本文主要是介绍【正点原子STM32连载】第五十一章 汉字显示实验 摘自【正点原子】STM32F103 战舰开发指南V1.2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1)实验平台:正点原子stm32f103战舰开发板V4
2)平台购买地址:https://detail.tmall.com/item.htm?id=609294757420
3)全套实验源码+手册+视频下载地址: http://www.openedv.com/thread-340252-1-1.html#
第五十一章 汉字显示实验
本章,我们将介绍如何使用STM32控制LCD显示汉字。在本章中,我们将使用外部SPI FLASH来存储字库,并可以通过SD卡更新字库。STM32读取存在SPI FLASH里面的字库,然后将汉字显示在LCD上面。
本章分为如下几个小节:
51.1 汉字显示介绍
51.2 硬件设计
51.3 程序设计
51.4 下载验证
51.1 汉字显示原理简介
汉字的显示和ASCII显示其实是一样的原理,如图51.1.1所示:
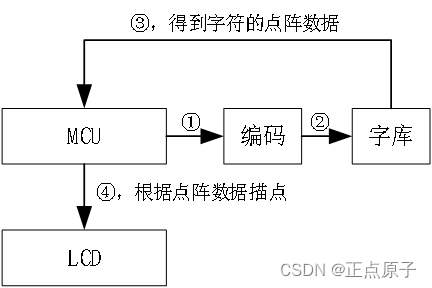
图51.1.1 单个汉字显示原理框图
上图显示了单个汉字显示的原理框图,单片机(MCU)先根据汉字编码(①,②)从字库里面找到该汉字的点阵数据(③),然后通过描点函数,按字库取模方式,将点阵数据在LCD上画出来(④),就可以实现一个汉字的显示。
接下来,重点介绍一下汉字的:编码、字库及显示等相关知识。
51.1.1 字符编码介绍
单片机只能识别0和1,所有信息都是以0和1的形式存储的,单片机本身并不能识别字符,所以我们需要对字符进行编码(也叫内码,特定的编码对应特定的字符),单片机通过编码来识别具体的汉字。常见的字符集编码如表:51.1.1.1所示:
字符集 编码长度 说明
ASCII 1个字节 拉丁字母编码,仅128个编码,最简单
GB2312 2个字节 简体中文字符编码,包含约6000多汉字编码
GBK 2个字节 对GB2312的扩充,支持繁体中文,约2W多汉字编码
BIG5 2个字节 繁体中文字符编码,在台湾、香港用的多
UNICODE 一般2个字节 国际标准编码,支持各国文字
表51.1.1.1 常见字符集编码
其中ASCII编码最简单,采用单字节编码,在前面的OLED和LCD实验,我们已经有所接触。ASCII是基于拉丁字母的一套电脑编码系统,仅包括128个编码,其中95个显示字符,使用一个字节即可编码完所有字符,我们常见的英文字母和数字,就是使用ASCII字符编码,另外ASCII字符显示所占宽度为汉字宽度的一半!也可以理解成:ASCII字符的宽度 = 高度的一半。
GB2312、GBK和BIG5都是汉字编码,GBK码是GB2312的扩充,是国内计算机系统默认的汉字编码,而BIG5则是繁体汉字字符集编码,在香港和台湾的计算机系统汉字编码一般默认使用BIG5编码。一般来说,汉字显示所占的宽度等于高度,即宽度和高度相等。
UNICODE是国际标准编码,支持各国文字,一般是2字节编码(也可以是3字节),这里不做讨论。想详细了解的可以执行百度学习。
接下来,我们重点介绍一下GBK编码。
GBK是一套汉字编码规则,采用双字节编码,共23940个码位,收录汉字和图形符号21886个,其中汉字(含繁体字和构件)21003个,图形符号883个。
每个GBK码由2个字节组成,第一个字节范围:0X810XFE,第二个字节分为两部分,一是:0X400X7E,二是:0X80~0XFE。其中与GB2312相同的区域,字完全相同。GBK编码规则如表51.1.1.2所示:
字节 范围 说明
第一字节(高) 0X81~0XFE 共126个区(不包括0X00~0X80,以及0XFF)
第二字节(低) 0X40~0X7E 63个编码(不包括0X00~0X39,以及0X7F)
0X80~0XFE 127个编码(不包括0XFF)
表51.1.1.2 GBK编码规则
我们把第一个字节(高字节)代表的意义称为区,那么GBK里面总共有126个区(0XFE - 0X81 + 1),每个区内有190个汉字(0XFE - 0X80 + 0X7E - 0X40 + 2),总共就有126190=23940个汉字。
