本文主要是介绍《RefineDNet: A Weakly Supervised Refinement Framework for Single Image Dehazing》论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《RefineDNet: A Weakly Supervised Refinement Framework for Single Image Dehazing》论文阅读
文章目录
- 《RefineDNet: A Weakly Supervised Refinement Framework for Single Image Dehazing》论文阅读
- 论文简介
- 摘要
- 介绍
- 本文主要贡献
- 提出的网络
- 框架整体
- 二阶框架
- 弱监督学习
- 去雾效果融合
- 网络结构
论文简介
意思:RefineDNet 一个弱监督的单一图像去雾改进框架
RefineDNet (Refinement Dehazing Network)
细化的去雾网络
论文期刊信息:
-
**2021年影响因子/JCR分区:**10.856/Q1
-
**是否TOP期刊:**是
-
大类学科及分区:
工程技术 1区 小类学科及分区:
COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE 计算机:人工智能 2区 ENGINEERING, ELECTRICAL & ELECTRONIC 工程:电子与电气 2区
摘要
图像去雾是很多计算机视觉任务中的先决条件,显得至关重要。基于先验的方法初步成功,但是其选择的先验条件并不总能适应环境;基于学习的方法可以得到更自然的结果,但是缺乏足够的训练样本,他们的去雾能力有限。本文将两种方法结合,将去雾任务分为两个步骤:可见度的恢复和真实性的提高。
nonetheless 但是
fusion n.融合
strategy n.策略
步骤:
- 在恢复能见度之前使用暗通道先验
- 细化前一阶段的初步脱模糊结果
- 提出一种有效的感知融合策略,就归纳不同的去雾结果
经过试验验证,具有感知策略的RefifineDNet具有不错的去雾效果,并且在视觉上有着令人满意的效果。
介绍
在雾霾条件下图像的可见性下降,使得许多计算机视觉任务如目标检测、识别难以进一步感知。
基于先验的方法依赖于一个被广泛应用的大气散射模型:
I ( x ) = J ( x ) t ( x ) + A ( 1 − t ( x ) ) I(x)=J(x)t(x)+A(1-t(x)) I(x)=J(x)t(x)+A(1−t(x))
其中x表示像素位置,I(x)表示模糊图像,J(x)表示清晰图像,A是某个常量。基于先验的方法可以产生机油较高可见性的去雾结果,局限性是其选择的先验参数难以适应任何环境。
基于学习的方法可以学习估计A和t(x),或者直接通过监督学习直接通过模糊图像恢复出J(x)。由于采用CNN可以产生很少伪影的图像,因此效果较佳。但是由于网络的训练数据集难以获取,不能批量收集;人工合成的图像与真实的图像存在一定的差距。上述局限性可能会使网络出现过拟合现象。
基于先验的方法在可见性的恢复相对较好,而基于学习的方法在提高结果的真实性方面较好。
本文主要贡献
- 提出了两阶段弱监督学习去雾网络,首先采用DCP(暗通道先验)恢复可见性,接着采用GANs提高图像的真实性。
- 提出新的感知策略去混合不同的去雾结果。
- 构建非配对户外数据集。
简介
-
基于暗通道先验的单幅图像去雾算法来自于何凯明博士2009年的CVPR论文:《Single Image Haze Removal Using Dark Channel Prior》,是那一年CVPR的最佳论文。他根据Dark Object Subtraction原理通过大量实验发现局部找最暗点进行均匀去雾有很好的效果。由此得到对于一个无雾图像,每个局部区域都很有可能有一些暗的地方,换言之,至少一个颜色通道会有很低的值、或黑色东西。
supervise v.监督
construct v.构建
blend v.混合
generative adj.有生产的
exploite v.运用;采用
variable n.变量
提出的网络
框架整体
框架整体图如下图所示:
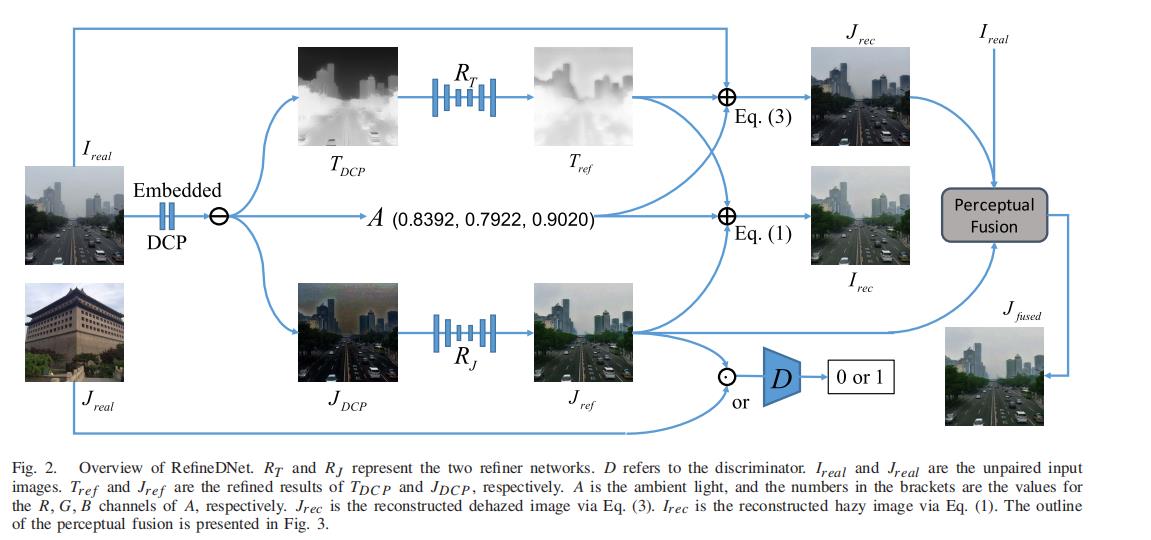
二阶框架
细化的去雾网络分为两个阶段。第一阶段使用DCP(暗通道先验),得到初步的A、去雾图像JDCP、透射图像TDCP。第二阶段TDCP被细化网络RT转换为Tref,JDCP被另一个细化网络RJ转换为Jref。
注:DCP被嵌入到了整个网络框架中,原始图像Ireal是RefineDNet的唯一输入。
弱监督学习
在训练过程为了确保Tref被合适的细化,根据科施米德定律(即Eq),使用Tref、Jref和A将模糊输入重构为Irec。然后最小化Ireal和Irec的距离更新细化器RT。 另外还有一个附加鉴别器D,用于接收预测图像Jref和清晰图像Jreal实现对抗学习,因此D在弱监督机制中起着最重要的作用。
去雾效果融合
虽然Jref是去雾的图像,但不适用于任何物理模型,因此需要通过施米德定律输出清晰的Jrec。转换公式如下:
J r e c ( x ) = I r e a l ( x ) − A T r e f ( x ) + A J_{rec}(x)=\frac{I_{real}(x)-A}{T_{ref}(x)}+A Jrec(x)=Tref(x)Ireal(x)−A+A
最后采用IQA特性来计算权值,融合Jref和Jrec作为最终的输出Jf。基于这些特征的IQA指标可以产生接近于人类感知的有效判断,因此我们将我们的融合策略称为感知融合。
网络结构
为了证明本文RefineDNet的主题而不是主干网络的有效性,采用了CycleGAN提供的基本主干网络来实现RT、RJ和D。具体来说,RT是一个U-Net,它包括8个下采样层和8个上采样卷积层。
这篇关于《RefineDNet: A Weakly Supervised Refinement Framework for Single Image Dehazing》论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







