本文主要是介绍论文研读|Protecting Intellectual Property of Deep Neural Networks with Watermarking,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
- 论文信息
- 文章简介
- 研究动机
- 研究方法
- 水印生成
- 水印嵌入
- 版权验证
- 实验结果
- 有效性(Effectiveness)
- 高效性(Converge Speed)
- 保真度(Functionality)
- 鲁棒性(Robustness)
- Anti-剪枝攻击(Pruning)
- Anti-微调攻击(Fine-tuning)
- 安全性(Security)
- Anti-模型逆向攻击(Model Inversion)
- 方法评估
- 相关文献
论文信息
论文名称:Protecting Intellectual Property of Deep Neural Networks with Watermarking
作者:IBM Research 团队
发表年份:2018年
发表会议:ASIACCS
文章简介
本文是第一篇提出「黑盒模型水印」的文章,文章借鉴模型后门攻击的思想,通过构造触发集的方式,将水印嵌入到模型中;在版权验证阶段,验证者通过输入触发集中的图片,验证水印的存在与否。
研究动机
基于白盒水印的版权认证需要验证者掌握模型的结构和参数,而在现实生活中,模型往往以 API 接口的形式被调用,于是基于白盒水印的应用场景受限。基于此,本文便提出「黑盒水印」的思想,确保验证者在模型结构和参数未知的情况下,验证水印的存在与否。
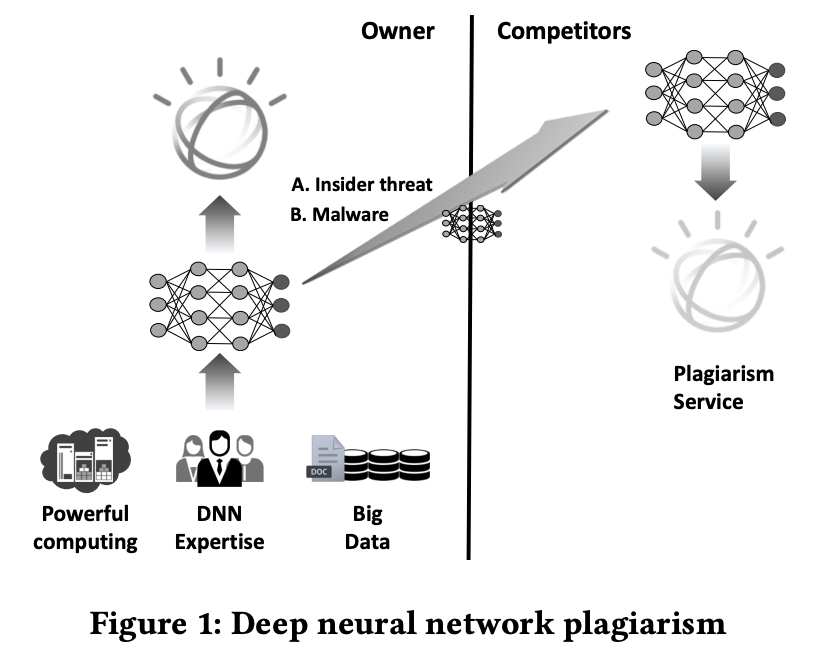
研究方法
考虑到在验证阶段无法获取模型结构和参数信息,本文提出利用输入与输出的映射关系嵌入水印,即给定特定的水印图像,模型若能够输出预设的水印标签,则认为该模型含有水印。其中,水印图像和水印标签构成触发集。
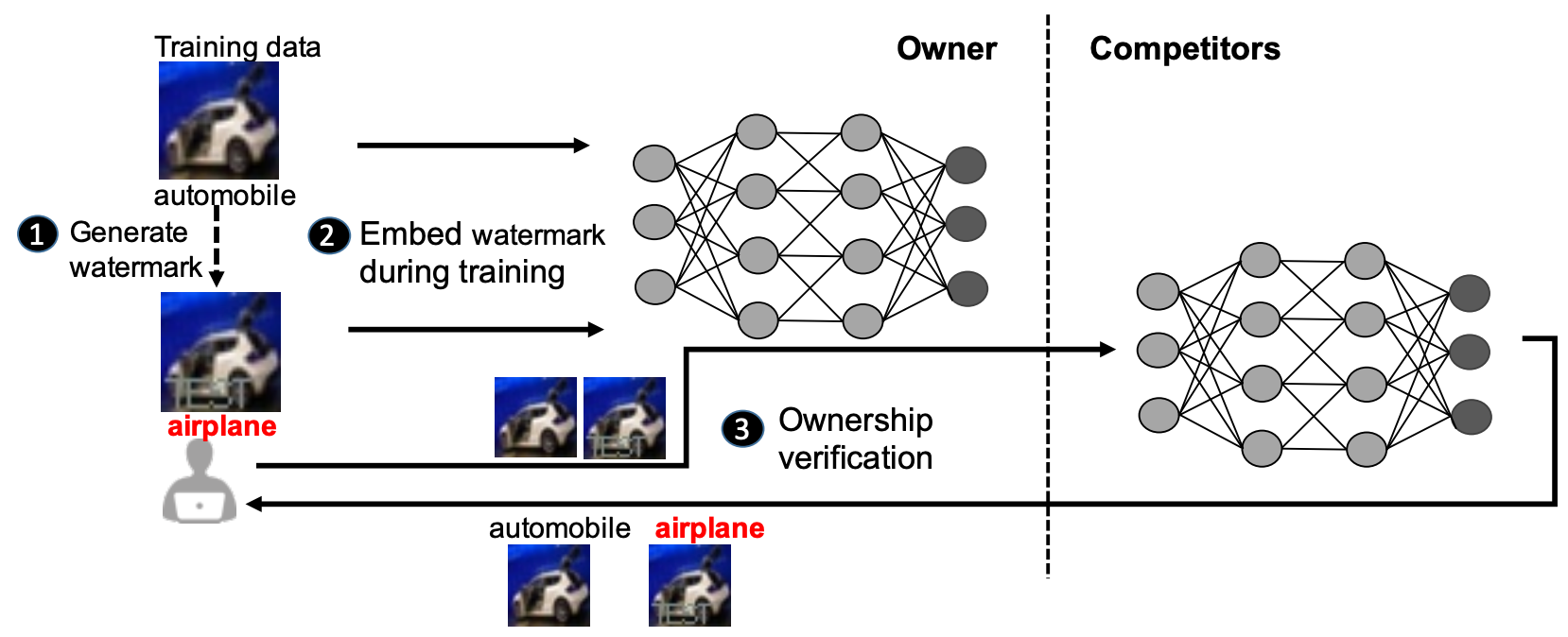
本文提出的完整水印框架如上图,分为「(1)水印生成(2)水印嵌入和(3)版权验证」三个阶段。