第一个编码:0X8140,对应汉字:丂;
第二个编码:0X8141,对应汉字:丄;
第三个编码:0X8142,对应汉字:丅;
第四个编码:0X8143,对应汉字:丆;
依次对所有汉字进行编码,详见:www.qqxiuzi.cn/zh/hanzi-gbk-bianma.php。
51.1.2 汉字字库简介
光有汉字编码,单片机还是无法在LCD上显示这个汉字的,必须有对应汉字编码的点阵数据,才可以通过描点的方式,将汉字显示在LCD上。所有汉字点阵数据的集合,就叫做汉字字库。而不同大小的汉字,其字库大小也不一样,因此又有不同大小汉字的字库(如:1212汉字字库、1616汉字字库、2424汉字字库等)。
单个汉字的点阵数据,也称之为字模。汉字在液晶上的显示其实就是一些点的显示与不显示,这就相当于我们的笔一样,有笔经过的地方就画出来,没经过的地方就不画。为了方便取模和描点,我们一般规定一个取模方向,当取模和描点都按取模方向来操作,就可以实现一个汉字的点阵数据提取和显示。
以12*12大小的“好”字为例,假设我们规定取模方向为:从上到下,从左到右,且高位在前,则其取模原理如图51.1.2.1所示:
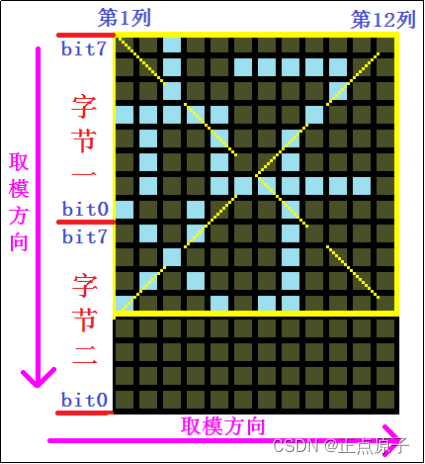
图51.1.2.1 从上到下,从左到右取模原理
图中,我们取模的时候,从最左上方的点开始取(从上到下,从左到右),且高位在前(bit7在表示第一个位),那么:
第一个字节是:0X11(1,表示浅蓝色的点,即要画出来的点,0则表示不要画出来);
第二个字节是:0X10;
第三个字节是:0X1E(到第二列了,每列2个字节);
第四个字节是:0XA0;
以此类推,共12列,每列2个字节,总共24字节,1212“好”字完整的字模如下:
uint8_t hzm_1212[24]={
0x11,0x10,0x1E,0xA0,0xF0,0x40,0x11,0xA0,0x1E,0x10,0x42,0x00,
0x42,0x10,0x4F,0xF0,0x52,0x00,0x62,0x00,0x02,0x00,0x00,0x00}; / 好字字模 /
在显示的时候,我们只需要读取这个汉字的点阵数据(1212字体,一个汉字的点阵数据为24个字节),然后将这些数据,按取模方式,反向解析出来(坐标要处理好),每个字节,是1的位,就画出来,不是1的位,就忽略,这样,就可以显示出这个汉字了。
知道显示一个汉字的原理,就可以推及整个汉字库了,要显示任意汉字,我们首先要知道该汉字的点阵数据,整个GBK字库是比较大的(2W多个汉字),这些数据可以由专门的软件来生成。
字库的制作
:
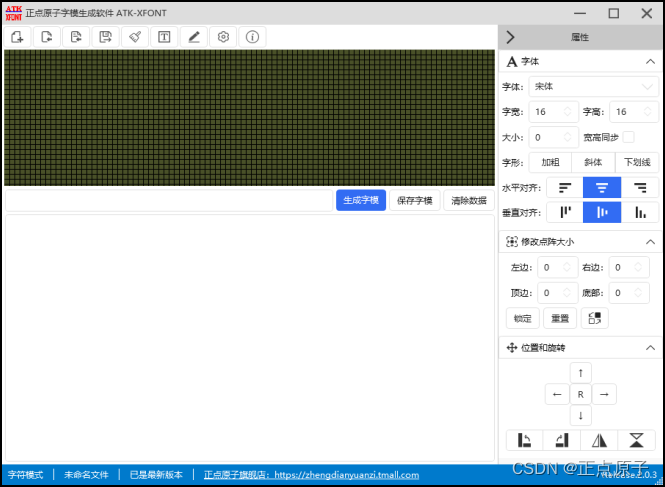
图51.1.2.2 点阵字库生成器默认界面
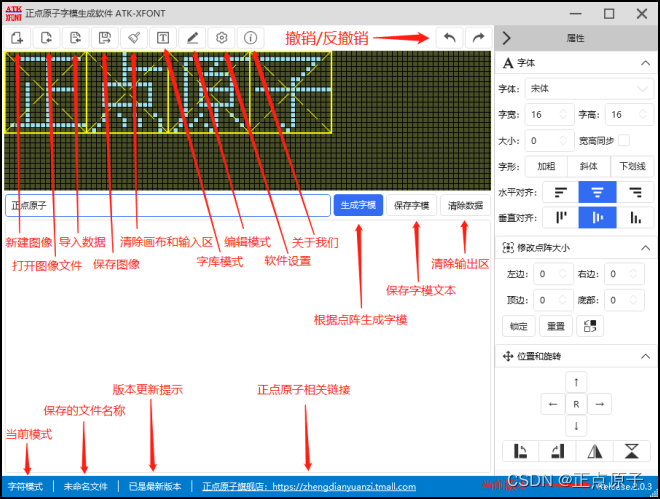
图51.1.2.3 生成GBK1616字库的设置方法
注意:电脑端的字体大小与我们生成点阵大小的关系为:
fsize = dsize * 6 / 8
其中,fsize是电脑端字体的大小,dsize是点阵大小(12、16、24等)。所以1616点阵大小对应的是12号字体。
生成完以后,我们把文件名和后缀改成:GBK16.FON(这里是手动修改后缀!!)。用类似的方法,生成1212的点阵库(GBK12.FON)和2424的点阵库(GBK24.FON),总共制作3个字库。
另外,该软件还可以生成其他很多字库,字体也可选,大家可以根据自己的需要按照上面的方法生成即可。该软件的详细介绍请看软件自带的。
最后,由于汉字字库比较大,我们不可能将其烧录在MCU内部FLASH里面。因此,我们生成的字库,要先放入TF卡,然后通过TF卡将字库文件复制到单片机外挂的SPI FLASH芯片(25Qxx)里面。使用的时候,单片机从SPI FLASH里面获取汉字点阵数据,这样,SPI FLASH就相当于一个汉字字库芯片了。
51.1.3 汉字显示原理
经过以上两个小节的学习,我们可以归纳出汉字显示的过程:
MCU汉字编码汉字字库汉字点阵数据描点
编码和字库的制作我们已经学会了,所以只剩下一个问题:如何通过汉字编码在汉字字库里面查找对应汉字的点阵数据?
