本文主要是介绍Chiplet技术概览,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、概览
chiplet技术顺应了芯片生产与集成技术发展的趋势,也开拓了半导体技术发展的新的发展方向,将创造出一种新的芯片设计和商业模式
1.1 chiplet技术发展史
- 2015 年 Marvell 创始人周秀文博士在 2015 年国际固态电路会议 (ISSCC) 上提出模块化芯片概念。
- 2019 年 Intel发布了名为 Lakefield 的处理器,该处理器采用了chiplet架构,将 10 nm 制程的计算 Die 与 22 nm的输入/输出 (I/O) Die 通过 Intel 的 Foveros 技术封装在一起
- 2022 年 3 月,Intel 牵头并联合 9 家公司 (高通、ARM、AMD、台积电、日月光、三星、微软、谷歌云、META) 制定了通用芯粒互连技术 (UCIe) 标准
- 2022 年的 ISSCC 会议上,AMD 详细解读了通过 3D 封装实现 3D V-Cache 的技术
- 2022 年的 ISSCC 会议上,Intel发布了采用chiplet技术的芯片Ponte Vecchio,包含 5 类芯片,并由 47 个 Chiplets 组成:16 个 Xe-HPG 架构的计算芯片、8 个 Rambo Cache 芯片、2 个 Xe 基础芯片、11个嵌入式多芯片互连桥 (EMIB) 连接芯片、2 个 Xe Link I/O芯片和 8 个高带宽存储 (HBM) 芯片,这些小芯片通过Co-EMIB封装在一起
1.1.1 芯片生产与集成技术发展的趋势
(1)低半径高带宽的物理连线(bandwidth / memory wall)
封装技术的进步给高速总线带来带宽密度的提升、摩尔定律(工艺进步推动芯片性能的提升)
(2)数据搬运开销(power wall)
(3)更高晶体管集成度 (dark silicon)
(4)商业模式的进步
降低成本(设计模块化、异构集成)
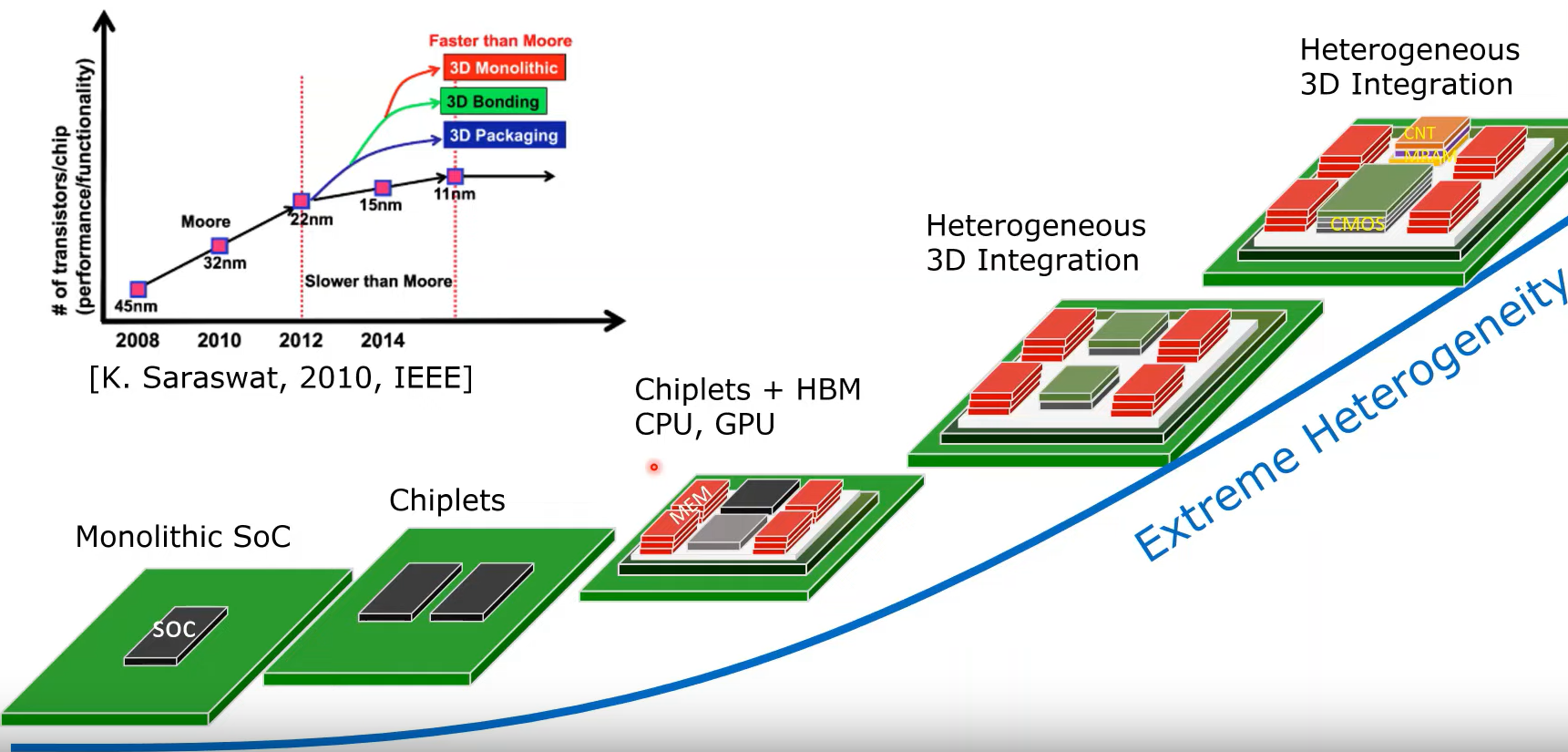
1.1.2 大模型技术助推chiplet技术的发展
人工智能技术是目前最火热的技术,也是半导体行业最炙手可热的新市场,作为其中的代表,大模型技术目前是影响力最大的技术。
其核心特点就是通过使用规模巨大(参数可达百亿到千亿数量级)的模型,并且在海量的数据上训练,来实现人工智能能力的突破,并且赋能新的应用。2022年下半年兴起的Chatgpt就是其典型的应用。而庞大的模型和海量的数据对运行平台,也就是计算芯片提出了新的要求,在摩尔定律逐渐失效的今天,通过多die互联来增加晶体管数量成为提升算力的选择。
数据互联成为chiplet芯片性能的关键
面对大模型的训练和部署的强大算力需求,数据互联变得越来越重要。原因如下:
- 训练和部署大模型需要使用分布式计算