水印生成
本文借鉴AI安全中后门攻击的思想,将水印嵌入过程看作模型对另一功能的学习,因此,水印嵌入之前要构造触发集,触发集是基于训练集中的部分训练样本改造以后的样本,图像分类任务的训练样本即为图像和它对应的标签。所以,在水印生成阶段,要分别对图像和标签进行改造,将图像变换为水印图像,并修改对应的标签为水印标签。
本文将水印标签预设为airplane。关于图像变换方法,本文提出如下三种,分别是(b) W M c o n t e n t WM_{content} WMcontent:在原始图像上添加有意义的内容(本文中使用灰色固定位置的TEST字样)(c) W M u n r e l a t e d WM_{unrelated} WMunrelated:将原始图像替换为训练集外的图像(本文中使用手写体图像1)(d) W M n o i s e WM_{noise} WMnoise:在原始图像上添加预设的噪声(本文中使用的高斯噪声)

之所以选择不同方式对图像进行变换,是为了测试DNN对于所要嵌入水印的学习能力。
水印嵌入
构造触发集之后,将它与其余训练数据混合,共同作为模型的训练样本,模型在训练过程中完成水印的嵌入,完整流程如下:

版权验证
将 D w m D_{wm} Dwm中的 x w m x_{wm} xwm输入可疑模型中,若模型的预测标签为 y w m y_{wm} ywm,说明该模型含有水印,证实了模型被窃取的事实。
实验结果
应用场景:图像分类任务
数据集:MNIST & CIFAR-10
有效性(Effectiveness)
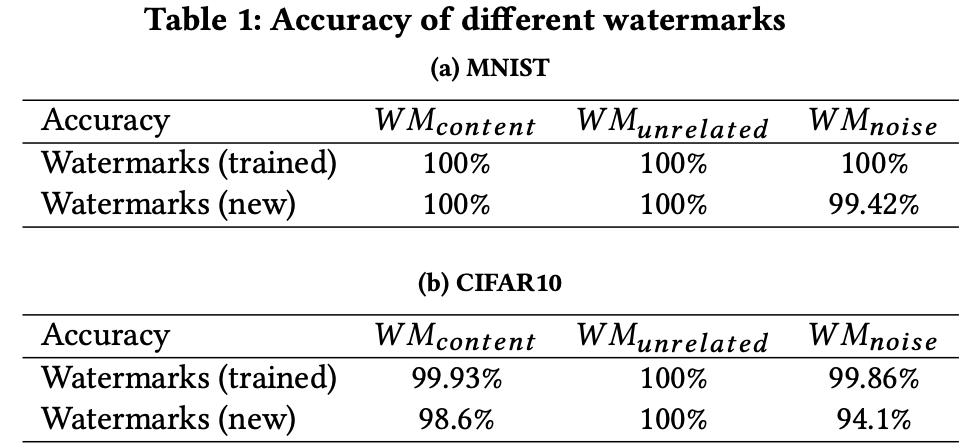
高效性(Converge Speed)
在训练期间,添加水印的模型收敛速度与不添加水印的模型持平,说明水印的添加对训练代价的影响程度较低。
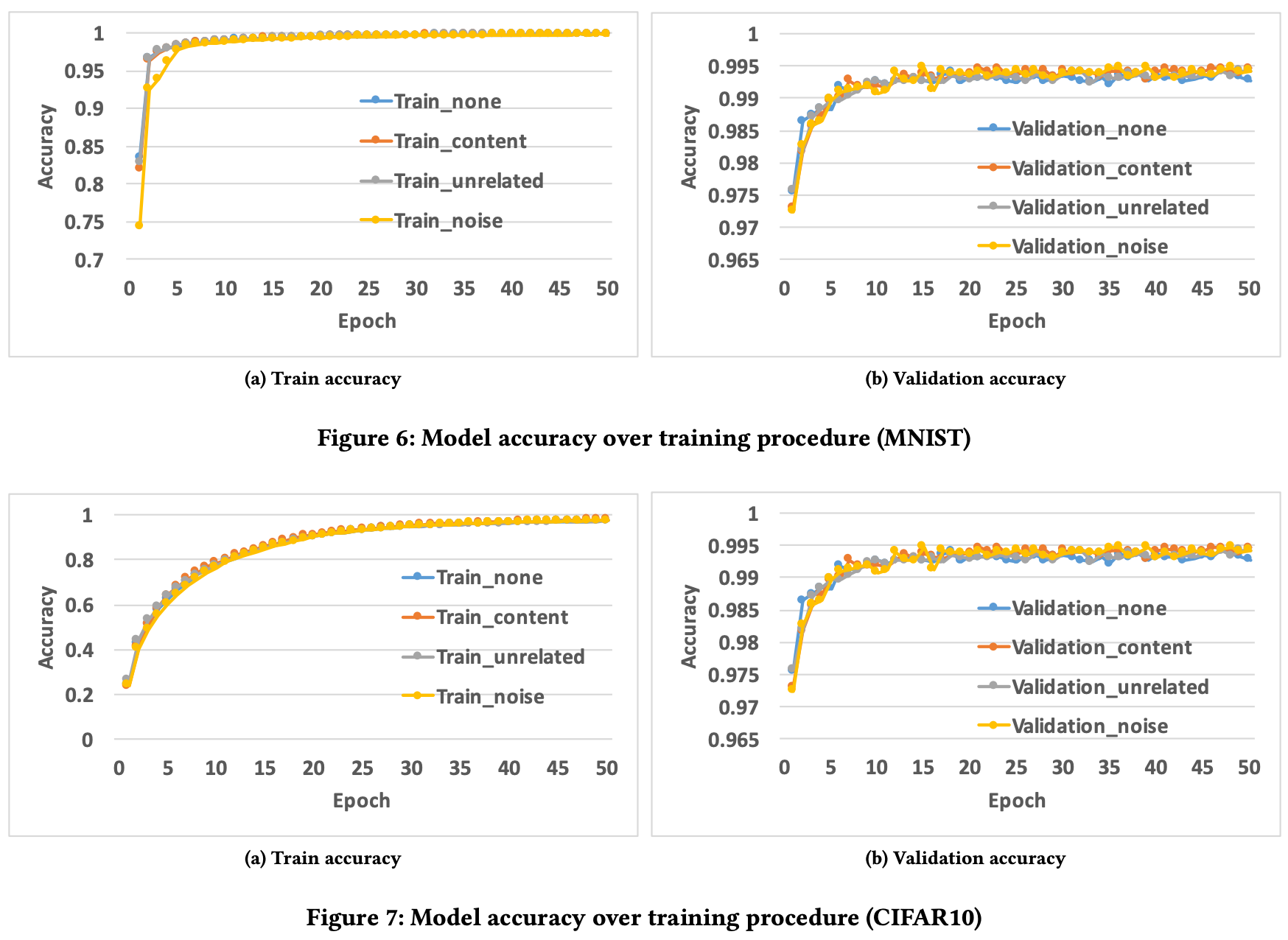
保真度(Functionality)
添加水印的模型对原始任务的性能影响较低,说明水印具有较好的保真度。

鲁棒性(Robustness)
本文主要对水印的抗剪枝攻击和抗微调攻击两个角度进行鲁棒性评估。
