本文主要是介绍【信源编码作业四】基于LBG的矢量量化算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
矢量量化VQ Vector Quantization是70年代后期发展起来的一种数据压缩技术是一种高效的有损数据压缩技术它具有压缩比大、解码简单和失真较小等优点。其基本思想是将若干个标量数据组构成一个矢量,然后在矢量空间给以整体量化,从而压缩了数据而不损失多少信息。矢量量化是香浓信息论在信源编码理论方面的发展,它的理论基础是香浓的率失真理论,率失真理论是一个存在性定理,并非是一个构造性定理,它未给出如何构造,矢量量化器的方法,矢量量化总是优于标量量化,这是因为矢量量化能有效地应用矢量中各,分量之间的4种相互关联性质来消除数据中的冗余度。自从1980年提出矢量量化器Vector
Quantizater码书设计的LBG算法以来,矢量量化Vector Quantization技术[Gray1984]已经成功地应用到图像压缩和语音编码中[1]。
二、LBG算法中最佳量化器的设计
LBG算法中的最佳矢量量化器设计的关键是最佳划分和最佳码书的设计[2]。
一是给定码书条件下,寻找信源空间的最佳划分,使平均失真最小,由码书和NNR得最
佳划分。
二是在给定划分条件下,寻找最佳码书,使平均失真最小
给定了划分后为了使码书的平均失真最小,码字必须为相应划分的形心,质心——即
式中表示选取的Y是使平均失真为最小的Y,对于一般的失真测度和信源分布,很难找
到形心的计算方法。对于训练序列分布和常用的均方失真测度,形心可由下式给出,式中表示集合中元素的个数,即集中有X个。
三、矢量量化器的设计算法
经典的码书设计算法是LBG算法[2]它是Y.LindeA.Buzo与R.M.Gray在1980年推出
的,其思想是对于一个训练序列,先找出其中心,再用分裂法产生一个初始码书A^0,最后
把训练序列按码书A^0中的元素分组,找出每组的中心,得到新的码书,转而把新码书作为初始码书再进行上述过程,直到满意为止。设计矢量量化器的主要任务是设计码书,在给定码书大小N的情况下,由最佳划分和最佳码书两个必要条件得到矢量量化器的设计算法LBG算法既可用于已知信源分布特性情况,又可用于未知信源分布特性情况
LBG算法流程描述如下
此算法基于最佳矢量量化器设计的最佳划分和最佳码书这两个必要条件,是劳埃德算法
在矢量空间的推广,其特点为物理概念清晰、算法理论严密及算法实现容易。但是它有3
个主要缺点:
1在每次迭代的最佳划分阶段从码书中搜索训练矢量的最近码字需要大量的存储空
间和繁琐的计算。
2初始码书的选择影响码书训练的收敛速度和最终码书的性能。
3码书的自适应能力不强。
二、程序调试
系统:win7
软件:vs2010
打开程序包项目,进行重新编译及重定项目目标后,运行程序,报错:无法找到unistd.h,

经查询解决方法为:
新建unistd.h文件,文件内容为:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
并将unistd.h文件置于如下路径文件夹中

一、 trvqsp_img:获得图像矢量量化的码书。
这个程序可以用来训练矢量量化器。使用LBG算法获得图像压缩码书,初始化使用Linde, Buzo, and Gray提出的分割方法。用作。这个项目可以 很长一段时间来运行特别是所需的大小 码书很大。因此这是一个好主意来运行 项目背景。
图像的尺寸可以由用户指定或者由程序直接获得。但是image_size只支持少量的图像标准,如果想要支持更多格式的文件需通过编辑文件image_size.c来实现。或者可以在运行时指定图像的尺寸(使用选项- x – y)。
1. 调用参数格式:
trvqsp_img ts_img codefile [-b cb_size] [ -t block_height] [-w block_width] [-x row_size][-y col_size] [-h]
ts_img:是训练图像,也即待量化压缩的图像,假定为8位灰度级,使用光栅扫描顺序存储。
Codefile:以二进制格式存放码书的文件,有一个包含12个字节的文件头记录:向量的维度,以及码书的大小。
-b cb_size:码书的大小
-t block_height:块的高度(以像素为单位)
-w block_width:块的宽度(以像素为单位)
实际上由block_width 、block_height决定着码书向量的大小,也即每个输出块的大小。因此向量的维数是block_height *block_width。
-x row_size:输入图像的宽
-y col_size:输入图像的高
-h 帮助

2. 码书构造流程

二、 vqimg_enc:根据码书对图像进行矢量量化。
这个程序可以使用矢量量化来压缩图像。需使用trvqsp_img获得的码书文件,码书的大小以及码块的大小包含在指定的码书文件中。这个程序使用的是定长编码,所以可以使用变长编码来优化程序。如果没有指定一个输出文件则从命令框中输出。
1. 调用格式:
vqimg_enc [-i imagein] [-o cmpfile] [-c codebook] [-x row_size] [-y col_size] [-h]
-i imagein:输入的待编码的图像文件名
-o cmpfile:输出的量化压缩后的文件名
-c cmpfile:码书文件
-x row_size:输入图像的宽
-y col_size:输入图像的高

2. 量化流程:

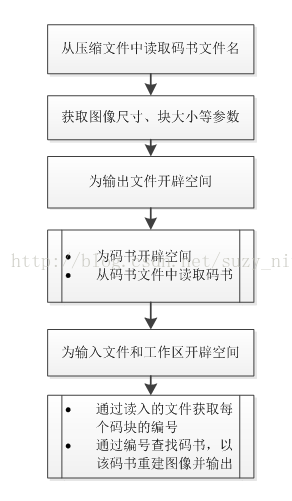
三、 vqimg_dec:根据码书文件和压缩后的文件重构原始图像。
重建压缩图像使用vqimg_enc。解码需要提供码书文件,而码书文件则通过压缩文件的文件头提供其名称,不需要人为输入。图像是8位灰度级图像,使用光栅扫描顺序存储。
1. 调用格式:
vqimg_dec [-i cmpfile] [-o imageout] [-h]
-i cmpfile:压缩文件名
-o imageout:重建图像文件名
-h 帮助

2. 重构流程
这篇关于【信源编码作业四】基于LBG的矢量量化算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









