本文主要是介绍现代数据堆栈MDS有什么现代之处,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Dazdata MDS
现代数据堆栈(MDS)已经普及了几年,但直到最近才在其定义上趋同。在我们深入探讨MDS的哲学和技术指标之前,让我们先谈谈传统数据堆栈的失败。
为什么MDS越来越受欢迎?
原因很简单,传统数据堆栈 (TDS) 无法满足任何现代组织的数据需求。为了保持竞争优势,组织需要能够在正确的时间采取行动的数据,并且足够灵活地适应变化。TDS通常是指逻辑耦合且复杂的本地Hadoop(生态系统)和SQL仓库。
在我们深入研究什么是现代数据堆栈(MDS)之前,让我们首先看一下仍在使用 TDS 的组织面临的一些问题。
典型的 TDS 设置会导致三个主要问题
1. 解开和建立基础设施的周转时间长
使用本地基础设施的公司负责与之相关的所有成本,例如保持一切维护和平稳运行所需的工程师大军。
由于设置是如此紧密地相互关联,看似微小的更改可能会破坏系统的其他部分。在对现有环境进行任何改进之前,找到系统之间的确切逻辑耦合需要大量的工作时间进行分析。
2. 对新信息反应迟钝
随着公司的发展,其数据和计算能力需求也在增加。在横向扩展(扩展)本地基础结构时,在资源和时间方面非常昂贵。
由于本地基础结构难以扩展,这自然会导致分析数据的计算能力受到限制。数据管道可能需要数小时才能完成,随着组织的发展,这个问题变得更加复杂。
TDS 需要缓慢的 ETL(提取、转换、加载)操作,然后新引入的数据才能符合数据模型的其余部分。新的数据更新可能需要数周和数小时的重构才能显示见解。当数据准备就绪时,组织无法及时采取行动,导致错失机会。
3. 昂贵的洞察之旅
许多报告生成都是手动完成的,尤其是当数据来自不同来源时。报告是手动生成的,手动清理,然后手动传输到Excel(喘气!这会导致出错、占用其他业务关键型任务的时间以及无法扩展。
由于环境复杂,分析师无法有效地履行其职责。数据工程师被拉入操作查询,阻止他们完成实际工作(例如使数据管道更具可扩展性!
看到业务环境的竞争激烈以及快速适应新信息的需求,很明显,传统的数据堆栈并不是理想的解决方案。这就是现代数据堆栈的用武之地,可帮助您的企业保持竞争力。
现代数据堆栈有哪些优势?
1. 从以 IT 为中心 IT 转向以业务为中心的运营模式
借助 MDS,您的组织可以重新获得专注于业务方面的自由,而不是陷入与 IT 相关的困境。
您的组织可以拥有更精简的数据团队,并且可以专注于更高价值的数据任务,而不是浪费时间进行传统数据堆栈的管理和性能优化。
MDS提供的工具在设计时考虑了更大的可访问性(无代码或需要很少的代码),大大降低了进入的技术门槛。
MDS 将自助服务视为核心功能,减少了对数据专业人员的依赖。这意味着CMO可以自己提取活动分析,并将数据团队视为推动者而不是瓶颈。
2. 即插即用的灵活性取代了长期承诺
由于基础设施不再在本地部署并部署在云中,因此公司不再需要担心硬件/平台维护及其相关成本(从而节省大量成本)。
存储和计算随时可用,通过云提供商的弹性缩短数据处理响应时间。
现代数据堆栈利用软件即服务平台 (SaaS),创建开箱即用的工具。这意味着您的团队可以在最低的设置要求下开始工作。(因此,我们使用现代数据堆栈作为每个新的DataOps / MLOps工具口号)
3. 从一次性分析转向运营 BI 和 AI
现代数据堆栈的设置和迭代速度要快得多,无需大型 IT 团队。这使得非科技公司可以在几个小时内开始产生可操作的见解,而不是通常的几天或几周。
数据可以来自各种第一方和第三方来源。现代数据堆栈可以将所有这些源集成到其数据摄取工具中,而数据摄取工具又将与商业智能工具配合使用。
4. 将数据治理视为一等公民
我们会在可以更早发现和缓解问题的地方进行处理。
MDS 供应商提供的工具可实现更好的数据质量、隐私控制和访问治理。随着网络安全威胁、负责任的 AI 以及数据法规的增加,在没有考虑数据治理的情况下构建的系统是每个 CIO 的噩梦。未能保护数据可能会给组织带来灾难性后果。
虽然保护整个堆栈仍然是一个挑战,但 MDS 技术提供商不会将数据治理视为事后的想法。这导致数据治理成为整个堆栈流程的一部分。
那么现代数据堆栈是什么?
