sparksql专题

SparkSQL在字节跳动的应用实践和优化实战
来源:字节跳动白泉的分享 作者:大数据技术与架构整理 点击右侧关注,大数据开发领域最强公众号! 点击右侧关注,暴走大数据! By 大数据技术与架构 场景描述: 面对大量复杂的数据分析需求,提供一套稳定、高效、便捷的企业级查询分析服务具有重大意义。本次演讲介绍了字节跳动

SparkSQL内核解析-执行全过程概述
大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 从SQL到RDD // 创建SparkSession类。从2.0开始逐步替代SparkContext称为Spark应用入口var spark = SparkSession.builder().appName("appName").master("local").getOrCreate()

【硬刚大数据之面试篇】2021年从零到大数据专家面试篇之SparkSQL篇
📢欢迎关注博客主页:https://blog.csdn.net/u013411339 📢欢迎点赞 👍 收藏 ⭐留言 📝 ,欢迎留言交流! 📢本文由【王知无】原创,首发于 CSDN博客! 📢本文首发CSDN论坛,未经过官方和本人允许,严禁转载! 本文是对《【硬刚大数据之学习路线篇】2021年从零到大数据专家的学习指南(全面升级版)》的面试部分补充。 硬刚大数据系列文章链接:

SparkSQL DML语句详解
前言 数据操作语句用于添加、更改或删除数据。Spark SQL 支持以下数据操作语句: INSERT TABLEINSERT OVERWRITE DIRECTORYLOAD INSERT TABLE INSERT 语句将新行插入到表中,或者覆盖表中现有的数据。插入的行可以通过值表达式指定,也可以是查询的结果。 语法 INSERT [ INTO | OVERWRITE ] [ TABL

SparkSQL缓存的用法
前言 SparkSQL关于缓存的操作语句官方给了三种: CACHE TABLE(缓存表)UNCACHE TABLE(清除指定缓存表)CLEAR CACHE(清除所有缓存表) 下面我们详细讲解这些语句的使用方法。 CACHE TABLE CACHE TABLE 语句使用给定的存储级别缓存表的内容或查询的输出。如果一个查询被缓存,那么将为此查询创建一个临时视图。这减少了在未来的查询中对

大数据-97 Spark 集群 SparkSQL 原理详细解析 Broadcast Shuffle SQL解析过程
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(正在更新!) 章节内容 上节我们完成了如下的内容: SparkSQL 语句 编码 测试 结果输入
Java实现SparkSQL Thrift方式读取Hive数据
前提是启动Thrit端口,我这里Thrift端口12000。 @Overridepublic QueryResult SparkOnLine(String sql, String userName) {ResultSet resultSet = null; Statement stmt = null; Connection conn = null; boolean
Java实现SparkSQL查询Hive表数据
简单说: 项目代码 package test;import org.apache.log4j.Level;import org.apache.log4j.Logger;import org.apache.spark.sql.SparkSession;public class SparkSQLJob {private static final String WRITE_FORMAT
Java实现SparkSQL Thrift 方式读取Hive数据
private List<List<String>> queryHiveData(String sql) {ResultSet resultSet = null; Statement stmt = null; Connection conn = null; boolean flag = true; int columnsCount = 0; String U

SparkSQL遵循ANSI标准
ANSI简介 ANSI Compliance通常指的是遵循美国国家标准学会(American National Standards Institute, ANSI)制定的标准。在计算机科学和技术领域,这通常涉及到数据库管理系统(DBMS)对于SQL语言的支持程度。 ANSI为SQL(Structured Query Language)制定了多个标准,这些标准定义了如何以一致的方式编写SQL查询

数据仓库之SparkSQL
Apache Spark SQL是Spark中的一个组件,专门用于结构化数据处理。它提供了通过SQL和DataFrame API来执行结构化数据查询的功能。以下是对Spark SQL的详细介绍: 核心概念 DataFrame: 定义: DataFrame是一个分布式数据集合,类似于关系型数据库中的表。它是以命名列的形式组织数据的。特性: DataFrame API是高层次的API,支持复杂查
SparkSQL读取HBase数据,通过自定义外部数据源(hbase的Hive外关联表)
关键字:SparkSQL读取HBase、SparkSQL自定义外部数据源 前面文章介绍了SparSQL通过Hive操作HBase表。 SparkSQL从1.2开始支持自定义外部数据源(External DataSource),这样就可以通过API接口来实现自己的外部数据源。这里基于Spark1.4.0,简单介绍SparkSQL自定义外部数据源,访问HBase表。 在HBase中

