本文主要是介绍MuCAN: Multi-Correspondence Aggregation Network for Video Super-Resolution阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

出自ECCV2020
文章思路
这篇文章的出发点是:帧间和帧内中存在很多相似的内容,如何有效的利用这些内容上的相似性去超分目标帧。这种相似性如下图所示:
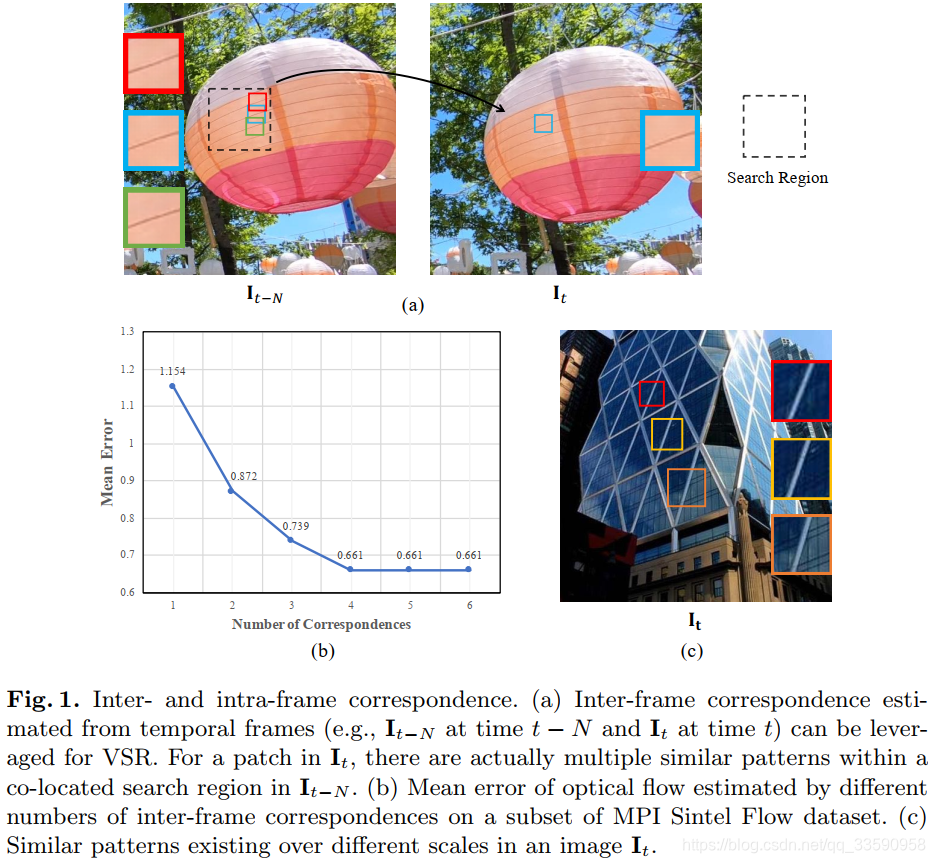
基于此,作者提出了一个temporal multi-correspondence aggregation module(TM-CAM)以利用帧间内容上的相似性, cross-scale
nonlocal-correspondence aggregation module(CN-CAM)以利用帧内内容上的相似行。
整个算法的框架如下图所示:
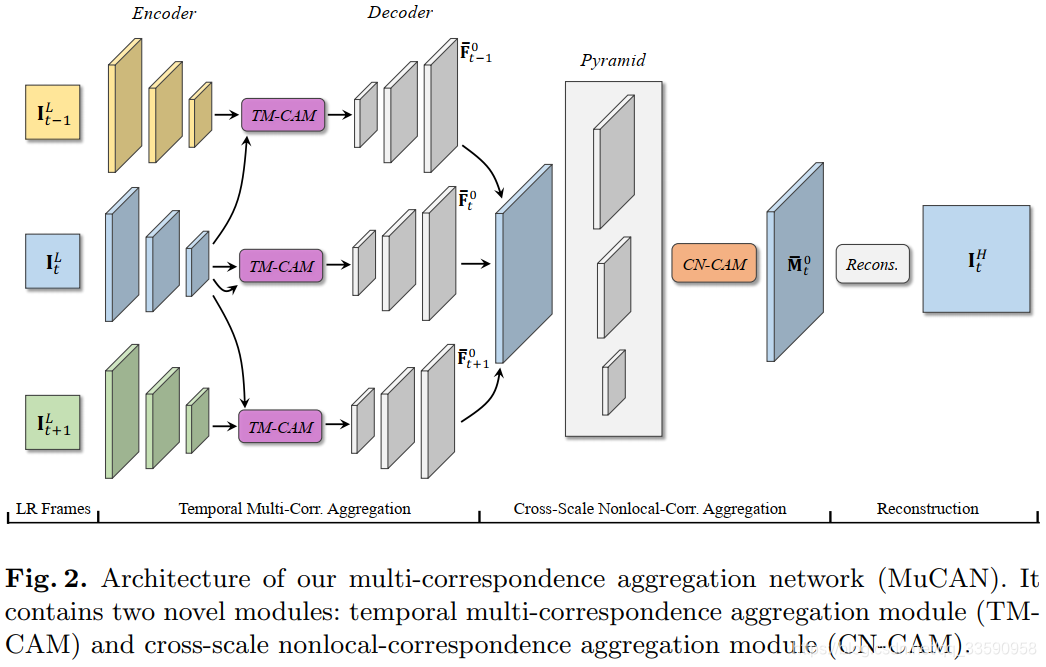
整个算法由三部分组成,分别是TM-CAM,CN-CAM和重构模块组成。
TM-CAM
结构如下
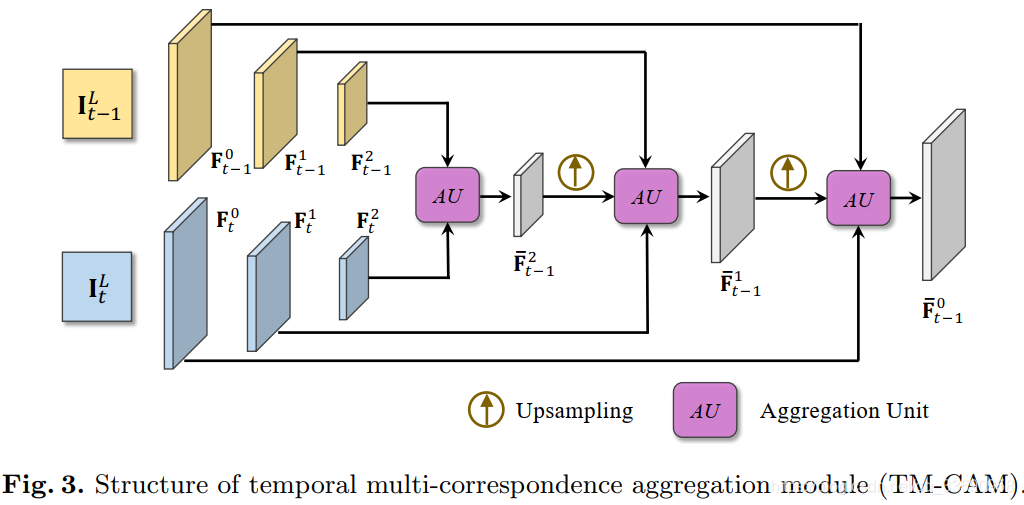
这个模块可以同时处理大运动和小运动,实现帧间对齐目的,并且作者说小运动对齐的准确性(在亚像素级别)是非常重要的,因为他是引入细节的源头。
以上图为例,这模块首先对输入帧的特征分别执行下采样操作,然后从分辨率最低的一级开始,逐级往上开始融合,直到分辨率最大的一级为止。通过这种方式达到同时捕获大运动和小运动的目的,从而实现更加准确的对齐操作。其中AU单元结构是实现这个功能的关键,结构如下:
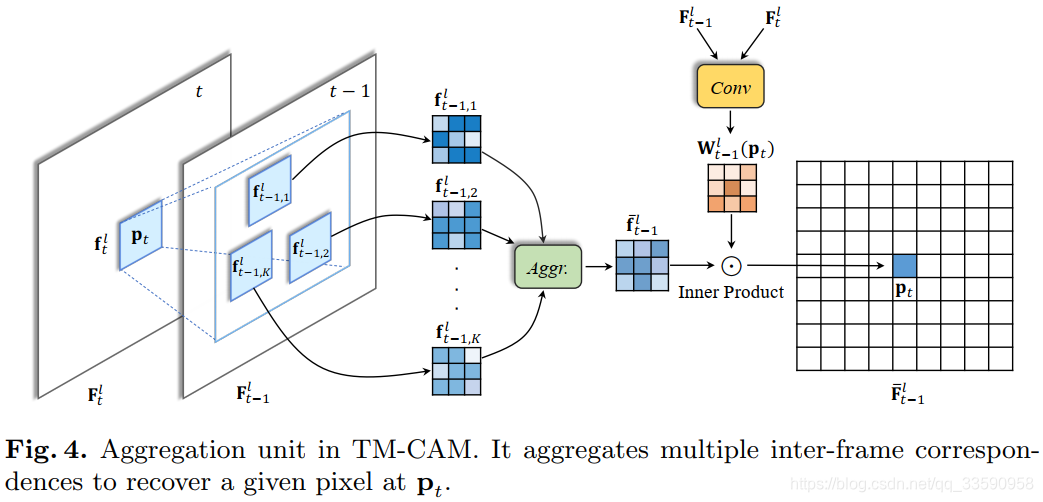
它的思路是:
1)在目标帧中,对于每一个位置,以它为中心,选择一个领域大小作为patch,然后在近邻帧中,以它为中心,在指定的范围查找与目标帧中对应patch最为相似的K个patch。
2)之后将这K个最相似的patch按通道拼接,通过一组卷积(即上图中的Aggr)进行融合,得到一个中间patch
3)为中间patch中各个位置分配权重,这里不是相同的权重,而是通过学些得到。具体地,近邻帧与目标帧特征拼接后送入一个卷积层,它的输出是一组权重,并且是针对每一个像素而言的,因此它的输出大小是 H × W × P a t c h H{\times}W{\times}Patch H×W×Patch
4)最后生成的权重与中间patch相乘得到对齐后的近邻帧。
注:
a、这里Patch的大小设为了 3 × 3 3\times3 3×3,K设为了4(这里为什么要设置为大于1的数值,可以见本文的第一张图b所示,,多个候选Patch可以实现信息的互补,减小对齐的误差,如果只是一个的话,我的理解是这样就和光流法很相似了)。
b、搜索范围由 ∣ P t − P t − 1 ∣ < = d |P_t-P_{t-1}|<=d ∣Pt−Pt−1∣<=d 限定,其中d从最高分辨率一级到最低分辨率依次取{7,5,3}。
c、两个Patch之间的相似性由下式度量:

即是两个归一化后向量的内积。
d、当所有的帧对齐完成后,通过PixelShuffle对其进行2倍的上采样(作者说这是为了保持亚像素细节,我的理解是前文作者说亚像素信息是引入细节的来源,如果进行上采样操作的话,可以放大这个亚像素信息,不至于因为之后的下采样操作将这些亚像素信息处理没了,所以可以更加有效的保持这个信息)
