本文主要是介绍文献调研——样本不均衡对神经网络的影响(Class Imbalance),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天调研不均衡样本对神经网络的影响。
2020/04/06
A systematic study of the class imbalance problem in convolutional neural networks
数据集中样本不均衡问题对神经网络的影响研究
Abstract
本文聚焦于样本不均衡对分类神经网络的影响,本文在依次在3种不同规模的通用数据集:MNIST/CIFAR-10/ImageNet中研究样本不均衡问题对分类网络的影响以及解决样本不均衡问题的相关思路:过采样/下采样/二段训练法/阈值法。
最终得出以下结论:
(1)样本不均衡不利于分类网络
(2)目前主流方法主要还是过采样方面
(3)对于通用网络过采样一般不会引起过拟合
Section I Introduction
卷积神经网络已广泛应用于计算机视觉领域,如物体检测、图像分类与分割任务等。在自然语言处理领域也逐渐取代传统的机器学习方法,CNN与传统机器学习算法最大的不同在于其将自动化的特征提取及分类器整合至一个框架中,因此可以有效的学习到层次化的特征表达。CNN主要有卷积层、池化层、全连接层堆叠组成,这种复杂的结构往往需要GPU提供算力支撑。
但CNN面临的一大问题就只往往部分数据在训练过程中较其他类别具有很高的占比,这就是样本不均衡问题。实际应用中常见于医学诊断、缺陷检测等领域,某些类别样本数量往往是其他类样本的数千倍。这一问题会严重影响网络训练阶段的收敛性及测试阶段的泛化性。
解决样本不均衡的途径之一就是通过采样的方法,在数据层面弥补不均衡的数据分布。如对少样本类别进行过采样或对主类样本进行欠采样。还有在分类器级别进行改进,这类方法并不改变数据而是在算法层面进行调整,如对不同类别样本错误分类使用不同的代价权重或者对分类器的输出概率进行调整。
一些其他的思路还包括:第一阶段在均衡数据上训练随后对输出层进行微调的二段训练法(two-phase training)。
Section II Methods for imbalance
解决数据不平衡问题主要有两类途径:一是数据层面的,主要改变数据集训练数据的分布,使得标准的算法工作;另一类是分类器级别的算法改进,并不改变训练集数据而是调整改进训练算法。也可将二者结合使用。
Part A Data Level
过采样(Oversampling)
随机过采样是使用最广泛的方法之一,就是对少数量类别的样本随机重复采样以增加该部分所占比例。但容易导致过拟合问题。
SMOTE
因此在此基础上提出了改进版本的SMOTE算法,在临近的数据点中以插值的方式插入人造数据。
基于集群的过采样:首先会对数据集内的数据进行集群,随后对各集群分别进行过采样。基于集群的过采样有效解决了类内和类间数据不均衡的问题
欠采样(Undersampling)
欠采样与过采样是相对的,通过随机移除多数量类别中的样本直至所有类别下具有相同样本数。虽然欠采样丢掉了部分原始训练数据,但在某些情况下可以取得比过采样更佳的效果。以及除了随机丢弃数据样本,更多情况下欠采样会有选择的丢弃部分样本,如通过单边标识边界附近的冗余样本及为部分样本重新打标签。
Part B Classifier Level
阈值
阈值法通过改变分类器的决策阈值达到在测试阶段更改输出概率的效果。最基本的阈值法通过将每个分类器的输出除以其估计的先验概率得到正确的类别概率,这一概率和各类别的样本数目有关。
代价敏感学习
代价敏感学习指对不同类别误分类后施加不同惩罚。阈值法是在网络推断阶段对输出进行调整,而代价敏感学习是在反向传播过程中对网络进行调整,用最小误分类代价代替标准损失函数进行网络的训练。如对部分样本施加更高的学习率,从而对网络参数的更新贡献更大,达到同过采样同样的效果。
异常检测One-Class Classification
神经网络中有一类任务叫做异常检测,即数据集中仅包含一类数据用于训练,其他类别(Outlier)的信息是缺失的。因此实际训练过程中往往面临数据严重不均衡的情况,更接近异常检测的范畴。此类问题多通过支持向量机、自编码器的思想加以解决。
集成法
集成法即将前述数据层的采样法和算法层的相关方法加以集合,共同调整类别不均衡的问题。
如EasyEnsemble和BalanceCascade方法是在欠采样的数据子集上对分类器进行调整;two-phase方法先使用平衡数据集进行训练随后在不平衡数据集上进行微调并成功应用于脑肿瘤分割任务。
Section III实验相关
Part A Forms of Imbalance
样本不均衡在多分类任务中十分常见,有的任务中某类数据较之其他类别明显过剩/缺少,有的多分类任务中每个类别下的样本数目都不尽相同。本文主要探讨现实世界中常见的两类样本不均衡。
阶跃不均衡(Step Imbalance)
指的是少样本及多样本类别下样本数目一致,但少数类别和多数类别下的样本数目不均衡的现象。
线性不均衡(Linear Imbalance)
线性不均衡指各类别下样本数目均不一致,称线性增长的趋势。
下图是两类imbalance的示意图.其中a,b为step imbalance,c为linear imbalance.
