本文主要是介绍【正点原子STM32连载】 第五十五章 录音机实验摘自【正点原子】STM32F103 战舰开发指南V1.2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1)实验平台:正点原子stm32f103战舰开发板V4
2)平台购买地址:https://detail.tmall.com/item.htm?id=609294757420
3)全套实验源码+手册+视频下载地址: http://www.openedv.com/thread-340252-1-1.html#
第五十七章 手写识别实验
本章,我们将利用正点原子提供的手写识别库,实现一个简单得数字字母手写识别。本章分为如下几个小节:
57.1 手写识别简介
57.2 硬件设计
57.3 程序设计
57.4 下载验证
57.1 手写识别简介
手写识别,是指对在手写设备上书写时产生的有序轨迹信息进行识别的过程,是人际交互最自然、最方便的手段之一。随着智能手机和平板电脑等移动设备的普及,手写识别的应用也被越来越多的设备采用。
手写识别能够使用户按照最自然、最方便的输入方式进行文字输入,易学易用,可取代键盘或者鼠标。用于手写输入的设备有许多种,比如电磁感应手写板、压感式手写板、触摸屏、触控板、超声波笔等。本实验通过使用STM32板子自带得TFTLCD触摸屏(2.8/3.5/4.3/7寸),可以用来作为手写识别的输入设备。接下来,我们将给大家简单介绍下手写识别的实现过程。
手写识别与其他识别系统如语音识别、图像识别一样分为两个过程:训练学习过程;识别过程。如图57.1.1所示:
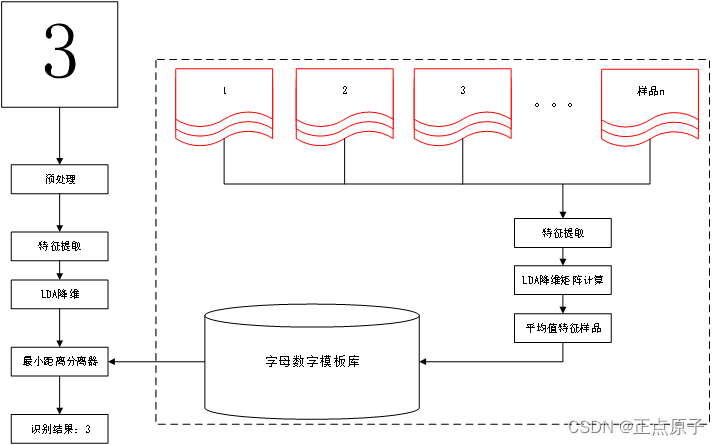
图57.1.1 字母数字识别系统示意图
上图中虚线部分分为训练学习过程,该过程首先需要使用设备采集大量数据样本,样本类别数目为09,az,A~Z 总过62类,每个类别5~10个样本不等(样本越多识别率就越高)。对这些样本进行传统的八方向特征提取,提取后特征维数为512维,这对于STM32来说,计算量和模板库的存储量都是难以接收,所以需要运行一些方法进行降维,这里采用LDA线性判决分析的方法进行降维。所谓的线性判决分析,即是假设所有样本服从高斯分布(正态分布)对样本进行低维投影,以达到各个样本间的距离最大化。关于LDA(线性判别分析)的更多知识可以自行阅读(http://wenku.baidu.com/view/f05c731452d380eb62946d39.html)等参考文档。这里将维度降到64维度,然后针对各个样本类别进行平均计算的到该类别的样本模板。
而对于识别过程,首先得到触屏输入的有序轨迹,然后进行一些预处理,预处理主要包括重采样,归一处理。重采样主要是因为不同的输入设备不同的输入处理方式产生的有序轨迹序列有所不同。为了达到更好的识别结果我们需要对训练样本和识别输入的样本进行重采样处理,这里主要应用隔点重采样的方法对输入序列进行重采样;而归一化就是因为不同的书写风格采用分辨率的差异会导致字体太小不同,因此需要对输入轨迹进行归一化。这里把样本进行线性缩放的方法归一化为6464像素。
接下来进行同样的八方向特征提取操作。所谓的八方向特征就是首先将经过预处理后的6464输入进行切分成88的小方格,每个方格88个像素;然后对每个88个小格进行各个方向的点数统计。如某个方格内一共有10个点,其中八个方向的点分别为:1、3、5、2、3、4、3、2,那么这个格子得到的八个特征向量为[0.1, 0.3, 0.5, 0.2, 0.3, 0.4, 0.3, 0.2]。总共64个格子,于是一个样本最终能得到648=512维特征,更多八方向特征提取可以参考一下两个文档:
1,http://wenku.baidu.com/view/d37e5a49e518964bcf847ca5.html;
2,http://wenku.baidu.com/view/3e7506254b35eefdc8d333a1.html;
