本文主要是介绍MySQL8.0高级应用———集群模式配置(主从、双主、MHA高可用模式配置),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MySQL8.0主从模式配置流程
- 1. MySQL集群配置
- 1.1. 主从模式配置
- 1.1.1. 开启账号访问权限
- 1.1.2. 配置Master库
- 1.1.3. 配置Slave库
- 1.1.4. 启动主从库
- 1.2. 双主模式配置
- 1.2.1. 多主多写模式
- 1.2.2. 双主多写模式
- 1.2.3. 双主单写模式
- 1.2.4. 推荐使用模式
- 1.2.5. 配置实例
- 2. 开启半同步复制
- 2.1. 配置主库
- 2.2. 配置从库
- 2.3. 主从不同步的处理方式
- 2.3.1. 数据量较小
- 2.3.2. 数据量较大
- 3. MHA高可用服务环境搭建
- 3.1. MySQL Router配置
- 4. MHA高可用架构模式配置
- 4.1. mha4mysql
- 4.2. 准备工作
- 4.3. 建立SSH无密码访问
- 4.4. 写mha4mysql的配置文件
- 4.5. 检查工具测试配置文件
- 4.6. 搭建流程问题汇总
1. MySQL集群配置
这里使用的是Ubuntu Server 20.04.2 + MySQL 8.0.23进行主从模式的配置演示,并启用了semisync进行半同步复制,基本的安装通过apt进行,安装结束全部配置完以后对虚拟机进行了克隆(这里通过克隆的方式,在后配置MySQL主从模式的时候需要修改data目录下的auto.cnf文件里面的UUID值,否则会导致slave同步失败,UUID相当于是MySQL节点的身份证,不能重复。所以在文章开头特地强调一下。)
1.1. 主从模式配置
这里采用的是1主2从,共3台机器,具体信息如下:
- 【server-1】
- IP:10.20.1.158
- MySQL Master