单计算机几乎不可能提供运行大模型的足够算力,而分布式计算随着计算节点数量提升,理想情况下计算能力是随着计算节点数量线性提升,但是现实中由于不同计算节点间的数据交互需要额外的开销,因此只能接近而无法真正实现计算能力随着计算节点增加而线性增加。换句话说,随着模型规模越来越大,需要的分布式节点数量越来越多,对于这类分布式计算节点间的数据互联需求(带宽,延迟,成本等)也就越来越高,否则这类分布式计算中的数据互联将会成为整体计算中的效率瓶颈。 - 摩尔定律失效推动高级封装技术提升芯片性能
在摩尔定律逐渐失效的今天,通过多die互联来增加晶体管数量,从而扩大计算单元数,提升芯片整体算力。而多die互联需要将同构、异构的chiplet构建成高效的互联网络,并使用高带宽、低延迟的总线作为互联通道。
chiplet技术优势
1)成本优势
2)die的可复用性,敏捷开发优势
chiplet技术难点
chiplet技术虽然不是一个新的技术,但是在即将大规模应用的当下,仍然有很多工程技术问题要解决。
-
芯粒互连
-
芯片封装
先进封装是否足够可靠:
- 材料种类数量提升,材料物性不匹配
- 聚合物材料的引入恶化了先进封装的失效问题
-
供电和散热技术
集成规模的增大导致整个芯片功率的增大和供电难,散热成本和散热组件在整个计算系统中的体积占比高 -
测试验证
作为封装内的互联总线,无法像外封装一样通过测量仪器对芯片引出来的引脚进行信号质量检测
1.2 Chiplet关键技术
Chiplet 技术主要包含高速接口技术、先进封装技术、标准协议和生态建设。
1.2.1 NoC+NoP互联网络
如1.1.2节所述,数据互联已经成为使用chiplet搭建的人工智能加速芯片中的核心组件,这意味着要在monolithic die的基础上拆分小芯片,设计Multi-Die计算体系结构,并将同构、异构的chiplet进行interposer上互联,最终构建成高效的互联网络。
1.2.2 高速接口总线技术
如上所说,仅仅构建高效的互联网络是不够的,还需要高带宽、低延迟的高速接口总线作为互联通道。
高速接口技术就如同智慧大脑中的血管技术,为数据的传输提供保障,它的主要指标包括能效、功耗、带宽、时延,同时具有更复杂的通信协议需求。
对于技术指标,一方面随着chiplet数量越来越多,系统越来越复杂,势必chiplet之间的互连距离会越来越长,这也就意味着互联线上的衰减会更大,会需要更强的收发机;另一方面,随着大算力场景对于chiplet间数据通信带宽的要求提升,每个chiplet上的数据互联模块数量也会增加,这就意味着单个数据互联模块的功耗不能过大以满足总功耗的限制。另外,随着数据互联需求的快速提升,单个数据互联模块的芯片面积又不能太大,这样才能满足chiplet上总互联接口的需求。因此,chiplet数据互联电路主要有两大指标,一个是能效比(J/bit),用来衡量数据率与功耗之间的关系;另一个指标则是数据率密度(bit/s/mm),用来衡量数据率与芯片面积之间的关系。
对于通信协议,主要面向chiplet之间协同工作的方式,例如处理器系统中,如何确保chiplet之间缓存一致性的问题。
1.2.3 先进封装技术
先进封装是 Chiplet 的基石,它能使每个 Chiplet 小芯片连接在一起,从而构成整个系统级的芯片。