由于训练过程进行了LDA降维计算,所以识别过程同样需要对应的LDA降维过程得到最终的64维特征。这个计算过程就是在训练模板的过程中可以运算得到一个512*64维的矩阵,那么我们通过矩阵乘运算可以得到64维的最终特征值。
最后将这64维特征分别与模板中的特征进行求距离运算。得到最小的距离为该输入的最佳识别结果输出。
关于手写识别原理,我们就介绍到这里。如果想自己实现手写识别,那得花很多时间学习和研究,但是如果只是应用的话,那么就只需要知道怎么用就OK了,相对来说,简单得多。
正点原子提供了一个数字字母识别库,我们不需要关心手写识别是如何实现的,只需要知道这个库怎么用,就能实现手写识别。正点原子提供的手写识别库由4个文件组成:ATKNCR_M_V2.0.lib、ATKNCR_M_V2.0.lib、atk_ncr.c和atk_ncr.h。
ATKNCR_M_V2.0.lib和ATKNCR_M_V2.0.lib是两个识别用的库文件(两个版本),使用的时候,选择其中之一即可。ATKNCR_M_V2.0.lib用于使用内存管理的情况,用户必须自己实现alientek_ncr_malloc和alientek_ncr_free两个函数。而ATKNCR_N_V2.0.lib用于不使用内存管理的情况,通过全局变量来定义缓存区,缓存区需要提供至少3K左右的RAM。大家根据自己的需要,选择不同的版本即可。正点原子手写识别库资源需求:FLASH在52K左右,RAM在6K左右。
57.2 硬件设计
- 例程功能
开机的时候先初始化手写识别器,然后检测字库,之后进入等待输入状态。此时,我们在手写区写数字/字符,在每次写入结束后,自动进入识别状态,进行识别,然后将识别结果输出在LCD模块上,同时打印到串口。通过按KEY0可以进行模式切换(4种模式都可以测试),通过按KEY_UP,可以进入触摸屏校准(仅电阻屏需要校准,如果发现触摸屏不准,请执行此操作)。LED0闪烁用于提示程序正在运行。 - 硬件资源
1)LED灯
LED0 – PB5
2)独立按键
KEY0 – PE4
KEY1 – PE3
3)串口1
4)ALIENTEK 2.8/3.5/4.3/7/10寸TFTLCD模块(仅限MCU屏,16位8080并口驱动)
5)NOR FLASH:通过SPI2连接
57.3 程序设计
57.3.1 程序流程图
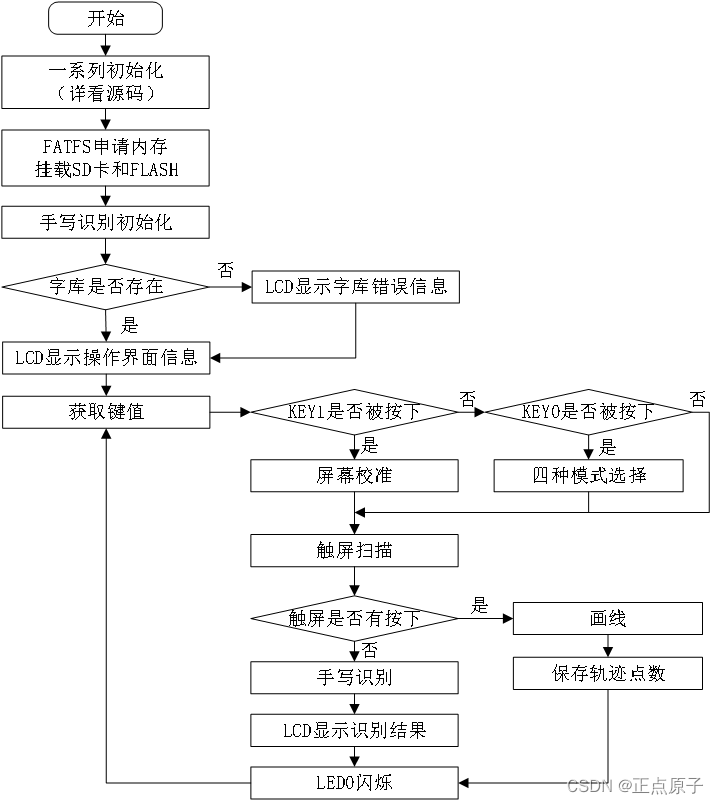
图57.3.1 手写识别实验程序流程图
手写识别我们主要通过配合LCD屏的触摸识别功能,将触摸信息传给解码库进行识别,由于解码库存储触摸点需要内存,所以注意保证内存够用。通过设定解码的点数就可以通过解码库封闭好的接口实现数据识别了。
57.3.2 程序解析
1.ATKNCR代码
手写识别代码我们在前面也提到了有四种,两个字母数字识别库至于用了哪个识别库,我们工程中使用的是ATKNCR_M_V2.0.lib。首先我们先看一下atk_nrc.h头文件中比较重要部分,其代码如下:
/* 输入轨迹坐标类型 */
__packed typedef struct _atk_ncr_point
{short x; /* x轴坐标 */short y; /* y轴坐标 */
}atk_ncr_point;/* 外部调用函数* 初始化识别器* 返回值 : 0, 初始化成功* 1, 初始化失败*/
unsigned char alientek_ncr_init(void);/* 停止识别器 */
void alientek_ncr_stop(void);/* 识别器识别* track : 输入点阵集合 * potnum : 输入点阵的点数,就是track的大小* charnum : 期望输出的结果数,就是你希望输出多少个匹配结果* mode : 识别模式* 1,仅识别数字* 2,仅识别大写字母* 3,仅识别小写字母* 4,混合识别(全部识别)** result : 结果缓存区(至少为:charnum+1个字节)*/
