本文主要是介绍秒级达百万高并发框架Disruptor,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、起源
Disruptor最初由lmax.com开发,2010年在Qcon公开发表,并于2011年开源,企业应用软件专家Martin Fowler专门撰写长文介绍,同年它还获得了Oracle官方的Duke大奖。其官网定义为:“High Performance Inter-Thread Messaging Library”,即:线程间的高性能消息框架。其实JDK已经为我们提供了很多开箱即用的线程间通信的消息队列,如:ArrayBlockingQueue、LinkedBlockingQueue、ConcurrentLinkedQueue等,这些都是基于无锁的CAS设计。
那么Disruptor为什么还有存在的意义呢?其实无锁并不代表没有竞争,所以当高并发写或者读的时候,这些工具类一样会面临资源争用的极限性能问题。而lmax.com作为一家顶级外汇交易商(英国),其交易系统需要处理的并发量非常巨大,对响应延迟也非常敏感。在这种背景下,Disruptor诞生了(研发的初衷是解决内存队列的延迟问题),基于Disruptor开发的系统单线程能支撑每秒600万订单,它的核心思想就是:把多线程并发写的线程安全问题转化为线程本地写,即:不需要做同步。同时,lmax公司基于Disruptor构建的交易系统也多次斩获金融界大奖。

传统阻塞的队列使用锁保证线程安全,而锁通过操作系统内核上下文切换实现,会暂停线程去等待锁,直到锁释放。
执行这样的上下文切换,会丢失之前保存的数据和指令。由于消费者和生产者之间的速度差异,队列总是接近满 或者 空的状态,这种状态会导致高水平的写入争用。
2、Java内置队列
队列是属于一种数据结构,队列采用的FIFO(first in first out),新元素(等待进入队列的元素)总是被插入到尾部,而读取的时候总是从头部开始读取。在计算中队列一般用来做排队(如线程池的等待排队,锁的等待排队),用来做解耦(生产者消费者模式),异步等等
在jdk中的队列都实现了java.util.Queue接口,在队列中又分为两类,一类是线程不安全的,ArrayDeque,LinkedList等等,还有一类都在java.util.concurrent包下属于线程安全,而在我们真实的环境中,我们的机器都是属于多线程,当多线程对同一个队列进行排队操作的时候,如果使用线程不安全会出现,覆盖数据,数据丢失等无法预测的事情,所以我们这个时候只能选择线程安全的队列。
队列的底层一般分成三种:数组、链表和堆。其中,堆一般情况下是为了实现带有优先级特性的队列,暂且不考虑。
从数组和链表两种数据结构来看,两类结构如下:
- 基于数组线程安全的队列,比较典型的是ArrayBlockingQueue,它主要通过加锁的方式来保证线程安全;
- 基于链表的线程安全队列分成LinkedBlockingQueue和ConcurrentLinkedQueue两大类,前者也通过锁的方式来实现线程安全,而后者以及上面表格中的LinkedTransferQueue都是通过原子变量compare and swap(以下简称“CAS”)这种不加锁的方式来实现的。
但是对 volatile类型的变量进行 CAS 操作,存在伪共享问题
在稳定性和性能要求特别高的系统中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列;同时,为了减少Java的垃圾回收对系统性能的影响,会尽量选择array/heap格式的数据结构。这样筛选下来,符合条件的队列就只有ArrayBlockingQueue。
但是ArrayBlockingQueue有两个问题严重影响了性能。
1)通过加锁的方式保证线程安全。
2)存在伪共享问题。
3、伪共享问题
CPU缓存大小是CPU的重要指标之一,而且缓存的结构和大小对CPU速度的影响非常大,CPU内缓存的运行频率极高,一般是和处理器同频运作,工作效率远远大于系统内存和硬盘。实际工作时,CPU往往需要重复读取同样的数据块,而缓存容量的增大,可以大幅度提升CPU内部读取数据的命中率,而不用再到内存或者硬盘上寻找,以此提高系统性能。
1) CPU内存

上图是计算机的基本结构。L1、L2、L3分别表示一级缓存、二级缓存、三级缓存,越靠近CPU的缓存,速度越快,容量也越小。所以L1缓存很小但很快,并且紧靠着在使用它的CPU内核;L2大一些,也慢一些,并且仍然只能被一个单独的CPU核使用;L3更大、更慢,并且被同一个CPU插槽之间的核共享;最后是主存,由全部插槽上的所有CPU核共享。

可见CPU读取主存中的数据会比从L1中读取慢了近2个数量级。
当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要尽量确保数据在L1缓存中。

当CPU要读取一个数据时,首先从一级缓存中查找,如果没有找到再从二级缓存中查找,如果还是没有就从三级缓存或内存中查找。一般来说,每级缓存的命中率大概都在80%左右,也就是说全部数据量的80%都可以在一级缓存中找到,只剩下20%的总数据量才需要从二级缓存、三级缓存或内存中读取,由此可见一级缓存是整个CPU缓存架构中最为重要的部分。

2) 缓存行

为了提高IO效率,CPU每次从内存读取数据,并不是只读取我们需要计算的数据,而是一批一批去读取的,这一批数据,也叫Cache Line(缓存行)。每个cache line通常是64字节,CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line。从读取的角度来说,缓存是由缓存行Cache Line组成的,所以使用缓存时,并不是一个一个字节使用,而是一行缓存行、一行缓存行这样使用(换句话说,CPU存取缓存都是按照一行,为最小单位操作的。并不是按照字节为单位,进行操作的)。所以,Cache Line可以简单的理解为CPU Cache中的最小缓存单位。这些CPU Cache的写回和加载,都不是以一个变量作为单位。这些都是以整个Cache Line作为单位。如果一个常量和变量放在一行,那么变量的更新,也会影响常量的使用。