SparkSQL中创建外部表及使用
一、使用需求 工作中经常会需要与外围系统打交道,由于外围系统和本系统不处于同一个Hadoop集群下,且不具有访问本系统的权限,所以基本上大数据量的接口都是以文件的方式进行传输。如何快速、便捷的将文件入Spark库中? 通过SparkSQL中创建外部表的方式就能够很好地解决这一需求。 二、解决方案 1. hdfs上创建存放外部表数据文件的目录 hdfs dfs -mkdir -p /hup

SparkSQL中使用concat_ws函数报错:cannot resolve 'concat_ws(,,(hiveudaffunction...
一、报错信息 Exception in thread "main" org.apache.spark.sql.AnalysisException: cannot resolve 'concat_ws(,,(hiveudaffunction(HiveFunctionWrapper(org.apache.hadoop.hive.ql.udf.generic.GenericUDAFCollectSet

SparkSQL整合Hive实现metastore元数据共享
一、需求 在兼容Hive技术的前提下,推进SparkSQL技术的使用,那么就会衍生出一个问题:如何让Hive和SparkSQL数据共享?,比如在Hive中操作,然后在SparkSQL中能够看到变化,反之亦然。 注意:记住一个前提,先使用Hive在先,后引入SparkSQL,笔者在操作过程中发现了一个问题,之前SparkSQL中的数据会看不到,只能看到Hive中的,这个问题有待进一步研究。 H
HIVE及SparkSQL优化经验
简介 针对高耗跑批时间长的作业,在公司近3个月做过一个优化专项;优化成效:综合cpu、内存、跑批耗时减少均在65%以上; cpu和内存消耗指的是:vcoreseconds和memoryseconds 这里简单说下优化的一些思路,至于优化细节之前写过两篇,或可参考:: sparksql优化:https://blog.csdn.net/me_to_007/article/details/1309
SparkSql搭建
Spark on yarn已搭建好,开始使用SparkSql,做如下工作 1、将hive-site.xml copy至$SPARK_HOME/conf目录,注意配置hive.metastore.uris、hive.metastore.client.socket.timeout 2、复制mysql-connector-java.jar 到$SPARK_HOME/lib目录 3、配置spark-
【数仓系列】maxcompute、postgresql、sparksql等行转列数据处理实战总结(其他类型持续总结更新)
1.熟悉、梳理、总结项目研发实战中的SQL开发日常使用中的问题、经验总结,都是常用的开发技能,可以省去很多时间,时间长就忘记了 2.欢迎点赞、关注、批评、指正,互三走起来,小手动起来! 文章目录 1.`maxcompute`行专列`SQL`示例2.`postgresql`行专列`SQL`示例2.`sparksql`行专列`SQL`示例 1.maxcompute行专列SQL
SparkSQL(6):外部数据源
一、总括 1.参考官网: http://spark.apache.org/docs/2.1.0/sql-programming-guide.html#data-sources 2.SparkSQL支持多种数据源,这个部分主要讲了使用Spark加载和保存数据源。然后,讲解内置数据源的特定选项。 3.数据源分类: (1)parquet数据 (2)hive表 (3)jdbc连接其他数据库(