void alientek_ncr(atk_ncr_point * track, int potnum, Int charnum,
unsigned char mode,char*result);
在上面的代码中,我们定义了一些外部接口函数以及轨迹结构体等。
alientek_ncr_init函数用与初始化识别器,该函数在.lib文件实现,在识别开始之前,我们应该调用该函数。
alientek_ncr_stop函数用于停止识别器,在识别完成之后(不需要再识别),我们调用该函数,如果一直处于识别状态,则没必要调用。该函数也是在.lib 文件实现。
alientek_ncr函数就是识别函数了。它有5个参数,第一个参数track,为输入轨迹点的坐标集(最好200以内);第二个参数potnum,为坐标集点坐标的个数;第三个参数charnum,为期望输出的结果数,即希望输出多少个匹配结果,识别器按匹配程度排序输出(最佳匹配排第一);第四个参数mode,该函数用于设置模式,识别器总共支持 4 种模式:
1,仅识别数字
2,进识别大写字母
3,仅识别小写字母
4,混合识别(全部识别)
最后一个参数是result,用来输出结果,注意这个结果是ASCII码格式的。
下面我们直接来介绍atk_ncr.c中内存管理部分,其代码如下:
/*** @brief 内存设置函数* @param *p : 内存首地址* @param c : 要设置的值* @param len : 需要设置的内存大小(字节为单位)* @retval 无*/
void alientek_ncr_memset(char *p, char c, unsigned long len)
{my_mem_set((uint8_t*)p, (uint8_t)c, (uint32_t)len);
}/*** @brief 分配内存* @param size : 要分配的内存大小(字节)* @retval 分配到的内存首地址.*/
void *alientek_ncr_malloc(unsigned int size)
{return mymalloc(SRAMIN,size);
}/*** @brief 释放内存* @param ptr : 内存首地址* @retval 无*/
void alientek_ncr_free(void *ptr)
{myfree(SRAMIN,ptr);
}
alientek_ncr_memset、alientek_ncr_free和alientek_ncr_free三个函数的实现主要调用malloc中的函数实现。这里就不多讲,忘记这些函数的实现,可以回顾一下内存管理实验章节。
2. main.c代码
在这里讲一下正点原子提供的手写数字识别库实现数字字母识别的步骤:
1)调用alientek_ncr_init函数,初始化识别程序
该函数用来初始化识别器,在手写识别进行之前,必须调用该函数。
2)获取输入点阵数据
此步,我们通过触摸屏获取输入轨迹点阵坐标,然后存放到一个缓冲区里面,注意至少要输入2个不同坐标的点阵数据,才能正常识别。注意输入点数不要太多,太多的话,需要更多的内存,我们推荐的输入点数范围:100~200点。
3)调用alientek_ncr函数,得到识别结果
通过调用alitntek_ncr函数,我们可以得到输入点阵的识别结果,结果将保存在result参数里面,采用ASCII码格式存储。
4)调用alientek_ncr_stop函数,终止识别
如果不需要继续识别,则调用alientek_ncr_stop函数,终止识别器。如果还还需要继续识别,重复步骤2和步骤3即可。
以上4个步骤,就是使用正点原子手写识别库的方法,十分简单。这个操作流程也在主函数中清晰看到,下面看一下main.c,其代码如下:
int main(void)