在Java中Long是8个字节,所以可以存储8个Long,在访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载另外7个。因此你能非常快的遍历这个数组。(我们上面说为什么选择数组不选择链表,也就是这个原因,在数组中可以依靠缓冲行得到很快的访问)。
3) 伪共享
CPU的缓存系统是以缓存行(cache line)为单位存储的,一般的大小为64bytes。在多线程程序的执行过程中,存在着一种情况,多个需要频繁修改的变量存在同一个缓存行当中。
假设:有两个线程分别访问并修改X和Y这两个变量,X和Y恰好在同一个缓存行上,这两个线程分别在不同的CPU上执行。那么每个CPU分别更新好X和Y时将缓存行刷入内存时,发现有别的修改了各自缓存行内的数据,这时缓存行会失效,从L3中重新获取。这样的话,程序执行效率明显下降。
两个线程(Thread1 和 Thread2)同时修改一个同一个缓存行上的数据 X Y:
如果线程1打算更改a的值,而线程2准备更改b的值:
Thread1:x=3;
Thread2:y=2;
由x值被更新了,所以x值需要在线程1和线程2之间传递(从线程1到线程2),
x、y的变更,都会引起 cache line 整块 64 bytes 被刷新,因为cpu核之间以cache line的形式交换数据(cache lines的大小一般为64bytes)。
在并发执行的场景下,每个线程在不同的核中被处理。
假设 x,y是两个频繁修改的变量,x,y,还位于同一个缓存行.
如果,CPU1修改了变量x时,L3中的缓存行数据就失效了,也就是CPU2中的缓存行数据也失效了,CPU2需要的y需要重新从内存加载。
如果,CPU2修改了变量y时,L3中的缓存行数据就失效了,也就是CPU1中的缓存行数据也失效了,CPU1需要的x需要重新从内存加载。
x,y在两个cpu上进行修改,本来应该是互不影响的,但是由于缓存行在一起,导致了相互受到了影响。
为了减少这种情况的发生,其实就是避免X和Y在同一个缓存行中,如何操作呢?可以主动添加一些无关变量将缓存行填充满。

以ArrayBlockingQueue队列为例,其中最核心的三个成员变量为:
putIndex:入队下标。
takeIndex:出队下标。
count:队列中元素的数量。

这三个变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,从而不能完全达到共享的效果。

如上图所示,当生产者线程和消费者线程同时操作ArrayBlockingQueue时,两个线程会加载这3个变量到自己的L1缓存中。假设Producer Thread put一个元素到ArrayBlockingQueue时,putIndex会修改,根据MESI协议,那么变量对应的其他所有缓存行都会失效。因为putIndex 和 takeIndex位于同一缓存行。所以consumer Thread 中的L1缓存行也会失效。 当consumer Thread需要消费后需要修改takeIndex时,则需要到主内存中去拿数据。
这种无法充分使用缓存行特性的现象,称为伪共享。
出现伪共享问题的原因:
- 一个缓存行可以存储多个变量(存满当前缓存行的字节数);64个字节可以放8个long,16个int
- 而CPU对缓存的修改又是以缓存行为最小单位的; 不是以long 、byte这样的数据类型为单位的
- 在多线程情况下,如果需要修改“共享同一个缓存行的其中一个变量”,该行中其他变量的状态 就会失效,甚至进行一致性保护
所以,伪共享问题的本质是:
对缓存行中的单个变量进行修改了,导致整个缓存行 其他不相关的数据也就失效了,需要从主存重新加载。
如果 其中有 volatile 修饰的变量,需要保证线程可见性的变量,还需要进入 缓存与数据一致性的保障流程, 如mesi协议的数据一致性保障 用了其他变量的 Core的缓存一致性。
缓存一致性是根据缓存行为单元来进行同步的,假如 y是 volatile 类型的,假如a修改了x,而其他的线程用到y,虽然用到的不是同一个数据,但是他们(数据x和数据y)在同一个缓存行中,其他的线程的缓存需要保障数据一致性而进行数据同步,当然,同步也需要时间。
一个CPU核心在加载一个缓存行时要执行上百条指令。如果一个核心要等待另外一个核心来重新加载缓存行,那么他就必须等在那里,称之为stall(停止运转)。
伪共享问题的解决方案:
减少伪共享也就意味着减少了stall的发生,其中一个手段就是通过填充(Padding)数据的形式,来保证本应有可能位于同一个缓存行的两个变量,在被多线程访问时必定位于不同的缓存行。
简单的说,就是 以空间换时间: 使用占位字节,将变量的所在的 缓冲行 塞满。disruptor 无锁框架就是这么干的。
我在这里举个例子,可以想象有个数组队列,ArrayQueue,他的数据结构如下:

对于maxSize是我们一开始就定义好的,数组的大小,对于currentIndex,是标志我们当前队列的位置,这个变化比较快,可以想象你访问maxSize的时候,是不是把currentIndex也加载进来了,这个时候,其他线程更新currentIndex,就会把cpu中的缓存行置为无效,请注意这是CPU规定的,他并不是只把currentIndex置为无效,如果此时又继续访问maxSize他依然得继续从内存中读取,但是MaxSize却是我们一开始定义好的,我们应该访问缓存即可,但是却被我们经常改变的currentIndex所影响。

为了解决上面缓存行出现的问题,在Disruptor中采用了Padding的方式

其中的Value就被其他一些无用的long变量给填充了。这样你修改Value的时候,就不会影响到其他变量的缓存行。
JAVA 8中添加了一个@Contended的注解,添加这个的注解,将会在自动进行缓存行填充。

下面是一个@Contended的例子:

