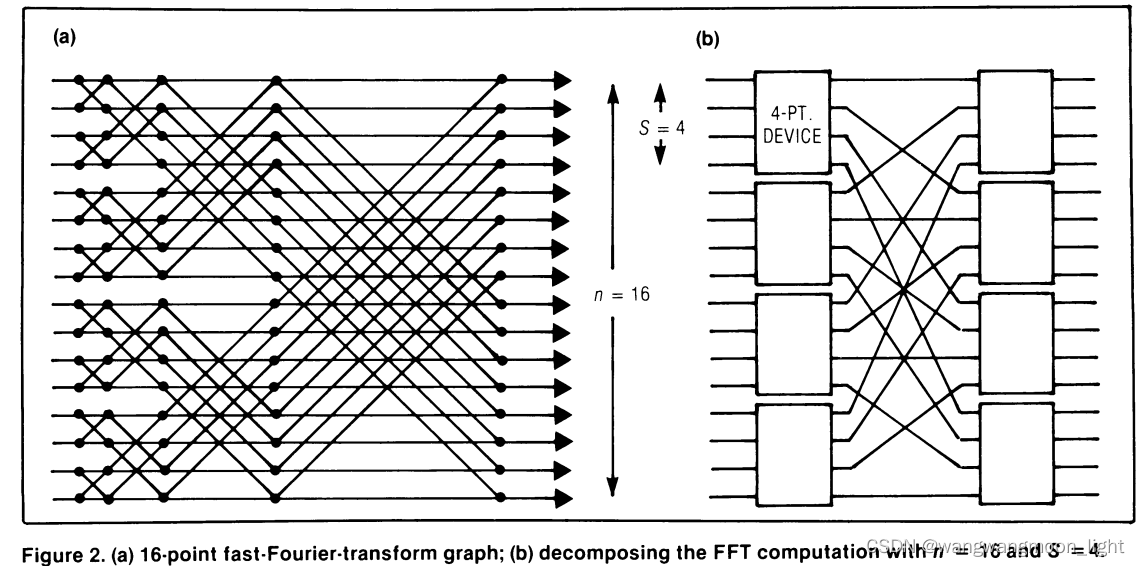
以FFT为例,
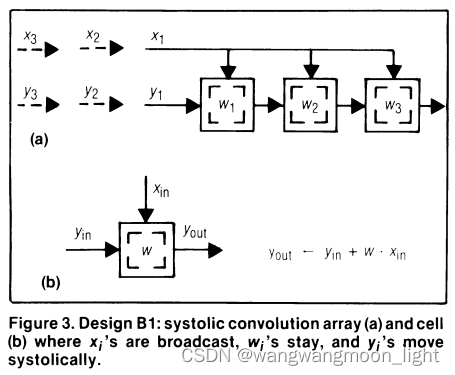
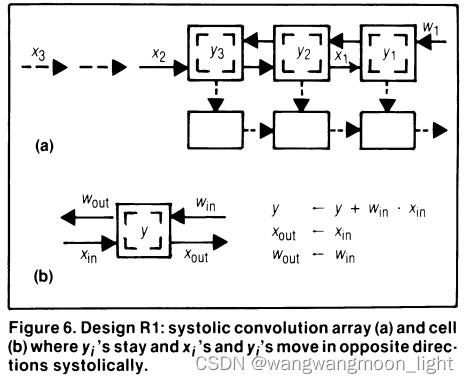
DesignB1: Wi 是保持不动,Yi周期性移动,Xi广播到每个W的值
DesignB2:Yi 是保持不动,Xi是广播,Wi是周期性移动

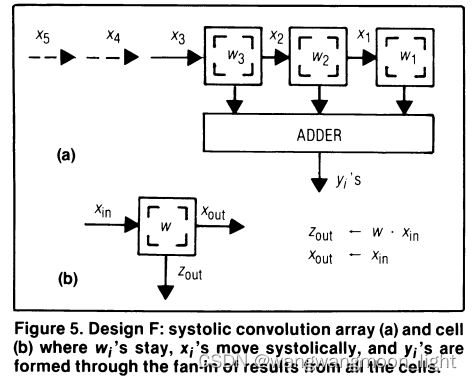
And their results are fanned-in and summed using an adder to form a new yi.

