本文主要是介绍数据科学最佳实践:Kedro 的工程化解决方案 | 开源日报 No.47,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

leonardomso/33-js-concepts
Stars: 58.4k License: MIT

这个项目是一个帮助开发者掌握 JavaScript 概念的资源库。该项目基于 Stephen Curtis 撰写的一篇文章,包含了对 33 个重要 JavaScript 概念全面深入地讲解,并被 GitHub 评为 2018 年最佳开源项目之一。
denysdovhan/wtfjs
Stars: 32.1k License: WTFPL

这个项目是一个有趣的 JavaScript 示例列表,主要功能是收集一些棘手的例子并解释它们如何工作。该项目可以帮助初学者更深入地了解 JavaScript,并为专业开发人员提供参考。核心优势和关键特点包括:
- 收集有趣且棘手的 JavaScript 示例
- 解释每个示例背后的原理和逻辑
- 提供对 ECMAScript 规范中相关部分链接以便进一步阅读
TheAlgorithms/JavaScript
Stars: 28.4k License: GPL-3.0

这个项目是 TheAlgorithms 的 JavaScript 仓库,使用 JavaScript 实现了各种算法和数据结构。
kedro-org/kedro
Stars: 8.8k License: Apache-2.0
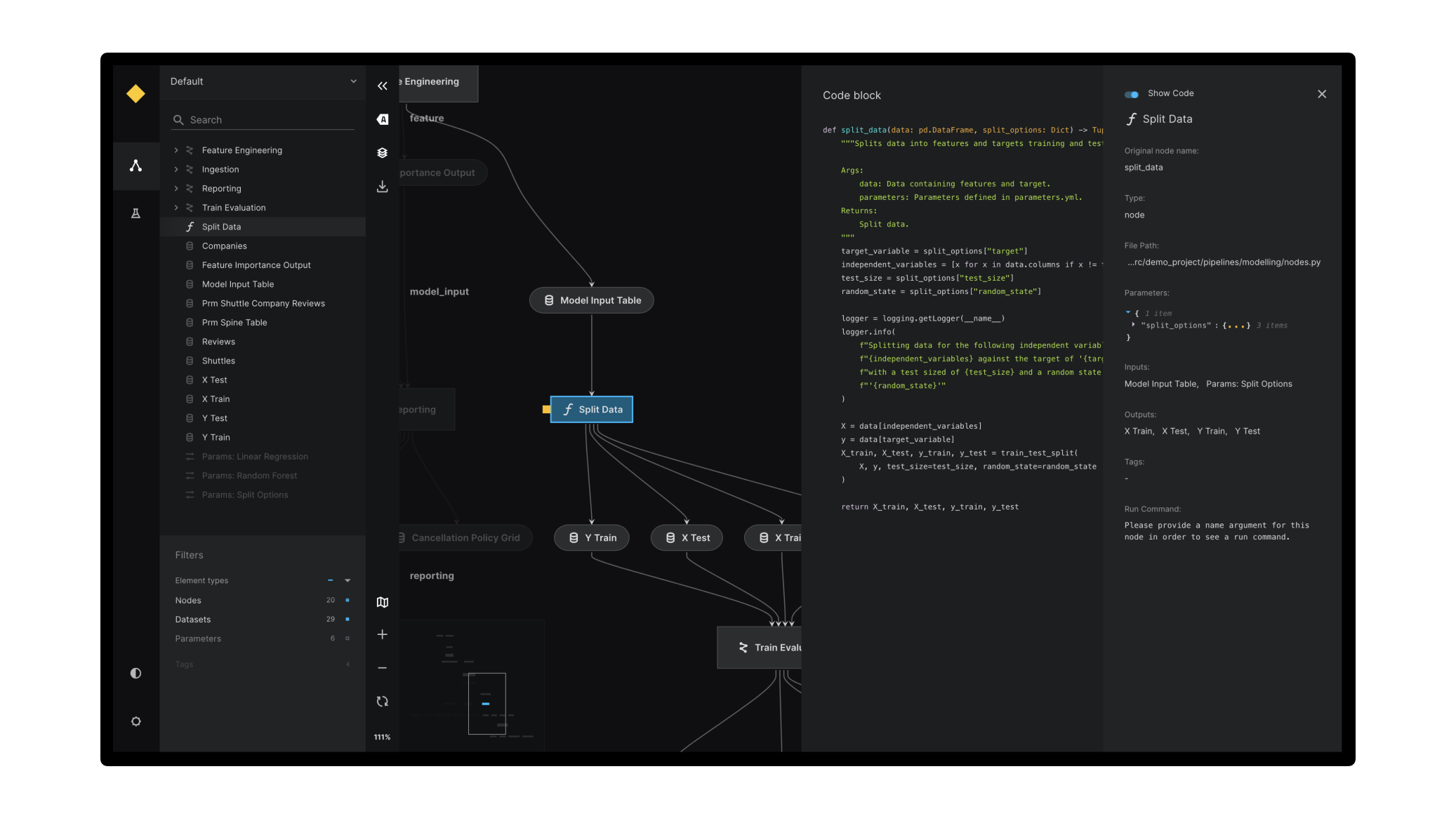
Kedro 是一个用于生产级数据科学的工具箱。它使用软件工程最佳实践,帮助您创建可重现、可维护和模块化的数据工程和数据科学流水线。主要功能包括:
- 项目模板:基于 Cookiecutter Data Science 的标准、可修改且易于使用的项目模板。
- 数据目录:一系列轻量级数据连接器,用于在许多不同文件格式和文件系统 (包括本地文件系统、网络文件系统、云对象存储和 HDFS) 之间保存和加载数据,并提供针对基于文件的系统进行版本控制。
- 流水线抽象:自动解析纯 Python 函数之间的依赖关系,并通过 Kedro-Viz 进行流水线可视化。
- 编码规范:采用
pytest进行测试驱动开发,在 Sphinx 中生成文档良好注释代码,支持flake8、isort和black,并利用标准 Python 日志库编写经过 lint 处理后的代码。 - 灵活部署:支持单机或分布式部署策略,同时还额外支持在 Argo,Prefect,Kubeflow,AWS Batch and Databricks 上部署。
4ian/GDevelop
Stars: 5.2k License: NOASSERTION
GDevelop 是一个全功能的、无代码的开源游戏开发软件。
- GDevelop 具有完整功能
- 无需编码即可创建游戏
- 可用于移动设备、桌面和 Web 平台
- 基于直观而强大的基于事件系统构建游戏逻辑
SoftFever/OrcaSlicer
Stars: 2.1k License: AGPL-3.0
Orca Slicer 是一款开源的 FDM 打印机切片软件。具有以下核心优势和特点:
- 自动校准
- 三明治模式
- 精确壁厚
- Klipper 支持
这篇关于数据科学最佳实践:Kedro 的工程化解决方案 | 开源日报 No.47的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