执行时,必须加上虚拟机参数-XX:-RestrictContended,@Contended注释才会生效。
下面的例子是测试利用cache line的特性和不利用cache line的特性的效果对比:
①存在伪共享场景下的耗时计算
entity类:
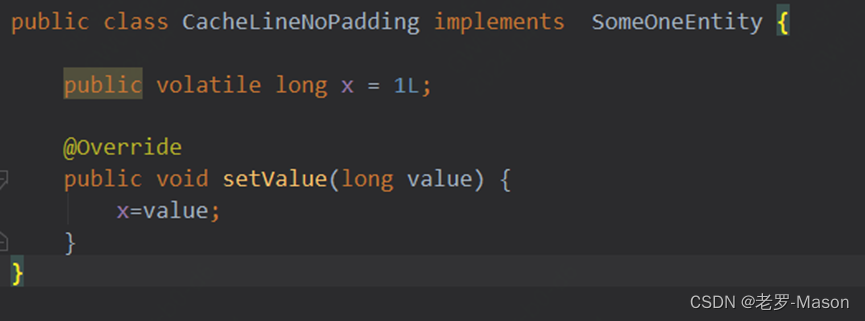
执行方法:

测试用例
执行时间

②消除伪共享场景下的耗时计算
entity类:

执行方法:

测试用例

执行时间

结论:消除伪共享场景 ,比存在伪共享场景的性能提升6倍左右
4、Disruptor
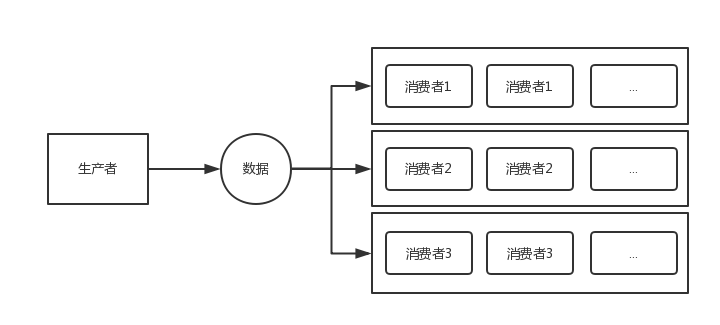
Disruptor的最常用的场景就是“生产者-消费者”( 一个生产者、多个消费者)的场景,并且要求顺序处理。
1) 框架很轻量
Disruptor非常轻量,整个框架最新版3.4.2也才70多个类,但性能却非常强悍。得益于其优秀的设计,和对计算机底层原理的运用,官网说的:mechanical sympathy,我翻译成硬件偏向或者面向硬件编程。这里说的线程间其实就是同一个进程内,不同线程间的消息传递,跟JDK中的那些阻塞和并发队列的用法是一样的,也就是说它们不会夸进程。
2) 应用很广泛
Apache Storm、Apache Camel、Log4j2(见:org.apache.logging.log4j.core.async. AsyncLoggerDisruptor)等都在用。(日志框架换成Log4j2,然后打开异步就可以了)
3) 性能很厉害
比JDK的ArrayBlockingQueue性能高近一个数量级单线程每秒能处理超600W的数据(处理600W并非是消费者消费完600W的数据,而是说Disruptor能在1秒内将600W数据发送给消费者,换句话说,不是600W的TPS,而是每秒600W的派发。再有,其实600W是Disruptor刚发布时硬件的水平,现在在个人PC上也能轻松突破2000W)
现实编程过程中,加锁通常会严重地影响性能。线程会因为竞争不到锁而被挂起,等锁被释放的时候,线程又会被恢复,这个过程中存在着很大的开销,并且通常会有较长时间的中断,因为当一个线程正在等待锁时,它不能做任何其他事情。
Disruptor论文中讲述了一个实验:
这个测试程序调用了一个函数,该函数会对一个64位的计数器循环自增5亿次。
机器环境:2.4G 6核
运算: 64位的计数器累加5亿次

CAS操作比单线程无锁慢了1个数量级;有锁且多线程并发的情况下,速度比单线程无锁慢3个数量级。可见无锁速度最快。 单线程情况下,不加锁的性能 > CAS操作的性能 > 加锁的性能。 在多线程情况下,为了保证线程安全,必须使用CAS或 锁,这种情况下,CAS的性能超过锁的性能,前者大约是后者的8倍。

