本文主要是介绍软信天成:医药企业数据整合难、共享难?这套企业级数据治理体系是关键,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在数字化时代,数据已成为企业发展的核心资产。然而,对于拥有十余个业务系统的某大型国有医药企业(下文简称案例企业)来说,数据整合难、共享难等问题却一直存在。面对庞杂的数据来源和多样化的数据格式,传统的数据处理方法已经无法满足企业的需求。为了解决这一痛点,软信天成与案例企业携手合作,共同构建了一套全面、高效的企业级数据治理体系,让数据不再成为阻碍企业发展的绊脚石。

一、项目背景
在长达数十年的信息化建设进程中案例企业陆续针对原有业务系统进行了全面重构。企业内部共设置了十余个业务系统,包括ERP系统、批发系统、零售系统和物流系统等,繁杂且相互独立的业务系统让原有的数据采集体系和数据中心架构的短板日渐凸显,主要表现在以下两方面:
- 缺乏集团层面的数据标准,影响集团信息存储、传递、共享和利用水平。
- 业务系统繁多且数据存储和访问方式各不相同,原有的体系和架构难以将数据整合,数据价值变为空谈。
上述问题表明,案例企业急需加强数据高质量治理,构建企业级数据治理体系:对集团内外部的各类信息系统和数据进行集中处理和管理,多方位实现数据共享,为企业商务智能及后期基于集团数据中心扩展的各类应用分析及数据挖掘奠定坚实基础。
二、项目内容
1、制定数据治理咨询方案,推进标准体系建设
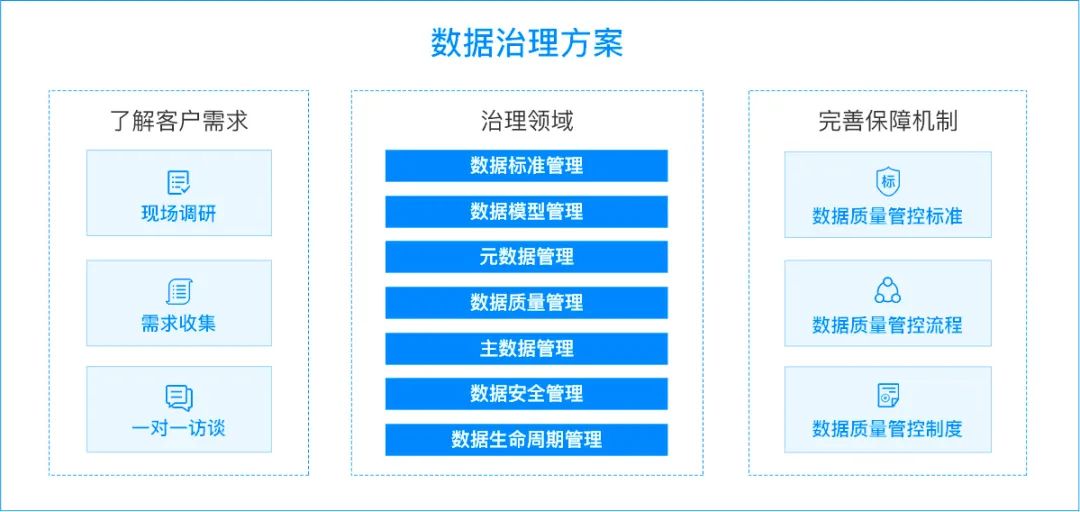
软信天成聚焦数据治理体系中数据标准管理、数据模型管理、元数据管理、数据质量管理、主数据管理、数据安全管理、数据生命周期管理七个重点领域,采用现场调研、需求收集、一对一访谈等多种形式了解案例客户。针对案例企业数据治理现状进行详细调研,并基于调研结果完成以下内容:
- 梳理出数据治理的整体思路,形成框架式规范;
- 贯穿整个数据集成过程,建立初步的数据质量管控标准、流程和管理制度;
- 结合规划的数据治理框架,制定数据治理的蓝图与实施路径。
2、打造企业数据集成平台,统一管控数据资产
作为一家立足医药商业、医药研发协同发展的大型国有企业,案例企业拥有100多家遍布各地的全级次分子公司,各个省份的营销中心生产库需要频繁与集团进行实时数据共享。对于他们而言,构建统一的企业级数据集成平台,完成集团内部数据处理以及对外数据交换场景的全覆盖,确保企业内、外部数据与第三方合作伙伴的无缝数据对接需求显得尤为关键。
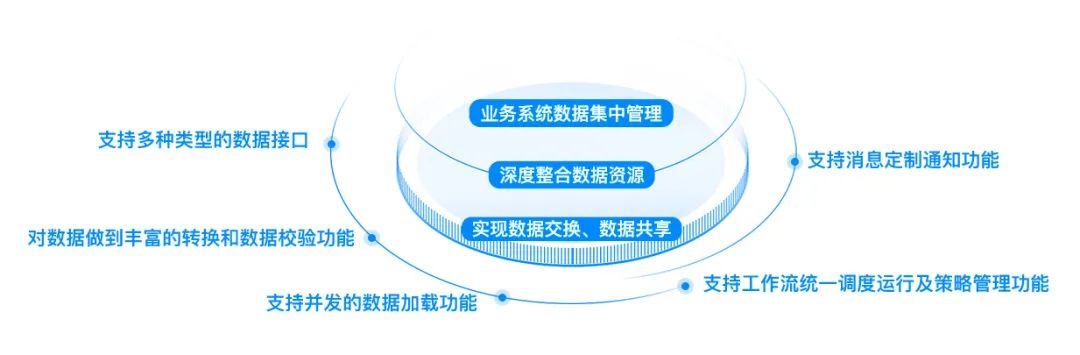
由于案例企业旗下营销中心生产库数量众多且分散在全国各地,因此本次数据集成项目需要对几百个数据源端库进行集成,项目难度陡然上升。
- 大量数据源端库导致传统服务器压力剧增,开发工程量繁重,mapping、数据抽取等难度加剧,需要进行数据实时同步的数据库高达上百个。
- 集团IT信息化建设相对落后,尤其是西藏、新疆等偏远地区网络资源不足严重影响数据抽取进程,带宽限制导致实时性数据抽取问题。
鉴于以上问题,软信天成对数据集成方案进行优化与升级,将偏远、交易量低的地区(如西藏、新疆等地)的同步方案改为定时更新,整体采用实时同步与小部分定时同步相结合的方式进行项目的落地实施。
三、项目成果
实现数据整合与共享:通过构建企业级数据治理体系,搭建数据集成平台,彻底解决集团内部的数据整合难、共享难的问题。
推进标准化数据建设:完善企业信息管理流程并统一数据标准,以推进标准化体系建设,提高数据资产利用率。
集团级统一数据视图:建立企业级客户、商品、订单等统一数据视图,以数据贯通业务流程,帮助企业更好的满足客户服务需求。
自定义报表数据分析:允许高级业务用户对制定主题、指标进行自定义灵活分析(包括自定义查询、报表以及多维旋转和穿透钻取等)。
企业数据可视化展示:赋予管理决策者信息访问权限,为其提供专属的系统资源,打造直观、便捷的存取界面。
全面提高企业协同效率:推进案例企业整体网络资源环境的优化进程,兼顾网络性能与企业成本,全面提高终端药品连锁机构与内部业务系统的协同效率。
最终,在软信天成和案例企业的共同努力下,案例企业顺利构建企业级数据治理体系,实现数据集成项目的落地,为后续更多商业智能分析和企业数字化营销转型提供底层支撑。
这篇关于软信天成:医药企业数据整合难、共享难?这套企业级数据治理体系是关键的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