很简单,现代数据堆栈 (MDS) 是一组托管在云中的工具,使组织能够实现高效的数据集成。我们相信 MDS 是 DataOps 和 MLOps 的基础。
MDS 创建干净、可信且始终可用的数据,使业务用户能够进行自助发现,从而实现真正的数据驱动型文化。
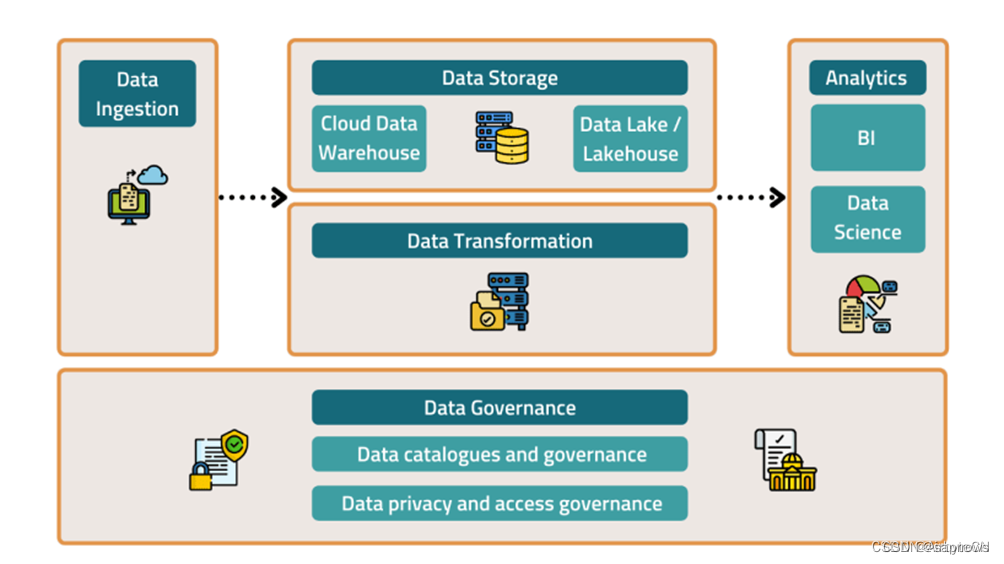
MDS 的组成部分是什么?
MDS由多层堆叠而成(如蛋糕),每层都有自己的功能。
1. 数据摄取
这是将数据从各种来源(数据库、服务器日志、第三方应用程序等)传输到存储介质的地方。
示例工具:Fivetran、Airbyte
2. 数据存储
数据仓库或数据湖(或湖仓!)是一种(通常基于云的)解决方案,用于存储从数据引入工具发送的所有收集的数据。在这里可以访问和分析数据。
示例工具:Snowflake,Databricks,Delta Lake
3. 数据转换
一旦原始数据被移动到存储中,就需要将其转换为用户友好的数据模型。这使分析师或数据科学家可以轻松查询数据以提取见解、构建仪表板甚至 ML 模型。
示例工具:EasyMorph、Airflow、DBT
4. 数据分析/商业智能
在这里分析数据并创建仪表板供用户浏览数据。现代数据分析工具的设计也考虑到了非技术用户。这使领域专家能够回答业务问题,而无需依赖开发人员和分析师。
示例工具:Looker、Power BI、ThoughtSpot
5. 数据治理
数据目录和治理
允许组织跟踪和理解其数据,这有助于数据可发现性、质量和共享。如果没有这些工具,数据湖很容易成为数据沼泽。
数据隐私和访问治理
这些工具可帮助组织在数据保护方面保持合法合规。敏感数据泄露等问题可以得到缓解。
示例工具:Atlan、Immuta、Informatica
我需要所有这些不同的组件吗?
好消息是,不,您不需要所有这些功能即可运行!MDS设置类似于订购食物,您可以按照当时需求的方式进行设置。例如,您可以订购蛋糕但保留奶油。需要注意的重要一点是,尽管没有任何奶油,但最终结果是你仍然有一个可以吃的蛋糕。
MDS 设置是模块化的,旨在与其他组件和工具兼容(即插即用)。这意味着您可以根据组织的要求切换组件。您还可以自定义设置以使用现有基础结构,而不是完全弃用它。
这种模块化(相对于单片)的另一个优点是,您可以水平旋转组件并避免供应商锁定。不喜欢供应商为数据存储层提供的特定工具?换成更适合您需求的其他供应商。如果组织很年轻,它很可能不需要一次所有组件,因为它的需求更简单。随着组织的发展,它可以根据需要切换或添加更多组件。
不同 MDS 设置的示例
并非所有组织都是一样的,也不是所有组织都是一刀切的。以下是不同类型的组织可以在其 MDS 中使用的工具示例。
1. 同时满足商业智能和数据科学要求的企业 MDS
EventHub + Delta Lake + Databricks + PowerBI
由于许多组织都订阅了Microsoft 365,因此PowerBI是一个自然的选择,因为它包含在企业订阅中。随着对实时报告的需求变得越来越占主导地位,将结构化流式处理与 PowerBI 相结合可以无缝集成到现有分析体系结构中。
2. 具有混合/多云雄心的中型分析团队
FiveTran+SnowFlake+Looker
中小企业有不同程度的需求,倾向于混合和匹配工具和云提供商。Snowflake 是一个合适的选择,因为它与云无关,并且与大多数 ETL 工具兼容。与 Azure 解决方案相比,列出的工具价格昂贵。
3. 数据驱动的启动
AirByte + DBT + Big Query + Metabase
初创企业的团队规模较小,基础设施需求更简单,因此工具需要既经济高效又易于使用。例如,Metabase是一个可视化工具,不需要SQL知识来构建,也不需要BI专家的帮助来使用。
设置 MDS 有多难?
