本文主要是介绍基于MTCNN+FaceNet的人脸检测与识别系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在整理出的上学期做的人脸识别复现,源码在git上改动不大。
Github链接:https://github.com/ALittleLeo/FaceRcognization/tree/master
引言
随着互联网技术的高速发展,互联网也进入了海量数据时代。在全球,每天约2EB的数据被产生。在各种类型的数据信息中,人脸数字图像数据是最重要的一种数据类型。所以越来越多的新型应用场景需要利用图像中的信息,而人脸图像数据作为一种直观高效的信息载体,包含了复杂多样的内容信息。
近年来,基于深度学习的OCR技术在人脸识别的精准度和效率上有着显著的提升。目前主流的人脸识别主要分为两个部分,即人脸检测和人脸识别。1)在人脸检测方面,目前在传统单一维度人脸检测有较为成熟的研究成果。纹理特征提取算法LBP对多维度人脸检测问题也有一定不错的效果。2)在人脸识别方面,主流的是CNN和transformer模型。此外仍有团队将Attention机制运用到人脸识别当中,强化了网络挖掘特征信息的能力。目前人脸识别的准确率仍然不高,本项目将在已有深度学习模型的基础上,使用MCTNN+facenet结合的方法,以能达到较好的识别效果。
人脸检测识别是人工智能领域中一项重要的关键技术,而深度学习是该技术兴起的研究热点,这项技术可提高人脸检测识别技术的精准性和数据的安全性。本文通过MCTNN+facenet的方法分析深度学习的检测技术原理,把该技术的各关键点有机结合起来,最终形成基于深度学习的人脸检测模技术。
MCTNN+facenet
MTCNN一个深度卷积多任务的框架,这个框架利用了检测和对准之间固有的关系来增强他们的性能。这里使用MTCNN进行人脸检测,一方面是因为其检测精度确实不错,另一方面facenet工程中,已经提供了用于人脸检测的mtcnn接口。MTCNN是多任务级联CNN的人脸检测深度学习模型,该模型中综合考虑了人脸边框回归和面部关键点检测。特别是,在预测人脸及脸部标记点的时候,通过3个CNN级联的方式对任务进行从粗到精的处理。
Stage 1:使用P-Net是一个全卷积网络,用来生成候选窗和边框回归向量(bounding box regression vectors)。使用Bounding box regression的方法来校正这些候选窗,使用非极大值抑制(NMS)合并重叠的候选框。全卷积网络和Faster R-CNN中的RPN一脉相承。
Stage 2:使用R-Net改善候选窗。将通过P-Net的候选窗输入R-Net中,拒绝掉大部分false的窗口,继续使用Bounding box regression和NMS合并。
Stage 3:最后使用O-Net输出最终的人脸框和特征点位置。和第二步类似,但是不同的是生成5个特征点位置。


实验结果
数据集分析
在本文采用AgeDB-30 (570 ids/12,240 images/6K pairs)跨年龄人脸识别数据集,AgeDB包含16,488个各种名人的图像,按照4:1的比例分为模型训练集和测试集。具体内容包括演员,作家,科学家,政治家,每个图像都注明了身份,年龄和性别属性。共存在568个不同的科目。 每个科目的平均图像数为29。最低和最高年龄分别为1和101。每个科目的平均年龄范围是50.3岁。
实验开发环境
本文实验开发环境为Intel i7-9750h,GPU为NVIDIA GTX1050
tensorflow-gpu 1.8.0
tensorflow-tensorboard 0.4.0
numpy 1.16.2
scipy 1.4.1
matplotlib 3.3.3
six 1.14.0