e、这个模块实现帧间对齐的操作,我的理解是通过在近邻帧中搜索与目标帧最相似的几个块,相当于是估计了多个光流运动信息,然后将这些信息进行合并综合融合得到一个更加准确的光流运动信息,之后与学习出权重相乘,相当于就是运动补偿操作,从而实现了帧间对齐的目的(这里是在特征级别上的对齐,不是输入网络前图像级别的对齐)
CN-CAM
结构如下
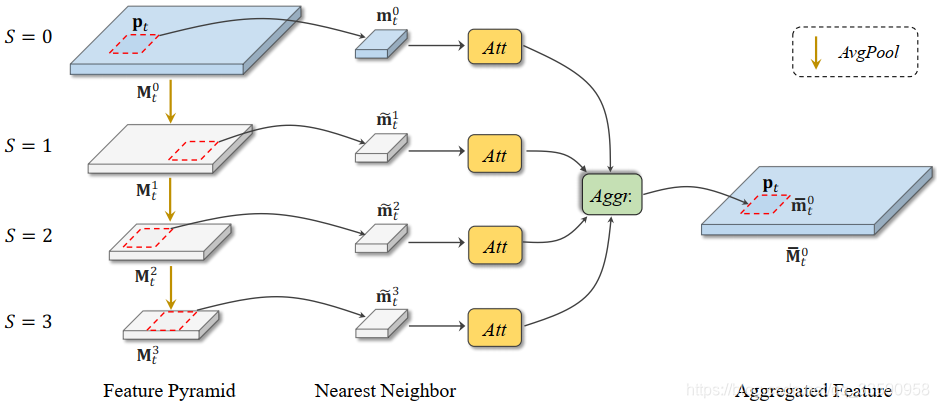
这个模块主要是捕获图像在空间维度上各个位置之间的相似性,以辅助实现更高效的超分。
具体的过程(以上图为例):
1)首先使用平均池化将输入这个模块额特征进行三次二倍的下采样,正如上图所示的S=1,2,3级
2)然后在S=0级,对每一个像素位置,以该位置为中心,它的一个指定领域为Patch,在S=1,2,3级中分别搜索与其最相似的一个Patch(这个相似性度量标准作者没有提及,猜测和TM-CAM的相似性度量方式一样)
3)然后将查询到的结果通过一个时空注意力模块过滤掉无用的信息
4)最后通过一组卷积层融合这四级特征,并输出融合后的特征。
注:
a、这里的Patch大小设为1,即一个像素大小
重构模块
对于7帧输入,由20个残差块组成
对于5帧输入,由40个残差块组成
这里不同的帧数是由于训练数据集不同导致。
损失函数
作者提出边缘损失,以促使网络生成更加细致的纹理。
实现方式是采用拉普拉斯滤波器作为边缘检测器,从GT中获取边缘图,然后进行二值化,二值化的方式如下:

其中 δ = 0.1 \delta=0.1 δ=0.1, I t E I_t^E ItE就是所获取的边缘图, P t P_t Pt指的是边缘图中对应的位置,B是二值化后的结果。最终的结果就是有边缘的区域为1,否则为0.