- 使用同步的账号root
- 【server-2】
- IP:10.20.1.159
- MySQL Slave-1
- 使用同步的账号root
- 【server-3】
- IP:10.20.1.160
- MySQL Slave-2
- 使用同步的账号root
PS:出于安全考虑可更换同步的账号为自定义的账号和权限,以缩小权限的范围。这里为了减少演示步骤就不做建号授权那些无关的步骤了,直接用root账号进行同步。
1.1.1. 开启账号访问权限
如果使用自建账号和授权的人可以忽略这一步,这里是开启root账号的内网访问权限。
第一步:先开启root账号的内网访问权限。
先通过mysql的cli登陆进数据库,并且换到mysql库。
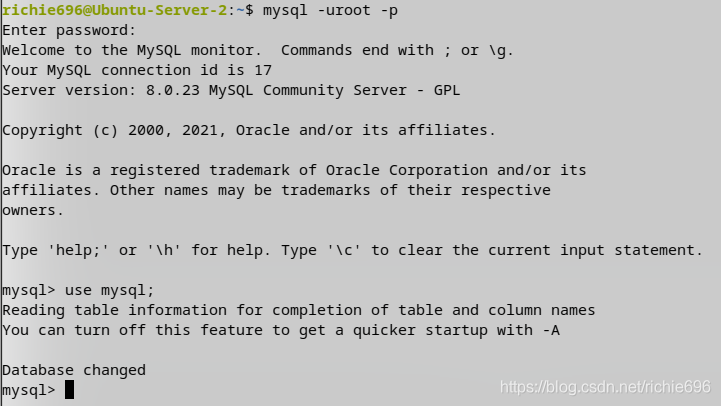
然后更新root账号的访问权限范围,并刷新权限信息。
update user set host='你的内网IP' where user = 'root';
flush privileges;
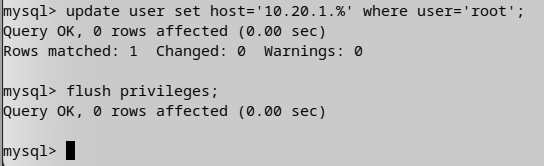
分别讲主从3台mysql账号的权限开启。
如果你是在虚拟机当中镜像的slave节点,那么请做下面的一步操作,将从库所在机器上auto.cnf文件里面的uuid修改掉。具体操作如下:
vim /var/lib/mysql/auto.cnf
(如果当前使用的不是root账号无法访问该文件,请su root以后再修改。)
然后google或baidu生成一个uuid替换掉以后,保存。
接着重启mysql服务
service mysql restart

1.1.2. 配置Master库
打开主库的my.cnf配置文件,并写入如下配置;
打开配置文件:
sudo vim /etc/mysql/my.cnf
写入配置:
[client]
# 配置远程端口(可选,不改就是3306)
port=15588
[mysqld]