图:通过加锁的方式实现线程安全
采取加锁的方式,默认线程会冲突,访问数据时,先加上锁再访问,访问之后再解锁。通过锁界定一个临界区,同时只有一个线程进入。

图:通过原子变量CAS实现线程安全
CAS会先把Entry现在的value跟线程当初读出的值相比较,若相同,则赋值;若不相同,则赋值执行失败。一般会通过while/for循环来重新执行,直到赋值成功。
可以和BlockingQueue做对比,不过disruptor除了能完成同样的工作场景外,能做更多的事,效率也更高。业务逻辑处理器完全是运行在内存中(in-memory),使用事件源驱动方式(event sourcing). 业务逻辑处理器的核心是Disruptors,这是一个并发组件,能够在无锁的情况下实现Queue并发安全操作。
基于事件驱动模型,不用消费者主动拉取消费
4) 核心概念
① Ring Buffer
Disruptor中的数据结构,用于存储生产者生产的数据。
如其名,环形的缓冲区。曾经 RingBuffer 是 Disruptor 中的最主要的对象,但从3.0版本开始,其职责被简化为仅仅负责对通过 Disruptor 进行交换的数据(事件)进行存储和更新。在一些更高级的应用场景中,Ring Buffer 可以由用户的自定义实现来完全替代。
② Sequence
序号,在Disruptor框架中,任何地方都有序号
生产者生产的数据放在RingBuffer中的哪个位置,消费者应该消费哪个位置的数据,RingBuffer中的某个位置的数据是什么,这些都是由这个序号来决定的。这个序号可以简单的理解为一个AtomicLong类型的变量。其使用了padding的方法去消除缓存的伪共享问题。
③ Sequencer
序号生成器,这个类主要是用来协调生产者的
在生产者生产数据的时候,Sequencer会产生一个可用的序号(Sequence),然后生产者就就知道数据放在环形队列的那个位置了。
Sequencer是Disruptor的真正核心,此接口有两个实现类SingleProducerSequencer、MultiProducerSequencer ,它们定义在生产者和消费者之间快速、正确地传递数据的并发算法。
④ Sequence Barrier
序号屏障
我们都知道,消费者在消费数据的时候,需要知道消费哪个位置的数据。消费者总不能自己想取哪个数据消费,就取哪个数据消费吧。这个SequencerBarrier起到的就是这样一个“栅栏”般的阻隔作用。你消费者想消费数据,得我告诉你一个序号(Sequence),你去消费那个位置上的数据。要是没有数据,就好好等着吧。
⑤ Wait Strategy
Wait Strategy决定了一个消费者怎么等待生产者将事件(Event)放入Disruptor中。
设想一种这样的情景:生产者生产的非常慢,而消费者消费的非常快。那么必然会出现数据不够的情况,这个时候消费者怎么进行等待呢?WaitStrategy就是为了解决问题而诞生的。
⑥ Event
从生产者到消费者传递的数据叫做Event。它不是一个被 Disruptor 定义的特定类型,而是由 Disruptor的使用者定义并指定。
⑦ EventHandler
Disruptor 定义的事件处理接口,由用户实现,用于处理事件,是 Consumer 的真正实现。
⑧ Producer
即生产者,只是泛指调用 Disruptor 发布事件的用户代码,Disruptor 没有定义特定接口或类型。
5) 如何实现高性能:
在Disruptor中有三大杀器:
- CAS
- 消除伪共享
- RingBuffer
Disruptor实现高性能主要体现了去掉了锁,采用CAS算法,同时内部通过环形队列实现有界队列。
- ① 环形数据结构:为了避免垃圾回收,采用数组而非链表。同时,数组对处理器的缓存机制更加友好。 (用数组实现, 解决了链表节点分散, 不利于cache预读问题,可以预分配用于存储事件内容的内存空间;并且解决了节点每次需要分配和释放, 需要大量的垃圾回收GC问题,数组内元素的内存地址的连续性存储的,在硬件级别,数组中的元素是会被预加载的,因为只要一个元素被加载到缓存行,其他相邻的几个元素也会被加载进同一个缓存行)
- ② 元素位置定位:数组长度2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心index溢出的问题。index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。 (求余操作本身也是一种高耗费的操作, 所以ringbuffer的size设成2的n次方,不要太大,否则会造成oom, 可以利用位操作来高效实现求余。要找到数组中当前序号指向的元素,可以通过mod操作,正常通过sequence mod array length = array index,优化后可以通过:sequence & (array length-1) = array index实现。比如一共有8槽,3&(8-1)=3,HashMap就是用这个方式来定位数组元素的,这种方式比取模的速度更快)。
- ③ 无锁设计:每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。整个过程通过原子变量CAS,保证操作的线程安全。
使用Disruptor,主要用于对性能要求高、延迟低的场景,它通过“榨干”机器的性能来换取处理的高性能。
CAS(compare and swap),顾名思义先比较再交换,一般是比较是否是老的值,如果是,进行交换设置,CAS中没有线程的上下文切换,减少了不必要的开销(CAS操作比锁消耗资源少的多,因为它们不牵涉操作系统,它们直接在CPU上操作)。
ArrayBlockingQueue就是用了重量级lock锁,在我们加锁过程中我们会把线程挂起,解锁后,又会把线程恢复,这一过程会有一定的开销,并且我们一旦没有获取锁,这个线程就只能一直等待,这个线程什么事也不能做。
- ④ 属性填充:通过添加额外的无用信息,避免伪共享问题
6) 使用环形队列的优势:
第一,简化了多线程同步的复杂度。学数据结构的时候,实现队列都要两个指针head和tail来分别指向队列的头和尾,对于一般的队列是这样,想象下,如果有多个生产者同时往缓冲区队列中提交任务,某一生产者提交新任务后,tail指针都要做修改的,那么多个生产者提交任务,头指针不会做修改,但会对tail指针产生冲突,例如某一生产者P1要做写入操作,在获得tail指针指向的对象值V后,执行compareAndSet()方法前,tail指针被另一生产者P2修改了,这时生产者P1执行compareAndSet()方法,发现tail指针指向的值V和期望值E不同,导致冲突。同样,如果多个消费者不断从缓冲区中获取任务,不会修改尾指针,但会造成队列头指针head的冲突问题(因为队列的FIFO特点,出列会从头指针出开始)。
环形队列的一个特点就是只有一个指针,只通过一个指针来实现出列和入列操作。如果使用两个指针head和tail来管理这个队列,有可能会出现“伪共享”问题(因为创建队列时,head和tail指针变量常常在同一个缓存行中,多线程修改同一缓存行中的变量就容易出现伪共享问题)。
第二,由于使用的是环形队列,那么队列创建时大小就被固定了,Disruptor框架中的环形队列本来也就是基于数组实现的,使用数组的话,减少了系统对内存空间管理的压力,因为它不像链表,Java会定期回收链表中一些不再引用的对象,而数组不会出现空间的新分配和回收问题。
如果你的项目有对性能要求高,对延迟要求低的需求,并且需要一个无锁的有界队列,来实现生产者/消费者模式,那么Disruptor是你的不二选择。
5、RingBuffer
RingBuffer是整个Disruptor的精神内核所在,Disruptor中的数据结构,用于存储生产者生产的数据,Ringbuffer是一个首尾相连的环,或者叫循环队列,但是它自己没有尾指针,底层数据结构采用数组实现,RingBuffer 拥有一个序号,这个序号指向数组中下一个可用元素。
1)减少竞争点,比如不删除数据,所以不需要尾指针(整个队列的尾指针由消费者维护)
2)重复利用数组,不需要GC事件对象
3)使用数组存储数据,可以利用CPU缓存每次都加载一个cache line的特性,同时也可以避开伪共享的问题