1.0 Systolic Array实现
Google TPUv1.0 谈及了脉动矩阵,但其由来并没有细说,此篇博客记录脉动矩阵的由来,参考下述链接:https://www.telesens.co/2018/07/30/systolic-architectures/

1.1 Systolic Architectures
Information 可以以流水线的方式在单元之间直接流动,这解决了我们前面提到的存储/加载中间结果的问题,与外界的通信只发生在边界Cell。
这里我们补充卷积运算的定义
为了使这些想法更加具体,让我们考虑一下如何使用三个“处理元素”(PEs)的收缩数组来实现卷积的密切对应关系。相关操作可以表示为:
因此,输出可以通过权向量与时移输入向量的点积来计算。让我们计算一下这个运算的结果。
操作的数量: 3次乘/ 2次加
I/O操作: 读取一个输入元素,回写一个输出元素
我们可以将相关操作分解为单独的乘法和加法运算,并在单独的PE上执行每个计算。
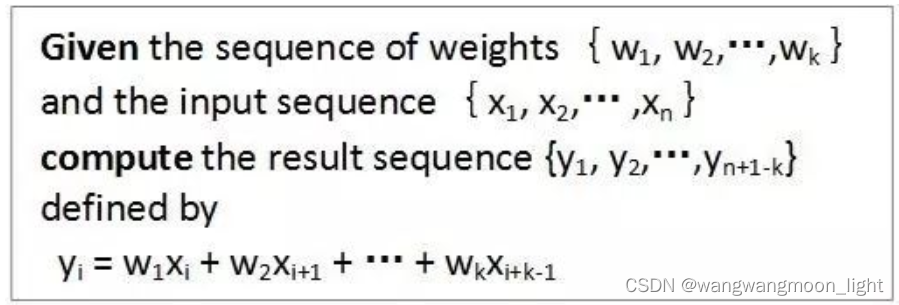
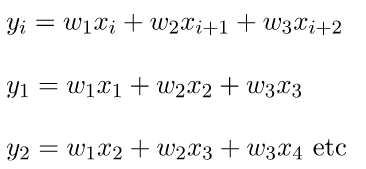
设计1 – Weight Stay stationnary:
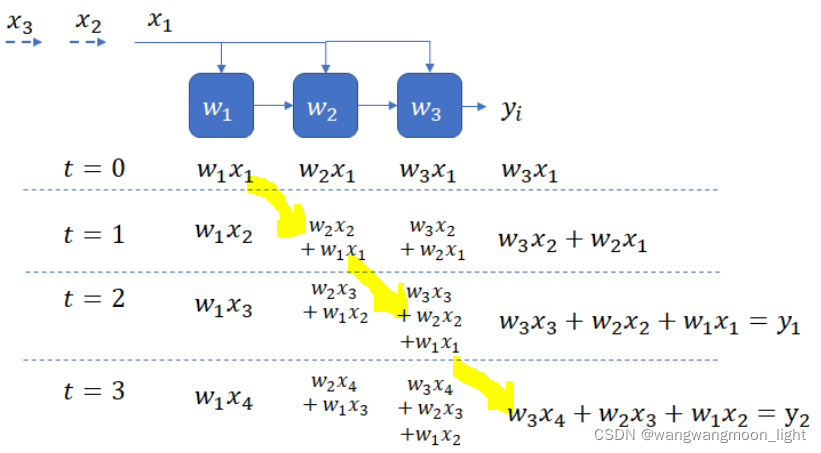
This design is an example of a “weight stationary” design, as the weights stay stationary and the inputs are streamed in. (weight没有变,而inputs在流动)
因此,arithmetic intensity 为5/2。对于k维关联,arithmetic intensity 为(2k-1)/2
