本文主要是介绍【手把手AI项目】四、Caffe_ssd安装以及利用VOC2012,VOC2007数据集测试VGG_SSD网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
安装caffe_ssd
前提:
- linux双系统
- 原生caffe安装配置
caffe_ssd:https://github.com/weiliu89/caffe/tree/ssd
git clone https://github.com/weiliu89/caffe.git
cd caffe
git checkout ssd #这句一定要有,相当于从origin转到一个tree去可以理解为转到这个仓库的一个新的分支当中去,这个才是真正的caffe_ssd 所以这也就是网址和 git clone 网址不一样的原因,因为需要转分支
之后的编译过程和我另外一篇博文完全一致,出现error解决方式在文章下方和过程中都有提到 https://blog.csdn.net/qq_33431368/article/details/84717053
sudo make all -j8 可能出现error
 解决办法
解决办法
修改Makefile ,line181 加入boost_regex,如下图
 成功编译
成功编译
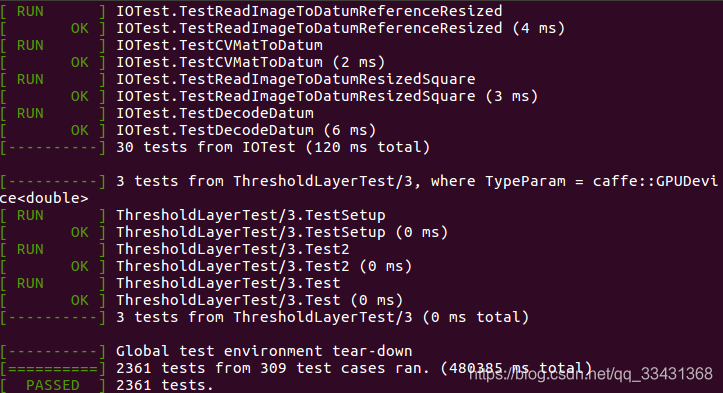
sudo make pycaffe -j8
下载数据集VOC2012 2007进行测试caffe_ssd(VGGnet)
下载预训练模型 https://gist.github.com/weiliu89/2ed6e13bfd5b57cf81d6
如果进不去,刷不出来网页,不要着急因为需要vpn才可以 参考以下这篇文章
如何在Ubuntu16.04访问国外网站——lantern2018-07-16
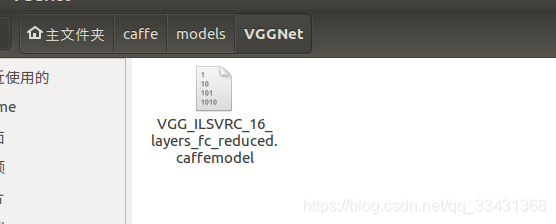
最后将model放到
$CAFFE_ROOT/models/VGGNet/
如下图我的放置所示
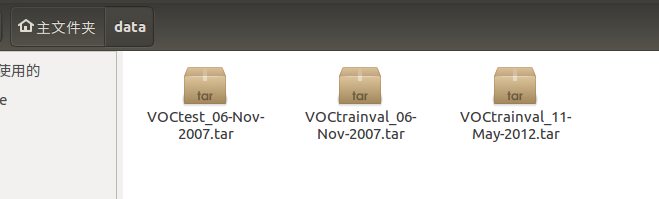
下载dataset VOC2012 VOC2007
cd $HOME/data #在自己的home下新建一个data 文件夹
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
如下图所示
下载步骤也可以在以下网站完成:
https://pjreddie.com/projects/pascal-voc-dataset-mirror/

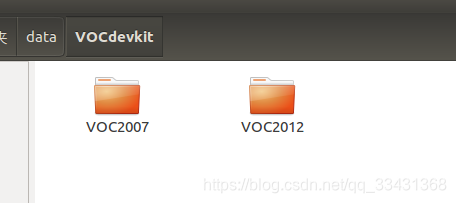
解压
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
之后把VOC格式转换为caffe输入的lmdb格式
cd caffe
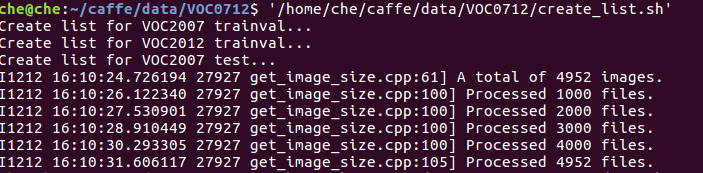
./data/VOC0712/create_list.sh
./data/VOC0712/create_data.sh
执行两个shell文件,生成train_list test_list文件以及进一步生成lmdb格式文件

cd caffe #一定要先cd 到caffe的根目录下再执行程序才能成功
python examples/ssd/ssd_pascal.py
直接执行会出现以下问题(具体因为./build/tools/caffe train的路径为caffe_ssd当前目录下的路径)