# MySQL8.0的默认时区
default-time_zone='+8:00'
# 配置远程端口(可选,不改就是3306)
port=15588
# 默认binlog文件的名称(可自定义)
log_bin=mysql-bin
# 当前服务器的ID,不能重复,推荐用服务器IP D段
server-id=158
# 数据刷盘参数=1时,只要有1个事务提交就会触发写盘的操作,安全性最高,并发性最差
# 数据刷盘参数=0时,由文件系统控制写盘的频率,并发性能最好,但是意外丢失数据的风险最大,这里根据实际需求配置,不建议乱配。
sync_binlog=0
# 排除掉不需要同步的数据库列表
binlog-ignore-db=performance_schema
binlog-ignore-db=information_schema
binlog-ignore-db=sys
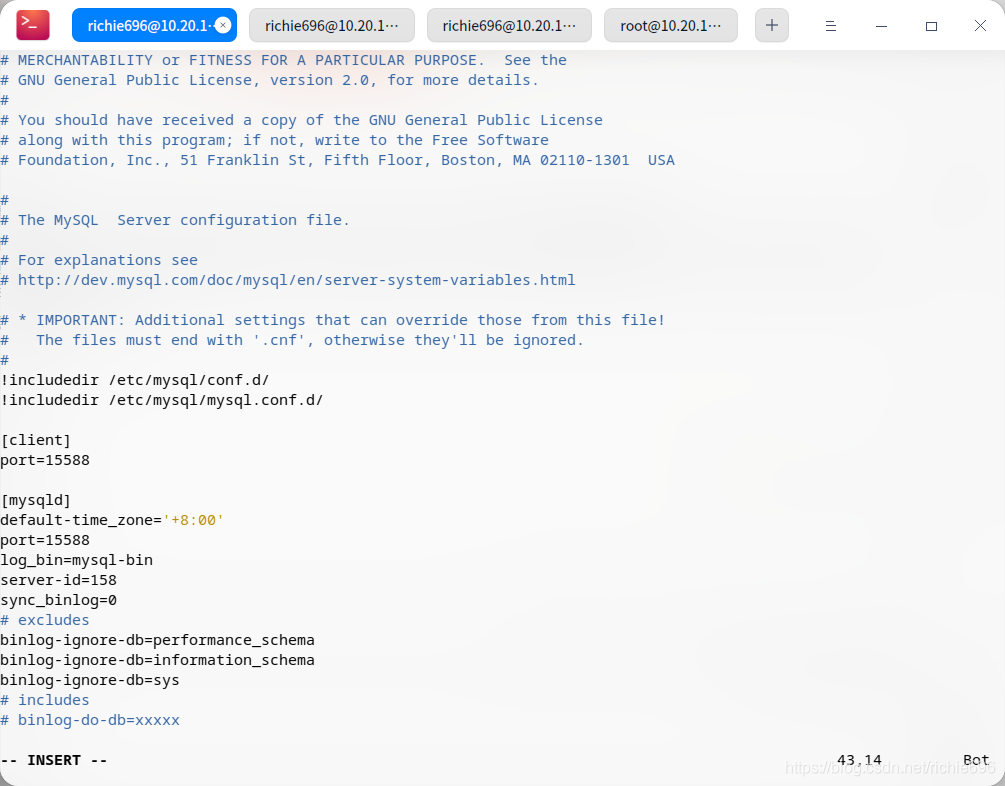
配置好以后重启服务。
1.1.3. 配置Slave库
下面,开始配置从库的数据,具体配置信息如下,不多做解释了:
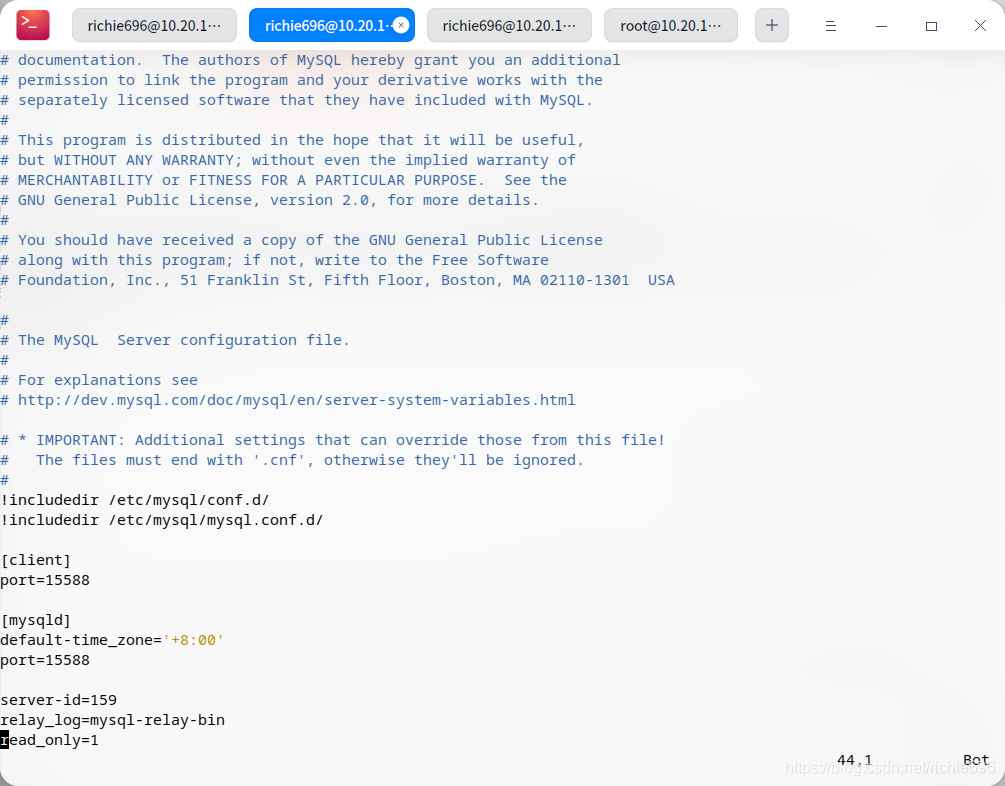
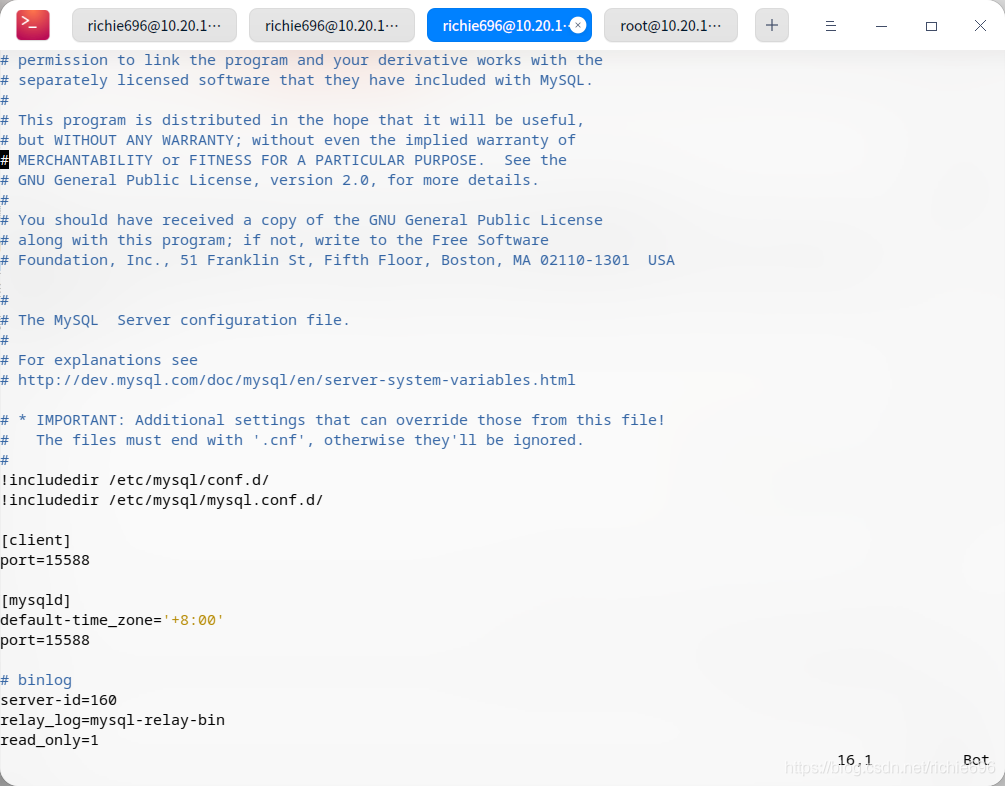
[client]
port=15588
[mysqld]
default-time_zone='+8:00'
port=15588
# 没台机器的ID都不同,根据自己实际情况修改
server-id=160
relay_log=mysql-relay-bin
read_only=1
至此,从库的基本配置也好了,下面我们就要开始配置slave节点信息了。
1.1.4. 启动主从库
先进入Master库的cli控制台,输入以下信息:
show master status;
看到如下信息:

记好前两列的信息,下面配置从库需要用到。
然后进入Slave的cli控制台,输入一下信息:
mysql>
