本文主要是介绍LMAX Disruptor,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
LMAX Disruptor 已经是好几年前的框架了,无论是官方还是网上已经有不少其原理分析的文章了,都2020年了,为什么还要写关于它的文章呢?
几年前了解到 LMAX Disruptor 架构后,我便产生了将它移植到 C++ 上的想法。一方面是想看如此高性能的框架,移植到 C++ 会不会性能更高;另一方面是想通过源码移植了解它架构中更为基本的东西。后来虽然移植也完成了,文章也看了,但我发现它框架中最基本的东西依然没有理解。网上的文章,包括官方的,对于其无锁队列设计的解析,都是围绕它本身的结构(ring_buffer、sequence、sequencer、barrier、wait_stragety 等 ),理解起来稍显复杂,我认为一定存在不涉及这么多概念的精简结构。直到我去年读到一篇文章,如醍醐灌顶,这不就是 LMAX Disruptor 无锁队列架构的基本原理吗。网上还没有看到结合文章中的数据结构来讲 LMAX Disruptor 的文章,因此决定写下来。
Arrary Based Lock-free Circurlar Queue
文章中提到的队列,可以用如下简图表示:
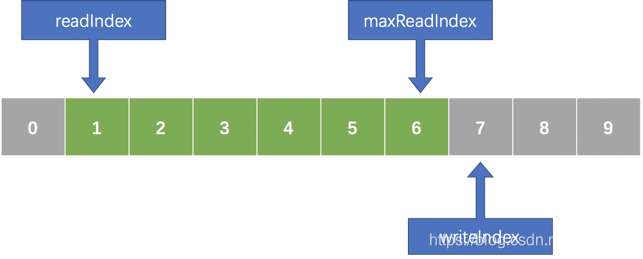
可以看到,队列是基于数组的,且包含如下三个索引:
readIndex:队首索引。
maxReadIndex:队尾索引。
writeIndex:写入索引。
上面三个索引最好是用64位整数表示,否则需要处理数值溢出会造成的问题。而使用 64 位整数,以目前单机每秒的吞吐量,也很难遇到溢出问题。
入队
入队操作与 LMAX Disruptor 如出一辙,分两步:写入和提交
- 先增加 writeIndex ,获得写入点
- 写入数据
- 增加 maxReadIndex ,提交数据
出队
简单的增加 readIndex 即可。
从 Arrary Based Lock-free Circurlar Queue 到 LMAX Disruptor
