本文主要是介绍使用深度学习进行脑肿瘤检测和定位:第 2 部分,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题陈述
通过使用 Kaggle 的 MRI 数据集的图像分割来预测和定位脑肿瘤。
这是该系列的第二部分。如果你还没有阅读第一部分,我建议你访问使用深度学习进行脑肿瘤检测和定位:第1部分以更好地理解代码,因为这两个部分是相互关联的。
文章地址:https://mp.weixin.qq.com/s/vBsTsVvHjA0gtQy3X1wdmw
我们在 ResNet50 上训练了一个分类模型,该模型使用回调对脑部 MRI 是否有肿瘤进行分类以提高我们的性能。在这一部分,我们将训练一个模型来使用图像分割来定位肿瘤。
先决条件
深度学习
数据集链接:https://www.kaggle.com/mateuszbuda/lgg-mri-segmentation
现在,让我们开始实施第二部分,即构建分割模型来定位肿瘤。
图像分割的目标是在像素级别理解图像。它将每个像素与某个类相关联。图像分割模型产生的输出称为图像的蒙版。
首先,从我们在上一部分创建的数据帧中选择蒙版值为 1 的记录,因为只有肿瘤存在,我们才能对其进行定位。
# Get the dataframe containing MRIs which have masks associated with them.
brain_df_mask = brain_df[brain_df['mask'] == 1]
brain_df_mask.shape输出:(1373, 4)
将数据拆分为训练和测试数据集。首先,我们将整个数据拆分为训练和验证数据,然后将一半的验证数据拆分为测试数据。
from sklearn.model_selection import train_test_split
X_train, X_val = train_test_split(brain_df_mask, test_size=0.15)
X_test, X_val = train_test_split(X_val, test_size=0.5)我们将再次使用DataGenerator 生成虚拟数据,即training_generator 和validation_generator。为此,我们将首先创建要传递到生成器的图像和蒙版路径的列表。
train_ids = list(X_train.image_path)
train_mask = list(X_train.mask_path)val_ids = list(X_val.image_path)
val_mask= list(X_val.mask_path)# Utilities file contains the code for custom data generator
from utilities import DataGenerator# create image generators
training_generator = DataGenerator(train_ids,train_mask)
validation_generator = DataGenerator(val_ids,val_mask)定义一个如下所示的方法 Resblock ,以在我们的深度学习模型中使用。
模型中使用 Resblocks 以获得更好的结果。这些块只是一堆层。resblocks 的主要功能是在顶部学习残差函数,而信息沿底部传递不变。
def resblock(X, f):# make a copy of inputX_copy = XX = Conv2D(f, kernel_size = (1,1) ,strides = (1,1),kernel_initializer ='he_normal')(X)X = BatchNormalization()(X)X = Activation('relu')(X) X = Conv2D(f, kernel_size = (3,3), strides =(1,1), padding = 'same', kernel_initializer ='he_normal')(X)X = BatchNormalization()(X)X_copy = Conv2D(f, kernel_size = (1,1), strides =(1,1), kernel_initializer ='he_normal')(X_copy)X_copy = BatchNormalization()(X_copy)# Adding the output from main path and short path togetherX = Add()([X,X_copy])X = Activation('relu')(X)return X同样,定义 upsample_concat 方法来放大和连接传递的值。Upsampling 层是一个简单的层,没有权重,可以将输入的维度加倍。
def upsample_concat(x, skip):x = UpSampling2D((2,2))(x)merge = Concatenate()([x, skip])return merge建立一个分割模型,添加下面显示的层,包括上面定义的 resblock 和 upsample_concat。
input_shape = (256,256,3)# Input tensor shape
X_input = Input(input_shape)# Stage 1
conv1_in = Conv2D(16,3,activation= 'relu', padding = 'same', kernel_initializer ='he_normal')(X_input)
conv1_in = BatchNormalization()(conv1_in)
conv1_in = Conv2D(16,3,activation= 'relu', padding = 'same', kernel_initializer ='he_normal')(conv1_in)
conv1_in = BatchNormalization()(conv1_in)
pool_1 = MaxPool2D(pool_size = (2,2))(conv1_in)# Stage 2
conv2_in = resblock(pool_1, 32)
pool_2 = MaxPool2D(pool_size = (2,2))(conv2_in)# Stage 3
conv3_in = resblock(pool_2, 64)
pool_3 = MaxPool2D(pool_size = (2,2))(conv3_in)# Stage 4
conv4_in = resblock(pool_3, 128)
pool_4 = MaxPool2D(pool_size = (2,2))(conv4_in)# Stage 5 (Bottle Neck)
conv5_in = resblock(pool_4, 256)# Upscale stage 1
up_1 = upsample_concat(conv5_in, conv4_in)
up_1 = resblock(up_1, 128)# Upscale stage 2
up_2 = upsample_concat(up_1, conv3_in)
up_2 = resblock(up_2, 64)# Upscale stage 3
up_3 = upsample_concat(up_2, conv2_in)
up_3 = resblock(up_3, 32)# Upscale stage 4
up_4 = upsample_concat(up_3, conv1_in)
up_4 = resblock(up_4, 16)# Final Output
output = Conv2D(1, (1,1), padding = "same", activation = "sigmoid")(up_4)model_seg = Model(inputs = X_input, outputs = output )编译上面训练的模型。这次我们将自定义优化器的参数。Focal tversky 是损失函数,tversky 是度量。
# Utilities file also contains the code for custom loss function
from utilities import focal_tversky, tversky# Compile the model
adam = tf.keras.optimizers.Adam(lr = 0.05, epsilon = 0.1)
model_seg.compile(optimizer = adam, loss = focal_tversky, metrics = [tversky])现在,你知道我们在分类器模型中使用的回调。我们将使用相同的方法来获得更好的性能。最后,我们训练我们的分割模型。