这种高算术强度是由于高数据重用——输出向量的每个元素重用已经读取的两个数据点。低人工智能操作受到内存的限制,因此通过增加并行化或增加时钟率来更快地执行计算是没有帮助的。
优化设计:
In this design, each x_i is being broadcast to all PEs. Another alternative is to cycle the x_i sequentially through the PEs and and sum the partial sums using an adder.
在这个设计中,每个 Xi 都被广播到所有 PE,另一种选择是循环 Xi 顺序通过 PE 和和 部分和 使用加法器。

每个PE只是简单地实现乘法操作。加的操作已移动到全局累加器。
这两种设计的缺点是,要么必须将输入的每个元素广播到所有pe(在第一个设计中),要么必须收集部分输出并发送到累加器。这样做需要使用总线,总线必须随着相关窗口大小的增加而缩放.
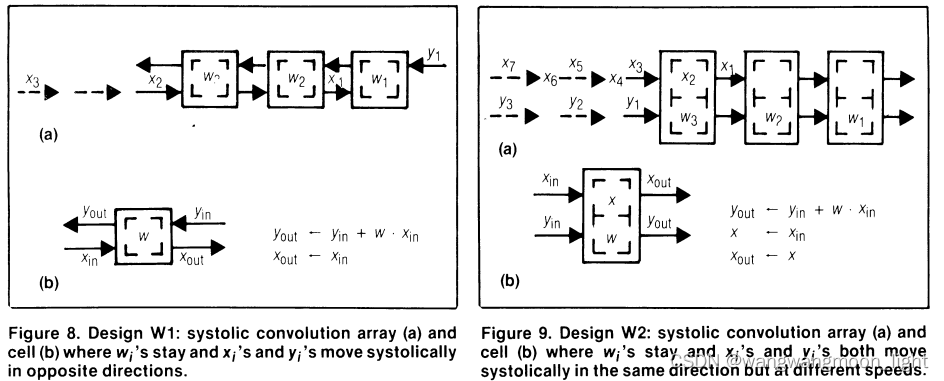
设计2 – Output stationnary:
结果保持不变,输入和权重向相反的方向移动。
Weight 和 Input 系列间隔了 One Time Step的含义是:
Weight 每一拍都会走,但 Weight 间隔一拍进来;
X 每一拍都会进来,但会间隔一拍走;
起始时X1会直接一拍通过空的PE到队尾,X2也是类似;
每个PE存储和积累部分结果。Xi 和 Wi 的收缩方向相反,当 X 与 W 相交时,它们相乘得到的结果与 PE 处的部分结果相加。Weight 从右往左走,Input 由左向右走,红色点点代表它们相交,相交会做乘加运算。