在sparkSQL中无法找到Hive表apache.spark.sql.catalyst.analysis.NoSuchTableException:Table or view ‘emp‘ not f
1.问题描述 使用Scala编程,通过SparkSession连接hive中的表,但是没有找到,报错: Exception in thread "main" org.apache.spark.sql.catalyst.analysis.NoSuchDatabaseException: Table or view 'emp' not found in database 'default'; 然
SparkSQL(9)RDD2DataFrame
一、两种方式 【参考官网:http://spark.apache.org/docs/2.1.0/sql-programming-guide.html#programmatically-specifying-the-schema】 Inferring the Schema Using Reflection(反射方式)Programmatically Specifying the Schema(编
SparkSQL入门(4)
无论是SQL AST,DataFrame还会Dataset都是按照这个流程来执行的 Unresolved Logical Plan 先生成一个纯粹的逻辑计划,这个时候还没和实际上的数据有任何的交互 Logical Plan 这个时候和数据交互后得到一个实际的逻辑执行计划 Optimized Plan 因为上一步已经和数据进行一定的交互,引擎可以在这个基础上进行一定的优化 Physical Plan
大数据开发之Spark篇---SparkSQL入门(5)
Catalog Catalog是一个抽象类,我们一般用它来对Spark里面的元数据进行操作的,其实现类是CatalogImpl这个类型 我们一般使用catalog是在sparkSession的实例对象里调用的,将返回一个Catalog对象,使用这个对象就可以直接查看元数据了。 val spark = SparkSession.builder().master("local[2]").appName
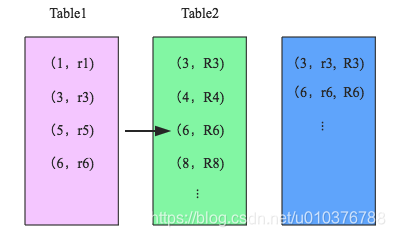
【SparkSQL】聊一聊 Join
1. Join 背景介绍 Join 是数据库查询永远绕不开的话题,传统查询 SQL 技术总体可以分为简单操作(过滤操作 WHERE、排序操作 LIMIT 等),聚合操作 GROUPBY 等以及 JOIN 操作等。其中 Join 操作是其中最复杂、代价最大的操作类型,也是 OLAP 场景中使用相对较多的操作。因此很有必要聊聊这个话题。 另外,从业务层面来讲,用户在数仓建设的时候也会涉及 Join
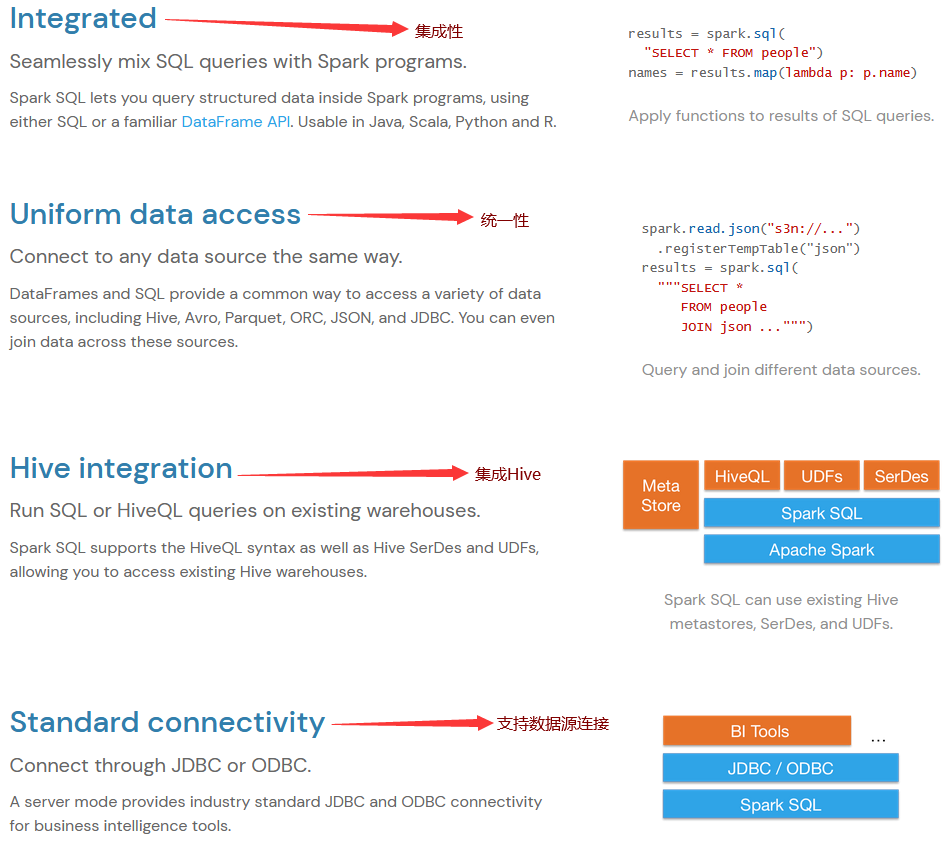
SparkSQL概述
1.1. SparkSQL介绍 SparkSQL,就是Spark生态体系中的构建在SparkCore基础之上的一个基于SQL的计算模块。SparkSQL的前身不叫SparkSQL,而是叫做Shark。最开始的时候底层代码优化、SQL的解析、执行引擎等等完全基于Hive,总是Shark的执行速度要比Hive高出一个数量级,但是Hive的发展制约了Shark。因此在15年中旬的时候,Shark的负责

SparkSQL与Hive整合 、SparkSQL函数操作
SparkSQL与Hive整合 SparkSQL和Hive的整合,是一种比较常见的关联处理方式,SparkSQL加载Hive中的数据进行业务处理,同时将计算结果落地回Hive中。 整合需要注意的地方 1)需要引入hive的hive-site.xml,添加classpath目录下面即可,或者放到$SPARK_HOME/conf。 2)为了能够正常解析hive-site.xml中hdfs路径,