本文主要是介绍语音转换之CycleGan-VC2:原理与实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
非平行语音转换CycleGAN
之前学习了传统统计学习里的经典的语音转换模型GMM。随着深度学习的发展,出现了更好的语音转换方法,今天学习较为经典的CycleGan。
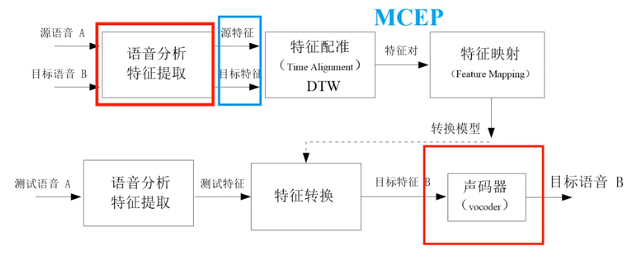
平行语音转换一般流程
典型代表就是基于GMM的语音转换。平行数据就是说源语音和目标语音一一对应,这里对应就是指每句话的内容必须一样。非平行数据就是说话内容无需完全一样。
所以,平行语音转换中最关键的就是特征配准(特征对齐),对齐效果好坏直接影响最终的转换效果。平行语音一般用DTW算法基于最小距离原则进行对齐。
特征映射模型总结
根据输入数据的类型,可将特征映射模型分为基于平行和非平行数据的模型。
基于平行数据
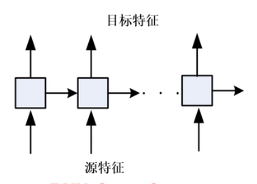
最早期使用基于规则的方法,后来引入概率统计模型,典型的如GMM,到现在深度学习的方法,主要基于神经网络。
-
DNN:帧到帧

-
RNN:帧到帧
-
seq-seq
基于非平行数据
-
通过切分、聚类,来设法构造并行数据
-
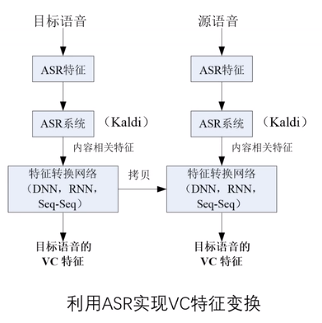
使用ASR系统,辅助VC。
提取与说话人无关的信息,构造这些信息与目标说话人之间的关联,在文本层级上进行对齐。
-
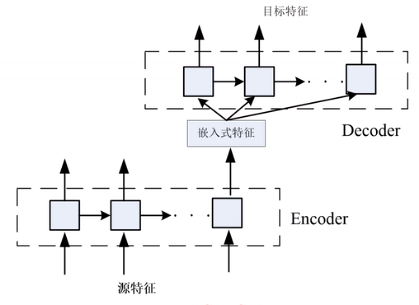
使用变分自编码VAE与竞争网络
Encoder可以看作特征降维。
对齐:让源特征和目标特征经过Encoder后,在浅变量概率分布层级上进行对齐。
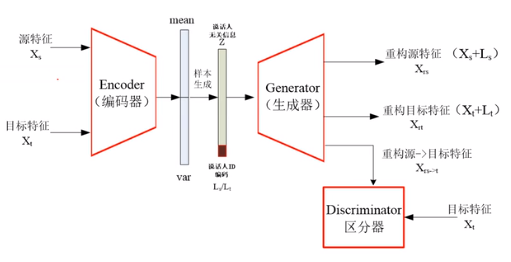
训练方法:
可以看到,这些非平行数据的VC算法中,还是离不开“对齐”操作。要么在音频特征切分后,在特征维度上进行对齐;要么利用ASR系统,在文本层级对齐;要么利用深度神经网络进行编码,在编码的潜变量或分布上进行对齐。
基于CycleGan的VC,真正意义上摆脱了“对齐”操作。
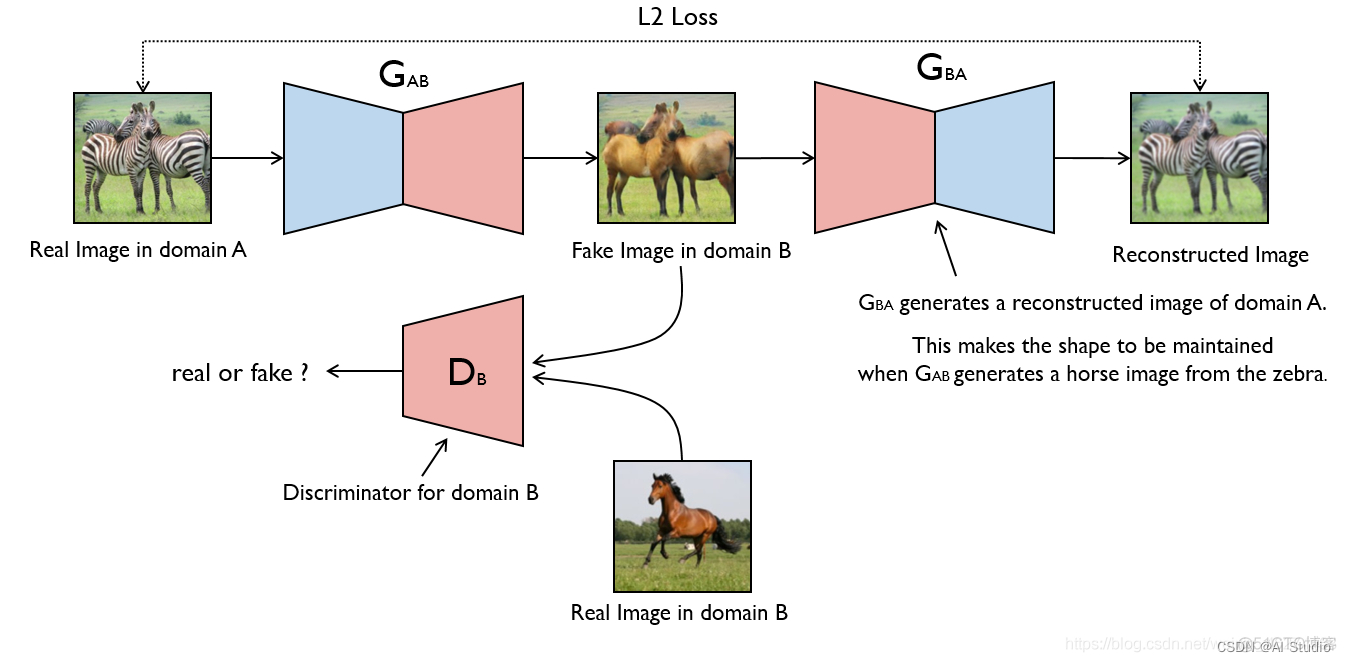
CycleGan最早用于图片风格转换。如下图CycleGAN 斑马与马转换。
2019年,有人将CycleGan用到语音转换,并作了一系列的工作。下面这篇是最经典的,第二代CycleGan-VC2,目前被引了两百多次了。

CycleGan-VC
Gan网络的原理,可以看这篇文章:GAN
下图是CycleGan结构图:
既可以A 到B,也可以B到A。
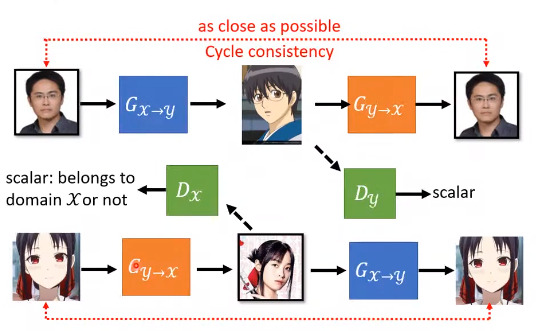
和上面图表达的类似,可以对比着看。
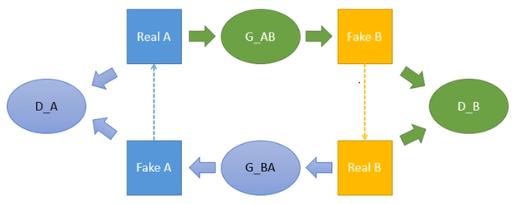
目标函数:
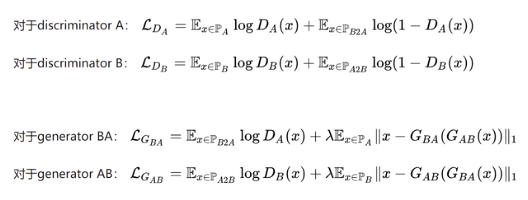
损失函数
1.对抗损失 Adversial loss
用来衡量如何区分由x生成的y和真实y
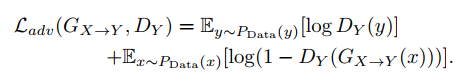
注意这个对抗损失是最大最小化,即训练G时,希望能骗过D,希望损失最小化;训练D时,希望D很厉害能识别生成的假数据,最大化损失。
2.循环不变性损失Cycle-consistency loss
用来保证GX-Y和GY-X得到(X,Y)对的文本内容相同。
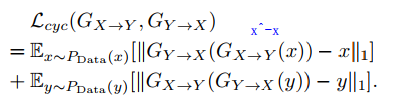
即循环一圈后生成的和原来的越相似越好。
CycleGan-VC2的改进,多了如下。