基于硅光子技术和共封装光学(co-packaged optics, CPO)的芯粒互联
CPO是将光芯片、电芯片等放置在一起进行3D封装的技术,该技术是长距离光通信数据互联的主要演进方向。
在硅光技术中,波导器件、光栅和调制器等核心模块都可以集成在同一块芯片上,从而可以大大降低光互联模块的成本。
同时,随着数据中心中的光互联带宽的需求进一步提升,功耗需求进一步降低,硅光子技术搭配共封装光学(co-packaged optics,CPO)也会成为下一代光互联带宽和功耗优化的核心技术。
1.2.4 芯粒测试技术
1.2.5 生态建设
生态建设决定了 Chiplet 技术的推广和应用,它需要上下游各方的共同努力,以便实现良性可持续发展
总线标准协议
而遵循某一指标框架的标准协议可确保每家的芯片都能组合到一起,有利于互联网协议 (IP) 的重复使用。
EDA工具生态
Chiplet模块的DFT、验证、可靠性与DFM,封装设计仿真
Synopsys有最新的3DIC Compiler,这也是行业内第一个完整的Chiplet设计平台,具备360o视角的3D视图,支持2.5D/3D封装设计和实现的自动化和可视化,同时面向供电、发热和噪声进行优化。
1.3 相关研究
综述
李应选. Chiplet的现状和需要解决的问题[J]. 微电子学与计算机, 2022, 39(5): 1-9. doi: 10.19304/J.ISSN1000-7180.2022.0036
封装技术
2.5D系统封装中高速I/O链路信号/电源完整性协同仿真. 固体电子学研究与进展
2.5 D/3D芯片-封装-系统协同仿真技术研究[J].电子与封装,2021
田飞飞;凌显宝;张君直;叶育红;蔡传涛;赵磊;陶洪琪;.晶圆级异构集成3D芯片互连技术研究[J].固体电子学研究与进展,2023,03:287
芯粒测试
基于FCM的芯粒测试电路设计与实现. 固体电子学研究与进展
Chiplet会议
HiPChips
High Performance Chiplet and Interconnect Architectures,2022年6月19日,第一届会议(连同第49界ISCA会议)于美国纽约举行。
参考链接:2022年第一届
Chiplet组织
- DARPA
- ODSA
开放计算项目(OCP, open compute project,由Facebook联合英特尔、Rackspace、高盛和Arista Networks在2011年联合发起的开源硬件组织,其使命是为实现可扩展的计算,提供高效的服务器,存储和数据中心硬件设计,以减少数据中心的环境影响)下的工作组。
- 工作宗旨
一方面帮助研究者了解关于数据密集型应用和ML/HPC驱动的chiplet设计架构的最新进展,另一方面为学术界和工业界的研究者提供先进技术的分享平台。 - 主要主题
- Chiplet-based accelerator level parallelism (ALP)
- Chiplet architecture for large scale system design