我们可以把整个队列分为三个逻辑部分:生产者、消费者及数据存储。生产者负责操作 writeIndex 与 maxReadIndex;消费者负责操作 readIndex;数据存储负责根据索引读取/写入数据。LMAX Disruptor 架构的抽象过程也可以看成是基于这三块进行,只不过这三大块下,分的更细。
Sequence
参考文章的实现可以看到,原子操作无处不在,而操作的目的就是为了修改索引。在 LMAX Disruptor 中,索引被称为 Cursor,由 Sequence 类提供对其的原子操作。
RingBuffer
RingBuffer 主要负责存取数据,就是个 Buffer。由于不负责维护队首和队尾索引,因此它里面的数据是可以被覆盖的。
Sequencer
Sequencer 是对生产者的抽象,主要维护 maxReadIndex,也就是队尾索引。虽然没有显式的维护队首索引,为了防止数据覆盖,Sequencer 还是维护了一个叫 Gating Sequences 的 Sequence 数组,这个数组中的最小值就是队首索引。有了队首和队尾索引,Sequencer 就知道队列是满是空了。当队列满时,Sequencer 则采用一种近乎忙等的方式等待队列有空。按 LMAX 的话说,队列设计中,消费者不应该成为瓶颈。因此,队列大部分情况下都应该有空,忙等自然算是划得来的做法。虽然 Sequencer 也还是维护了队首和队尾索引,要注意的是,Gating Sequences 数组是个数组,它是可以为空数组的。这种情况下,由于队首索引不存在了,往队列写数据会发生覆盖。按 LMAX 的说法,有时候是有这种需求的,比如日志。
Sequencer 按使用场景又分 MultiProducerSequencer 和 SingleProducerSequencer,其中 SingleProducerSequencer 工作机制与文章中的方式非常像,也维护了 writeIndex(不过并不使用原子操作)。以 SingleProducerSequencer 为例,它的 Claim 及 publish 工作方式如下:
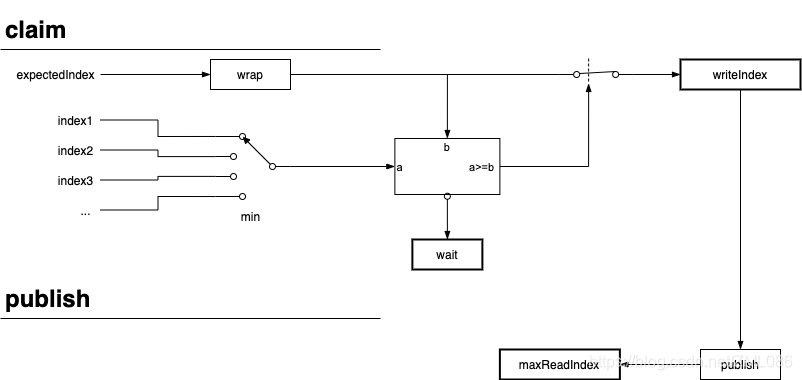
