本文主要是介绍SparkSQL并行执行多个Job的探索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现象
先来看个现象,下图中一个sql任务居然有多个job并行跑,为什么呢?

不错看到这里是不是有很多疑问,下面我就带着这些疑问,从以下几方面一一解答。
看看Spark的调度框架是否支持并行提交多个job(引用了些其他博主的内容)
讲解
SparkSQL的ThriftServer入口,为后面SQL并行提交Job做铺垫讲解在非自适应与自适应情况下SQL的并行提交Job的机制
1 并行提交多个job
1.1 是否支持并行提交多个任务
df.write.partitionBy("type", "interval").mode("append").parquet("s3://data")通过
partitionBy功能让Spark自动做将数据写入不同的分区路径。对于一个
Spark Job,我们总是期望能充分利用所有的cpu-vcore来并行执行,因此通常会将数据repartition成cpu-vcore的个数,即每个cpu-vcore上跑一个Task。而对于写文件的Job,每个Task会写入到自己的一个文件中,最终生成的文件数是由Task个数决定。在下图中,假设集群总共有12个cpu-vcore分配给Executor使用,那么就会有12个Task并行执行写入,最终生成12个文件。

从充分利用资源的角度来看,这样的设计无疑是最佳的。但是,
对于一些实时流处理任务或者周期性的离线任务而言,这样做会产生大量的小文件,会给后续的文件加载和快速查询带来困难。因此,从尽可能产生少量文件的角度出发,需要采用下图所示的写入方式,即在写入前,将数据分配到少量的Partition中,用少量的Task来执行。但是,这样做就会导致有部分cpu-vcore在写入过程中处于闲置状态,造成了资源浪费。
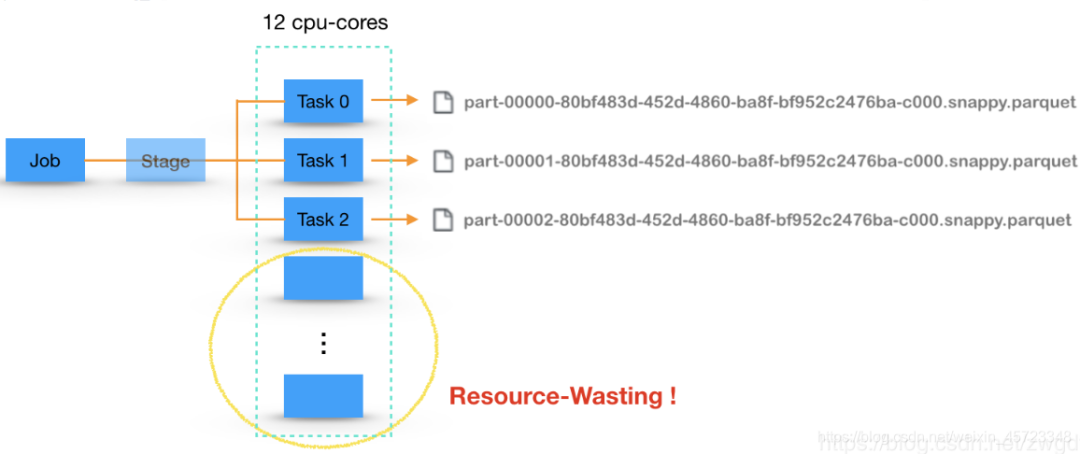
显然,在这件事情上,“充分利用资源”和“产生少量文件”两个方向发生了冲突。那么,有没有一个两全之策呢?即既保证产生少量文件,又能把原本闲置的资源利用起来。如下图所示,假设我们能
同时跑多个写入文件的Job,每个Job利用一部分cpu-vcore来执行,似乎就可以达到这个目的了。带着这样的思路,做一番调研与实践。

上述思路可以总结为:通过一个SparkContex并行提交多个Job,由Spark自己来调度资源,实现并行执行。针对这个思路,首先要搞清楚Spark是否支持这么玩,如果支持的话又是怎么支持的。
简单梳理下Spark的任务调度机制:
SparkContext向DAGScheduler提交一个Job后,会创建一个JobWaiter对象,用于阻塞当前线程,等待Job的执行结果。因此,在一个线程中,Job是顺序执行的。DAGScheduler会根据RDD的依赖关系将一个Job划分为若干个Stage(以Shuffle为界)。因为前后Stage存在数据上的依赖,所以只有父Stage执行完毕才能提交当前Stage。DAGScheduler在提交Stage时,会根据Partition信息生成相应的Task,打包成TaskSet,提交给TaskScheduler。而TaskScheduler收到后,会将TaskSet封装成TaskSetManager,丢到任务队列中等待执行。SchedulerBackend负责Executor状态与资源的管理,当发现有空闲资源时,就会通过TaskScheduler从任务队列中取出相应的TaskSetManager去调度执行。TaskSetManager中的Task最终会分发到Executor中的线程里去执行。
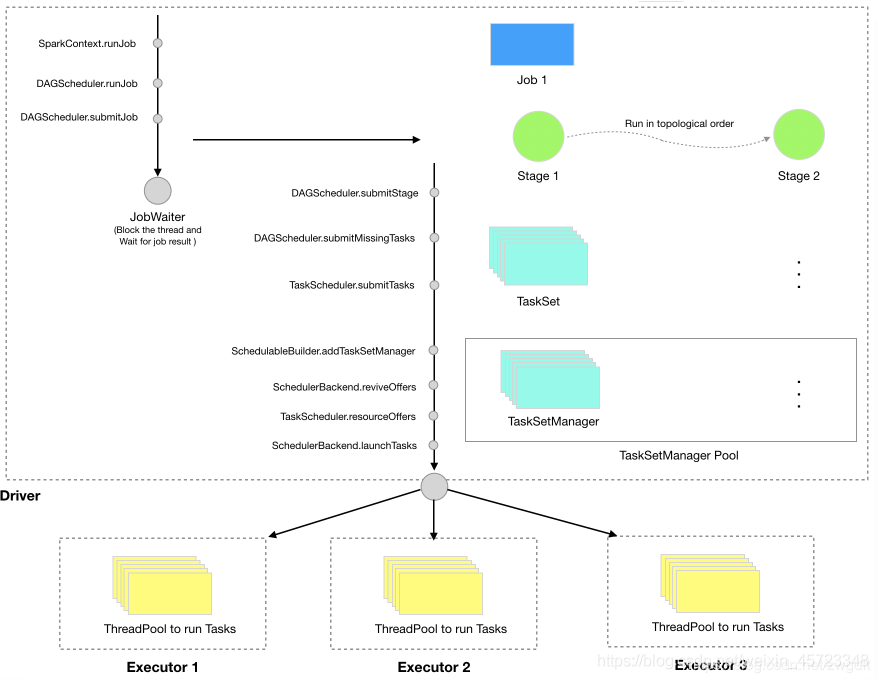
Spark是以TaskSetManager为单元来调度任务的。通常情况下,任务队列中只会有一个TaskSetManager,而通过多线程提交多个Job时,则会有多个TaskSetManager被丢到任务队列中。在有空闲资源的情况下,谁会从队列里被取出来执行就取决于相应的调度策略了。目前,Spark支持FIFO和FAIR两种调度策略。
基本可以明确以下两点:
Spark支持通过多线程在一个
SparkContext上提交多个Job,每个线程里面的Job是顺序执行的,但是不同线程的Job是可以并行执行的,取决当时Executor中是否有充足的cpu-vcore。任务队列中的
TaskSetManager是有序执行,还是轮询执行(可分配权重)取决于采用哪种调度策略。
可以用多线程方式并行提交Job,示例如下:
var df = spark.read.json("person.json").repartition(55)
// df.cache()
// val c = df.count()
// println(s"${c}")val jobExecutor = Executors.newFixedThreadPool(5)
for( _ <- Range(0, 5) ) {jobExecutor.execute(new Runnable {override def run(): Unit = {val id = UUID.randomUUID().toString()df.coalesce(11).write.json(s"hdfs://ns1/user/root/data/test/${id}")}})