- Physical and logical inter-die interface design for heterogeneous architectures
- Coherent and non-coherent data sharing protocols via fast chiplet interconnection
- Chiplet architectures for in-memory computing and other emerging technologies
- ODSA-based 3D architecture for efficient ML acceleration
- Chiplet-based secure computing
- Power evaluation and performance modeling of chiplet architecture
- Software optimization framework with fast inter-chiplet network
- Chiplet topology aware ML optimizations
ODSA官方链接
1.4 chiplet产品案例
- 英特尔:英特尔的Xeon Scalable处理器、FPGA加速器和Ethernet网卡等产品中都使用了Chiplet技术。
Intel CPU概览和微架构分析
- Ponte Vecchio Xe-HPC GPU
16 compute die + 8 cache die + 2 base die + 8 HBM Die +2 IO die
采用EMIB+Foveros封装
第五代志强处理器Emerald Rapids
-
AMD:AMD的EPYC处理器和Radeon Instinct加速器等产品中也采用了UCIe技术。
参考链接:
AMD CPU微架构分析
从AMD CPU IO Die演进看高速接口IP发展趋势 -
Apple M1 UltraMax CPU
2 compute Die + 8 LPDDR5 die
InFO-L封装

-
Amazon: Graviton3 server GPU
1 compute die + 2 IO die + 4 DDR die + 2 IO die
substrate标准封装 -
Mellanox:Mellanox的InfiniBand和Ethernet互连解决方案中也采用了chiplet技术。
-
华为lego模式
二、芯粒互联技术
三、先进封装技术
Chiplet 技术发展的基础是先进封装。要将多颗芯片高效地整合起来,必须采用先进封装技术。在芯片尺寸不断增大、架构变得复杂的情况下,封装结构由原先的二维发展至三维。按封装介质材料和封装工艺划分,Chiplet 的实现方式主要包括以下几种:MCM、2.5D 封装、3D 封装。
3.1 MCM封装
MCM 封装是指通过引线键合、倒装芯片技术在有机基板上进行高密度连接的封装技术。
工艺较成熟,成本较低,一般用于 I/O 数目较少、对信号速率要求较低的情况