sklearn 0.0
实验结果及分析
系统实现流程:
1、建立人脸数据图库
2、搭建MTCNN网络
3、利用MTCNN网络把人脸数据图库转换为人脸特征库(embedding库)
4、使用MTCNN网络提取待检测的人脸图片的特征
5、使用facenet比较待识别的人脸和人脸库特征,绘制图片,得到最终结果
目录说明:
align文件夹中包含三个mtcnn要用到的模型文件,以及搭建mtcnn网络的文件 detect_face.py,这里面的东西在facenet的项目中的都可以找到
dataset文件夹中主要存放数据,包括images(人脸数据图库),emb(人脸特征库),test_images(测试图片)
models文件夹中存放facenet预训练模型
utils是工具类文件夹,用于文件读写,图片相关操作。
predict.py是进行人脸识别的入口
create_dataset.py用于将人脸数据图库转换为人脸特征库。
MTCNN由3个网络结构组成(P-Net,R-Net,O-Net)
facenet进行人脸识别
方法:facenet通过CNN将人脸映射到欧式空间的特征向量上,计算不同图片人脸特征的距离,通过相同个体人脸的距离总是小于不同个体 人脸·的距离这一先验知识训练网络(详细介绍后续补充)。
代码实现,运行predict.py。流程:加载人脸特征数据库,提取待识别的人脸的特征与人脸数据库中的信息逐一比较。

如图是实机实验的结果,可以看到在模型的训练过程中,胡歌和周杰伦的照片在人脸识别数据库里,人脸的特征保存在训练的模型之中,可以被检测(绿线框出)并被识别为胡歌和周杰伦(红色标注)。撒贝宁的照片虽然可以被检测为人像,但由于数据集中缺少照片未被训练而不能被识别。

模型测评,运行evaluation_test.py,该文件会绘制测试文件的ROC曲线,并给出最优阈值,以及利用用sklearn.metric得到FPR, TPR, AUC等参数。对数据集是agedb_30进行测试,该数据集共有12000张照片,分为6000对每对照片有一个label值为1或0用来表示两张图是否为一个人,是同一个为 True不同为False,通过该数据集测试结果,绘制当前模型的ROC曲线,可得roc_auc:0.8308236111111111,optimal_idx :1190,best_threshold :
1.1180874109268188,即由该阈值划分二分类效果最好。

人脸检测识别是一种通用识别技术,近些年已成为深度学习计算机视觉方向的研究热点。如今传统的人脸识别技术已经相对成熟,但多维度识别真人识别等人脸识别技术仍有提升的空间。本文实验利用MCTNN和facenet结合的方法进行实验,操作步骤简单,可行度高。实验测试图片来自已公开的训练集和网络,实验结果证明本文采用的方法适应性强,准确率较高。
传统LBP算法
LBP是一种纹理特征提取算法,LBP通过提取LBP算子来进行图像的检测和识别。
原始的LBP算子定义为在33的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若处于周围的像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。由此得到的33邻域内的8个点对比可得8位二进制数,再转化为十进制数类型即256中LBP码,通过计算可得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。如下图所示:
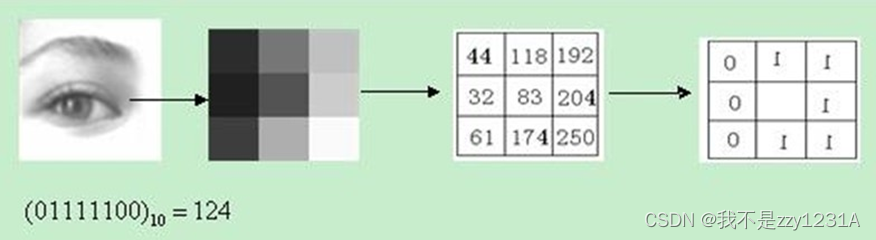
由 LBP 定义可得,LBP 算子只满足灰度不变而不满足旋转不变。经过旋转的图像会得到不同的 LBP值。为此Maenpaa等人将 LBP算子改进加以扩展,改进后的LBP是具有旋转不变性的 LBP算子,在不断旋转圆形邻域后计算得到一系列的初始定义 LBP值,在这些值中取其最小值作为该邻域的 LBP值。