根据GBK编码规则,我们的汉字点阵字库只要按照这个编码规则从0X8140开始,逐一建立,每个区的点阵大小为每个汉字所用的字节数190。这样,我们就可以得到在这个字库里面定位汉字的方法:
当GBKL < 0X7F时:Hp = ((GBKH - 0x81) * 190 + GBKL - 0X40) * csize;
当GBKL > 0X80时:Hp = ((GBKH - 0x81) * 190 + GBKL - 0X41) * csize;
其中GBKH、GBKL分别代表GBK的第一个字节和第二个字节(也就是高字节和低字节),csize代表单个汉字点阵数据的大小(字节数),Hp则为对应汉字点阵数据在字库里面的起始地址(假设是从0开始存放,如果是非0开始,则加上对应偏移量即可)。
单个汉字点阵数据大小(csize)计算公式如下:
csize = (size / 8 + ((size % 8) ? 1 : 0)) * (size);
其中size为汉字点阵长宽尺寸,如:12(对应1212字体)、16(对应1616字体)、24(对应2424字体)。对于1212字体,csize大小为24字节,对于1616字体,csize大小为32字节。
通过以上方法,从字库里面获取到某个汉字点阵数据后,按取模方式(我们使用:从上到下、从左到右,高位在前)进行描点还原即可将汉字显示在LCD上面。这就是汉字显示的原理。
51.1.4 ffunicode.c优化(补充说明)
本小节内容和汉字显示无关,仅做补充说明,可选择性学习。
在上一章,我们提到要用ffunicode.c,以支持长文件名,但是ffunicode.c文件里面中文转换(中文的页面编码代号为:936)的两个数组太大了(172KB),直接刷在单片机里面,太占用flash了,所以我们必须把这两个数组存放在外部flash。数组uni2oem936和oem2uni936存放unicode和gbk的互相转换对照表,这两个数组很大,这里我们利用正点原子提供的一个C语言数组转BIN(二进制)的软件:C2B转换助手V2.0.exe,将这两个数组转为BIN文件,我们将这两个数组拷贝出来存放为一个新的文本文件,假设为UNIGBK.TXT,然后用C2B转换助手打开这个文本文件,如图51.1.4.1所示:

图51.1.4.1 C2B转换助手
然后点击转换,就可以在当前目录下(文本文件所在目录下)得到一个UNIGBK.bin的文件。这样就完成将C语言数组转换为.bin文件,然后只需要将UNIGBK.bin保存到外部FLASH就实现了该数组的转移。
在ffunicode.c里面,通过ff_uni2oem和ff_oem2uni调用这两个数组,实现UNICODE和GBK的互转,该函数原代码如下:
WCHAR ff_uni2oem ( /* Returns OEM code character, zero on error */DWORD uni, /* UTF-16 encoded character to be converted */WORD cp /* Code page for the conversion */
)
{const WCHAR *p;WCHAR c = 0, uc;UINT i = 0, n, li, hi;if (uni < 0x80) /* ASCII? */{c = (WCHAR)uni;}else /* Non-ASCII */{if (uni < 0x10000 && cp == FF_CODE_PAGE)/* in BMP and valid code page? */{uc = (WCHAR)uni;p = CVTBL(uni2oem, FF_CODE_PAGE);hi = sizeof CVTBL(uni2oem, FF_CODE_PAGE) / 4 - 1;li = 0;for (n = 16; n; n--){i = li + (hi - li) / 2;if (uc == p[i * 2]) break;if (uc > p[i * 2]){li = i;}else{hi = i;}}if (n != 0) c = p[i * 2 + 1];}}return c;
}WCHAR ff_oem2uni ( /* Returns Unicode character in UTF-16, zero on error */WCHAR oem, /* OEM code to be converted */WORD cp /* Code page for the conversion */
)
{const WCHAR *p;WCHAR c = 0;UINT i = 0, n, li, hi;if (oem < 0x80) /* ASCII? */{c = oem;}else /* Extended char */{if (cp == FF_CODE_PAGE) /* Is it valid code page? */{p = CVTBL(oem2uni, FF_CODE_PAGE);hi = sizeof CVTBL(oem2uni, FF_CODE_PAGE) / 4 - 1;li = 0;for (n = 16; n; n--){i = li + (hi - li) / 2;if (oem == p[i * 2]) break;if (oem > p[i * 2]){li = i;}else{hi = i;}}if (n != 0) c = p[i * 2 + 1];}}return c;
}
以上两个函数,我们只需要关心对中文的处理,也就是对936的处理,这两个函数通过二分法来查找UNICODE(或GBK)码对应的GBK(或UNICODE)码。当我们将两个数组存放在外部flash的时候,这两个函数该可以修改为:
WCHAR ff_uni2oem ( /* Returns OEM code character, zero on error */DWORD uni, /* UTF-16 encoded character to be converted */WORD cp /* Code page for the conversion */
)