执行开始后可能出现error:
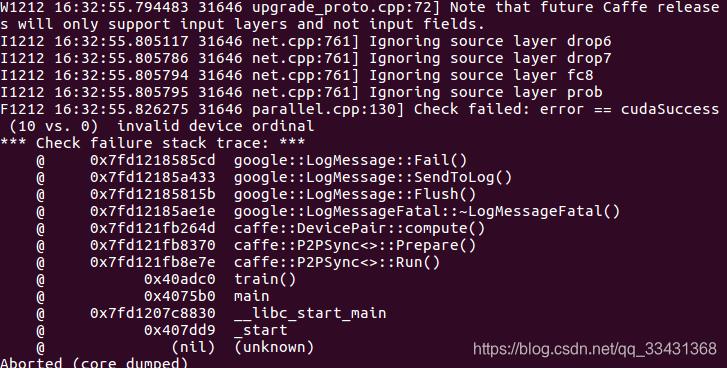
解决办法
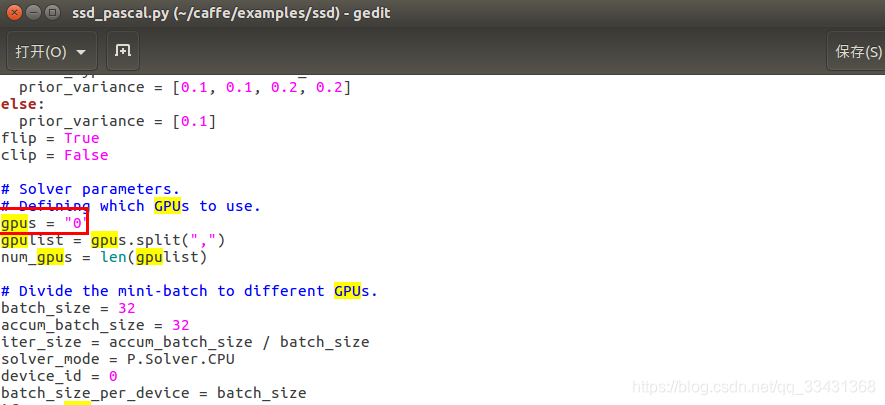
根据你的显卡个数来定义GPU的参数
我这里只有一个1060ti所以参数改为如下所示,在ssd_pascal.py 中改为 gpus = “0”

如果CPU则直接删掉,GPU为一块显卡则为 “0”,以此列推 三块显卡为"0,1,2"
我只有一块显卡 改为如下图:
但是可能还会有这些错误,如果是1080ti可能不会存在
F1212 16:38:34.863675 32735 syncedmem.cpp:56] Check failed: error == cudaSuccess (2 vs. 0) out of memory
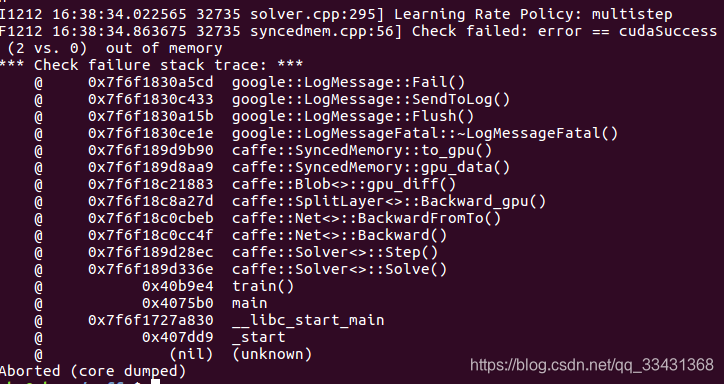
解释一下,这是常见错误,就是显卡内存不够,所以batchsize 改小就好了。
找到ssd_pascal.py里面的batchsize处更改即可,改为32,不行的话就继续修改为16,或者8,甚至为4。

训练成功
 会发现随着迭代次数的增加,整个loss是不断减小的,直到趋于平稳。
会发现随着迭代次数的增加,整个loss是不断减小的,直到趋于平稳。
如果你没有时间这边作者有自己训练好的下载测试一下美滋滋
https://drive.google.com/file/d/0BzKzrI_SkD1_WVVTSmQxU0dVRzA/view
下载解压,解压之后其实是个整体文件有网络结构文件prototxt文件,caffemodel,两个python文件,直接覆盖之前的VGGnet即可
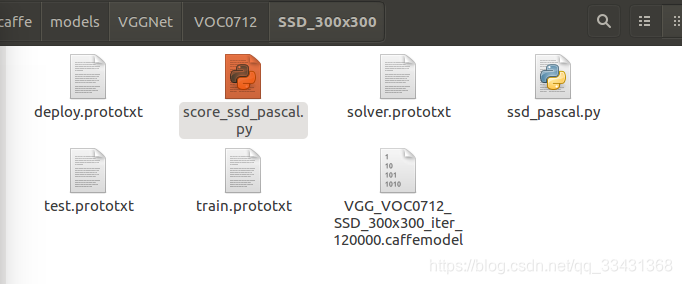
文件情况如上图所示,caffemodel为input为300*300d迭代12000次的训练的caffemodel
执行
cd caffe
python models/VGGNet/VOC0712/SSD_300x300/score_ssd_pascal.py
这边用 examples/ssd/score_ssd_pascal.py也可以一样的,只是下载打包顺便用了,如果自己训练出了模型,不下载直接运行这个py文件也ok
 打开摄像头走一波
打开摄像头走一波
cd caffe
python examples/ssd/ssd_pascal_webcam.py

PC机上很快, 博主就不露脸了,长得丑 ,截图放出来三分之一能看到label和acc以及FPS即可
Reference
https://blog.csdn.net/zhang_shuai12/article/details/52346878
https://blog.csdn.net/yx2017/article/details/72870565
https://blog.csdn.net/QLULIBIN/article/details/81810501
这篇关于【手把手AI项目】四、Caffe_ssd安装以及利用VOC2012,VOC2007数据集测试VGG_SSD网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







