本文主要是介绍Fusing Heterogeneous Factors with Triaffine Mechanismfor Nested Named Entity Recognition,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:https://aclanthology.org/2022.findings-acl.250.pdf
ACL 2022
介绍
使用一个预训练好的模型加上一些简单的结构就能达到比较好的结果,但作者认为如果对一些相关特征进行明确的建模(比如:inside tokens、边界、标签和related span)有利于复杂嵌套的span表征和分类。
虽然这些因素在之前的工作中可能被研究过,但目前并没有一个统一的结构来融合所有的因素。并且传统的加法、乘法注意力和biaffine transformation不能同时与多个因素进行交互。
因此作者提出triaffine机制,( triaffine mechanism as the tensor multiplication with three rank-1 tensors (vectors) and a rank-3 tensor)能同时考虑多个因素之间的交互。
方法
整个模型的框架如下图所示:

Deep Triaffine Transformation
首先介绍作者提出的Triaffine变换,公式计算如下:

其中()表示模n的张量乘法,
表示t层的MLP;边界表征分别表示为u和v(边界头尾两个token),inside token或者span表征为w,W是服从
初始化的tensor,triaffine attention中的tensor表示为
,triaffine 分数表示为
。
Text Encoding
与之前几篇论文相同,使用了多个embedding concat后来表示token embedding。
具体的,对于有N个token的文本。首先从预训练模型中得到上下文embedding,然后将其与word embedding和POS embedding、character embedding进行concate后,经过一个BiLSTM来得到最终的token embedding:
Triaffine Attention for Span Representations
该模块示意图如下所示:

为了实现token、label和边界之间的交互,使用span(i,j)的triaffine attention 来获得标签敏感的span表征
:

这里边界表征和参数
作为注意力中的query,tokens(
)为key和values。(这个是哪里来的token啊?i与j之间的所有token?好像真是这样,将ij之间所有token都与边界进行交互,总和作为边界i,j的表征。不过这个r是啥意思?)作者认为triaffine能够关注query和key之间的高阶交互。
Triaffine Attention for Cross-span Representations
将选出来的relate span()之间进行Triaffine attention计算,得到cross-span的表征。也就是将其他span的表征用来丰富当前presentation。

Triaffine Scoring for Span Classification
使用边界信息和cross-span表征来使用triaffine scoring对span进行分类。通过以下公式来计算span(i,j)标签r的对数可能性:
![]()
当且仅当上的变换层为0时,将上式分解为以下两步:

该模块图例如下:

Training and Inference
在所有的span之间进行交互,代价比较高,因此作者提出了一个辅助性任务:使用中间sapn的表征来对spans进行分类。(中间 翻译为中途感觉更好),根据预测值对所有span进行排序,并选择top m个span作为候选span。然后计算它们的cross-span表征,估计分类分数。因此模型中有两组预测值:一个是针对所有span的,一个是针对top-m个span的。
训练的损失函数如下:

实验
对比实验
在ACE2004、ACE2005和GENIA三个数据集上进行对比实验,结果如下图所示:

在数据集KBP2017上进行实验,结果如下图所示:

消融实验

作者将triaffine和biaffine在不同长度的数据集上进行对比,发现实体长度增加时,triaffine的优势更明显。作者认为这是因为在triaffine中边界和related span之间相互作用的结果。

对实验结果依据ner的类型进行分类,如下所示:

可以看出作者提出的模型在这两个数据集上效果更好,特别是在嵌套类型的ner上。
作者对m的取值也进行了实验,结果如下所示,可以发现在m=30时,能够达到性能和效率之间比较好的性能。

case study
下表展示了ACE2004和GENIA数据集中的两个例子:
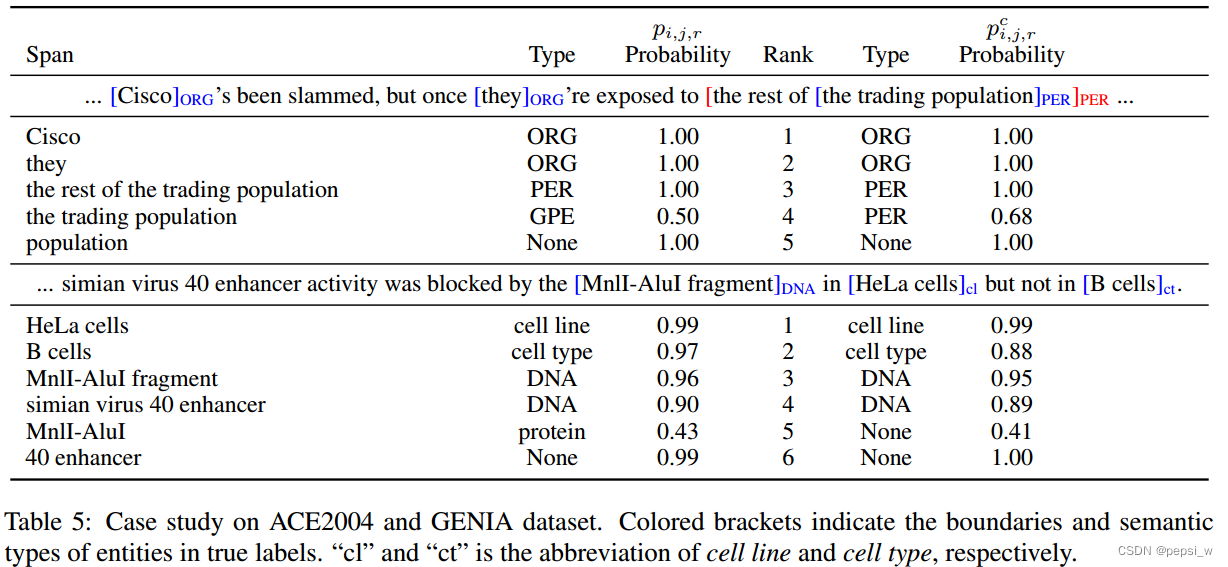
比如“the tradding population”第一阶段被预测为“GPE”,但在结合了span之间的交互后(更外面的span the rest of the trading population),模型正确的预测为“PER”。
总结
感觉整体的创新点就是提出了Triaffine attention,将其他很多信息都用来丰富span presentation,并在span之间进行交互,这样每个span就能看到其他span的信息,就像上面这个例子中的“the tradding population”,由于会在span之间进行交互,那它就能看到span the rest of the trading population这个span,明显后者更像PER,因此会抛弃“the tradding population”。
这篇关于Fusing Heterogeneous Factors with Triaffine Mechanismfor Nested Named Entity Recognition的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!