本文主要是介绍深度模型笔记03 DeepFM原理与应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深度模型笔记03 DeepFM原理与应用
引言:本节需要先了解关于FM和Deep的一些知识,学习链接参考:datawhale
1. DeepFM网络结构和原理
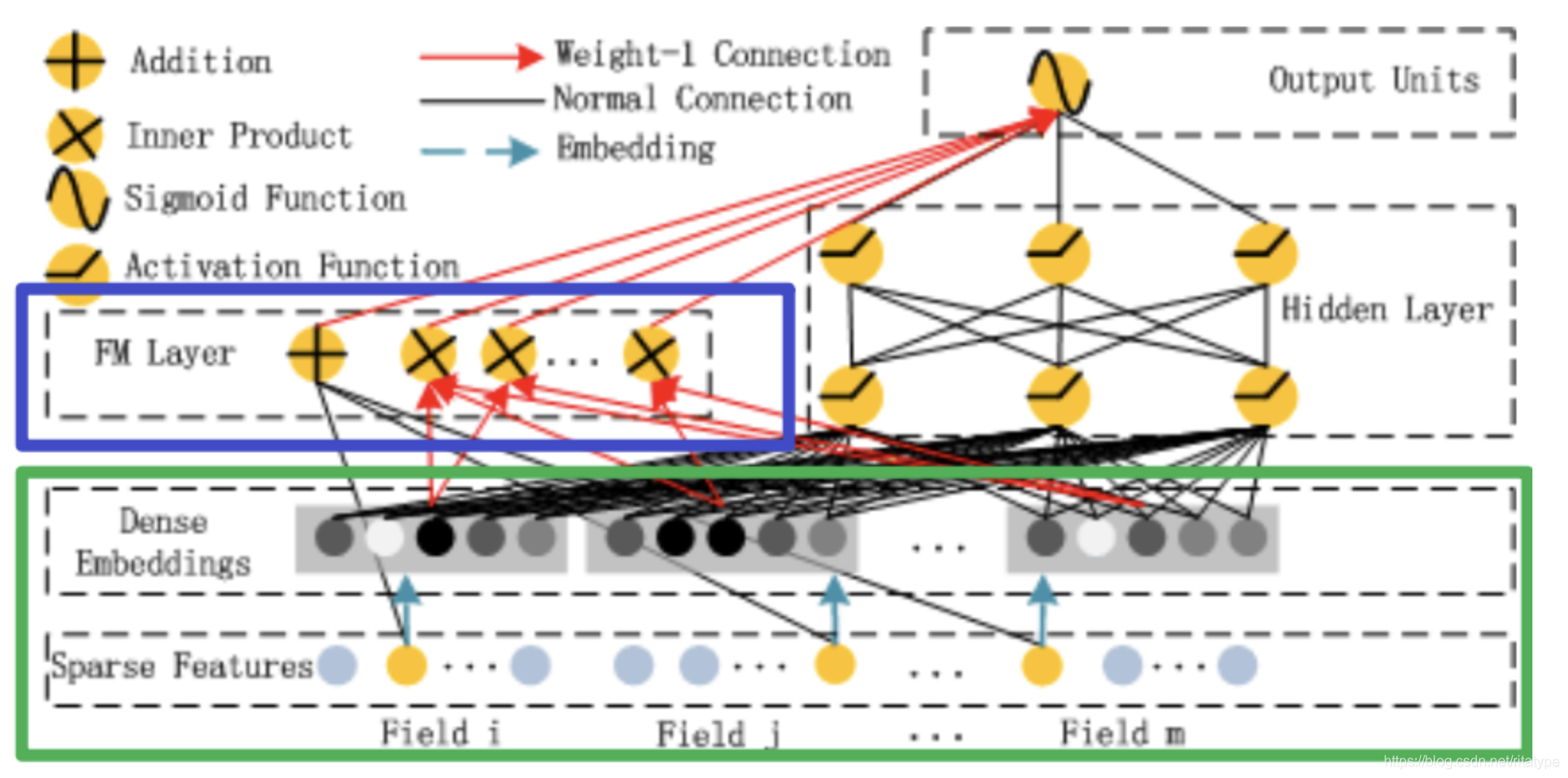
简单来说,DeepFM模型由Deep模型和FM模型的输出通过一个sigmoid函数获得。
y = s i g m o i d ( y F M + y D N N ) y=sigmoid(y_FM+y_DNN) y=sigmoid(yFM+yDNN)
- FM:一阶特征部分与二阶特征交叉部分组成
- DNN:高阶特征交叉
在构建模型的时候需要分别对这三部分输入的特征进行选择。
1.1 采用随机梯度下降SGD训练FM
FM模型公式如下:
y ( x ) = w 0 + ∑ i = 1 d w i x i + 1 / 2 ∑ f = 1 k ( ( ∑ i = 1 d v i , f x i ) 2 − ∑ i = 1 d v i , f 2 x i 2 ) y(x)=w_0+\sum_{i=1}^dw_ix_i+1/2\sum_{f=1}^k((\sum_{i=1}^dv_{i,f}x_i)^2-\sum_{i=1}^dv_{i,f}^2x_i^2) y(x)=w0+∑i=1dwixi+1/2∑f=1k((∑i=1dvi,fxi)2−∑i=1dvi,f2xi2)
当FM使用梯度下降法进行学习时,模型的梯度为:
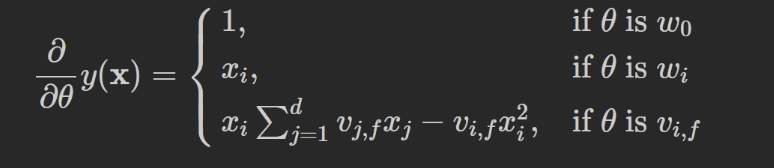 式中, ∑ j = 1 d v i , j x j \sum_{j=1}^dv_{i,j}x_j ∑j=1dvi,jxj只与f有关而与I无关,在每次迭代过程中,可以预先对所有f的 ∑ j = 1 d v i , j x j \sum_{j=1}^dv_{i,j}x_j ∑j=1dvi,jxj进行计算,复杂度 O ( k d ) O(kd) O(kd),就能在常数时间 O ( 1 ) O(1) O(1)内得到 v i , f v_{i,f} vi,f的梯度。而对于其他参数的 w 0 w_0 w0和 w i w_i wi,也是在常数时间里计算梯度。此外,更新参数只需要 O ( 1 ) O(1) O(1),一共有 1 + d + k d 1+d+kd 1+d+kd个参数,因此FM参数训练的复杂度也是 O ( k d ) O(kd) O(kd)。