1) 高性能原理:
①环形数组
首先因为是数组,所以要比链表快,而且根据我们对上面缓存行的解释知道,数组中的一个元素加载,相邻的数组元素也是会被预加载的,因此在这样的结构中,cpu无需时不时去主存加载数组中的下一个元素。
数组会预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。环形数组中的元素采用覆盖方式(不删除buffer中的数据),避免了jvm的GC。(用数组实现, 解决了链表节点分散, 不利于cache预读问题,可以预分配用于存储事件内容的内存空间;并且解决了节点每次需要分配和释放, 需要大量的垃圾回收GC问题,数组内元素的内存地址的连续性存储的,在硬件级别,数组中的元素是会被预加载的,因为只要一个元素被加载到缓存行,其他相邻的几个元素也会被加载进同一个缓存行)
其次结构作为环形,数组的大小为2的n次方,这样元素定位可以通过位运算效率会更高。在disruptor中,这个牛逼的环形结构就是RingBuffer,既然是数组,那么就有大小,而且这个大小必须是2的n次方(求余操作本身也是一种高耗费的操作, 所以ringbuffer的size设成2的n次方,不要太大,否则会造成oom, 可以利用位操作来高效实现求余。要找到数组中当前序号指向的元素,可以通过mod操作,正常通过sequence mod array length = array index,优化后可以通过:sequence & (array length-1) = array index实现。比如一共有8槽,3&(8-1)=3,HashMap就是用这个方式来定位数组元素的,这种方式比取模的速度更快)。
②无锁设计
先来看一下Disruptor 的RingBuffer中哪些地方需要用到锁。
相较于ArrayBlockingQueue队列中的三个变量,putIndex,takeIndex,count。 RingBuffer中存在线程竞争的只有数组的角下表 Sequence(生产者生产的数据放在RingBuffer中的哪个位置,消费者应该消费哪个位置的数据,RingBuffer中的某个位置的数据是什么,这些都是由这个序号来决定的)。这样线程访问之间的冲突也就更少了。然而Disruptor中并没有使用锁,那他是如何保证线程安全的。
我们都知道线程安全的三要素分别是:原子性、有序性和可见性。
原子性:在代码中Sequence的数据类型是AtomicLong类型。所以Disruptor是通过CAS的方式来保证原子性的。
有序性、可见性:在Disruptor中,在Sequence之前用volatile进行修饰的。
对Volatile关键字修饰的变量,执行写操作的时候,Jvm会发送一条lock前缀指令给CPU,CPU在操作完这个变量后会立即把这个值写会主存中,同时有MESI缓存一致性协议,所以各个CPU都会访问总线,感知自己本地高速缓存区中的数据是否被其他线程修改过。如果发现本地缓存的数据被其他线程修改,那么本地高速缓存区与主存中不一致的数据当做过期的值并清理掉。然后再从主存内中重新加载最新的数据。这样就是实现了可见性。
在对Volatile关键字修饰的变量,执行操作读写操作的时候会插入内存屏障,这样可以禁止CPU指令重排。内存屏障遵循的就是happens-before原则表示的是前一个操作的结果对于后续操作是可见的。
内存屏障本身不是一种优化方式, 而是你使用lock-free(CAS)的时候, 必须要配合使用内存屏障,因为CPU和memory之间有多级cache, CPU core只会更新cache-line, 而cache-line什么时候flush到memory, 这个是有一定延时的 ,在这个延时当中, 其他CPU core是无法得知你的更新的, 因为只有把cache-line flush到memory后, 其他core中的相应的cache-line才会被置为过期数据,所以如果要保证使用CAS能保证线程间互斥, 即乐观锁, 必须当一个core发生更新后, 其他所有core立刻知道并把相应的cache-line设为过期, 否则在这些core上执行CAS读到的都是过期数据。
内存屏障 = “立刻将cache-line flush到memory, 没有延时”
③缓存行填充
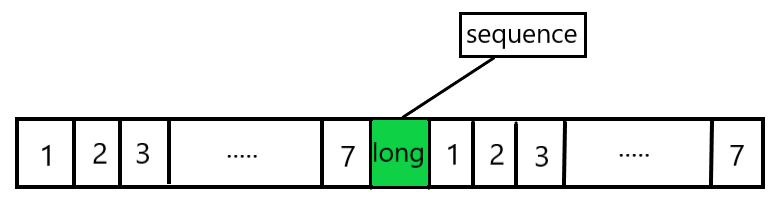
从上面介绍的缓存行可以知道,每个cache line通常是64字节。Long数据类型是8字节。所以在前面补充7个long ,在后面补充7个long,就可以保证sequence无论如何加载,都会独占一个缓存行。这样就避免了伪共享的问题。采取的就是空间换时间的方式。
总结:Sequence是一个递增的序号,说白了就是计数器;其次,由于需要在线程间共享,所以Sequence是引用传递,并且是线程安全的;再次,Sequence支持CAS操作;最后,为了提高效率,Sequence通过padding来避免伪共享。
④批量操作
Ring Buffer的核心操作是生产和消费,如果能减少这两个操作的次数,性能必然相应地提高。Disruptor中使用成批操作来减少生产和消费的次数,下面具体说一下Disruptor的生产和消费过程中如何体现Batch的。向RingBuffer生产东西的时候,需要经过2个阶段:阶段1为申请空间,申请后生产者获得了一个指针范围[low,high],然后再对缓冲区中[low,high]这段的所有对象进行setValue,阶段2为发布(像这样ringBuffer.publish(low,high);)。阶段1结束后,其他生产者再申请的话,会得到另一段缓冲区。阶段2结束后,之前申请的这一段数据就可以被消费者读到。
从RingBuffer消费东西的时候也需要两个阶段,阶段一为指定消费者的消费区间[A,B],判断A到B是不是一段可以连续消费的区间,如果不是则返回最大可消费连续区间进行消费。 阶段二 对[A,B]区间中的值进行消费。
这样可以减少生产和消费时同步带来的性能损失。
2) 如何从Ringbuffer读取:

消费者(Consumer)是一个想从Ring Buffer里读取数据的线程,它可以访问ConsumerBarrier对象——这个对象由RingBuffer创建并且代表消费者与RingBuffer进行交互。就像Ring Buffer显然需要一个序号才能找到下一个可用节点一样,消费者也需要知道它将要处理的序号——每个消费者都需要找到下一个它要访问的序号。在上面的例子中,消费者处理完了Ring Buffer里序号8之前(包括8)的所有数据,那么它期待访问的下一个序号是9。
消费者可以调用ConsumerBarrier对象的waitFor()方法,传递它所需要的下一个序号.
ConsumerBarrier返回RingBuffer的最大可访问序号——在上面的例子中是12。ConsumerBarrier有一个WaitStrategy方法来决定它如何等待这个序号.
接下来,消费者会一直逛来逛去,等待更多数据被写入 Ring Buffer。并且,写入数据后消费者会收到通知一一节点 9,10,11 和 12 已写入。现在序号 12 到了,消费者可以指示 ConsumerBarrier 去拿这些序号里的数据了。

- Producer会向这个RingBuffer中填充元素,填充元素的流程是首先从RingBuffer读取下一个Sequence,之后在这个Sequence位置的槽填充数据,之后发布。
- Consumer消费RingBuffer中的数据,通过SequenceBarrier来协调不同的Consumer的消费先后顺序,以及获取下一个消费位置Sequence。
- Producer在RingBuffer写满时,会从头开始继续写替换掉以前的数据。但是如果有SequenceBarrier指向下一个位置,则不会覆盖这个位置,阻塞到这个位置被消费完成。Consumer同理,在所有Barrier被消费完之后,会阻塞到有新的数据进来。
6. 如何实现生产和消费
在Disruptor中生产者分为单生产者和多生产者,而消费者并没有区分。单生产者情况下,就是普通的生产者向RingBuffer中放置数据,消费者获取最大可消费的位置,并进行消费。
多生产者时候,又多出了一个跟RingBuffer同样大小的Buffer,称为AvailableBuffer。在多生产者中,每个生产者首先通过CAS竞争获取可以写的空间,然后再进行慢慢往里放数据,放完数据后就将AvailableBuffer中对应的位置置位,标记为写入成功。如果正好这个时候消费者要消费数据,那么每个消费者都需要获取最大可消费的下标,这个下标是在AvailableBuffer进行获取得到的最长连续的序列下标。
1) 一个生产者 - 写数据
在并发系统中提高性能最好的方式之一就是单一写者原则,对Disruptor也是适用的。如果在你的代码中仅仅有一个事件生产者,那么可以设置为单一生产者模式来提高系统的性能。

生产者单线程写数据的流程比较简单:
- 申请写入m个元素;
- 若是有m个元素可以入,则返回最大的序列号。这儿主要判断是否会覆盖未读的元素;
- 若是返回的正确,则生产者开始写入元素。