}1.2 Spark Thrift Server简单讲解
Thrift 是一种接口描述语言和二进制通信协议,由 Facebook 开发并贡献到 Apache 开源社区,用来定义和创建跨语言的服务 。Thrift包含的代码生成引擎可以应用于多种语言中,包括C ++、 Java 、 Python 等 。其数据传输采用二进制格式,相对常用的 XML 和 JSON 格式体积更小,在多语言、高并发和大数据场景下更具优势 。
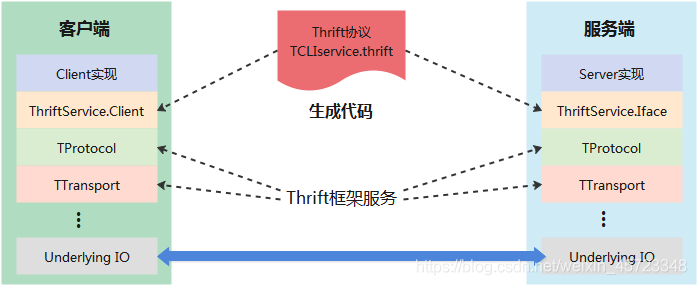
Thrift 框架支持使用
IDL (Interface Definition Language)定义服务接口,然后利用提供的编译器将服务接口编译成不同语言的实现代码,从而实现服务端和客户端跨语言的支持。SparkThriftServer中定义的 Thrift的协议在 if 目录下的TCLIService. thrift文件中 。客户端与服务端工作的原理如下图所示,协议层( Protocol)、传输层(Transport)乃至底层 IO传输的具体实现都不需要用户关心 。
Spark 中启动ThriftServer 的主要流程 :
整个服务的生命周期从执行。sbin 文件夹下的start-thriftserver.sh脚本开始直到执行stop-thriftserver脚本结束。最终调用sparkSubmit接口提交org.apache.spark.sql.hive.thriftserver.HiveThriftServer2应用。

ThriftCLIService作为服务端负责维护与客户端的连接并将客户端的请求转发至SparkSQLCLIService,SparkSQLCLIService通过调用后端Hive或Spark系统完成运算并把执行结果返回给ThriftCLIService, 最终ThriftCLIService把结果返回给客户端 。ThriftCLIService有ThriftHttpCLIService和ThriftBinaryCLIService两种形式,分别对应 Http输模式和 Binary 传输模式,通过配置参数( hive.server2. transport.mode)进行判断,默认为 Binary模式。SparkSQLSessionManager对象,用于 Session 的管理 。