这种设计不需要总线或任何其他全球网络来收集pe的输出。由断裂箭头指示的收缩输出路径就足够了。
虽然这种设计解决了全局总线的问题,但它有一个缺点,即每个 PE 只在一半的时间内执行有用的工作(如红点所示)。当 PE 完成 Yi 的计算时,还需要额外的逻辑来重置PE中的累加器。
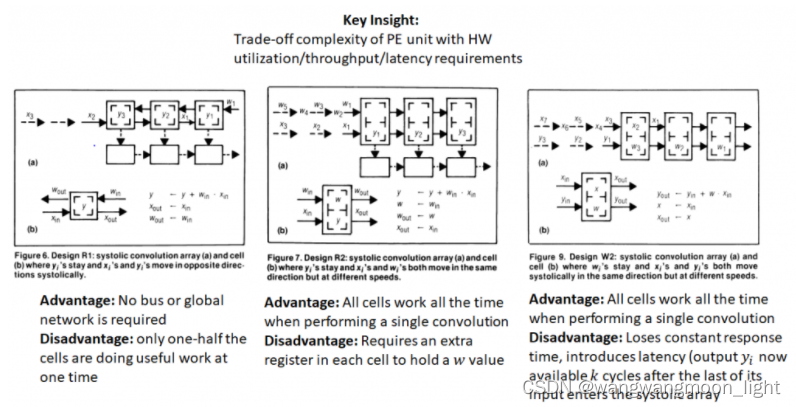
需要理解的关键点是,通过调整PE和周围硬件(总线、定时硬件等)的复杂性,可以在硬件利用率(PE做有用工作的频率)、吞吐量和延迟之间进行各种权衡。
2. Matrix Multiplication on a Weight Stationary 2D Systolic Array
TPU的 核心 是由一个 N * N (N=256) 的 multiple - accumulate, MAC 单元网格组成的收缩压阵列。该TPU采用一种 Weight-Stationary 的架构,其中权重被 Preloaded 到 MAC 阵列,激活从激活存储缓冲区进行。激活水平地从左到右移动,partial sum 垂直地从上到下移动。Matrix Product 反馈给激活单元,为常见的激活功能提供硬件支持。
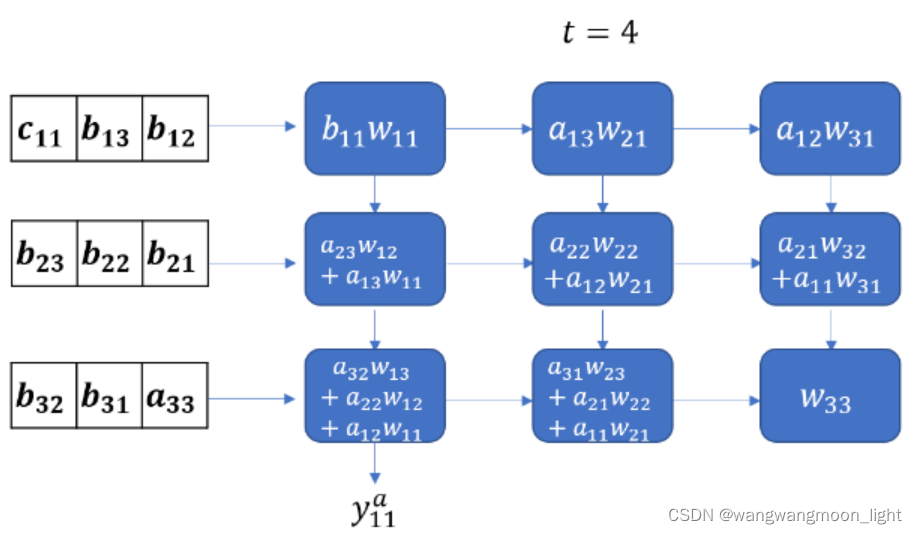
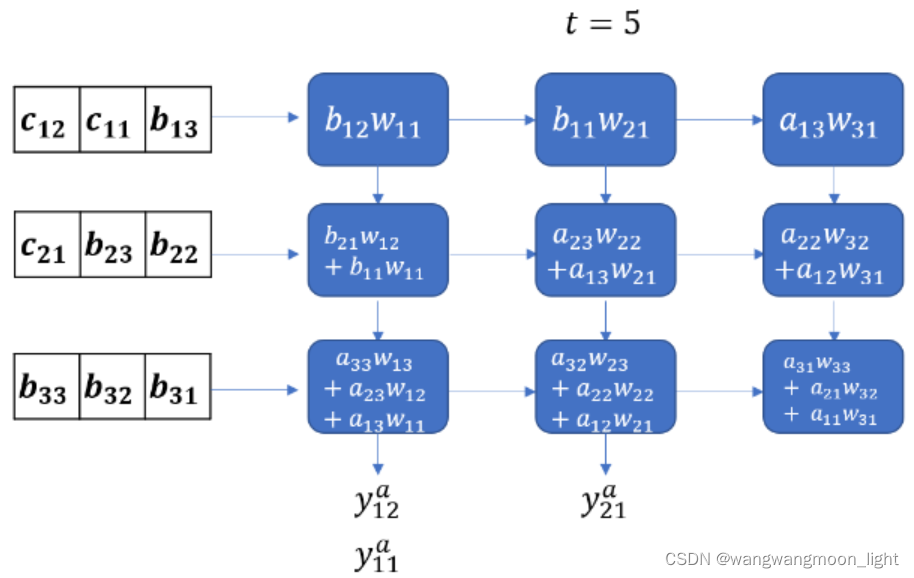
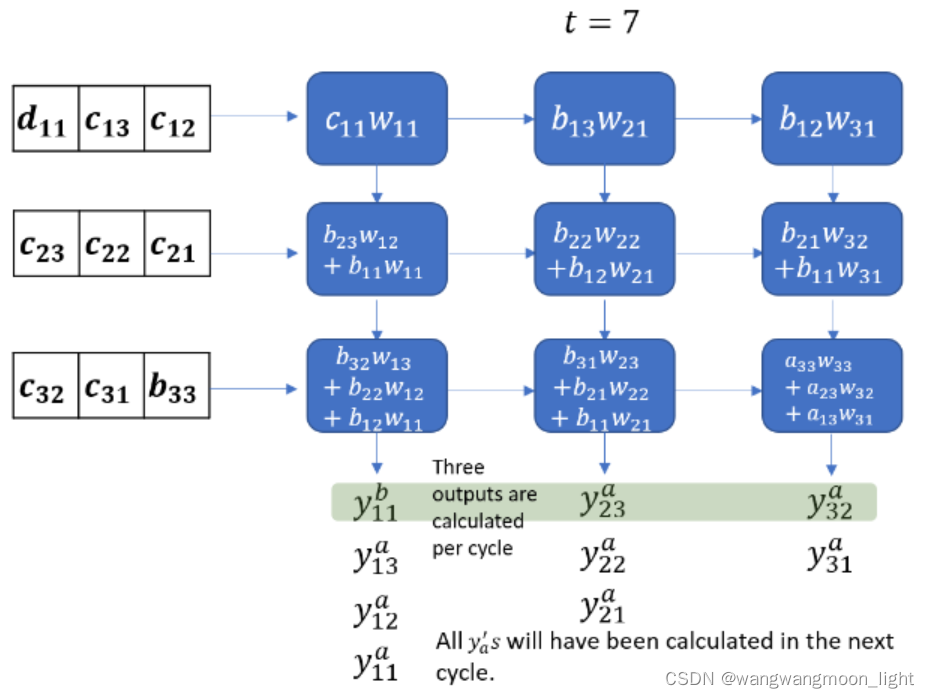
下面的动画显示了两个3 3 矩阵的激活流和部分和。权重矩阵W被预加载到MAC单元中,输入矩阵A, B, C从左边进入。每个输入矩阵的行在时间上是偏移的。权重矩阵和输入矩阵的乘积用Y表示,其中Ya = WA, Yb = WB 等
