本文主要是介绍【AI达人特训营第三期】基于PaddleClas的苹果品牌Logo识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
【赛题题目】
苹果品牌Logo识别
【赛题背景】
logo是徽标或者商标的英文说法,起到对商标拥有公司的识别和推广的作用,形象的logo可以让消费者记住公司主体和品牌文化,logo对于品牌来说非常重要,是品牌价值的重要组成部分。如果要盘点世界上最有价值的logo的话,苹果的logo肯定要位列其中。
苹果最初的Logo在1976年由创始人三人之一韦恩设计,只在生产Apple-I时使用,为牛顿坐在苹果树下看书的钢笔绘画。在1976年由乔布斯决定重新委托广告设计,并配合Apple-2的发行使用,本次Logo确定使用了彩虹色、具有一个缺口的苹果图像。
这个Logo一直使用至1998年,在iMac发布时作出修改,变更为单色系列。2007年再次变更为金属带有阴影的银灰色。事实上,该品牌最近又恢复了2000年的标识,这表明如果标识足够强大,用户仍然会认出来。

【赛题描述】
本赛题要求选手研究开发高效可靠的深度学习算法,准确识别图片中是否包含品牌logo,提升图像智能分类的准确度与效率。
【赛题任务】
允许选手下载赛题数据,设计算法并在本地完成模型训练,输出结果要求标出图片是否含苹果Logo,是则标记为1,否则标记为0;
【赛题数据】
本赛题将会提供近千张的从互联网收集的图片,图片为jpg格式,图片示例如下:
本赛题已将数据集合理划分为训练集和测试集,隐藏测试标注数据作为模型测评依据。训练集用来给选手训练模型,含苹果Logo图片269张,不含苹果Logo图片519张。
a) 我们将提供用于训练的图片和分类标签、测试图片以及提交示例文件,文件夹结构如下:
work/data/
├── test
├── train
└── 提交示例文件.csv
b) 其中,train文件夹存放训练集图像数据,test文件夹存放测试集图像数据,图片均为jpg格式。train文件夹结构如下:
work/data/train/
├── logo
└── without_logo
c) train训练集图像数据文件夹中,logo文件夹存放有苹果Logo的训练图片,without_logo存放没有苹果Logo的训练图片。
d) csv: 只包含测试集图片id的结果文件示例。
【提交说明】
本赛题要求选手通过使用主办方提供的数据,训练算法来预测测试集中的图片是否含苹果Logo,图片ID和标注结果一一对应生成csv文件提交评测。
提交文件示例(result.csv):
注:为避免评测过程中文编码格式导致评测错误的影响,请统一以utf-8编码,result.csv中第一列是图片的唯一标记,第二列是对应的标注。并且注意不要包含表头,标注结果只能是0或1:0表示图片中不含苹果Logo,1表示图片中含有苹果Logo。
【评估指标】
赛题分数计算方式:准确率ACC
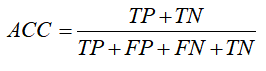
# 持久化安装,只需运行一次
!mkdir /home/aistudio/external-libraries
!pip install paddlex==2.1.0 -t /home/aistudio/external-libraries
!pip install paddleclas==2.4.0 -t /home/aistudio/external-libraries
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
import sys
sys.path.append('/home/aistudio/external-libraries')
一、数据准备
1.1 数据集格式说明
PaddleClas 使用 txt 格式文件指定训练集和测试集,即需要指定 train_list.txt 和 val_list.txt 当作训练集和验证集的数据标签,格式形如:
# 每一行采用"空格"分隔图像路径与标注
train/1.jpg 0
train/10.jpg 1
...
如果您想获取更多常用分类数据集的信息,可以参考文档可以参考 PaddleClas 分类数据集格式说明 。
1.2 标注文件生成
如果您已经有实际场景中的数据,那么按照上节的格式进行标注即可。这里,我们提供了一个快速生成数据的脚本,您只需要将不同类别的数据分别放在文件夹中,运行脚本即可生成标注文件。
首先,假设您存放数据的路径为./train,train/ 中包含了每个类别的数据,类别号从 0 开始,每个类别的文件夹中有具体的图像数据。
train
├── 0
│ ├── 0.jpg
│ ├── 1.jpg
│ └── ...
└── 1├── 0.jpg├── 1.jpg└── ...
└── ...