change master to master_host='10.20.1.158',master_port=15588,master_user='root',master_password='root',master_log_file='mysql-bin.000003',master_log_pos=13404;
mysql>start slave;
下面查看slave的状态:
mysql>
show slave status \G;
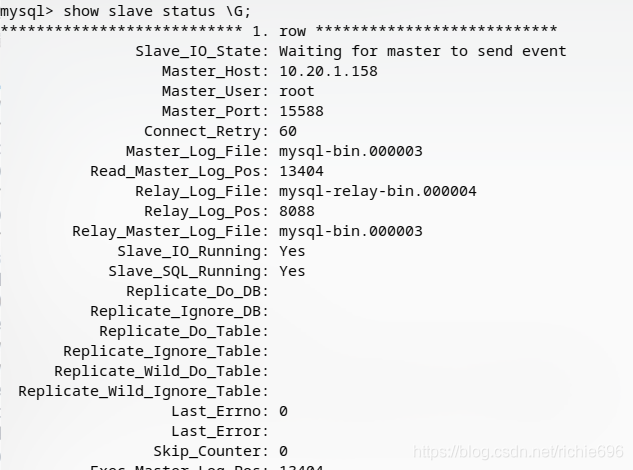
当看到上面的信息就证明同步成功了,最主要就是看Slave_IO_Running和Slave_SQL_Running。同样的方法再把其他的节点配置成功以后就可以了,如果这时候主库的数据已经非常多了,通过pos的方式定位日志数据进行同步会非常慢,建议用mysqldump,直接导出主库的数据sql脚本,扔到从库里面去执行,速度会快很多,如果担心有数据确实,那么再导出之前查看一下当前pos的位置,在从库倒入过主库备份以后,再使用上面的方法从最近的pos位开始往后同步,防止你在同步期间有新的数据在产生,而没能被倒入到从库中。
1.2. 双主模式配置
什么是双主模式?说白了就是2个master,但是2个master之间如何进行数据同步呢?那就是互为slave。而双主模式又分多主多写、双主双写模式和双主单写模式。
1.2.1. 多主多写模式
是指2个以上的master节点来承担数据写入的任务,以此来大幅提升数据库并发写入的性能,但是一旦数据库出现问题,在处理问题数据的时候会是一件让人头大的事情,并且多写数据库的ID值起始位置和增量需要对多写主机总数取模,求得增量间隔。否则master之间生成的id会出现冲突,所以一般不太推荐使用这种方式。
1.2.2. 双主多写模式