Weight是不变的。
Coming back to our discussion, from this animation, it should be clear that it takes 2N-1 cycles to read all elements of the product of two N\times N matrices.
回到我们的讨论,从这个动画中可以清楚地看到,读取两个N * N矩阵乘积的所有元素需要 2N-1个周期。(33 矩阵花了 7个cycles )
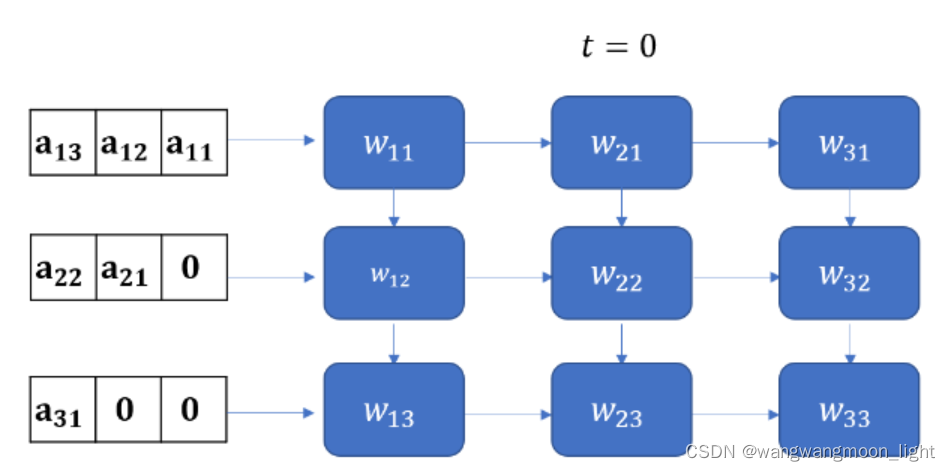
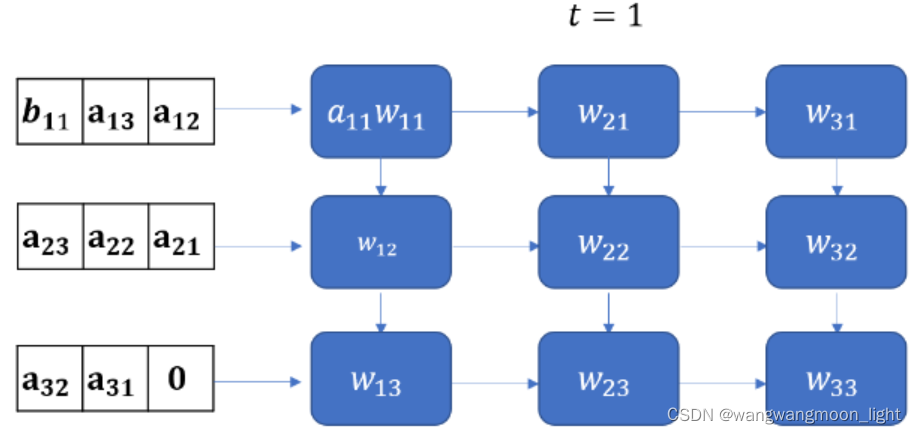
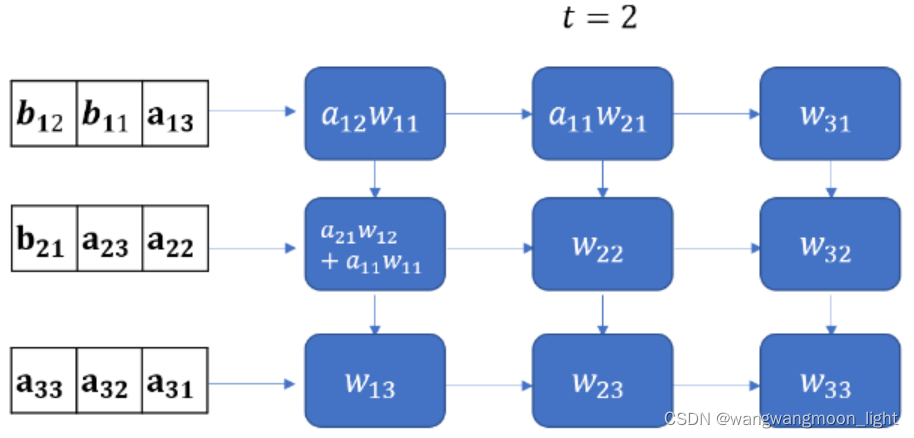


前面已经说过,Y的矩阵结果公式为下面:
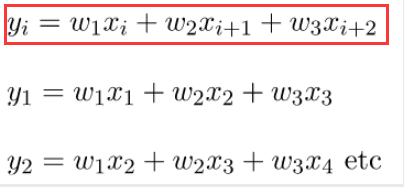
这里值得注意的是,要实现正确的矩阵运算,数据进入脉动阵列需要调整好形式,并且按照一定的顺序。这就需要对原始的矩阵进行一些reformat,这也增加了额外的操作。
2.1 Google TPU Implementation
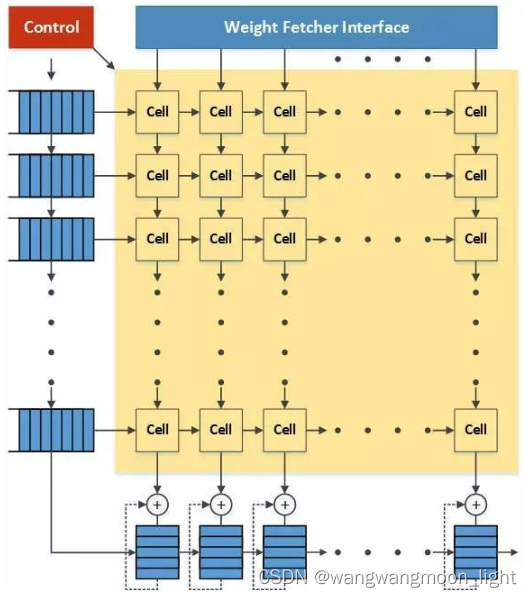
Weight 由上向下流动,FeatureMap数据从左向右流动,在最下方有一些累加单元,左上方有控制单元。控制单元实际上就是把指令翻译成控制信号,控制weight和activation如何传入脉动阵列以及如何在脉动阵列中进行处理和流动
注意,由于读取权重的频率比读取激活的频率要低得多,因此进入和离开激活存储缓冲区的带宽要比权重缓冲区的带宽高得多: 30 GB/Sec VS 167GB/Sec.