# use early stopping to exit training if validation loss is not decreasing even after certain epochs.
earlystopping = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=20)# save the best model with lower validation loss
checkpointer = ModelCheckpoint(filepath="ResUNet-weights.hdf5", verbose=1, save_best_only=True)model_seg.fit(training_generator, epochs = 1, validation_data = validation_generator, callbacks = [checkpointer, earlystopping])预测测试数据集的蒙版。这里,model是前面训练的分类器模型,model_seg是上面训练的分割模型。
from utilities import prediction# making prediction
image_id, mask, has_mask = prediction(test, model, model_seg)输出将为我们提供图像路径、预测蒙版和类标签。
根据预测结果创建数据帧并与 image_path 上的测试数据帧合并。
# creating a dataframe for the result
df_pred = pd.DataFrame({'image_path': image_id,'predicted_mask': mask,'has_mask': has_mask})# Merge the dataframe containing predicted results with the original test data.
df_pred = test.merge(df_pred, on = 'image_path')
df_pred.head()
正如你在输出中看到的那样,我们现在已将最终预测的蒙版合并到我们的数据帧中。
最后,将原始图像、原始蒙版和预测蒙版一起可视化,以分析我们的分割模型的准确性。
count = 0
fig, axs = plt.subplots(10, 5, figsize=(30, 50))
for i in range(len(df_pred)):if df_pred['has_mask'][i] == 1 and count < 5:# read the images and convert them to RGB formatimg = io.imread(df_pred.image_path[i])img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)axs[count][0].title.set_text("Brain MRI")axs[count][0].imshow(img)# Obtain the mask for the image mask = io.imread(df_pred.mask_path[i])axs[count][1].title.set_text("Original Mask")axs[count][1].imshow(mask)# Obtain the predicted mask for the image predicted_mask = np.asarray(df_pred.predicted_mask[i])[0].squeeze().round()axs[count][2].title.set_text("AI Predicted Mask")axs[count][2].imshow(predicted_mask)# Apply the mask to the image 'mask==255'img[mask == 255] = (255, 0, 0)axs[count][3].title.set_text("MRI with Original Mask (Ground Truth)")axs[count][3].imshow(img)img_ = io.imread(df_pred.image_path[i])img_ = cv2.cvtColor(img_, cv2.COLOR_BGR2RGB)img_[predicted_mask == 1] = (0, 255, 0)axs[count][4].title.set_text("MRI with AI Predicted Mask")axs[count][4].imshow(img_)count += 1fig.tight_layout()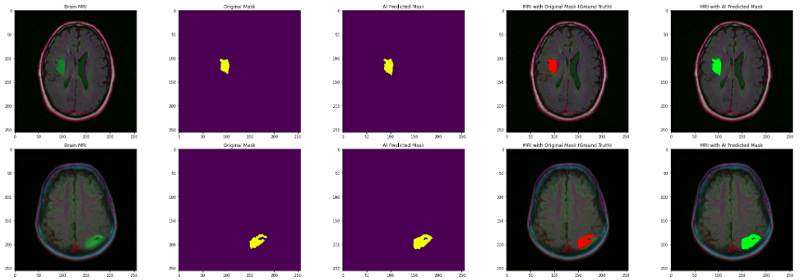
输出显示我们的分割模型非常好地定位了肿瘤。做得好!
此外,你可以尝试向目前训练的模型添加更多层并分析性能。还可以将类似的解决方案应用于其他问题陈述,因为图像分割是当今非常感兴趣的领域。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓

这篇关于使用深度学习进行脑肿瘤检测和定位:第 2 部分的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