 Part B 实验方案
Part B 实验方案
本文将前述提及的主要7种方法进行了实验,分别是
(1)少数类别随机过采样
(2)多数类别随机欠采样
(3)基于随机过采样数据集的二段训练法
(4)基于随机欠采样的二段训练法
(5)阈值法
(6)过采样阈值集成法
(7)欠采样阈值集成法
Part C 数据集及模型
实验采用的数据集,根据复杂程度依次是:
MNIST、CIFAR-10、ImageNet
其中MNIST使用LeNet-5,设置了linear imbalance和step imbalance两种不均衡情况进行训练。
CIFAR-10使用ALL-CNNs,具体结构参见Table III。
ImageNet使用的是ImageNet的一个子集,网络选的是ResNet-10,出于训练时间的考虑。
 Part D 评价指标
Part D 评价指标
分类任务常以模型的分类精确度(Accuracy)作为模型性能的评价指标,然而在样本不均衡的前提下,Accuracy往往并不能反映真实的情况。当测试集中样本不均衡(如绝大部分属于某一类别时)往往分类器会将全部样本分为该类别;当测试集样本均衡但训练集样本不均衡时,训练出的分类器往往也不能真实对测试样本进行分类。
所以,AUC是较好的评估分类器性能的指标,AUC指的谁ROC曲线的面积,ROC则是根据分类器的假阳率和真阳率绘制出的曲线,其中FPR为横坐标,TPR为纵坐标。ROC能够在样本分布发生变化时较为客观的反映对正负样本的分类能力,因此比较适合在样本不均衡情况下作为评测指标。
ROC AUC相关参考:
ROC AUC related
# Section IV 实验结果分析
Part A 样本不均衡对分类效果的影响
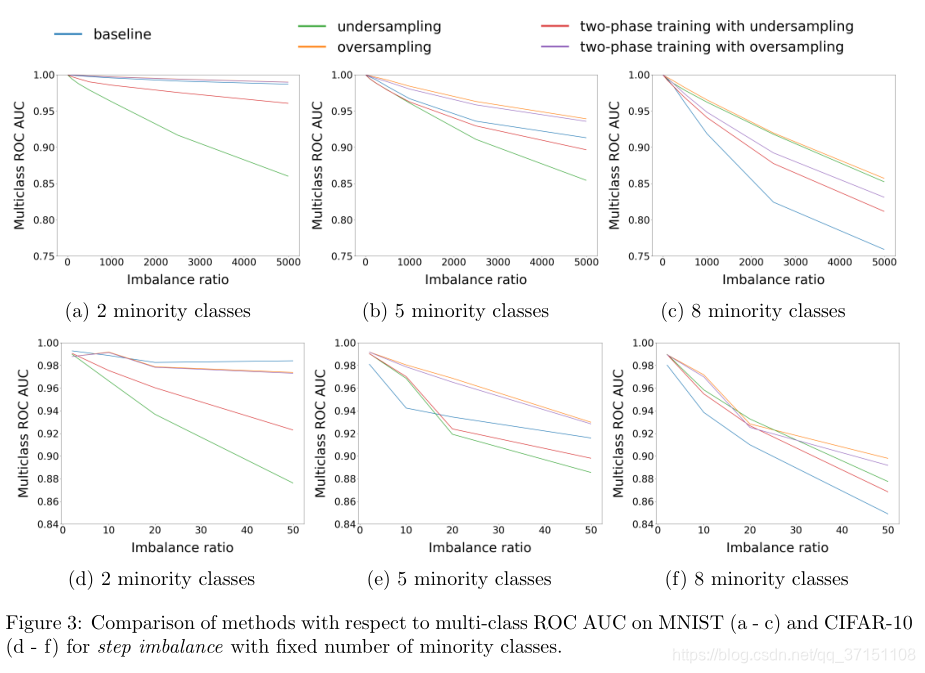
Figure3显示了不同均衡率下实验不同方法对分类效果的影响。
(1)可以看到样本不均衡缺失会显著影响模型的分类效果;
(2)随着多数样本和少数样本之间不均衡率的增大,以及少数样本类别的增多均对分类器有负面影响
(3)样本不均衡对复杂分类任务的影响更为显著
(4)从弥补样本不均衡的方面来看,过采样是最有效的方法,甚至比在原始样本上的分类效果更佳
(5)在实验方法中,欠采样对数据不均衡的弥补效果是最差的,可能和丢弃了一部分原始数据有关。
(6)二段训练法的效果介于原始方法和采样法之间,主要取决于采样对样本不均衡的弥补效果,若采样后有效抑制了样本不均衡的影响,则微调后的二段训练法会取得更佳的分类效果。