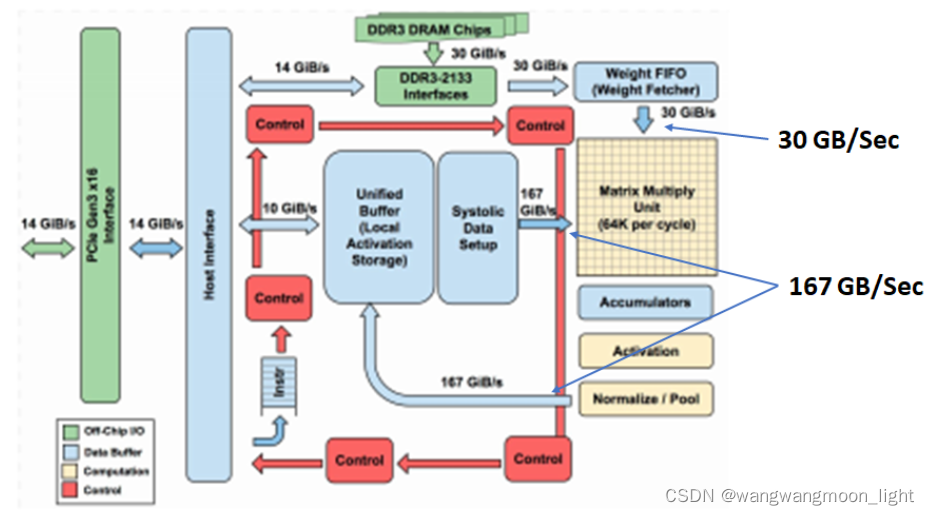
如果矩阵-矩阵乘法的大小大于收缩期阵列,则分几个块进行运算。每个块的结果存储在累加器中,并与下一个块的结果相加。
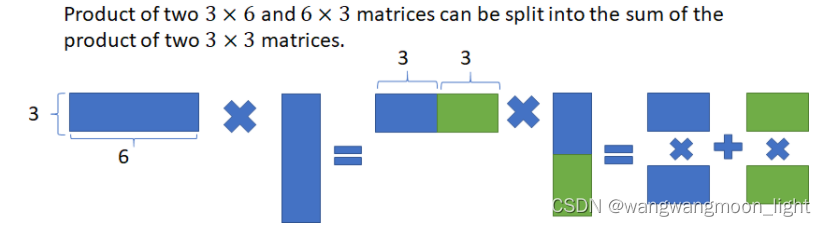
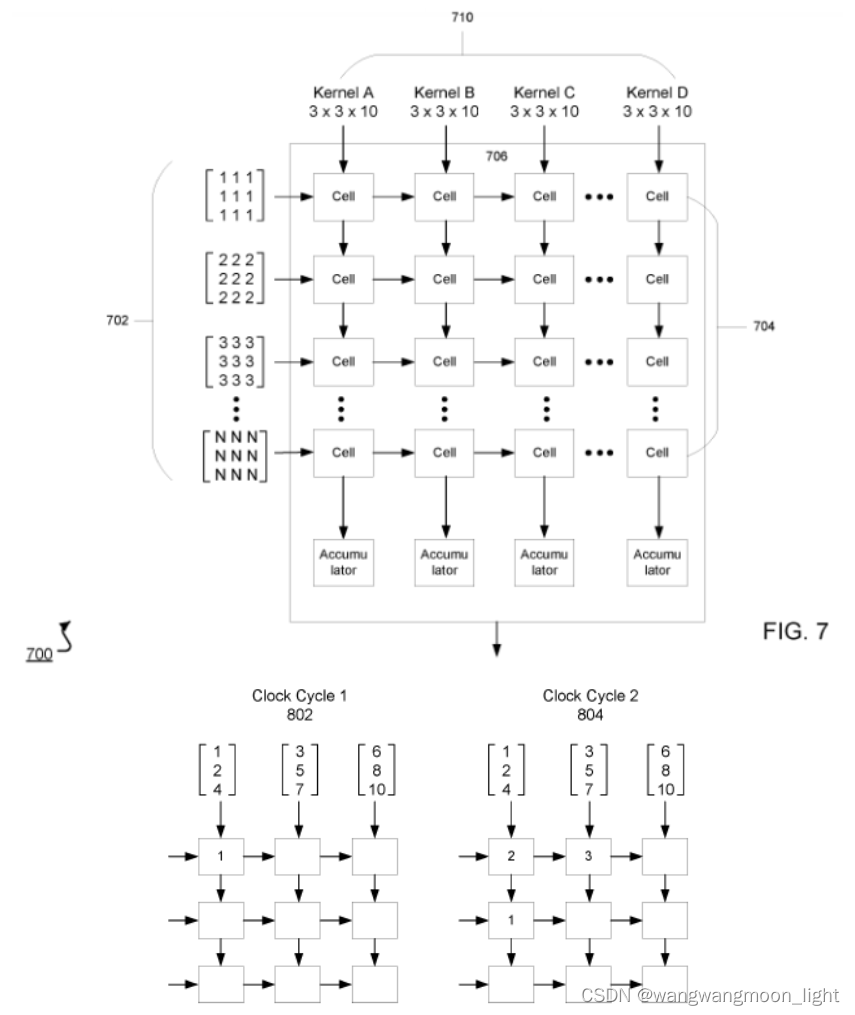
那么,在这样一个大规模的脉动阵列中怎么实现卷积操作呢?在Google的专利中有这样一个例子,可以看出一点。如下图所示,Feature输入被转换成一定的向量形式,作为脉动阵列的行输入。而3x3卷积核(Kernel)经过旋转,变成9个矩阵分别输入到脉动阵列的9个列
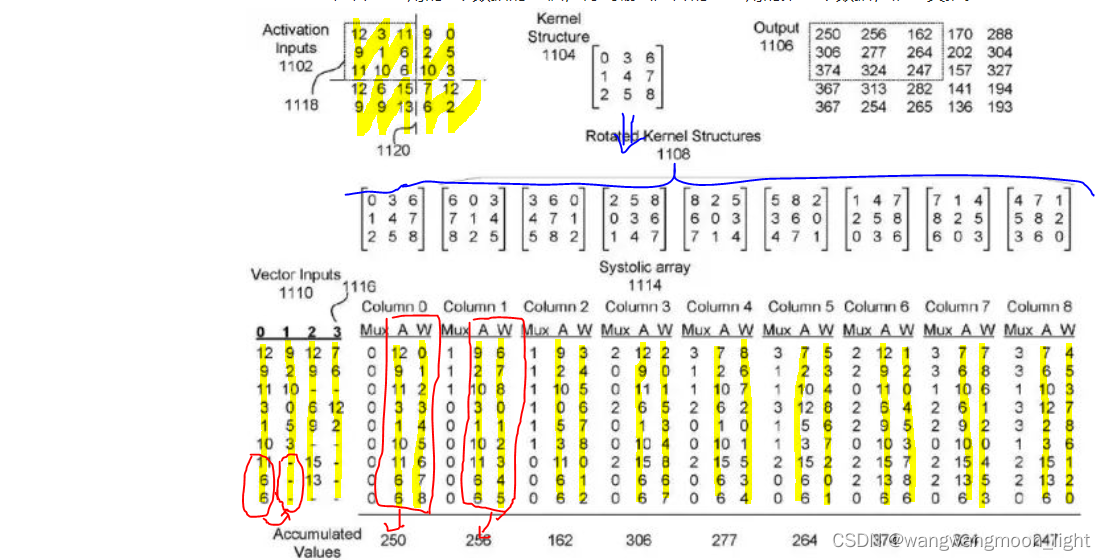
1)图中的Kernel 特殊处理成了9份,FeatureMap的数据是按列排布(竖着按黄色部分来看),第一列计算的是卷积核和activation矩阵左上角的9个数据的卷积,得到输出矩阵的左上角的第一个数据。
2)但没有看懂第二个数据是怎么由脉动矩阵计算得到的:
[12, 9, 11, 3, 1, 10, 11, 6, 6] + [9, 2, 10, 0, 5, 3, -, -, -] -> [9, 2, 10, 3, 1, 10, 11, 6, 6] 这个变化没有看懂?