{uint8_t i = 0;uint8_t tcnt = 0;char sbuf[10];uint8_t key;uint16_t pcnt = 0;uint8_t mode = 4; /* 默认是混合模式 */uint16_t lastpos[2]; /* 最后一次的数据 */HAL_Init(); /* 初始化HAL库 */sys_stm32_clock_init(RCC_PLL_MUL9); /* 设置时钟, 72Mhz */delay_init(72); /* 延时初始化 */usart_init(115200); /* 串口初始化为115200 */led_init(); /* 初始化LED */lcd_init(); /* 初始化LCD */key_init(); /* 初始化按键 */tp_dev.init(); /* 初始化触摸屏 */norflash_init(); /* 初始化NORFLASH */my_mem_init(SRAMIN); /* 初始化内部SRAM内存池 */exfuns_init(); /* 为fatfs相关变量申请内存 */f_mount(fs[0], "0:", 1); /* 挂载SD卡 */f_mount(fs[1], "1:", 1); /* 挂载FLASH */alientek_ncr_init(); /* 初始化手写识别 */while (fonts_init()) /* 检查字库 */{lcd_show_string(60, 50, 200, 16, 16, "Font Error!", RED);delay_ms(200);lcd_fill(60, 50, 240, 66, WHITE); /* 清除显示 */delay_ms(200);}RESTART:text_show_string(60, 10, 200, 16, "正点原子STM32F1开发板", 16, 0, RED);text_show_string(60, 30, 200, 16, "手写识别实验", 16, 0, RED);text_show_string(60, 50, 200, 16, "正点原子@ALIENTEK", 16, 0, RED);text_show_string(60, 70, 200, 16, "KEY0:MODE KEY1:Adjust", 16, 0, RED);text_show_string(60, 90, 200, 16, "识别结果:", 16, 0, RED);lcd_draw_rectangle(19, 114, lcddev.width - 20, lcddev.height - 5, RED);text_show_string(96, 207, 200, 16, "手写区", 16, 0, BLUE);tcnt = 100;while (1){key = key_scan(0);if (key == KEY1_PRES && (tp_dev.touchtype & 0X80) == 0){tp_adjust(); /* 屏幕校准 */lcd_clear(WHITE);goto RESTART; /* 重新加载界面 */}if (key == KEY0_PRES){lcd_fill(20, 115, 219, 314, WHITE); /* 清除当前显示 */mode++;if (mode > 4)mode = 1;switch (mode){case 1:text_show_string(80, 207, 200, 16, "仅识别数字", 16, 0, BLUE);break;case 2:text_show_string(64, 207, 200, 16,"仅识别大写字母",16, 0, BLUE);break;case 3:text_show_string(64, 207, 200, 16,"仅识别小写字母", 16, 0, BLUE);break;case 4:text_show_string(88, 207, 200, 16, "全部识别", 16, 0, BLUE);break;}tcnt = 100;}tp_dev.scan(0); /* 扫描 */if (tp_dev.sta & TP_PRES_DOWN) /* 有按键被按下 */{delay_ms(1); /* 必要的延时, 否则老认为有按键按下 */tcnt = 0; /* 松开时的计数器清空 */if ((tp_dev.x[0] < (lcddev.width - 20 - 2) &&