3.映射一致性损失Identity-mapping loss
Gx-y的网络应该输入x,希望生成y,现在直接就输入y,希望它能不变的输出y,为了保证模型只转换风格,不转换内容。
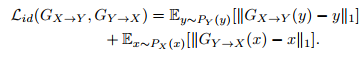
上面几个组成总目标函数:
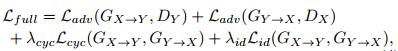
4.对抗损失2 Adversial loss2
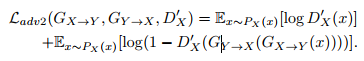
从下图可以看到,给生成的x又加了个判别器Dx。按理说刚才说的损失循环不变性损失Cycle-consistency loss,也就是下图的(a)已经能保证说话内容不变了,为什么还有这个损失函数?
因为Cycle-consistency loss中的L1范式的度量仍然会导致过平滑,为了减轻这种负面影响才提出这个损失函数。
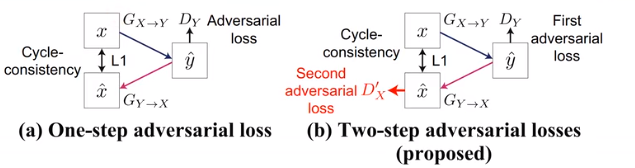
实际使用中不需要重新建一个Dx,用已有的Dx就行。
总结上面4个损失函数:
1是为了输出的语音是一句目标语音的人的声音,而不是其他声音,至于说的内容它无法约束。
2和3损失就是为了保证说的内容和原说话人一致,如源说话人说你好,转换后也得内容是你好。
4是为了缓解过平滑,让循环一圈以后的声音仍和原声更接近。
为了损失函数更直观,把上面的这几个损失函数进行了规整,统一成min的,loss最小。
1.对抗损失 Adversial loss

2.循环不变性损失Cycle-consistency loss

3.映射一致性损失Identity-mapping loss
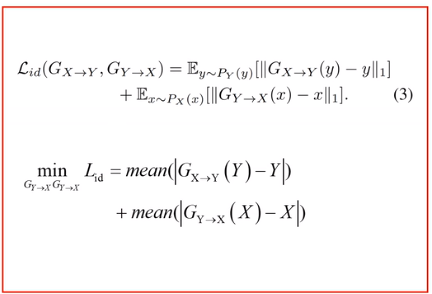
4.对抗损失2 Adversial loss2

网路结构
生成器G: 输入source的MCEP特征,输出改变音色的MCEP特征。
生成器使用1DCNN,以捕获总体特征之间的关系,同时保留时间结构。同时使用了下采样层,残差层和上采样层,以及Instance Normalization。
这里用到了门控CNN,模拟lstm的是否遗忘门,或者说判断权重的思想。再做一个和CNN卷积一样参数的filter, 取值0-1,判断这个序列的特征哪些应该被关注,哪些应该被忽略。在门控CNN中,门控线性单元(GLUs)被用作一个激活函数,GLU是一个数据驱动的激活函数,并且门控机制允许根据先前的层状态选择性地传播信息。

鉴别器D: 输入音频的MCEP等特征,进行二分类,输出是否经过转换
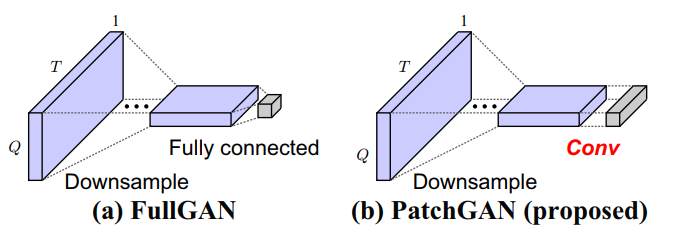
使用2D CNN鉴别器来基于2D频谱纹理鉴别数据。使用具有完全连接层作为最后一层的FullGAN,以根据整体输入结构来区分数据。
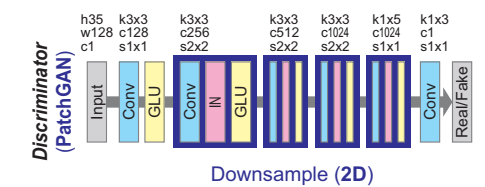
注意里面结构PatchGAN:
一般D输出就是一维的,PatchGAN就是输出多维,就还是1-x,取平均。
代码实现
在GitHub上就有官方代码:CycleGAN-VC2
里面data文件夹有两个人的语音,可以分别新建train和test文件夹,把数据分来。
一般工程代码主要包含下面部分:

相关参数
hparams.py:超参数