而SparkSessionManager是SessionManager的子类,构造参数也比SessionManager多了一个 SQLContext,其内部包含一个SparkSQLOperationManager对象,用于 Operation 的管理。SparkSQLCLIService、SparkSQLSessionManager、SparkSQOperationManager三者 之间的关系类似基本的CLIService、SessionManager、OperationManager之间的关系 。SparkOperationManager创建的是SparkExecuteStatementOperation, 查询发送给 SparkSQL 完成 。SparkExecuteStatementOperation是 Spark SQL 执行 SQL 语句的最终实现,其内部声明了4 个比较重要 的对象 :执行 SQL 语句 生成的 result (DataFrame 类型)、结果集的迭代器iter(Iterator [SparkRow] 类型)、结果集头部迭代器iterHeader (Iterator[SparkRow]类型)和数据类型dataTypes ( Array[DataType] 类型 )。作为 Operation 的子类,外部调用的接口是 runInternal 方法,但其核心逻辑在execute方法中实现 。
def execute() : Unit = {
****************************************
result = sqlContext.sql (statement) // 构造逻辑计划阶段和物理计划阶段, 最终得到 的是 DataFrame 数据类型
****************************************
iter = {
val useincrementalCollect = sqlContext.getConf(
" spark.sql.thriftServer.incrementalCollect","false").toBoolean
if (useincrementalCollect) {
result.toLocaliterator.asScala
} else {
****************************************
result.collect().iterator // 启动runJob
****************************************
val (itra, itrb) = iter. duplicate
IterHead = itra
iter = itrb