# %cd /home/aistudio/work/data
# # 从train文件夹中筛选出所有的图片文件,并把它们的完整路径和所属类别输出到train_list.txt文件中。
# # tree -r -i -f train 是指使用tree程序以反向、无缩进、全路径的方式列出train文件夹下的所有文件。
# # | 是指管道符,表示把前一个程序的输出作为后一个程序的输入。
# # grep -E “jpg|JPG|jpeg|JPEG|png|PNG” 是指使用grep程序根据正则表达式匹配所有以jpg、JPG、jpeg、JPEG、png或PNG结尾的文件。
# # awk -F “/” ‘{print $0" "$2}’ > train_list.txt 是指使用awk程序按照"/"分隔每一行,并打印每一行的全部内容($0)和第二个字段($2),即图片所属类别,然后重定向输出到train_list.txt文件中。# !tree -r -i -f train | grep -E "jpg|JPG|jpeg|JPEG|png|PNG" | awk -F "/" '{print $0" "$2}' > train_list.txt
1.3 切分训练集和验证集
# 关掉警告信息
import warnings
warnings.filterwarnings("ignore")# 将数据集以按8:2切分为训练集和验证集
!paddlex --split_dataset --format ImageNet --dataset_dir /home/aistudio/work/data/data --val_value 0.2
二、模型训练
修改 SwinTransformer_base_patch4_window12_384.yaml 中数据集路径的配置文件
# global configs
Global:checkpoints: 10pretrained_model: https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/SwinTransformer_base_patch4_window12_384_22kto1k_pretrained.pdparams# model architecture
Arch:name: SwinTransformer_base_patch4_window12_384class_num: 2Optimizer:lr:# for 1 cardslearning_rate: 1.25e-4warmup_start_lr: 2.5e-7# data loader for train and eval
DataLoader:Train:dataset:name: ImageNetDatasetimage_root: /home/aistudio/work/data/data/cls_label_path: /home/aistudio/work/data/data/train_list.txtsampler:batch_size: 16Eval:dataset: name: ImageNetDatasetimage_root: /home/aistudio/work/data/data/cls_label_path: /home/aistudio/work/data/data/val_list.txtsampler:batch_size: 16Infer:infer_imgs: /home/aistudio/work/data/testbatch_size: 16PostProcess:class_id_map_file: /home/aistudio/work/data/data/labels.txt# 直接使用 SwinTransformer_base_patch4_window12_384.yaml 训练的命令为:
%cd /home/aistudio/work/PaddleClas-2.4.0
!export CUDA_VISIBLE_DEVICES=0
!python3 tools/train.py \-c ./ppcls/configs/ImageNet/SwinTransformer/SwinTransformer_base_patch4_window12_384.yaml
三、模型评估
训练好模型之后,可以通过以下命令实现对模型指标的评估。
其中 -o Global.pretrained_model="output/SwinTransformer_base_patch4_window12_384/best_model" 指定了当前最佳权重所在的路径,如果指定其他权重,只需替换对应的路径即可。
%cd /home/aistudio/work/PaddleClas-2.4.0
!python3 tools/eval.py \-c ppcls/configs/ImageNet/SwinTransformer/SwinTransformer_base_patch4_window12_384.yaml \-o Global.pretrained_model=output/SwinTransformer_base_patch4_window12_384/best_model# [Eval][Epoch 0][Iter: 0/10]CELoss: 0.47169, loss: 0.47169, top1: 0.68750, batch_cost: 3.13238s, reader_cost: 1.29282, ips: 5.10793 images/sec
# [Eval][Epoch 0][Avg]CELoss: 0.27567, loss: 0.27567, top1: 0.89744
四、模型预测
模型训练完成之后,可以加载训练得到的预训练模型,进行模型预测。在模型库的 tools/infer.py 中提供了完整的示例,只需执行下述命令即可完成模型预测:
备注:
-
这里
-o Global.pretrained_model="output/SwinTransformer_base_patch4_window12_384/best_model"指定了当前最佳权重所在的路径,如果指定其他权重,只需替换对应的路径即可。 -
默认是对
/home/aistudio/work/data/test进行预测,此处也可以通过增加字段-o Infer.infer_imgs=xxx对其他图片预测。 -
默认输出的是 Top-5 的值,如果希望输出 Top-k 的值,可以指定
-o Infer.PostProcess.topk=k,其中,k为您指定的值。
修改 /home/aistudio/work/PaddleClas-2.4.0/ppcls/engine/engine.py 中的推理代码 infer(self)
@paddle.no_grad()def infer(self):assert self.mode == "infer" and self.eval_mode == "classification"total_trainer = dist.get_world_size()local_rank = dist.get_rank()image_list = get_image_list(self.config["Infer"]["infer_imgs"])# data splitimage_list = image_list[local_rank::total_trainer]batch_size = self.config["Infer"]["batch_size"]self.model.eval()batch_data = []image_file_list = []csvfile = open("/home/aistudio/work/data/result.csv", "a", newline="")writer = csv.writer(csvfile)for idx, image_file in enumerate(image_list):with open(image_file, 'rb') as f:x = f.read()for process in self.preprocess_func:x = process(x)batch_data.append(x)image_file_list.append(image_file)if len(batch_data) >= batch_size or idx == len(image_list) - 1:batch_tensor = paddle.to_tensor(batch_data)if self.amp and self.amp_eval:with paddle.amp.auto_cast(custom_black_list={"flatten_contiguous_range", "greater_than"},level=self.amp_level):out = self.model(batch_tensor)else:out = self.model(batch_tensor)if isinstance(out, list):out = out[0]if isinstance(out, dict) and "Student" in out:out = out["Student"]if isinstance(out, dict) and "logits" in out:out = out["logits"]if isinstance(out, dict) and "output" in out:out = out["output"]result = self.postprocess_func(out, image_file_list)for res in result:file_name = res['file_name'].split('/')[-1]class_id = res['class_ids'][0]writer.writerow([file_name, class_id])batch_data.clear()image_file_list.clear()csvfile.close()
%cd /home/aistudio/work/PaddleClas-2.4.0/
!python3 tools/infer.py \-c ppcls/configs/ImageNet/SwinTransformer/SwinTransformer_base_patch4_window12_384.yaml \-o Global.pretrained_model=output/SwinTransformer_base_patch4_window12_384/best_model
将推理保存的 /home/aistudio/work/data/result.csv 文件在比赛苹果品牌Logo识别进行提交
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
这篇关于【AI达人特训营第三期】基于PaddleClas的苹果品牌Logo识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