- 一次生产,串行消费
比如:现在触发一个注册Event,需要有一个Handler来存储信息,一个Hanlder来发邮件等等。


- 菱形方式执行


- 链式并行计算

- 相互隔离模式

- 航道模式


2) 多生产者 - 写数据
多个生产者的情况下,会遇到“如何防止多个线程重复写同一个元素”的问题。Disruptor的解决方法是,每个线程获取不同的一段数组空间进行操作。这个通过CAS很容易达到。只需要在分配元素的时候,通过CAS判断一下这段空间是否已经分配出去即可。
但是会遇到一个新问题:如何防止读取的时候,读到还未写的元素。Disruptor在多个生产者的情况下,引入了一个与Ring Buffer大小相同的buffer:available Buffer。当某个位置写入成功的时候,便把availble Buffer相应的位置置位,标记为写入成功。读取的时候,会遍历available Buffer,来判断元素是否已经就绪。
写数据--多个生产者写入的时候:
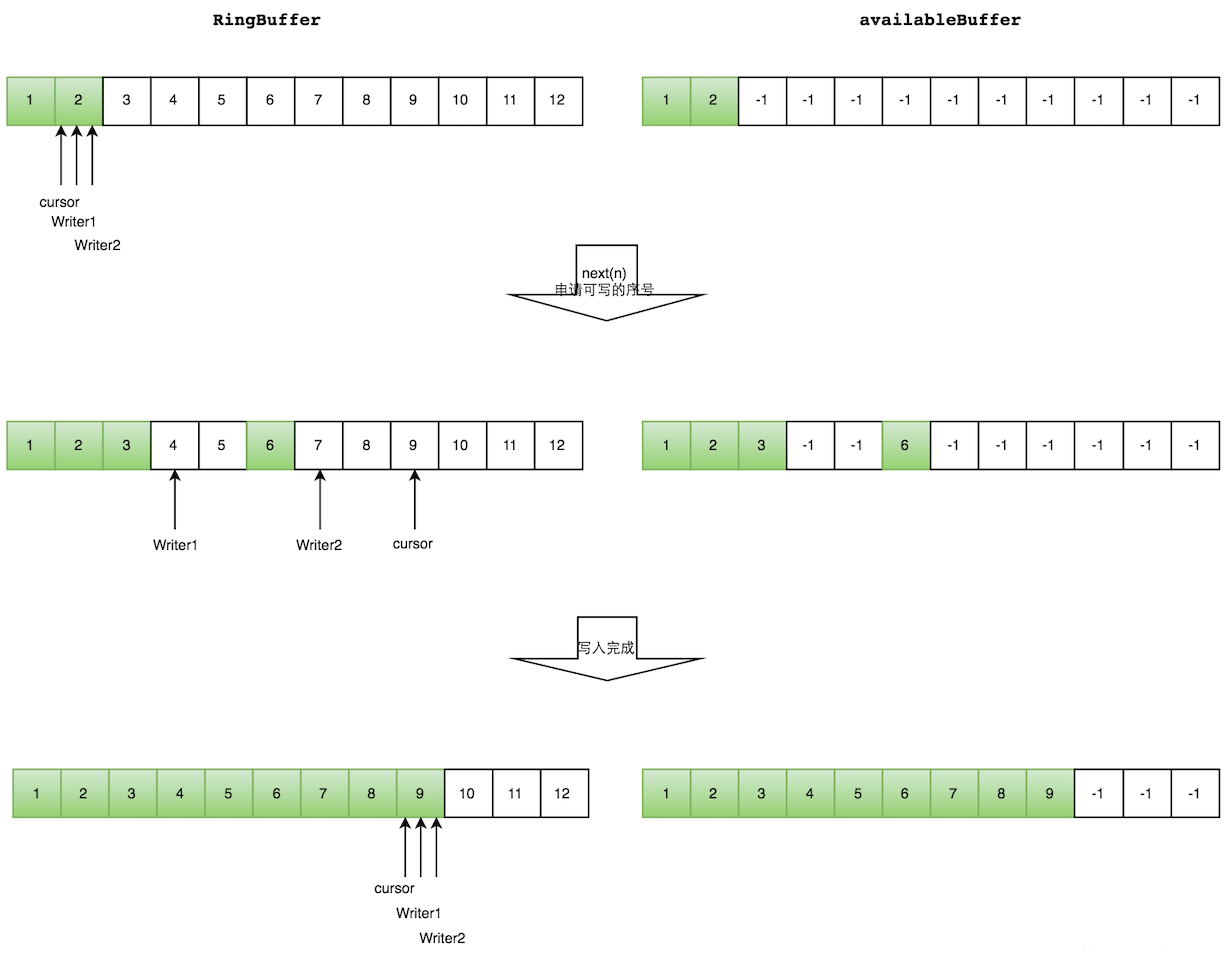
- 申请写入m个元素;
- 若是有m个元素可以写入,则返回最大的序列号。每个生产者会被分配一段独享的空间;
- 生产者写入元素,写入元素的同时设置available Buffer里面相应的位置,以标记自己哪些位置是已经写入成功的。
如下图所示,Writer1和Writer2两个线程写入数组,都申请可写的数组空间。Writer1被分配了下标3到下表5的空间,Writer2被分配了下标6到下标9的空间。
Writer1写入下标3位置的元素,同时把available Buffer相应位置置位,标记已经写入成功,往后移一位,开始写下标4位置的元素。Writer2同样的方式。最终都写入完成。
3) 多生产者 - 读数据
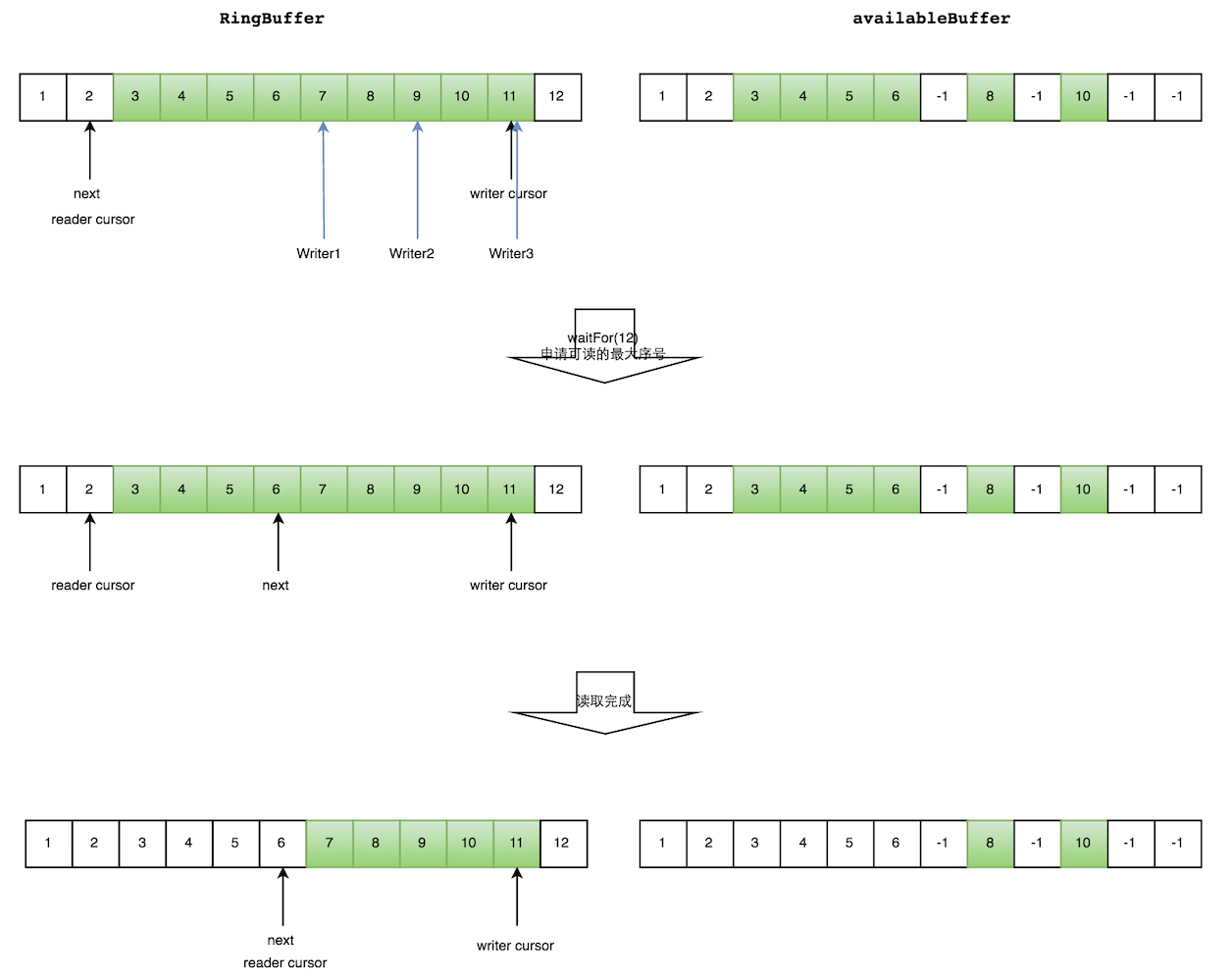
读数据--生产者多线程写入的情况会复杂很多:
- 申请读取到序号n;
- 若writer cursor >= n,这时仍然无法确定连续可读的最大下标。从reader cursor开始读取available Buffer,一直查到第一个不可用的元素,然后返回最大连续可读元素的位置;
- 消费者读取元素。
如下图所示,读线程读到下标为2的元素,三个线程Writer1/Writer2/Writer3正在向RingBuffer相应位置写数据,写线程被分配到的最大元素下标是11。
读线程申请读取到下标从3到11的元素,判断writer cursor>=11。然后开始读取availableBuffer,从3开始,往后读取,发现下标为7的元素没有生产成功,于是WaitFor(11)返回6。
然后,消费者读取下标从3到6共计4个元素。
4) 代码运行对比
Disruptor和ArrayBlockingQueue进行对比:

我们可以看到随着数据量的增加,Disruptor的效率逐渐超越了ArrayBlockingQueue,并且越拉越大。

我们可以看到随着线程数量的增加,ArrayBlockingQueue锁竞争越严重,效率也就越低
ArrayBlockingQueue性能测试:
Disruptor性能测试:

7. 使用场景
停车批量入场数据上报,数据上报后需要对每条入场数据存入DB,还需要发送kafka消息给其他业务系统。如果执行完所有的操作,再返回,那么接口耗时比较长,我们可以批量上报后验证数据正确性,通过后按单条入场数据写入环形队列,然后直接返回成功。
实现方式一:启 动2个消费者线程,一个消费者去执行db入库,一个消费者去发送kafka消息。
实现方式二:启动4个消费者,2个消费者并发执行db入库,两个消费者并发发送kafka消息,充分利用cpu多核特性,提高执行效率。
实现方式三:如果要求写入DB和kafka后,需要给用户发送短信。那么可以启动三个消费者线程,一个执行db插入,一个执行kafka消息发布,最后一个依赖前两个线程执行成功,前两个线程都执行成功后,该线程执行短信发送。
附录2:Disruptor的等待策略
Disruptor默认的等待策略是BlockingWaitStrategy。这个策略的内部适用一个锁和条件变量来控制线程的执行和等待(Java基本的同步方法)。BlockingWaitStrategy是最慢的等待策略,但也是CPU使用率最低和最稳定的选项。然而,可以根据不同的部署环境调整选项以提高性能。
SleepingWaitStrategy
和BlockingWaitStrategy一样,SpleepingWaitStrategy的CPU使用率也比较低。它的方式是循环等待并且在循环中间调用LockSupport.parkNanos(1)来睡眠,(在Linux系统上面睡眠时间60µs).然而,它的优点在于生产线程只需要计数,而不执行任何指令。并且没有条件变量的消耗。但是,事件对象从生产者到消费者传递的延迟变大了。SleepingWaitStrategy最好用在不需要低延迟,而且事件发布对于生产者的影响比较小的情况下。比如异步日志功能。
YieldingWaitStrategy
YieldingWaitStrategy是可以被用在低延迟系统中的两个策略之一,这种策略在减低系统延迟的同时也会增加CPU运算量。YieldingWaitStrategy策略会循环等待sequence增加到合适的值。循环中调用Thread.yield()允许其他准备好的线程执行。如果需要高性能而且事件消费者线程比逻辑内核少的时候,推荐使用YieldingWaitStrategy策略。例如:在开启超线程的时候。
BusySpinW4aitStrategy
BusySpinWaitStrategy是性能最高的等待策略,同时也是对部署环境要求最高的策略。这个性能最好用在事件处理线程比物理内核数目还要小的时候。例如:在禁用超线程技术的时候。
这篇关于秒级达百万高并发框架Disruptor的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