tp_dev.x[0] >= (20 + 2)) &&
(tp_dev.y[0] < (lcddev.height - 5 - 2) &&
tp_dev.y[0] >= (115 + 2))){if (lastpos[0] == 0XFFFF){lastpos[0] = tp_dev.x[0];lastpos[1] = tp_dev.y[0];}
/* 画线 */lcd_draw_bline(lastpos[0],lastpos[1],tp_dev.x[0],tp_dev.y[0],2,BLUE); lastpos[0] = tp_dev.x[0];lastpos[1] = tp_dev.y[0];if (pcnt < 200) /* 总点数少于200 */{if (pcnt){if((ncr_input_buf[pcnt - 1].y != tp_dev.y[0]) &&
(ncr_input_buf[pcnt - 1].x != tp_dev.x[0])) /* x,y不相等 */{ncr_input_buf[pcnt].x = tp_dev.x[0];ncr_input_buf[pcnt].y = tp_dev.y[0];pcnt++;}}else{ncr_input_buf[pcnt].x = tp_dev.x[0];ncr_input_buf[pcnt].y = tp_dev.y[0];pcnt++;}}}}else /* 按键松开了 */{lastpos[0] = 0XFFFF;tcnt++;delay_ms(10);/* 延时识别 */i++;if (tcnt == 40){if (pcnt) /* 有有效的输入 */{printf("总点数:%d\r\n", pcnt);alientek_ncr(ncr_input_buf, pcnt, 6, mode, sbuf);printf("识别结果:%s\r\n", sbuf);pcnt = 0; lcd_show_string(60 + 72, 90, 200, 16, 16, sbuf, BLUE);}lcd_fill(20,115,lcddev.width-20-1,lcddev.height-5-1,WHITE);}}if (i == 30){i = 0;LED0_TOGGLE();}}
}
main函数代码实现手写识别功能的步骤跟前面所说的一致的。其中使用到了lcd_draw_bline函数,该函数是用来画粗线的,函数的实现也是通过调用lcd_fill_circle实现,这里就不做展开讲解该函数了。在获取触点数据需要注意的是:这里我们采用的都是不重复的点阵(即相邻的坐标不相等)。这样可以避免重复数据,而重复的点阵数对于识别是没有帮助的。
57.4 下载验证
将程序下载到开发板后,可以看到LED0不停的闪烁,提示程序已经在运行了。LCD显示的内容如图57.4.1所示:

图57.4.1手写识别界面图
此时,我们在手写区写数字/字母,即可得到识别结果,如图57.4.2 所示:

图57.4.2 手写识别结果图
按下KEY0可以切换识别模式,同时在识别区提示当前模式。按下KEY1可以对屏幕进行校准(仅限电阻屏,电容屏无需校准)。每次识别结束,会在串口打印本次识别的输入点数和识别结果,大家可以通过串口助手查看。
这篇关于【正点原子STM32连载】 第五十五章 录音机实验摘自【正点原子】STM32F103 战舰开发指南V1.2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