不难看出,为了要体现脉动阵列的运算效率(“keep the matrix unit busy”),需要对 weight 和 activation进行很多形式上的转换。从TPU论文来看,似乎这项工作是由software stack中的“User Space driver”来完成,“It sets up and controls TPU execution, reformats data into TPU order, translates API calls into TPU instructions, and turns them into an application binary.”这项工作的运算量也不小,具体是怎么优化的就不得而知了
补充:
在知乎上看到了最最清晰关于Systolic Array 最清晰的解释:
数据流下面我们以矩阵乘法的应用场景为例,逐 cycle 展示脉动阵列的一种经典数据流。这种数据流的方式也可以非常直观地称为“输入移动、权重保持、输出移动”。如下面一系列图所示,展示了这种数据流下,如何完成一个矩阵乘法的细节。输入的维度为 4 x 3,左乘上一个维度为 4 x 4 的权重,得到一个维度为 4 x 3 的输出。整个“脉动”的过程中,权重被提前装载到对应的位置且固定不动(权重保持),输入数据自左向右传播(输入移动),输出数据自上向下传播(输出移动)。下面一系列图中,左半张图代表了软件视角下哪些元素正在被计算、右边半张图代表了硬件视角下(即脉动阵列中)哪些元素正在被计算。 cycle 0 为初始化时的数据格式。从 cycle 1 开始,每个正处于脉动阵列中被计算的元素被不同颜色高亮表示。

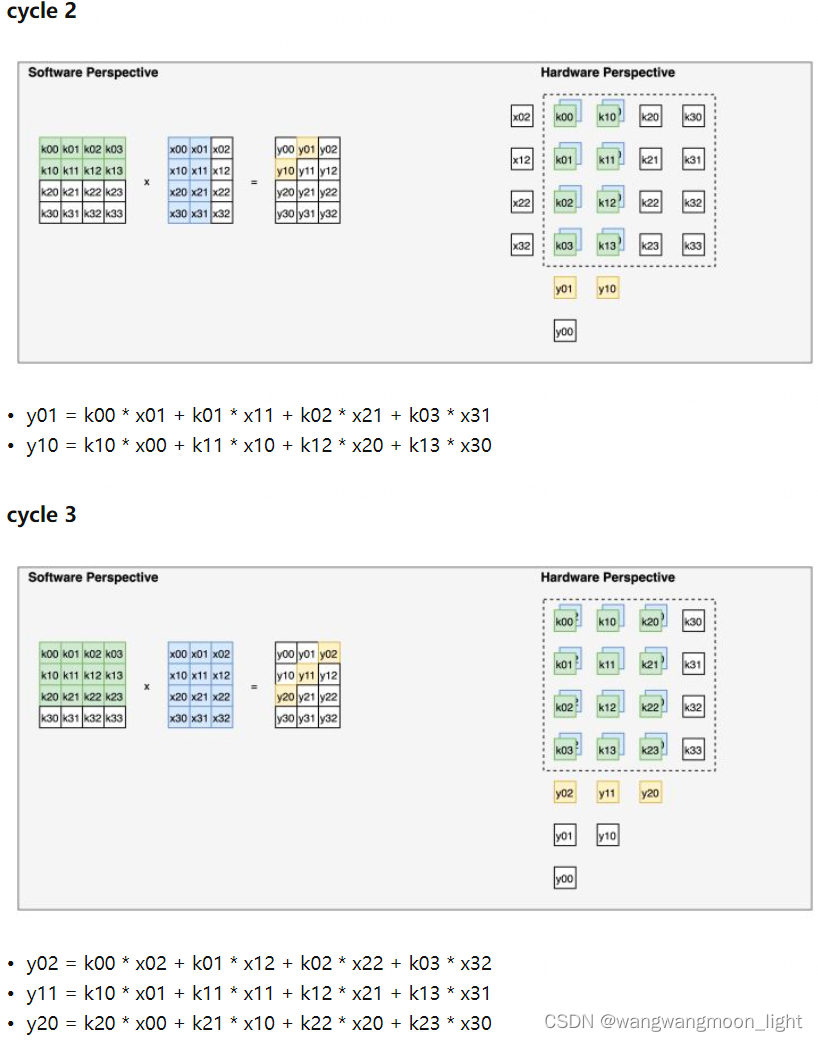


y00 – y32 逐拍计算出来.