最终的损失函数如下

第一项为Cb损失,计算超分结果 I ^ t H \hat{I}_t^H I^tH与真实值 I t H I_t^H ItH之间的差异,第二项则为边缘损失,其中 λ = 0.1 \lambda=0.1 λ=0.1。圆圈表示对应元素相乘。
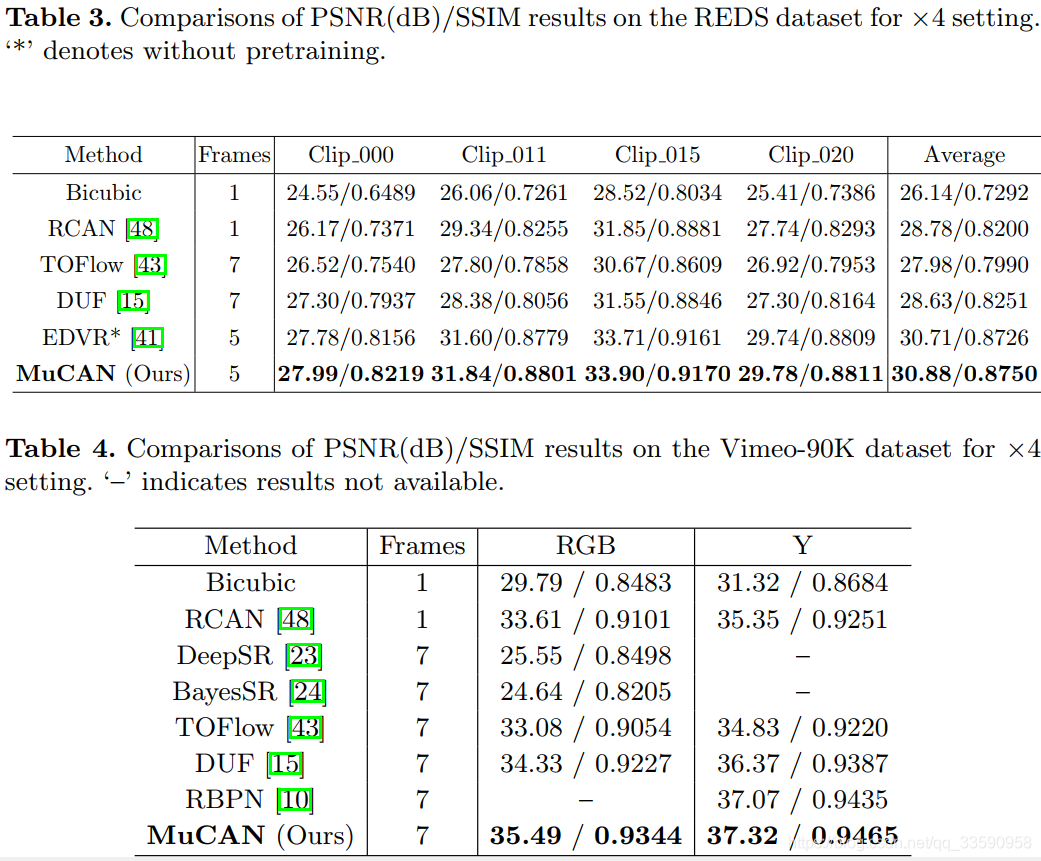
实验结果
训练数据集:Vimeo-90K,REDS
测试数据集:Vid4,REDS4,Vimeo-90K=T
评价指标:PSNR,SSIM


这篇关于MuCAN: Multi-Correspondence Aggregation Network for Video Super-Resolution阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