封装尺寸可以达到 110 mm×110 mm。但受限于基板加工工艺能力,目前封装基板上的走线宽度/间距一般为 9 μm/12 μm。为保证铜走线的工艺控制,在设计时信号走线的线宽大多在 12 μm 以上,布线密度比 2.5D 封装低。
3.2 2.5D封装
3.3 3D封装
3.4 共封装光学(co-packaged optics, CPO)
使用硅光子技术实现的光互联模块和使用传统CMOS技术实现的数字逻辑(例如光互联模块后接的网络模块)将会使用高级封装技术集成在同一个封装里——而在传统的实现中,光互联模块和其他CMOS芯片并不会集成在同一个封装里。
CPO是基于硅光技术之上的,因为传统的分立式光模块因为体积太大,无法使用共封装光技术和其他芯片集成到同一个封装里。
CPO缩小die间距,并减小功耗
通过使用共封装光学技术,光互联模块和其他芯片之间的互联距离大大缩小,从而减小了光互联模块与电信号接口的信号传输衰减,而这对于超高带宽通信至关重要,因为在这些超高数据率的应用中,真正限制数据率的往往不是光信号,而是光信号在转换成电信号之后的信号衰减(即last-mile问题)。另一方面,通过减小信号衰减,光互联模块的整体功耗可以减小。
四、高速接口技术
4.1 物理层接口形式
4.1.1 SerDes串行互联
传统的serdes架构,利用差分对信号进行高速传输,比较适合普通的基板封装(organic substrate)。
- 优势:
1)单lane数据传输率较高,带宽较高,目前以达到112GT/s、224GT/s
2)pin脚需求较小
3)功耗低
4)抗干扰强
5)速度快 - 劣势:
1)serdes架构,延迟较大
2)功耗较大
3)低密度route
根据发射端与接收端之间的距离,互连的 SerDes 技术可细分为长距 (LR) SerDes、 中 距 (MR) SerDes、 短距 (VSR)SerDes、极短 (XSR) SerDes 和超短距 (USR) SerDes。
长距SerDes
其中,LR/MR/VSR SerDes 的相关技术已经较为成熟,应用比较广泛,封装成本也较低,但缺点是功耗和信号的延迟比较大。
XSR SerDes
XSR 的光网络论坛-通用电气接口规范 (OIF-CEI 4.0)是专门针对 Die 之间互连的,并向着 100 Gbit/s 的方向发展。相较于 LR Serdes,XSR Serdes 具有功耗低、面积小、通信协议灵活的特点 。
USR SerDes
USR SerDes 通过信号增强可进一步降低SerDes 的功耗。封装产品可以根据不同项目产品的需求选择合适的 SerDes 类型,以实现成本与带宽的平衡。
4.1.2 并行接口
在串行互连的基础上,各大公司技术联盟提出了基于并行数据传输的物理层互连技术,这种技术采用单端信号传输,forward clock,适合线距较短的先进封装使用。AIB、HBM、Open-HBI、LIpincon、BOW、UCIe属于这种接口。
- 优势:
1)高密度route,整体布局较紧凑
2)低延时
3)低功耗 - 劣势:
1)为保证多组IO引脚之间延迟移植,数据传输率难以做高