{WCHAR t[2];WCHAR c;uint32_t i, li, hi;uint16_t n;uint32_t gbk2uni_offset = 0;if (uni < 0x80){c = uni; /* ASCII,直接不用转换 */}else{hi = ftinfo.ugbksize / 2; /* 对半开 */hi = hi / 4 - 1;li = 0;for (n = 16; n; n--) /* 二分法查找 */{i = li + (hi - li) / 2;norflash_read((uint8_t *)&t, ftinfo.ugbkaddr + i * 4 +
gbk2uni_offset, 4); /* 读出4个字节 */if (uni == t[0]) break;if (uni > t[0]){li = i;}else{hi = i;}}c = n ? t[1] : 0;}return c;
}WCHAR ff_oem2uni ( /* Returns Unicode character, zero on error */WCHAR oem, /* OEM code to be converted */WORD cp /* Code page for the conversion */
)
{WCHAR t[2];WCHAR c;uint32_t i, li, hi;uint16_t n;uint32_t gbk2uni_offset = ftinfo.ugbksize / 2;if (oem < 0x80){c = oem; /* ASCII,直接不用转换 */}else{hi = ftinfo.ugbksize / 2; /* 对半开 */hi = hi / 4 - 1;li = 0;for (n = 16; n; n--) /* 二分法查找 */{i = li + (hi - li) / 2;norflash_read((uint8_t *)&t, ftinfo.ugbkaddr + i * 4 +
gbk2uni_offset, 4); /* 读出4个字节 */if (oem == t[0]) break;if (oem > t[0]){li = i;}else{hi = i;}}c = n ? t[1] : 0;}return c;
}
代码中的ftinfo.ugbksize为我们刚刚生成的UNIGBK.bin的大小,而ftinfo.ugbkaddr是我们存放UNIGBK.bin文件的首地址,这里同样采用的是二分法查找。
修改后的ffunicode.c,我们将其命名为myffunicode.c,并保存在exfuns文件夹下,将工程FATFS组下的ffunicode.c删除,然后重新添加myffunicode.c到FATFS组下,myffunicode.c的源码就不贴出来了,其实就是在ffunicode.c的基础上去掉了两个大数组,然后对ff_uni2oem和ff_oem2uni两个函数进行了修改,详见本例程源码。
关于ffunicode.c的修改,我们就介绍到这。
51.2 硬件设计
- 例程功能
本实验开机的时候程序通过预设值的标记位检测norflash中是否已经存在字库,如果存在,则按次序显示汉字(三种字体都显示)。如果没有,则检测SD卡和文件系统,并查找SYSTEM文件夹下的FONT文件夹,在该文件夹内查找UNIGBK.BIN、GBK12.FON、GBK16.FON和GBK24.FON这几个文件的由来,我们在前面已经介绍过了。在检测到这些文件之后,就开始更新字库,更新完毕才开始显示汉字。通过按按键KEY0,可以强制更新字库。
LED0闪烁,提示程序运行。 - 硬件资源
1)LED灯
LED0 – PB5
2)独立按键
KEY0 – PE4
3)串口1(PA9/PA10连接在板载USB转串口芯片CH340上面)
4)正点原子 2.8/3.5/4.3/7/10寸TFTLCD模块(仅限MCU屏,16位8080并口驱动)
5)SD卡
6)NOR FLASH,通过SPI驱动,我们需要用到它来存储汉字库
51.3 程序设计
51.3.1 程序流程图
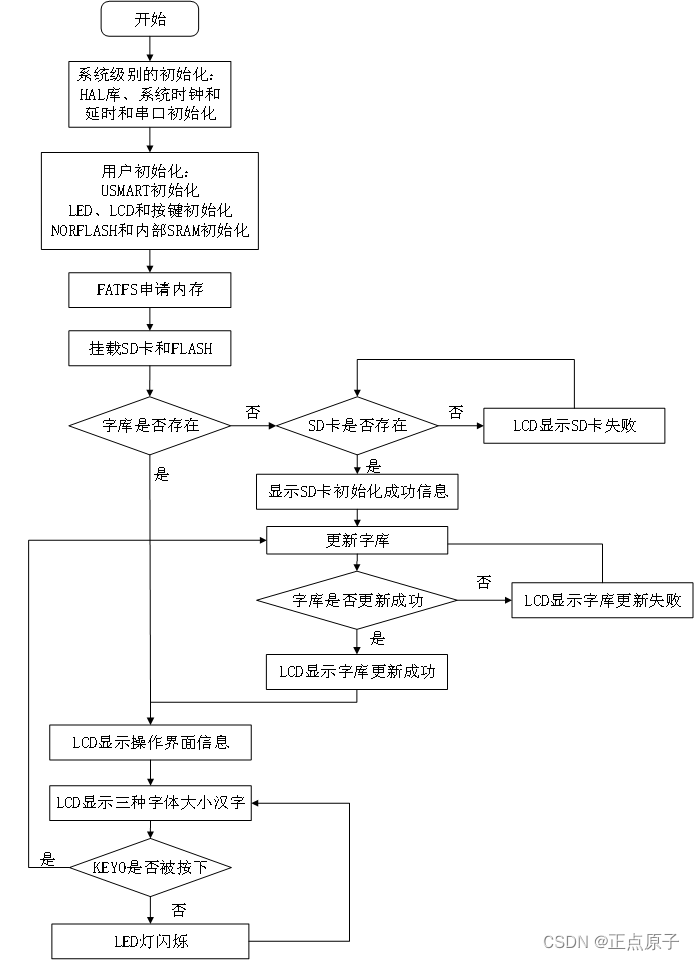
图51.3.1.1汉字显示实验程序流程图
51.3.2 程序解析
- TEXT代码
这里我们只讲解核心代码,详细的源码请大家参考光盘本实验对应源码。TEXT驱动源码包括四个文件:text.c、text.h、fonts.c和fonts.h。
汉字显示实验代码主要分为两部分:一部分就是对字库的更新,另一部分就是对汉字的显示。字库的更新代码放在font.c和font.h文件中,汉字的显示代码就放在text.c和text.h中。
下面我们介绍一下有关字库操作的代码,首先我们先看一下fonts.h文件中字库信息结构体定义,其代码如下:
/* 字库信息结构体定义* 用来保存字库基本信息,地址,大小等*/
__packed typedef struct
{uint8_t fontok; /* 字库存在标志,0XAA,字库正常;其他,字库不存在 */uint32_t ugbkaddr; /* unigbk的地址 */uint32_t ugbksize; /* unigbk的大小 */uint32_t f12addr; /* gbk12地址 */uint32_t gbk12size; /* gbk12的大小 */uint32_t f16addr; /* gbk16地址 */uint32_t gbk16size; /* gbk16的大小 */uint32_t f24addr; /* gbk24地址 */uint32_t gbk24size; /* gbk24的大小 */
} _font_info;
这个结构体用于记录字库的首地址以及字库大小等信息,总共占用33个字节,第一个字节用来标识字库是否OK,其他的用来记录地址和文件大小。因为我们将NORFLASH(25Q128)的前12M字节给了FATFS管理(用做本地磁盘),12M字节后紧跟3个字库+UNIGBK.BIN总大小3.09M字节791个扇区,在15.10M字节后,预留了100K字节给用户自己使用。所以,我们的存储地址是从1210241024处开始的。最开始的33个字节给_font_info用,用于保存_font_info结构体数据,之后是UNIGBK.BIN、GBK12.FON、GBK16.FON和GBK24.FON。