class hparams():def __init__(self):# 数据缓存self.train_dir_A = "data/S0913/train"self.train_dir_B = "data/gaoxiaosong/train"self.catch_A = "catch/train_A"self.catch_B = "catch/train_B"self.n_frames =128# 特征提取相关self.fs = 16000 # 采样率 self.frame_period = 5.0 # 帧移self.coded_dim = 36 # mcep 特征维度 # 训练相关参数self.g_lr = 2e-4self.d_lr = 1e-4self.train_steps = 2e4# learing rate 衰减self.start_decay = 1e4self.decay_G = self.g_lr/2e5self.decay_D = self.d_lr/2e5# 丢失 identity_lossself.step_drop_identity = 1e4# lamdaself.identity_loss_lambda = 10self.cycle_loss_lambda = 5#每个 step_log 进行一次保存self.step_save = 2000# 模型保存路径self.path_save = 'save'
数据预处理
提取语音常见特征:F0、MCEP(这里编码成coded-sp)、ap
import numpy as np
import pyworld
import glob
from hparams import hparams
import librosa
import os# 用world声码器特征提取
def feature_world(wav,para):fs = para.fswav = wav.astype(np.float64)f0, timeaxis = pyworld.harvest(wav, fs, frame_period=para.frame_period, f0_floor=71.0, f0_ceil=800.0)sp = pyworld.cheaptrick(wav, f0, timeaxis, fs)ap = pyworld.d4c(wav, f0, timeaxis, fs)coded_sp =pyworld.code_spectral_envelope(sp, fs, para.coded_dim)return f0,timeaxis,sp,ap,coded_sp# 信号正则
def wav_normlize(wav):max_ = np.max(wav)min_ = np.min(wav)wav_norm = wav*(2/(max_ - min_)) - (max_+min_)/(max_-min_)return wav_norm# 处理文件夹中的每条语音
def processing_wavs(file_wavs,para):f0s = []coded_sps = []for file in file_wavs:print("processing %s"%(file))fs = para.fswav, _ = librosa.load(file, sr=fs, mono=True)wav = wav_normlize(wav)# 提取特征f0和coded_spf0,_,_,_,coded_sp=feature_world(wav,para)print(coded_sp.shape)f0s.append(f0)coded_sps.append(coded_sp)# 计算log_f0的 均值和stdlog_f0s = np.ma.log(np.concatenate(f0s))log_f0s_mean = log_f0s.mean()log_f0s_std = log_f0s.std()# 计算 coded_sp 的均值和 标准差coded_sps_array = np.concatenate(coded_sps,axis=0) # coded_sp的维度 T * Dcoded_sps_mean = np.mean(coded_sps_array,axis=0,keepdims = True)coded_sps_std = np.std(coded_sps_array,axis=0,keepdims = True)# 利用 coded_sp 的均值和 标准差 对特征进行正则coded_sps_norm = []for coded_sp in coded_sps:coded_sps_norm.append( (coded_sp- coded_sps_mean)/ coded_sps_std )return log_f0s_mean,log_f0s_std,coded_sps_mean,coded_sps_std,coded_sps_normif __name__ == "__main__":para = hparams()# 提取说话人A的特征dir_train_A = para.train_dir_Awavs = glob.glob(dir_train_A+'/*wav') f0_mean,f0_std,mecp_mean,mecp_std, mecps = processing_wavs(wavs,para)os.makedirs(para.catch_A,exist_ok = True)np.save(os.path.join(para.catch_A,'static_f0.npy'),np.array([f0_mean,f0_std],dtype=object))np.save(os.path.join(para.catch_A,'static_mecp.npy'),np.array([mecp_mean,mecp_std],dtype=object))np.save(os.path.join(para.catch_A,'data.npy'),np.array(mecps,dtype=object))# 提取说话人B的特征dir_train_B = para.train_dir_Bwavs = glob.glob(dir_train_B+'/*wav')f0_mean,f0_std,mecp_mean,mecp_std, mecps = processing_wavs(wavs,para)os.makedirs(para.catch_B,exist_ok = True)np.save(os.path.join(para.catch_B,'static_f0.npy'),np.array([f0_mean,f0_std],dtype=object))np.save(os.path.join(para.catch_B,'static_mecp.npy'),np.array([mecp_mean,mecp_std],dtype = object))np.save(os.path.join(para.catch_B,'data.npy'),np.array(mecps,dtype=object))
构造Dataloader
import os
import torch
import numpy as np
from torch.utils.data import Dataset,DataLoader