图中,index1,index2,... 就是 Gating Sequences 数组; wrap 操作是减去 bufferSize,这样就方便比较 expectedIndex 有没有覆盖到队首。
SequenceBarrier
SequenceBarrier 主要负责隔离消费者与其他组件,可以看作是消费者的数据源。它为消费者提供可供消费的索引,同时也维护一个 Dependent Sequences 数组,这个数组中的最小值即表示最大可消费的索引。维护 Dependent Sequences 数组是为了实现 Pipeline,即上一个消费者处理完后下一个消费者再处理。
SequenceBarrier 获取可供消费索引的机制大致如下图:
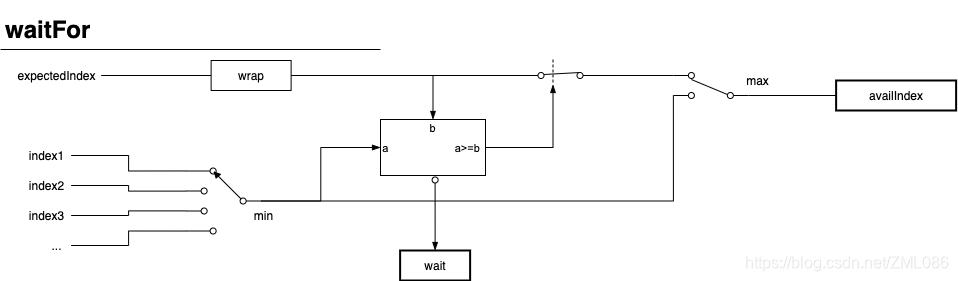
图中 index1,index2 ... 就是 Dependent Sequences 数组;wait 的具体等待方式由 waitStrategy 提供。
EventProcessor
EventProcessor 才是真正的消费者,它维护自己的 readIndex,表示已经目前消费的索引。它依赖 SequenceBarrier 告诉它可消费的索引,每消费一笔数据,readIndex 就加一。LMAX Disruptor 实现了两个 EventProcessor:BatchEventProcessor 和 WorkProcessor,分别用于批次处理的场景和单个处理的场景。分裂 EventProcessor 与 SequenceBarrier 是为了简化 EventProcessor,让它更单纯。让一个 SequenceBarrier 搭配多个 EventProcessor,即可实现并行消费。
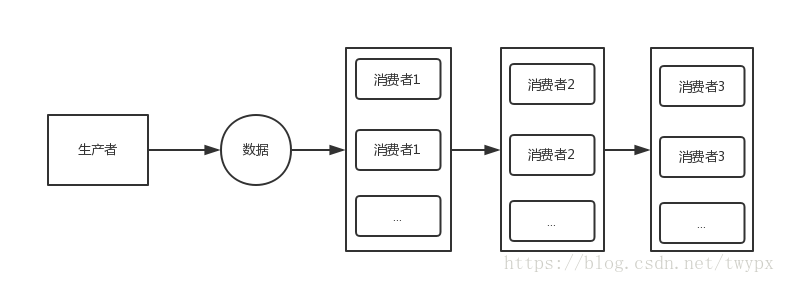
下图展示的是 1 个生产者 3 个消费者组成的 Pipeline 其内部工作机制:
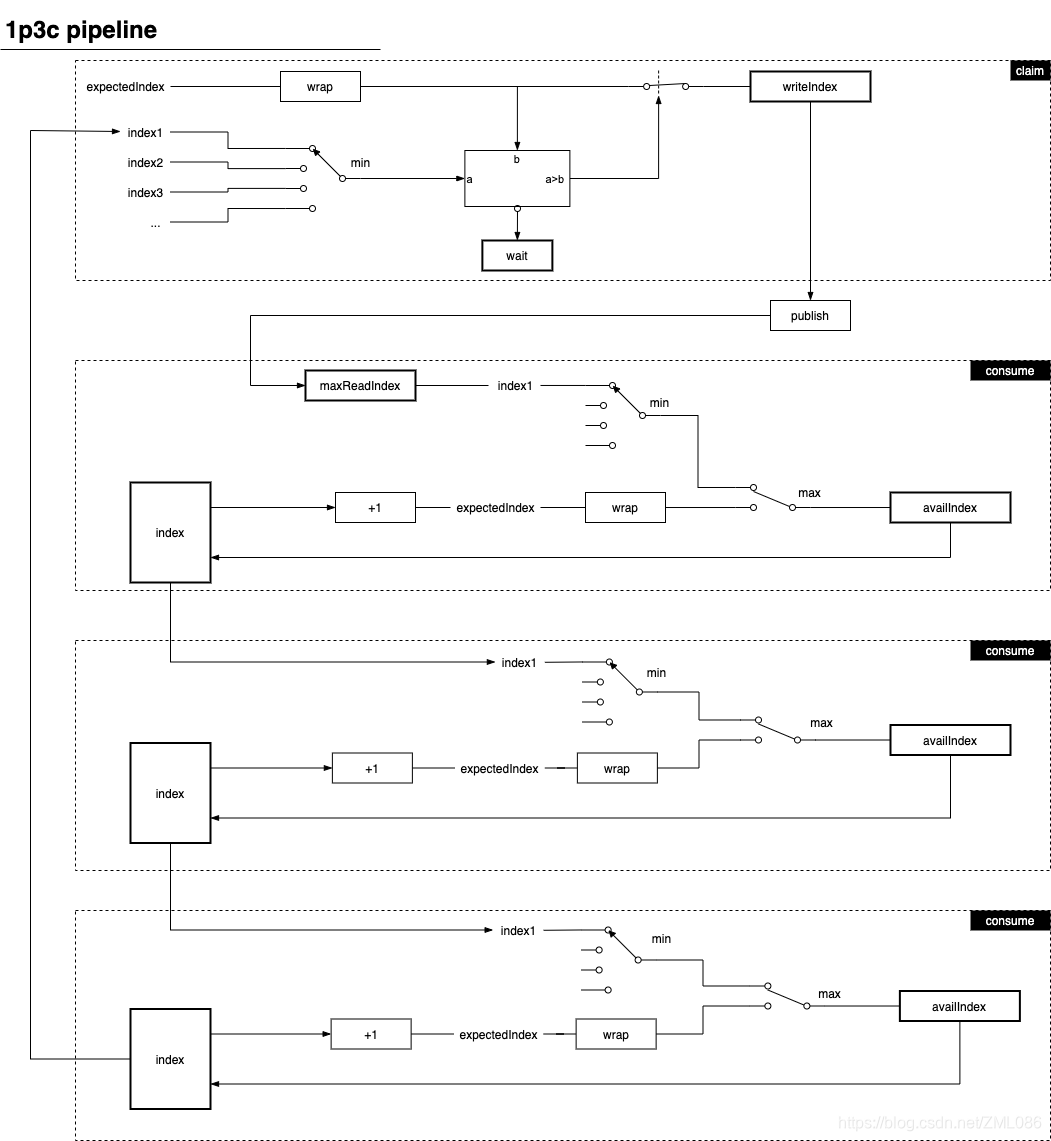