下面介绍font.c文件中几个重要的函数。
字库初始化函数也是利用其存储顺序,进行检查字库,其定义如下:
/*** @brief 初始化字体* @param 无* @retval 0, 字库完好; 其他, 字库丢失;*/
uint8_t fonts_init(void)
{uint8_t t = 0;while (t < 10) /* 连续读取10次,都是错误,说明确实是有问题,得更新字库了 */{t++;
/* 读出ftinfo结构体数据 */norflash_read((uint8_t *)&ftinfo, FONTINFOADDR, sizeof(ftinfo)); if (ftinfo.fontok == 0XAA){break;}delay_ms(20);}if (ftinfo.fontok != 0XAA){return 1;}return 0;
}
这里就是把NORFLASH的12M地址的33个字节数据读取出来,进而判断字库结构体ftinfo的字库标记fontok是否为AA,确定字库是否完好。
有人会有疑问:ftinfo.fontok是在哪里赋值AA呢?肯定是字库更新完毕后,给该标记赋值的,那下面就来看一下是不是这样子,字库更新函数定义如下:
/*** @brief 更新字体文件* @note 所有字库一起更新(UNIGBK,GBK12,GBK16,GBK24)* @param x, y : 提示信息的显示地址* @param size : 提示信息字体大小* @param src : 字库来源磁盘* @arg "0:", SD卡;* @Arg "1:", FLASH盘* @param color : 字体颜色* @retval 0, 成功; 其他, 错误代码;*/
uint8_t fonts_update_font(uint16_t x, uint16_t y, uint8_t size, uint8_t *src, uint16_t color)
{uint8_t *pname;uint32_t *buf;uint8_t res = 0;uint16_t i, j;FIL *fftemp;uint8_t rval = 0;res = 0XFF;ftinfo.fontok = 0XFF;pname = mymalloc(SRAMIN, 100); /* 申请100字节内存 */buf = mymalloc(SRAMIN, 4096); /* 申请4K字节内存 */fftemp = (FIL *)mymalloc(SRAMIN, sizeof(FIL)); /* 分配内存 */if (buf == NULL || pname == NULL || fftemp == NULL){myfree(SRAMIN, fftemp);myfree(SRAMIN, pname);myfree(SRAMIN, buf);return 5; /* 内存申请失败 */}for (i = 0; i < 4; i++) /* 先查找文件UNIGBK,GBK12,GBK16,GBK24 是否正常 */{strcpy((char *)pname, (char *)src); /* copy src内容到pname */strcat((char *)pname, (char *)FONT_GBK_PATH[i]); /* 追加具体文件路径 */res = f_open(fftemp, (const TCHAR *)pname, FA_READ);/* 尝试打开 */if (res){rval |= 1 << 7; /* 标记打开文件失败 */break; /* 出错了,直接退出 */}}myfree(SRAMIN, fftemp); /* 释放内存 */if (rval == 0) /* 字库文件都存在. */
{ /* 提示正在擦除扇区 */lcd_show_string(x, y, 240, 320, size, "Erasing sectors... ", color); for (i = 0; i < FONTSECSIZE; i++) /* 先擦除字库区域,提高写入速度 */{fonts_progress_show(x+20*size/2,y,size,FONTSECSIZE,i,color);/*进度显示*/
/* 读出整个扇区的内容 */norflash_read((uint8_t *)buf, ((FONTINFOADDR / 4096) + i) * 4096,4096);for (j = 0; j < 1024; j++) /* 校验数据 */{if (buf[j] != 0XFFFFFFFF)break; /* 需要擦除 */}if (j != 1024){norflash_erase_sector((FONTINFOADDR / 4096) + i); /*需要擦除的扇区*/}}for (i = 0; i < 4; i++) /* 依次更新UNIGBK,GBK12,GBK16,GBK24 */{lcd_show_string(x,y,240,320,size,FONT_UPDATE_REMIND_TBL[i],color);strcpy((char *)pname, (char *)src); /* copy src内容到pname */strcat((char *)pname, (char *)FONT_GBK_PATH[i]); /* 追加具体文件路径 */res = fonts_update_fontx(x+20*size/2,y,size,pname,i,color);/*更新字库*/if (res){myfree(SRAMIN, buf);myfree(SRAMIN, pname);return 1 + i;}}ftinfo.fontok = 0XAA; /* 全部更新好了 */norflash_write((uint8_t *)&ftinfo,FONTINFOADDR,sizeof(ftinfo));/*保存字库信息*/}myfree(SRAMIN, pname); /* 释放内存 */myfree(SRAMIN, buf);return rval; /* 无错误. */
