本文主要是介绍计算机数据存储与读取原理,读写存储器RAM-微计算机原理-电子发烧友网站,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第三节 读写存储器RAM
本节内容:
一、 基本存储电路
二、 RAM的结构
三、 典型RAM芯片举例
四、 RAM与CPU的连接
§5.3.1 基本存储电路
一个基本存储电路存储一位二进制信息0或1。它是存储器的核心。
1、SRAM基本存储电路
SRAM的基本存储电路的核心是MOS管构成的双稳态触发器。

MOS(场效应)管的工作特性如左图所示。
MOS管构成的双稳态触发器:
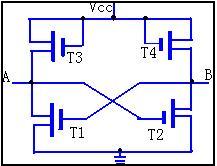
T3、T4的g、s端连在一起,vgs=0,d、s呈现高阻,该大电阻作为负载。 双稳态触发器有两个稳定状态:
① 若T1导通,A=0,使T2截止,B=1,B=1又保证T1导通。该状态表示存储信息0。(A=0)。
② 若T1截止,A=1,使T2导通,B=0,B=0又保证T1截止。该状态表示存储信息1。(A=1)。
为了将信息0/1写入或读出触发器,就需要加控制电路。加入控制电路的基本存储单元如下图:
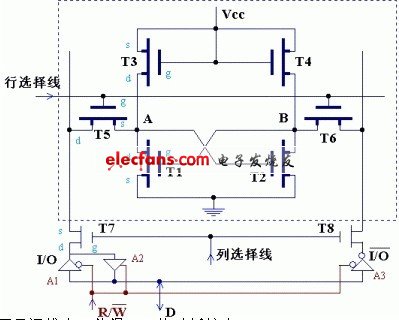
写操作:CPU送出地址信号、数据信号D和写入信号R/W=0。地址信号分成行地址和列地址,行地址经"行选择译码"产生行选择线信号,使该基本存储电路被选中,T5、T6导通;列地址经"列选择译码"产生列选择线信号,使T7、T8导通。R/W=0,三态缓冲器A1、A3导通,A2禁止,数据信号D经A1、A3、T7、T8、T5、T6进入该基本存储电路。
如写入1,则I/O=1、I/O=0,它们使A=1、B=0,T1截止、T2导通,即数据1被写入。
如写入0,则I/O=0、I/O=0,它们使A=0、B=1,T1导通、T2截止,即数据0被写入。
在写入完成后,地址信号消失,T5、T6、T7、T8截止,双稳态电路保持写入的信息不变。或者说,写入过程相当于将输入电荷存储到T1、T2的栅极上。在写入信号和选择信号消失后,两个作为负载电阻的T3、T4和电源Vcc相连,从而可以不断地往T1、T2的栅极补充电荷(T3给T2、T4给T1补充),加上T1、T2互相控制,能够保持住所写入的数据。
读操作:CPU送出地址信号,R/W=1。T5、T6、T7、T8导通,R/W=1,三态缓冲器A2导通,A1、A3禁止,基本存储电路A点状态经T5、T7、A2送至数据线D。A=1表示D=1,A=0表示D=0。在读出后,基本存储电路的状态不发生变化,即读操作是非破坏性的。
SRAM的特点:
(1) 采用CMOS电路构成,读出/写入速度快(5~15ns)。
(2) 所用管子数目多,单个器件的容量小,如256×4,16Kb×1,64Kb×8。
(3) T1、T2总有一个处于导通状态,使得SRAM的功耗较大。
2、 DRAM基本存储电路(单管DRAM基本存储电路)
数据以电荷形式存在电容C上,当C上有电荷,表示信息1;当C上无电荷,表示信息0。
写操作时,"行选择信号"为1,Q导通,若"列选择信号"为1,该基本存储电路被选中,由"数据输入/输出线"送来的信息通过刷新放大器和Q管送入到电容C。
读操作时,"行选择信号"为高电平,使存储矩阵中该行的所有基本存储电路的Q管导通,"刷新放大器"读取对应电容C上的电压值,刷新放大器的灵敏度很高,放大倍数很大,并且能将从电容上读得的电压值折合为逻辑"0"或逻辑"1"。"
这篇关于计算机数据存储与读取原理,读写存储器RAM-微计算机原理-电子发烧友网站的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





