本文主要是介绍图的关节点(Tarjan算法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据结构复习–求图的关节点(Tarjan算法)
文章目录
- 重连通图的关节点(割点)
- 关节点
- 重(双)连通图
- 深度优先生成树与回边
- Visited数组与Low数组
- visited数组
- low数组
- Low数组求法
- 关节点的判定
- Low[w]>=Visited[v]的理解:
- Tarjan算法
- 注意点:
- 时间复杂度分析:
重连通图的关节点(割点)
关节点
若连通图中某个顶点和其相关联的边被删去后,该连通图被分割成两个或两个以上的联通分量,则称此节点为关节点(割点)。
重(双)连通图
没有关节点的连通图称为双连通图。
即从一个双连通图中删去任何一个顶点及其想关联的边,它仍为一个连通图。
深度优先生成树与回边
从图中任意顶点开始,执行深度优先搜索并在顶点被访问时给它们编号。
而对于图中实际存在而深度优先生成树中不存在的边,称为回边(v,w)或背向边(v,w)。
如下例,虚线部分表示回边。


Visited数组与Low数组
visited数组
第一次对图执行深度优先搜索时,依次访问节点,同时按访问顺序对节点编号。对于每一个节点v,我们称其先序序号为visited[v]。
low数组
然后对深度优先搜索树上的每一个节点v,计算编号最低的顶点,称之为low[v]。
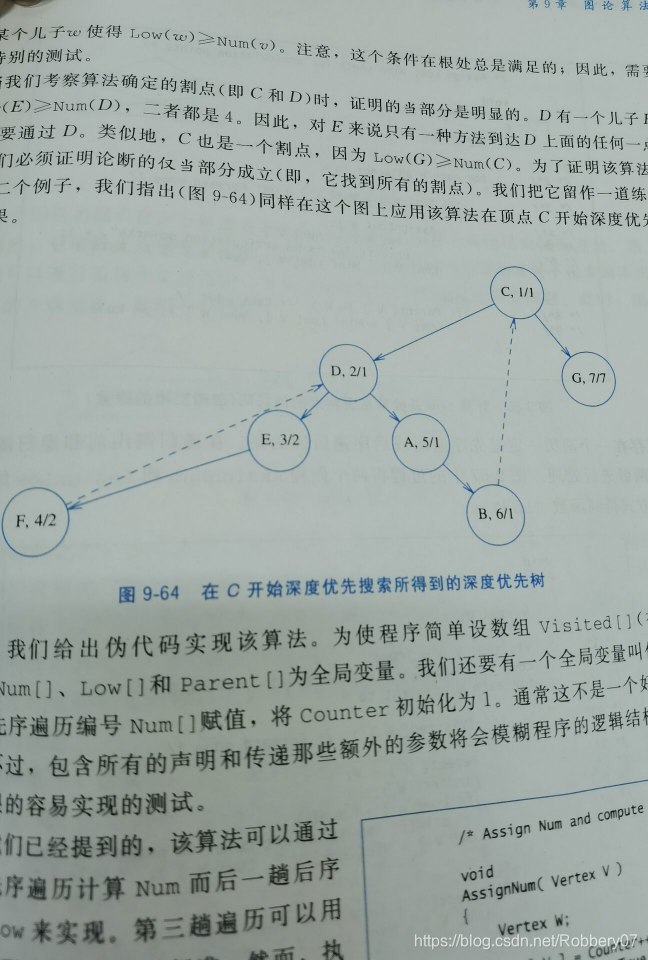
其意义为(个人理解):通过该点,经过零条或多条边及最多一条回边,可以到达的顶点的编号的最小值。例如上图中的C点,其先序编号为3,但可首先通过一条边达到D点,并通过D的回边到达A,所以其low数组编号,及可到达的最低节点编号为1。
上图中顶点的数字标注为visited[v]/low[v]。
Low数组求法

解释:对于任意一个顶点V,其low数组值为自身先序编号(visited[v]),其所有孩子节点的low值的最小值,与其通过回边相连的祖先节点K的先序编号(visited[k])这三者中的最小值。
关节点的判定
1.若生成树中根节点顶点V,其子树个数大于1,则该节点一定为关节点(易理解)。
2.对于非根节点v,它是割点当且仅当它有某个儿子w,使得Low[w]>=Visited[v]。注:该条件在根处总是满足,所以需要进行特别判断。
上例中顶点C与D为关节点。
Low[w]>=Visited[v]的理解:
Low[w]>=Visited[v]含义为,v有某个孩子w,其可到达的节点的最低先序编号大于等于其父亲的先序编号。即w一定不可能到达比v先序编号低的节点(深度优先搜索中比v先访问的节点),则删除节点v后,w一定不能与v之前的节点相连,则该图不为连通图。
Tarjan算法
Tarjan算法为求关节点的常用算法,其时间复杂度为O(V+E)。
void FindArticul(ALGraph G){//连通图G以邻接表作存储结构,查找并输出G上全部关节点。全局量count对访问计数。count = 1; visited[0] = 1; //设定邻接表上0号顶点为生成树的根 for( i=1; i<G.vexnum; ++i) //其余顶点清零,尚未访问。 visited[i]=0;p=G.vertices[0].firstarc; //p为0号顶点指向的第一条依附于它的弧。 v=p->adjvex; //v为该弧所指向的顶点的位置。(即树的根结点) DFSArticul(G,v); //从第v顶点出发深度优先查找关节点 if(count<G.vexnum) //生成树的根至少有两颗子树 {printf(0,G.vertices[0].data); //根是关节点,输出 while(p->nextarc) //指向下一条弧 {p=p->nextarc;v=p->adjvex; if(visited[v]==0)DFSArticul(g,v);} }
}void DFSArticul(ALGraph G,int v0){ //在深度遍历,标记visited[v]的同时检查关节点 //从第v0个顶点出发深度优先遍历图G,查找并输出G上全部关节点。全局count对访问计数。 visited[v0]=min=++count;for(p=G.vertices[0].firstarc;p;p=p->nextarc){ //对v0的每个邻接顶点检查 w=p->adjvex; //w为v0邻接顶点if(visited[w]==0) //w未曾访问,是v0的孩子; 注:结点v的low与其孩子有关,所以一定先递归求出节点的所有子树的low值。 {DFSArticul(G,w); //返回前求得low[w];if(low[w]<min) min=low[w];if(low[w]>=visited[v0])printf(v0,G.vertices[v0].data); //输出关节点; } else if(visited[w]<min) //不是孩子节点,则为v0节点的祖先(回边) min=visited[w];}low[v0]=min;
}
注意点:
1.搜索树的根节点需要特判
2.对于每个顶点V,其low一定要在其所有孩子的low值已知的情况下才能决定,所以在算法中要先递归调用求出所有子树的low值。
3.节点孩子的判断方式(w为v的邻接点,且w之前未被访问),
回边的判断方式(w为v的邻接点,w已被访问)。
4.DFSArticul函数同时实现visited数组的标记,low数组的更新与关节点的判定。
时间复杂度分析:
Tarjan算法的时间复杂度与图的深度优先遍历复杂度相同,都是对所有顶点与边访问一次,复杂度为O(V+E)。
这篇关于图的关节点(Tarjan算法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