}
函数的实现:动态申请内存→尝试打开文件(UNIGBK、GBK12、GBK16和GBK24),确定文件是否存在→擦除字库→依次更新UNIGBK、GBK12、GBK16和GBK24→写入ftinfo结构体信息。
在字库更新函数中能直接看到的是ftinfo.fontok成员被赋值,而其他成员在单个字库更新函数中被赋值,接下来分析一下更新某个字库函数,其代码如下:
/*** @brief 更新某一个字库* @param x, y : 提示信息的显示地址* @param size : 提示信息字体大小* @param fpath : 字体路径* @param fx : 更新的内容* @arg 0, ungbk;* @Arg 1, gbk12;* @arg 2, gbk16;* @arg 3, gbk24;* @param color : 字体颜色* @retval 0, 成功; 其他, 错误代码;*/
static uint8_t fonts_update_fontx(uint16_t x, uint16_t y, uint8_t size, uint8_t *fpath, uint8_t fx, uint16_t color)
{uint32_t flashaddr = 0;FIL *fftemp;uint8_t *tempbuf;uint8_t res;uint16_t bread;uint32_t offx = 0;uint8_t rval = 0;fftemp = (FIL *)mymalloc(SRAMIN, sizeof(FIL)); /* 分配内存 */if (fftemp == NULL)rval = 1;tempbuf = mymalloc(SRAMIN, 4096); /* 分配4096个字节空间 */if (tempbuf == NULL)rval = 1;res = f_open(fftemp, (const TCHAR *)fpath, FA_READ);if (res)rval = 2; /* 打开文件失败 */if (rval == 0){switch (fx){case 0: /* 更新 UNIGBK.BIN */
/*信息头之后,紧跟UNIGBK转换码表 */ftinfo.ugbkaddr = FONTINFOADDR + sizeof(ftinfo); ftinfo.ugbksize = fftemp->obj.objsize; /* UNIGBK大小 */flashaddr = ftinfo.ugbkaddr;break;case 1: /* 更新 GBK12.FONT */
/* UNIGBK之后,紧跟GBK12字库 */ftinfo.f12addr = ftinfo.ugbkaddr + ftinfo.ugbksize; ftinfo.gbk12size = fftemp->obj.objsize; /* GBK12字库大小 */flashaddr = ftinfo.f12addr; /* GBK12的起始地址 */break;case 2: /* 更新 GBK16.FONT */
/* GBK12之后,紧跟GBK16字库 */ftinfo.f16addr = ftinfo.f12addr + ftinfo.gbk12size; ftinfo.gbk16size = fftemp->obj.objsize; /* GBK16字库大小 */flashaddr = ftinfo.f16addr; /* GBK16的起始地址 */break;case 3: /* 更新 GBK24.FONT *//* GBK16之后,紧跟GBK24字库 */ftinfo.f24addr = ftinfo.f16addr + ftinfo.gbk16size; ftinfo.gbk24size = fftemp->obj.objsize; /* GBK24字库大小 */flashaddr = ftinfo.f24addr; /* GBK24的起始地址 */break;}while (res == FR_OK) /* 死循环执行 */{
res = f_read(fftemp, tempbuf, 4096, (UINT *)&bread); /* 读取数据 */if (res != FR_OK)break; /* 执行错误 */norflash_write(tempbuf,offx+flashaddr,bread); /*从0开始写入bread个数据*/offx += bread;fonts_progress_show(x,y,size,fftemp->obj.objsize,offx,color);/*进度显示*/if (bread != 4096)break; /* 读完了. */}f_close(fftemp);
}myfree(SRAMIN, fftemp); /* 释放内存 */myfree(SRAMIN, tempbuf); /* 释放内存 */return res;
}
单个字库更新函数,主要是对把字库从SD卡中读取出数据,写入NORFLASH。同时把字库大小和起始地址保存在ftinfo结构体里,在前面的整个字库更新函数中使用函数:
norflash_write((uint8_t *)&ftinfo,FONTINFOADDR,sizeof(ftinfo)); /保存字库信息/
结构体的所有成员一并写入到那33字节。有了这个字库信息结构体,就能很容易进行定位。结合前面的说到的根据地址偏移寻找汉字的点阵数据,我们就可以开始真正把汉字搬上屏幕中去了。
首先我们肯定需要获得汉字的GBK码,这里MDK已经帮我们实现了。这里用一个例子说明:
在这里可以看出MDK识别汉字的方式是GBK码,换句话来说就是MDK自动会把汉字看成是两个字节表示的东西。知道了要表示的汉字和其GBK码,那么就可以去找对应的点阵数据。在这里我们就定义了一个获取汉字点阵数据的函数,其定义如下:
/*** @brief 获取汉字点阵数据* @param code : 当前汉字编码(GBK码)* @param mat : 当前汉字点阵数据存放地址* @param size : 字体大小* @note size大小的字体,其点阵数据大小为: (size / 8 + ((size % 8) ? 1 : 0))