2)IO数量多
4.2 物理层信号调制技术
NRZ
Non-Return-to-Zero,即不归零编码。使用两个信号电平来表示数字逻辑信号0/1信息的调制技术,负电平代表0,正电平代表1,波特率和比特率相同。不归零是指每传输完1比特,信号无需返回到零电平,这样可节约数据带宽。
CNRZ
PAM4
4-Level Pulse Amplitude Modulation,4电平脉冲幅度调制,使用四个信号电平来进行信号传输。每个符号周期代表2位逻辑信息。波形有四种电平(1000/0100/0010/0001),分别代表00、01、10、11,即波特率是比特率的一半。
相同码率(比特率)下,PAM4的波特率是NRZ的一半,因此PAM4信令中传输相同数量的符号造成的信号损耗大大降低。
PAM4 的眼高是 NRZ 的 1/3,导致 PAM4 将 SNR(信噪比)提高 -9.54 dB(链路预算惩罚),这会影响信号质量并引入额外的高速信号的限制,垂直眼图开度小也导致PAM4的BER更高,但是前向纠错(FEC)可以改善该问题。
4.3 总线数据传输特征
多个chiplet之间需要通过数据传输协议进行数据传输,而该协议可分为一致性协议和非一致性协议。
一致性数据传输
维护一致性的代价和设计的物理面积成正比,因为面积越大,延迟也会越大。常用的一致性数据传输协议有CCIX、CXL、Tilelink、OpenCAPI等。
非一致性数据传输
非一致性协议相比一致性协议,延迟更容易控制,例如Tensorflow就是一款使用非一致性数据传输的加速器。
非一致性数据传输可以通过两种方式实现:
-
一种是将die内互联向die外互联扩展,但大多数die内互联都使用同步总线,向die外扩展不是很容易;
-
另一种是使用在die外互联中使用非一致性数据传输协议,如PCIe。
Netronome已经开发出一款轻量级的可变数据结构和协议用于chiplet间的数据传输。
五、生态建设
5.1 接口标准协议
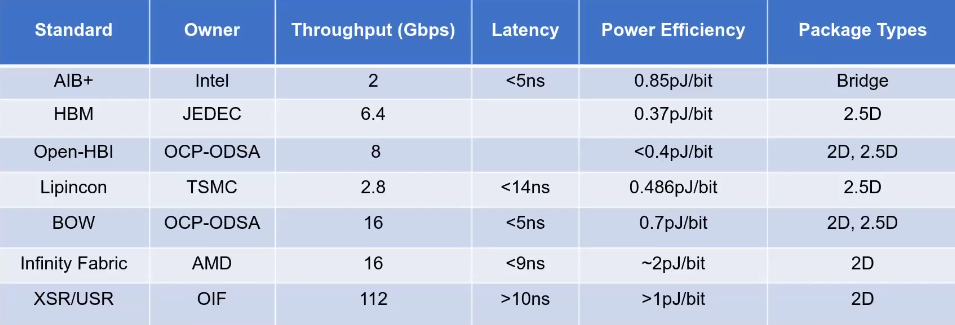
当前主流的标准协议
如图(图片来源于奎芯科技直播课)是已有的一些chiplet标准协议,当前这些技术针对物理层有明确的规范要求,对协议层定义较模糊,需要定制化地对现有协议作配置
- UCIe
UCIe 是 Intel 主推的一个开放的、多协议兼容的、可满足不同客户对定制封装内多 Die 互连需求的技术标准。UCIe 可同时支持 2.5D、3D 封装技术,例如 MCM、晶圆级封装 (CoWoS)、EMIB 等。
协议解读参考链接:
参考链接:UCIe技术——概览索引
- AIB
intel在2019开源的die-to-die互联协议,后移交给chipalliance维护
参考链接:github——aib-phy-hardware
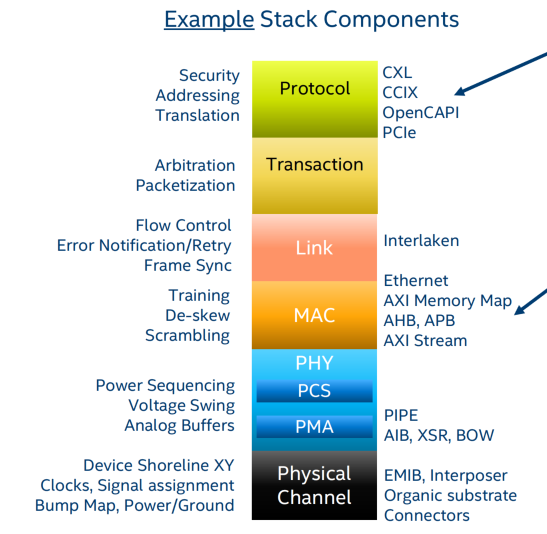
EDA工具链
这篇关于Chiplet技术概览的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