dataTypes = result.queryExecution.analyzed.output.map(_.dataType).toArray
…………………………………………………………………………………………………………………………………………
}1.3 SparkSQL中如何并行Job
举个例子TPC-DS中标准SQL第一个sql为例子来说明并行Job:
with customer_total_return as
(select sr_customer_sk as ctr_customer_sk
,sr_store_sk as ctr_store_sk
,sum(SR_FEE) as ctr_total_return
from store_returns
,date_dim
where sr_returned_date_sk = d_date_sk
and d_year =2001
group by sr_customer_sk
,sr_store_sk)select c_customer_id
from customer_total_return ctr1
,store
,customer
where ctr1.ctr_total_return > (select avg(ctr_total_return)*1.2
from customer_total_return ctr2
where ctr1.ctr_store_sk = ctr2.ctr_store_sk)
and s_store_sk = ctr1.ctr_store_sk
and s_state = 'MI'
and ctr1.ctr_customer_sk = c_customer_sk
order by c_customer_id
limit 100;在开启与关闭自适应情况下来比对对比生成的并行Job数:

上图中看到明显开启spark.sql.adaptor.enabled=true情况下生成的并行Job更多,下面我们分析一下两种情况的执行计划。
关闭自适应情况下执行计划如下,根节点为TakeOrderAndProject,如下图所示(由于DAG图比较庞大,只截取了一部分):
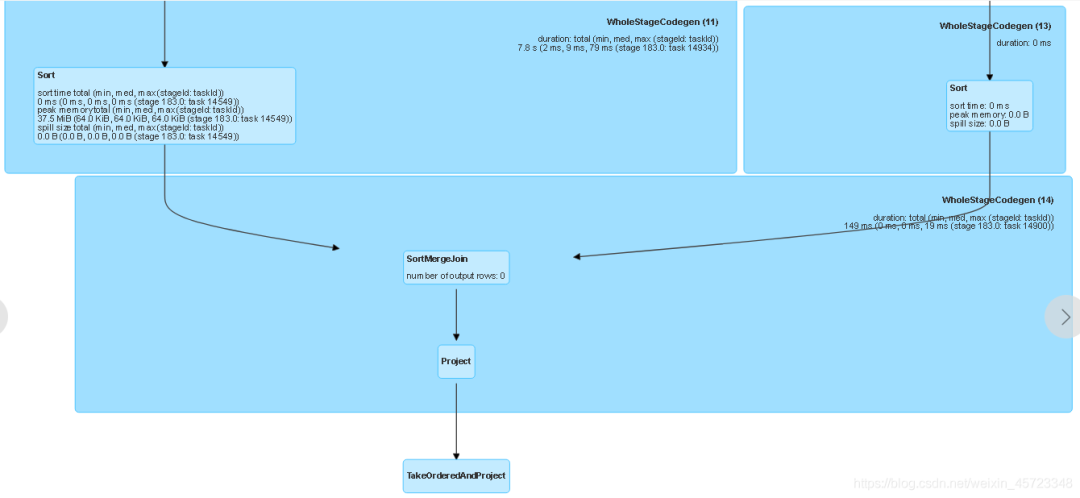
开启自适应情况下,根节点为AdaptiveSparkPlan,他的子节点才为TakeOrderAndProject,如下图所示(DAG部分截图)。
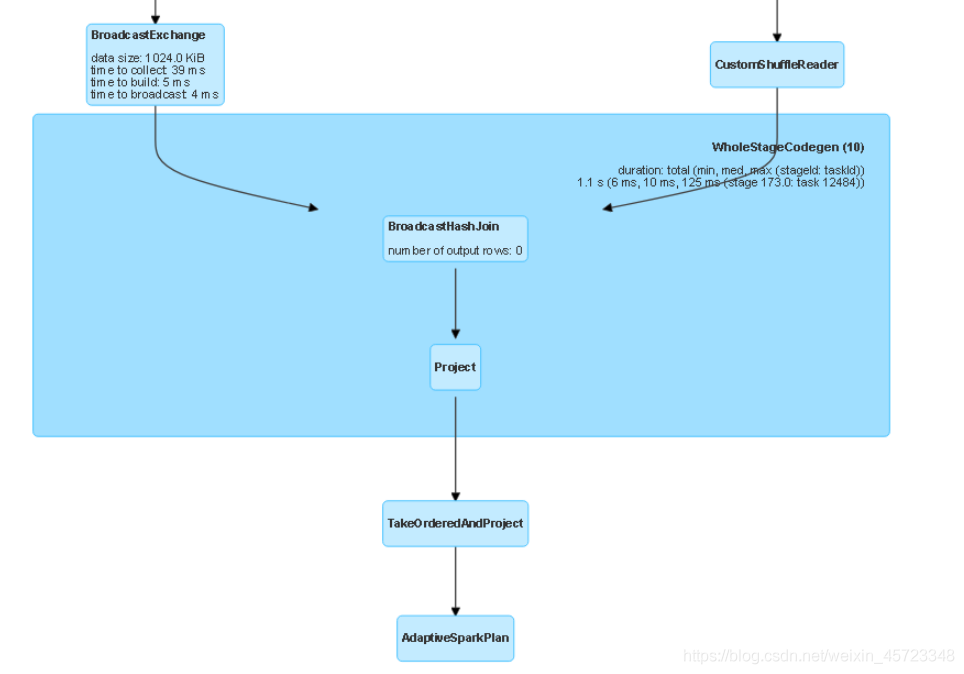
1.3.1 主Job如何生成