* (size) 字节* @retval 无*/
static void text_get_hz_mat(unsigned char *code, unsigned char *mat,
uint8_t size)
{unsigned char qh, ql;unsigned char i;
unsigned long foffset;
/* 得到字体一个字符对应点阵集所占的字节数 */uint8_t csize = (size / 8 + ((size % 8) ? 1 : 0)) * (size);qh = *code;ql = *(++code);if (qh < 0x81 || ql < 0x40 || ql == 0xff || qh == 0xff) /* 非 常用汉字 */{for (i = 0; i < csize; i++){*mat++ = 0x00; /* 填充满格 */}return; /* 结束访问 */}if (ql < 0x7f){ql -= 0x40; /* 注意! */}else{ql -= 0x41;}qh -= 0x81;foffset = ((unsigned long)190 * qh + ql) * csize; /* 得到字库中的字节偏移量 */switch (size){case 12:norflash_read(mat, foffset + ftinfo.f12addr, csize);break;case 16:norflash_read(mat, foffset + ftinfo.f16addr, csize);break;case 24:norflash_read(mat, foffset + ftinfo.f24addr, csize);break;}
}
函数实现的依据就是前面42.1.3小节讲到的两条公式:
当GBKL < 0X7F时:Hp = ((GBKH - 0x81) * 190 + GBKL - 0X40) * csize;
当GBKL > 0X80时:Hp = ((GBKH - 0x81) * 190 + GBKL - 0X41) * csize;
目标汉字的GBK码满足上面两条公式其一,就会得出与一个GBK对应的汉字点阵数据的偏移。在这个基础上,通过汉字点阵的大小,就可以从对应的字库提取目标汉字点阵数据。
在获取到点阵数据后,接下来就可以进行汉字显示,下面看一下汉字显示函数,其定义如下:
/*** @brief 显示一个指定大小的汉字* @param x,y : 汉字的坐标* @param font : 汉字GBK码* @param size : 字体大小* @param mode : 显示模式* @note 0, 正常显示(不需要显示的点,用LCD背景色填充,即g_back_color)* @note 1, 叠加显示(仅显示需要显示的点, 不需要显示的点, 不做处理)* @param color : 字体颜色* @retval 无*/
void text_show_font(uint16_t x, uint16_t y, uint8_t *font, uint8_t size, uint8_t mode, uint16_t color)
{uint8_t temp, t, t1;uint16_t y0 = y;
uint8_t *dzk;
/* 得到字体一个字符对应点阵集所占的字节数 */uint8_t csize = (size / 8 + ((size % 8) ? 1 : 0)) * (size); if (size != 12 && size != 16 && size != 24 && size != 32){return; /* 不支持的size */}dzk = mymalloc(SRAMIN, size); /* 申请内存 */if (dzk == 0) return; /* 内存不够了 */text_get_hz_mat(font, dzk, size); /* 得到相应大小的点阵数据 */for (t = 0; t < csize; t++){temp = dzk[t]; /* 得到点阵数据 */for (t1 = 0; t1 < 8; t1++){if (temp & 0x80){lcd_draw_point(x, y, color); /* 画需要显示的点 */}else if (mode == 0) /* 如果非叠加模式, 不需要显示的点,用背景色填充 */{lcd_draw_point(x, y, g_back_color); /* 填充背景色 */}temp <<= 1;y++;if ((y - y0) == size){y = y0;x++;break;}}}myfree(SRAMIN, dzk); /* 释放内存 */
}
汉字显示函数通过调用获取汉字点阵数据函数text_get_hz_mat就获取到点阵数据,使用lcd画点函数把点阵数据中“1”的点都画出来,最终会在LCD显示你所要表示的汉字。
其他函数就不多讲解,大家可以自行消化。
2. main.c代码
在main.c里编写代码如下:
int main(void)
{uint32_t fontcnt;uint8_t i, j;uint8_t fontx[2]; /* GBK码 */uint8_t key, t;HAL_Init(); /* 初始化HAL库 */sys_stm32_clock_init(RCC_PLL_MUL9); /* 设置时钟, 72Mhz */delay_init(72); /* 延时初始化 */usart_init(115200); /* 串口初始化为115200 */usmart_dev.init(72); /* 初始化USMART */led_init(); /* 初始化LED */lcd_init(); /* 初始化LCD */key_init(); /* 初始化按键 */norflash_init(); /* 初始化NORFLASH */my_mem_init(SRAMIN); /* 初始化内部SRAM内存池 */exfuns_init(); /* 为fatfs相关变量申请内存 */f_mount(fs[0], "0:", 1); /* 挂载SD卡 */f_mount(fs[1], "1:", 1); /* 挂载FLASH */while (fonts_init()) /* 检查字库 */{