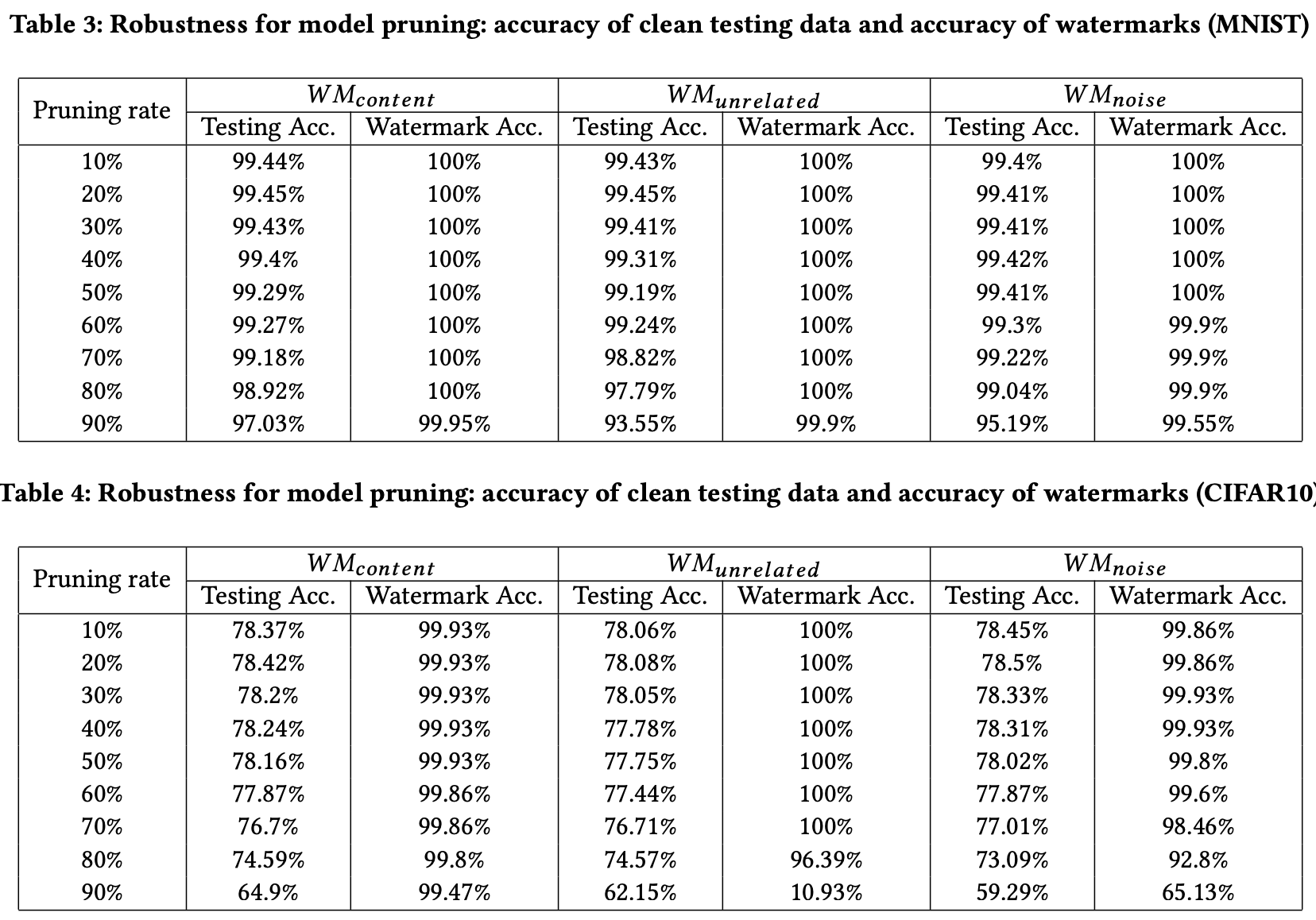
Anti-剪枝攻击(Pruning)
结合Table2观察发现,在保证模型可用的情况下,剪枝攻击对水印的影响程度较小。
Anti-微调攻击(Fine-tuning)

安全性(Security)
安全性的目标是衡量嵌入的水印是否易于被未经授权的各方识别或修改。这里通过水印的抗模型逆向攻击能力对水印的安全性进行评估。
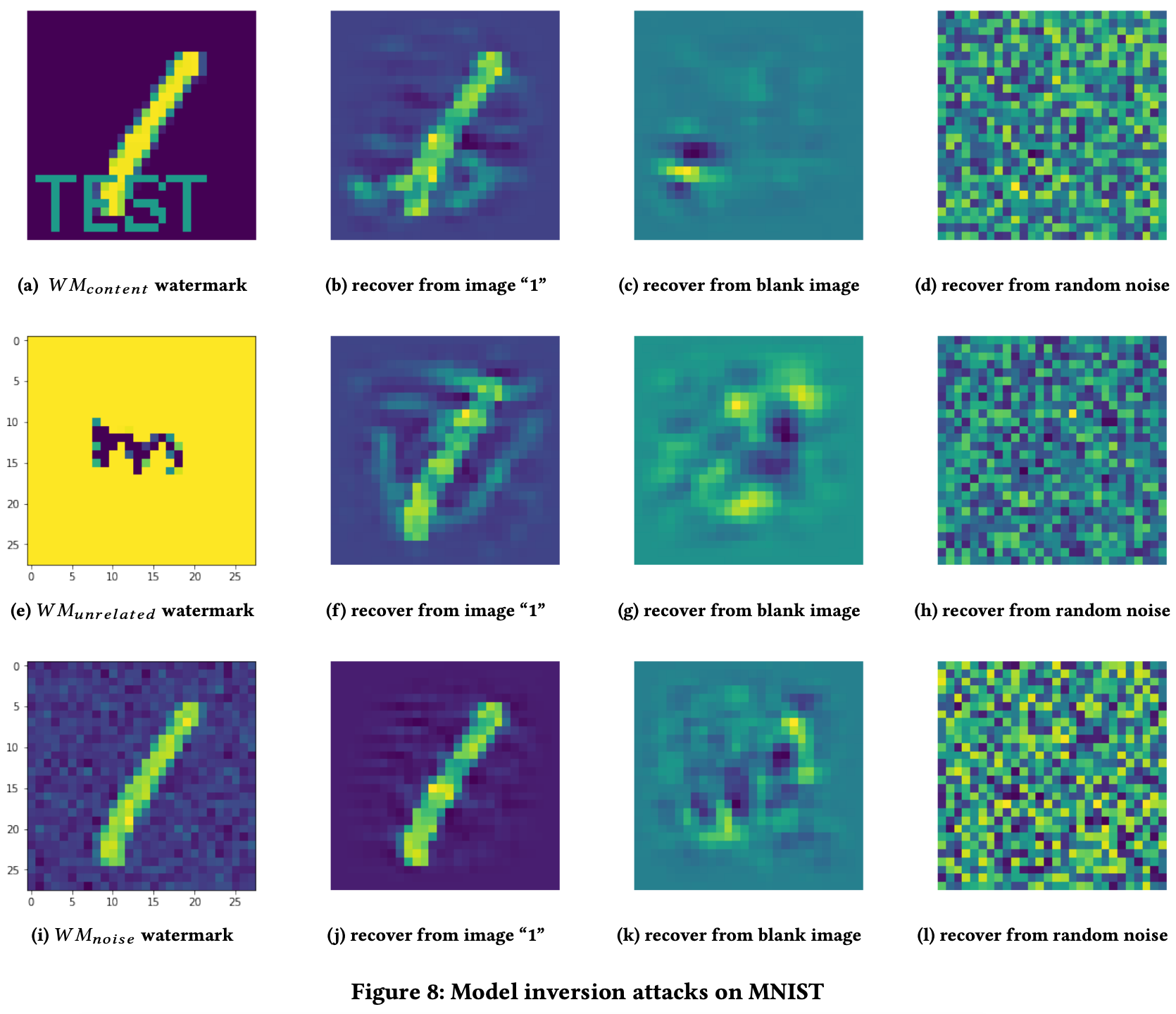
Anti-模型逆向攻击(Model Inversion)
模型逆向攻击旨在通过模型的输出逆推出训练数据,从而暴露水印。在本文的场景中,模型逆向攻击的目标就是在攻击者已知水印标签的情况下,逆推出对输入图像的变换,即重构出水印图像,从下图可以看出,此种水印方法能够很好地抵御该攻击方式。

方法评估
(1)该方法需要掌握模型的API调用接口,若模型为非公开服务状态,此方法失效。
(2)模型窃取攻击:攻击者可以利用查询访问和结果机密性之间的关系来窃取机器学习模型的参数。使用本文方法添加水印的模型仍有被窃取的风险。 [ 53 ] ^{[53]} [53]
(3)逃逸攻击:由于该方法是基于API查询的方式验证水印的存在与否,因此,若攻击者识别出验证者的异常查询并中断查询,该水印框架就会失效。 [ 39 ] ^{[39]} [39]
相关文献
[39] Meng et al. MagNet: a Two-Pronged Defense against Adversarial Examples. CCS, 2017.
[53] Florian Tramer et al. Stealing Machine Learning Models via Prediction APIs. USENIX, 2016.
这篇关于论文研读|Protecting Intellectual Property of Deep Neural Networks with Watermarking的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)