有上一章节中已经指定SQL的提交过程,并且SparkExecuteStatementOperation#execute主方法中执行了sqlContext.sql()进行了构造逻辑计划阶段和物理计划阶段, 最终得到 的是 DataFrame 数据类型。调用result.collect()真正启动了一个job。流程如下图所示:
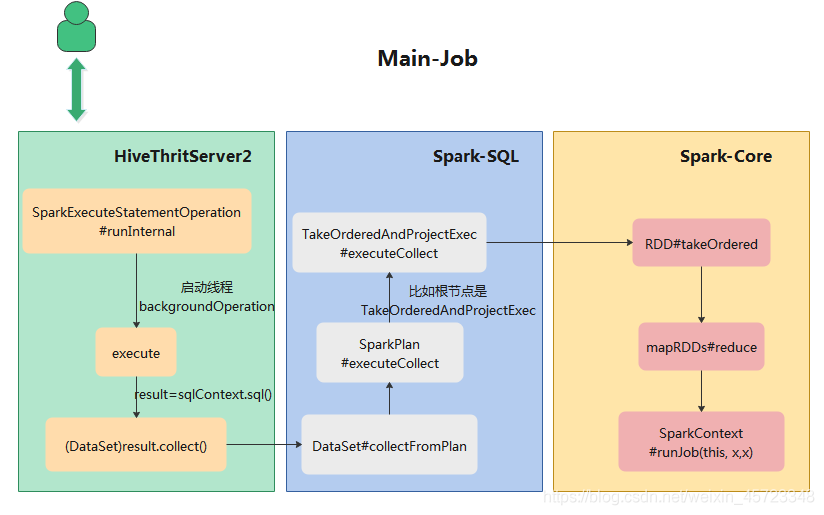
从上图中可以看到主Job是由HiveThriftServer2驱动的DataSet.collect来触发的,上面例子用跟节点为TakeOrderAndProjectExec来走的流程,实际后期调用的还是RDD#takeOrdered来触发的。
1.3.2 子Job如何生成
SparkPlan是一颗庞大的树,上一章节中提到DataSet#collectFormPlan调用到SparkPlan#executeCollect此方法可以是其他类型的跟节点,目前继承的有下图这些,当开启自适应则调用的是AdaptiveSparkPlanExec#executeCollect方法:
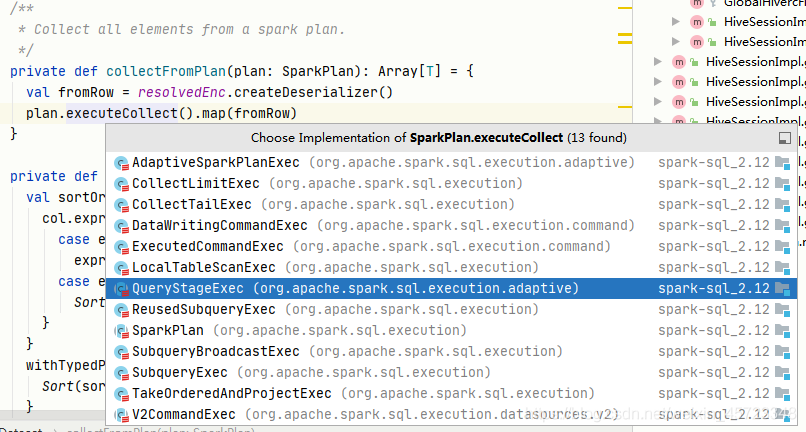
其中自适应查询包adaptive的QueryStageExec有两个继承类BroadcastQueryStageExec与ShuffleQueryStageExec。

子Job并行启动的所有流程,如下图所示:
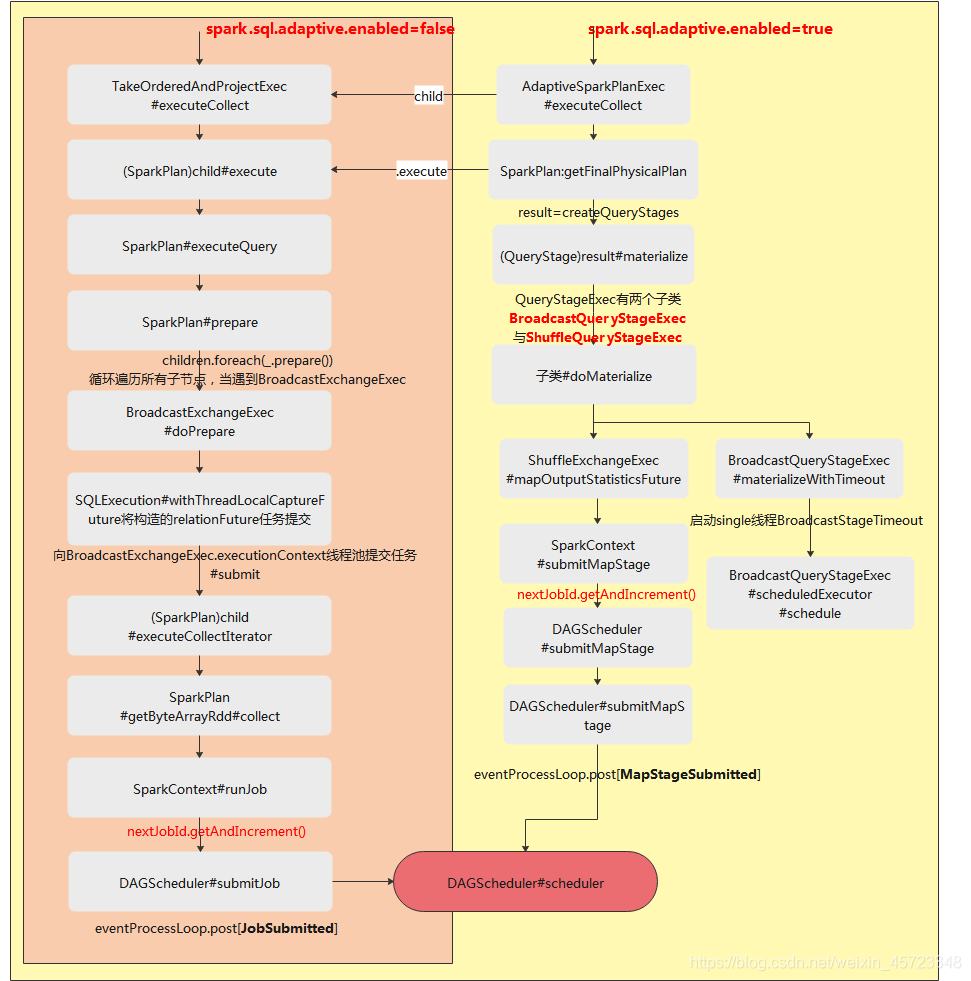
当不开启自适应时,入口是通过TakeOrderAndProject#child#execute来构造任务想BroadcastExchangeExec中线程池提交child#executeCollectIterator任务来触发collect操作从而启动了子Job。
当开启自适应时,入口是AdaptiveSparkPlan#executeCollect,中间也会走不开启自适应的路启动一批广播的子Job,在调用AdaptiveSparkPlan#getFinalPhysicalPlan时,会调用子类doMaterialize方法在子类中会启动BroadcastStageTimeout线程,重要的是submetMapStage线程来向DAGScheduler提交MapStageSubmitted任务来触发另一批子Job启动。
以上就是对SparkSQL并行执行多个Job的所有探索,与一个Job转成DAG从而划分层多个Stage不是同层次的原理,希望能帮助到大家!

这篇关于SparkSQL并行执行多个Job的探索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