UPD:lcd_clear(WHITE); /* 清屏 */lcd_show_string(30, 30, 200, 16, 16, "STM32F103", RED);while (sd_init()) /* 检测SD卡 */{lcd_show_string(30, 50, 200, 16, 16, "SD Card Failed!", RED);delay_ms(200);lcd_fill(30, 50, 200 + 30, 50 + 16, WHITE);delay_ms(200);}lcd_show_string(30, 50, 200, 16, 16, "SD Card OK", RED);lcd_show_string(30, 70, 200, 16, 16, "Font Updating...", RED);key = fonts_update_font(20, 90, 16, (uint8_t *)"0:", RED); /* 更新字库 */while (key) /* 更新失败 */{lcd_show_string(30, 90, 200, 16, 16, "Font Update Failed!", RED);delay_ms(200);lcd_fill(20, 90, 200 + 20, 90 + 16, WHITE);delay_ms(200);}lcd_show_string(30, 90, 200, 16, 16, "Font Update Success! ", RED);delay_ms(1500);lcd_clear(WHITE);/* 清屏 */}text_show_string(30, 30, 200, 16, "正点原子开发板", 16, 0, RED);text_show_string(30, 50, 200, 16, "GBK字库测试程序", 16, 0, RED);text_show_string(30, 70, 200, 16, "正点原子@ALIENTEK", 16, 0, RED);text_show_string(30, 90, 200, 16, "按KEY0,更新字库", 16, 0, RED);text_show_string(30, 110, 200, 16, "内码高字节:", 16, 0, BLUE);text_show_string(30, 130, 200, 16, "内码低字节:", 16, 0, BLUE);text_show_string(30, 150, 200, 16, "汉字计数器:", 16, 0, BLUE);text_show_string(30, 180, 200, 24, "对应汉字为:", 24, 0, BLUE);text_show_string(30, 204, 200, 16, "对应汉字(16*16)为:", 16, 0, BLUE);text_show_string(30, 220, 200, 16, "对应汉字(12*12)为:", 12, 0, BLUE);while (1){fontcnt = 0;for (i = 0x81; i < 0xff; i++) /* GBK内码高字节范围为0X81~0XFE */{fontx[0] = i;lcd_show_num(118, 110, i, 3, 16, BLUE); /* 显示内码高字节 */for (j = 0x40; j <0xfe; j++) /* GBK内码低字节范围0X40~0X7E,0X80~0XFE */{if (j == 0x7f)continue;fontcnt++;lcd_show_num(118, 130, j, 3, 16, BLUE); /* 显示内码低字节 */lcd_show_num(118, 150, fontcnt, 5, 16, BLUE); /* 汉字计数显示 */fontx[1] = j;text_show_font(30 + 132, 180, fontx, 24, 0, BLUE);text_show_font(30 + 144, 204, fontx, 16, 0, BLUE);text_show_font(30 + 108, 220, fontx, 12, 0, BLUE);t = 200;while (t--) /* 延时,同时扫描按键 */{delay_ms(1);key = key_scan(0);if (key == KEY0_PRES){goto UPD; /* 跳转到UPD位置(强制更新字库) */}}LED0_TOGGLE();}}}
}
main函数实现了我们在硬件设计例程功能所表述的一致,至此整个软件设计就完成了。
51.4 下载验证
本例程支持1212、1616和24*24等三种字体的显示,将程序下载到开发板后,可以看到LED0不停的闪烁,提示程序已经在运行了。LCD开始显示三种大小的汉字及内码如图51.4.1所示:

图51.4.1 汉字显示实验显示效果
一开始就显示汉字,是因为板子在出厂的时候都是测试过的,里面刷了综合测试程序,已经把字库写入到NORFLASH里面,所以并不会提示更新字库。如果你想要更新字库,就需要先找一张SD卡,把A盘资料\5,SD卡根目录文件 文件夹下面的SYSTEM文件夹拷贝到SD卡根目录下,插入开发板,并按复位,之后,在显示汉字的时候,按下KEY0,就可以开始更新字库。字库更新界面如图51.4.2所示:

图51.4.2汉字字库更新界面
此外我们还可以使用USMART来测试该实验。通过USMART调用text_show_string或者text_show_string_middle来实现任意位置显示任何字符串,有兴趣的朋友可以尝试一下。
这篇关于【正点原子STM32连载】第五十一章 汉字显示实验 摘自【正点原子】STM32F103 战舰开发指南V1.2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