3. Advantages and Disadvantages of a TPU
总的来说,TPU和 systolic architectures 的关键优势在于它们的简单性。TPU是一种专门用于做一件事的领域专用处理器——矩阵乘法。它不实现缓存、分支预测、乱序执行、多处理、上下文切换等通用特性,使设计简单,功耗低。这种简单的设计意味着控制逻辑只占整个芯片空间的很小一部分(2%)。矩阵乘法单元和不同的内存类型占用了大部分空间,这有助于减少芯片制造
与GPU相比,TPU的一个关键优势是对 latency sensitive 的推理应用程序具有良好的硬件利用率。GPU需要批量处理才能充分利用所有可用的硬件资源。然而,批处理引入了延迟,这对于可能有严格的延迟上限的推理应用程序是不可取的。
3.1 Disadvantages of a TPU
Latency Depends on Matrix Dimensions (延迟取决于矩阵的维度)
我们之前看到,完成两个 N * N 矩阵的乘积需要 2N-1 个时钟周期,这意味着矩阵乘积的延迟取决于矩阵维数。
For a batch of size B, the latency is N(B+1) -1 (see below).
although it isn’t much of an issue for neural network inference as the size of the matrix dimensions are known in advance and the batch size can simply be adjusted to meet the latency bound.
batch of size 是 3 的 3x3 矩阵,然后 Latency 就是 3x4 - 1 == 11;

Poor MXU Utilization and Wasted Memory BW for Non-Standard Matrix Dimensions
非标准的 Matrix 维度 – 对于平铺的最后一行和最后一列,将不使用所有可用的MAC单位,产生了浪费。
A partially occupied MXU tile also wastes memory bandwidth.

这意味着加载一个完全被占用的 tile 和加载一个部分被占用的 tile 所花费的时间是一样的。因此,部分占用的 tile 将浪费内存带宽。
Implementing Convolutions as Matrix-Multiplications may not be Optimal – 将卷积实现为矩阵乘法可能不是最优的
TPU不直接支持卷积。卷积是通过将它们转换为矩阵乘法来实现的。
然而:A great example is the Eyeriss accelerator that is specially designed for the convolution operation
这可能不是最优的(特别是对于较大的卷积内核),因为卷积具有特定的数据流模式,可以利用这些模式实现更好的效率。一个很好的例子是专门为卷积运算设计的Eyeriss加速器。
No Direct Support for Sparsity
目前在TPU上不支持稀疏性,而 less important weights 可以极大地减少网络的规模、操作次数和能量消耗。这既是一个机会也是一个缺点,因为有了对稀疏性的硬件支持,应该可以实现显著更好的性能。
4. Pipelining of Weight Reads
从主机存储器读取 weights 到 AI 加速器芯片存储器,并将 weights 转移到矩阵乘法单元,需要一定的时间。因此,使用 pipelining 来隐藏相应的延迟是有意义的。其基本思想是在处理当前层的计算时为下一网络层加载权值。
TPU实现了4块权重FIFO,将权重从片外DRAM转移到片上统一缓冲区。矩阵单元是双缓冲的,因此它可以在处理当前层时保存下一层的权值。如果没有双缓冲,将下一层的权值从统一缓冲区转移到MXU需要256个周期。这类似于计算机图形学中的 “ page flipping ”。
5. Conclusion
了解矩阵乘法在二维收缩阵列中的实际工作原理有助于对收缩结构的利弊形成直觉。由于许多重要的市场参与者正在深度学习推理加速器中使用收缩结构,这种直觉应该有助于为您的特定应用做出有关推理硬件的设计选择。
这篇关于AI算力基础 _Systolic Array的实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