式中, ∑ j = 1 d v i , j x j \sum_{j=1}^dv_{i,j}x_j ∑j=1dvi,jxj只与f有关而与I无关,在每次迭代过程中,可以预先对所有f的 ∑ j = 1 d v i , j x j \sum_{j=1}^dv_{i,j}x_j ∑j=1dvi,jxj进行计算,复杂度 O ( k d ) O(kd) O(kd),就能在常数时间 O ( 1 ) O(1) O(1)内得到 v i , f v_{i,f} vi,f的梯度。而对于其他参数的 w 0 w_0 w0和 w i w_i wi,也是在常数时间里计算梯度。此外,更新参数只需要 O ( 1 ) O(1) O(1),一共有 1 + d + k d 1+d+kd 1+d+kd个参数,因此FM参数训练的复杂度也是 O ( k d ) O(kd) O(kd)。
1.2 关于Sparse Feature中不同颜色节点代表的含义
- 灰色节点
- 黄色节点
Sparse Feature层总共有M个field,每个field对应k个嵌入维数,而在由输入得到embedding Vector的过程中,需要考虑同一个field位置下0、1的个数。一般对于输入的一条记录,同一个field只有一个位置是1,也就是黄色节点代表的含义。对应的,灰色节点代表的是0的含义。
2.具体构造代码如下:
def DeepFM(linear_feature_columns, dnn_feature_columns):# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embeddinglinear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logitslinear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型# embedding层用户构建FM交叉部分和DNN的输入部分embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)# 将输入到dnn中的所有sparse特征筛选出来dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))fm_logits = get_fm_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers) # 只考虑二阶项# 将所有的Embedding都拼起来,一起输入到dnn中dnn_logits = get_dnn_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)# 将linear,FM,dnn的logits相加作为最终的logitsoutput_logits = Add()([linear_logits, fm_logits, dnn_logits])# 这里的激活函数使用sigmoidoutput_layers = Activation("sigmoid")(output_logits)model = Model(input_layers, output_layers)return model
这篇关于深度模型笔记03 DeepFM原理与应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