from hparams import hparamsclass VC_Dataset(Dataset):def __init__(self,para):self.path_A = para.catch_Aself.path_B = para.catch_Bself.n_frames = para.n_frames# 加载数据self.train_A = np.load(os.path.join(self.path_A,'data.npy'),allow_pickle=True).tolist()self.train_B = np.load(os.path.join(self.path_B,'data.npy'),allow_pickle=True).tolist()self.n_samples = min(len(self.train_A),len(self.train_B))# 生成随机数据对self.gen_random_pair_index()def gen_random_pair_index(self):train_data_A_idx = np.arange(len(self.train_A))train_data_B_idx = np.arange(len(self.train_B))np.random.shuffle(train_data_A_idx)np.random.shuffle(train_data_B_idx)train_data_A_idx_subset = train_data_A_idx[:self.n_samples].tolist()train_data_B_idx_subset = train_data_B_idx[:self.n_samples].tolist()self.index_pairs = [(i,j) for i,j in zip(train_data_A_idx_subset,train_data_B_idx_subset)]def __len__(self):return len(self.index_pairs)def __getitem__(self,idx):# 读取 A 和 B 的数据data_A = self.train_A[self.index_pairs[idx][0]]data_B = self.train_B[self.index_pairs[idx][1]]# 从 A 和 B 中 随机截取 n_frames 帧start_A = np.random.randint(len(data_A) - self.n_frames + 1)sub_data_A = data_A[start_A:start_A + self.n_frames]start_B = np.random.randint(len(data_B) - self.n_frames + 1)sub_data_B = data_B[start_B :start_B + self.n_frames]return torch.from_numpy(sub_data_A.T),torch.from_numpy(sub_data_B.T)if __name__ == "__main__":para = hparams()m_Dataset= VC_Dataset(para)m_DataLoader = DataLoader(m_Dataset,batch_size = 2,shuffle = True, num_workers = 2)m_Dataset.gen_random_pair_index()for n_epoch in range(3):for i_batch, sample_batch in enumerate(m_DataLoader):train_A = sample_batch[0]train_B = sample_batch[1]print(train_A.shape)print(train_B.shape)if i_batch>5:breakm_Dataset.gen_random_pair_index()
其他代码太多就不一一列出来了
这篇关于语音转换之CycleGan-VC2:原理与实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