(7)但根据在ImageNet数据集上开展的实验结果来看,并不是所有情况下过采样总是最有效的解决途径。尤其当分类任务逐渐复杂以及样本存在极端不均衡的情况时,此时实验结果表明过采样和欠采样达到的效果是近似的。(参见Fig 4)
 Part B 进一步探讨
Part B 进一步探讨
通过实验还要探明的一个问题就是:到底是因为样本数量上的减少导致的模型精度下降,还是真的由于样本不均衡才引起的精度下降。
实验也给出了证实,确实是样本不均衡引起的模型精度下降。
(1)因为比如在过采样部分,我们采用的训练样本数目和原始数据集样本数目是一样的,只是通过过采样改变了类别之间的不均衡程度;
(2)另一方面,在欠采样的实验中,我们发现欠采样的部分实验结果甚至优于原始数据集的训练结果,这也说明了不是样本数量的减少导致的模型精度下降。
(3)linear imbalance和step imbalance的对比实验结果表明,模型精度的下降不仅和样本数目有关,更重要的是类别之间的分布。
Part C 采样法的泛化性
下面讨论一下基于采样方法解决样本不均衡问题的泛化性。许多情况下过采样和欠采样的效果相近,这时就要考虑选择哪种具有更好的泛化性。而过采样法由于会对少样本类别多次采样,可能会带来对少样本类别的过拟合问题,在这种情况下我们更倾向于选择欠采样的方式。
Scetion V Conclusion
本文明确了两种样本不均衡问题并在MNIST/CIFAR-10/ImageNet数据集上验证了样本不均衡问题对模型精度的影响,进一步测试了采样法、阈值法等对样本不均衡的效果。
结论主要有:
(1)样本不均衡会影响模型精度
(2)随着分类任务复杂度的上升,样本不均衡对模型的影响会显著上升
(3)样本不均衡问题导致模型精度下降的原因不仅是训练样本的减少,主要是因为样本类别的分布
在算法层面:
(1)在绝大多数多分类任务中,过采样是最能有效抑制样本不均衡的方法
(2)在部分样本极度不平衡的情况下,欠采样和过采样取得相近的效果;如果出于训练时间的考虑,选择欠采样更为合适
(3)为了达到更好的精度,在采样的基础上对分类器的概率输出进行优化,即采用采样-阈值联合的优化方式可达到更加的分类精度
(4)与传统机器学习不同,过采样方法并不会引起卷积神经网络的过拟合问题
这篇关于文献调研——样本不均衡对神经网络的影响(Class Imbalance)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