LBP的主要应用领域是人脸识别分析和纹理分析等,LBP图谱一般不作为特征向量用于分类识别,取而代之的是由LBP特征谱生成的统计直方图,进而用于分类识别。
由上述可知,这个特征与图片的位置信息是紧密相关的。未经过预处理直接对两幅图片提取特征,并进行分析分类的话,会因为位置的偏差而产生较大的误差难以识别。经过研究人员改进后发现,将图片划分为若干的子区域,对每个子区域内的每个像素点都提取LBP特征,然后,在每个子区域内建立LBP特征的统计直方图。由此可将整个图片细化为多个子区域,每个子区域用一个统计直方图来进行描述;整个图片就由若干个统计直方图组成。
相关主流神经网络算法
目前的神经网络算法是一种非线性动力学系统,相比于传统的纹理特征检测算法具有良好的自组织、自适应能力。目前神经网络方法在人脸识别中的研究方兴未艾。Valentin提出一种方法,首先提取人脸的 50个主元,然后用自相关神经网络将它映射到 5维空间中,再用一个普通的多层感知器进行判别,对一些简单的测试图像效果较好;Intrator等提出了一种混合型神经网络来进行人脸识别,其中非监督神经网络用于特征提取,而监督神经网络用于分类。Lee等将人脸的特点用六条规则描述,然后根据这六条规则进行五官的定位,将五官之间的几何距离输入模糊神经网络进行识别,效果较一般的基于欧氏距离的方法有较大改善,Laurence等采用卷积神经网络方法进行人脸识别,由于卷积神经网络中集成了相邻像素之间的相关性知识,从而在一定程度上获得了对图像平移、旋转和局部变形的不变性,因此得到非常理想的识别结果,Lin等提出了基于概率决策的神经网络方法 (PDBNN),其主要思想是采用虚拟 (正反例 )样本进行强化和反强化学习,从而得到较为理想的概率估计结果,并采用模块化的网络结构 (OCON)加快网络的学习。这种方法在人脸检测、人脸定位和人脸识别的各个步骤上都得到了较好的应用,其它研究还有 :Dai等提出用Hopfield网络进行低分辨率人脸联想与识别,Gutta等提出将RBF与树型分类器结合起来进行人脸识别的混合分类器模型,Phillips等人将MatchingPursuit滤波器用于人脸识别,国内则采用统计学习理论中的支撑向量机进行人脸分类。
神经网络方法在人脸识别上的应用比起前述几类方法来有一定的优势,因为对人脸识别的许多规律或规则进行显性的描述是相当困难的,而神经网络方法则可以通过学习的过程获得对这些规律和规则的隐性表达,它的适应性更强,一般也比较容易实现。因此人工神经网络识别速度快,但识别率低 。而神经网络方法通常需要将人脸作为一个一维向量输入,因此输入节点庞大,其识别重要的一个目标就是降维处理。
结语
此次研究课题为人脸检测与识别,此课题在当今时代仍十分值得深入探讨的,就人脸检测方面在如今研究下的成果而言,计算机在此方面的应用仍具有一定的挑战性。基于多维度小样本的背景环境下,相比于传统人脸的检测与识别定会具备更多的干扰因素以及对于实验结果更强有力的影响。虽然存在着更高的难度,但不免存在更多有待考察和研究的思考空间,以及未来科技应用技术的发展方向。
此次研究中,通过自主实验进行数据的收集和结果的分析,重点以faster-R-CNN + CRNN模型结合的方法进行对人脸的深度学习。此次研究使我们对于此方面的知识具备更深刻的了解与认识,同时对于人脸检测的研究也有具备一些相关知识的基础和个人见解。最后,对在我们研究过程中为我们提出帮助的老师同学以及我们参考的文献的作者们致以感谢。
这篇关于基于MTCNN+FaceNet的人脸检测与识别系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