对于开始全新领域的组织来说,这可能非常简单,因为主要的云提供商提供MDS模板(re。AWS湖形成)。但对于拥有现有传统数据堆栈的组织来说,这并不像将所有内容迁移到云那么简单。
如果要从现有的成熟数据堆栈迁移到云,仔细的重新架构将至关重要。如果新的云基础结构是以耦合的整体方式设置的(将一堆本地虚拟机移动到云中),则只会浪费时间。
下一节概述了设置新 MDS 时要注意的重要事项。
使用 MDS 时需要注意的事项
我们必须记住,MDS不仅适用于专业数据科学家,也适用于任何想要处理数据的人。由于MDS在设计上是模块化的,因此许多组织倾向于找到所有最佳工具并将它们集成在一起。问题解决了,对吧?
这种方法的问题在于,MDS 现在是围绕工具构建的,而不是为用户构建的。虽然从建筑和工程的角度来看这很好,但它会进入最常见的故障模式:糟糕且令人沮丧的用户体验。
首次实施 MDS 时,通常的方法是查看组织需要什么并相应地购买工具(仪表板、分析等)。不幸的是,这形成了一个 MDS,它是一个脱节的花哨工具集合;与用于解决问题的协作堆栈相去甚远。
用户体验不佳的MDS将导致一个设计精美的数据平台,他们试图支持的分析师和科学家的采用率为零。
好的MDS和坏的MDS有什么区别?
这一切都归结为一个简单的概念:用户体验。仅仅因为一个组织拥有最好和最昂贵的工具并不能保证和谐。这些工具的用户应该能够完成工作,而不会觉得他们在打一场艰苦的战斗。从本质上讲,组织应该构建一个围绕最适合其用户的内容设计的 MDS。
最终,这一切都归结为用户体验。设计新式数据堆栈时,请牢记用户的需求和痛点:
善解人意和包容
MDS 需要对所有用户可用且具有包容性。
允许用户培养对数据的信任并鼓励协作。
使用户能够执行他们应该执行的作业(不要强迫分析师编写复杂的转换)。
周密的计划;简单开始
MDS 不需要具有所有组件即可运行。
规划组织当时需要的组件,以避免不必要的成本和复杂性。
简单地说,具有引入、转换和存储的简单设置仍然是有效的 MDS。
相应地展开并添加组件。
寻找合适的合作伙伴
每个组织都是不同的,这意味着没有一刀切的解决方案。您不能只采用与另一个组织相同的设置并期望它正常工作。
因此,不要羞于与供应商联系,以帮助您设计适合您组织的 MDS。您甚至可以请求演示。
有许多公司专门帮助组织构建和设置适合其环境的现代数据堆栈 - 无论是初创企业还是大型企业。与人交谈,阅读内容,并加入 Slack 社区的阵列。
在哪里可以找到有关 MDS 的更多信息?
这是一个大规模爆炸的景观,并且每天都在不断发展!以下是一些快速了解现代数据堆栈的资源:
Modern Data Stack | Andrew Ermogenous | Substack
The Data Exchange — Data ∪ Machine Learning ∪ AI
The Beginner’s Guide to the Modern Data Stack | by Prukalpa | Towards Data Science
结论
第二次世界大战后,汽车制造商努力降低生产成本,并在生产过程中遇到了许多障碍,损害了他们的利润。后来,丰田创建了准时制(JIT)生产系统,该系统消除了大部分问题,并在不影响质量的情况下提高了效率。不久之后,其他制造商意识到了这些好处并采用了类似的方法。
回到科技行业,组织意识到数据变得越来越复杂,他们的传统数据堆栈根本无法应对。现代数据堆栈是一种解决方案,可以帮助组织节省时间、精力和金钱。与传统数据堆栈相比,它更快、更具可扩展性且更易于访问。MDS 还可帮助组织过渡到现代数据驱动型组织,这对于创建业务解决方案至关重要。在当今时代,没有可操作的数据,任何组织都无法保持竞争力。
仅这些好处就足以让任何组织认真重新评估其当前系统。但是,重要的是不要赶上技术嗡嗡声,为了现代化而进行现代化改造。要真正从 MDS 中受益,需要仔细规划以实现良好的用户体验。设计一个好的MDS,让你的员工做他们的工作,回报将是无价的。
这篇关于现代数据堆栈MDS有什么现代之处的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