图中,方框代表的 index 即 EventProcessor 维护的 readIndex,这里共有 3 个 EventProcessor 实例,图中省略了 SequenceBarrier 的等待流程。每个 consume 流程都需要一个 SequenceBarrier,因此总共要 3 个实例。每个 SequenceBarrier 都把上一步 EventProcessor 的 readIndex 作为 Dependent Sequence。
下图展示的是 1 个生产者 2 个消费者同时消费这种情景的内部机制:
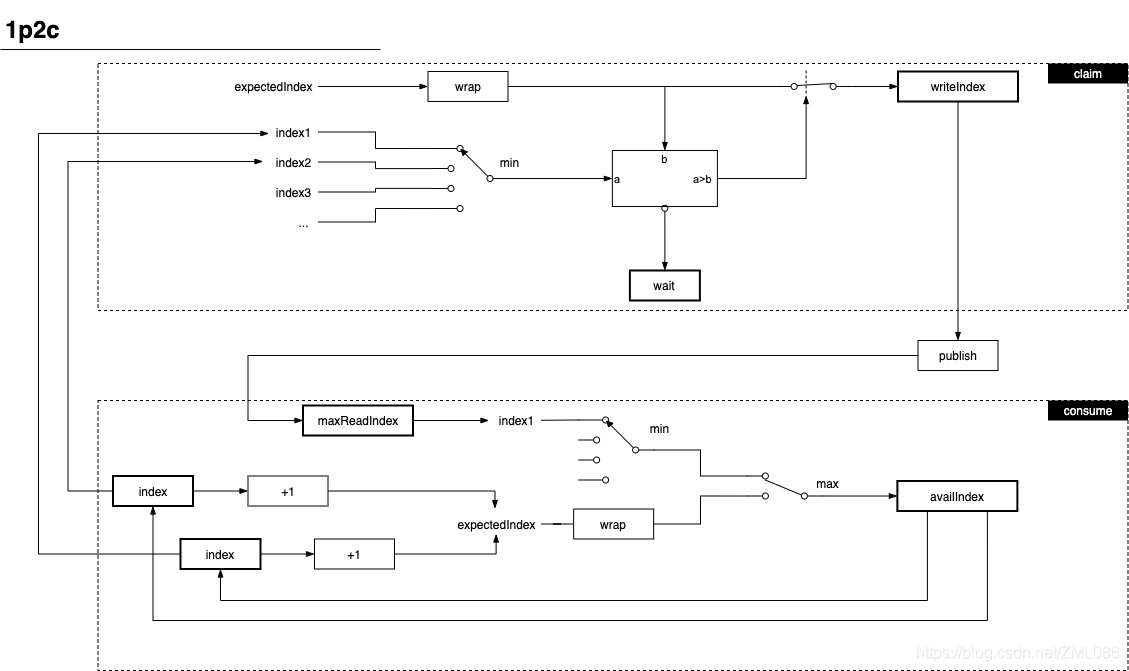
从图中可以看出,总共需要 2 个 EventProcessor、1 个 SequenceBarrier。生产者(Sequencer)又把 2 个 EventProcessor 的 readIndex 作为 Gating Sequences,这个例子中最慢的那个 EventProcessor 的 readIndex 就是队首。
WaitStrategy
WaitStrategy 主要是为了抽象等待策略。它的 waitFor 方法是 SequenceBarrier 在用;signalAll 则主要是 Sequencer 在用,用于告诉消费者有数据到达。
总结
可以看到,LMAX Disruptor 架构把 readIndex、maxReadIndex 维护 和 数据存储外包给了不同的类,将传统队列三者合一的实现方式拆散为独立而又能自由组合的部分,从而满足复杂的场景。
首先,针对数据存储与访问抽象独立的 Buffer 类。
然后,针对 maxReadIndex 的维护问题,抽象出生产者 Sequencer。
再然后,针对 readIndex 的维护问题,委派给各个消费者自己维护。生产者通过计算 readIndex 的最小值间接知道队首在哪里。
再然后,将获取可消费索引的代码独立出来,让这个独立的组件充当代理数据源。给这个代理数据源添加依赖,实现串行消费。
最后,等待生产者生产数据是不可避免的,不同的等待方式性能不同,因此抽象出等待策略供开发人员选择。
这篇关于LMAX Disruptor的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!