和多主多写类似,只不过作为master的节点限制到了2个,并且相互之间的ID值起始位置一个为1、一个为2,且增量均为2,使2台机器生成的ID一个为双数一个为单数,问题和多主多写一样,只不过出问题以后比多主多写相对容易处理一些,应用在并发写入量要求没那么极致的情况下,这里就不多赘述了。
1.2.3. 双主单写模式
该模式可以理解为为主master做冗余备份之用,防止主master数据库挂掉以后,直接导致服务不可用的情况发生,该方式可以提升MySQL集群的高可用性,而对于另外两种方式提供的并发写入性能的提升,可以利用Reids、MongoDB等其他的技术手段来变相的提升写入性能,以达到近似的效果。此种方式在出现问题时,数据处理上也相对简单,工作量比另外2种小了非常多,所以在企业环境内如果达到了主从模式都无法满足的地步可以优先考虑该方式。
1.2.4. 推荐使用模式
而本文介绍的方式主要就是双主单写模式,其他方式在该模式基础上增加一个ID自增间隔和ID起始位置的配置,然后在后文中提到的MySQL Router当中添加到master的路由列表中就可以实现了。
1.2.5. 配置实例
下面就开始在主从模式的基础上增加双主单写模式的配置,这与主从模式完全不冲突。
此处,新增一个服务器节点作为master-2,之前的master(10.20.1.158)作为master-1(下文统称master-1),将会由下面的server-4和master-1进行互为同步操作。
【server-4】
IP:10.20.1.157(下文统称master-2)
MySQL Master-2
使用同步的账号root
首先,我们打开master-1和master-2的my.cnf配置文件,增加如下配置,2个节点内容完全相同:
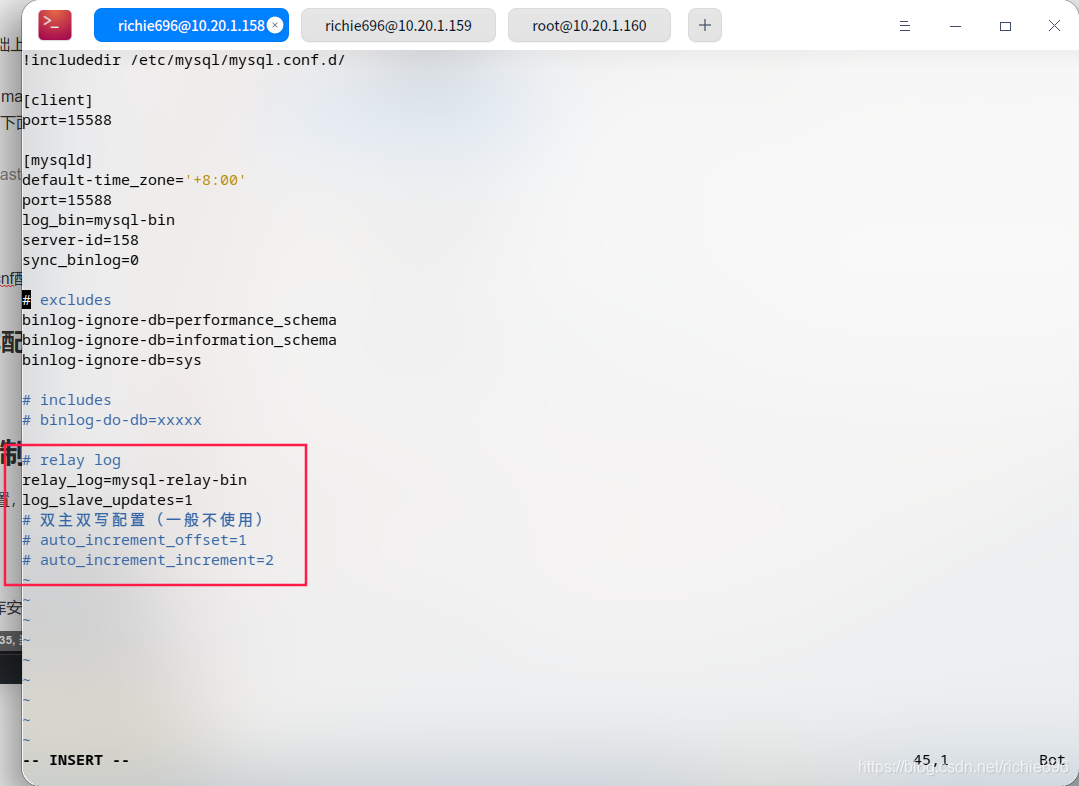
之后,重启2台机器的MySQL后,登录到mysql控制台,先查看master-1的master状态
master-1的master状态:
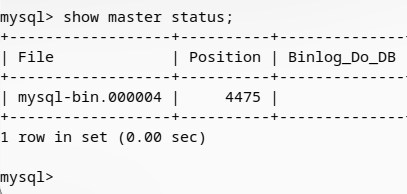
master-2的master状态:
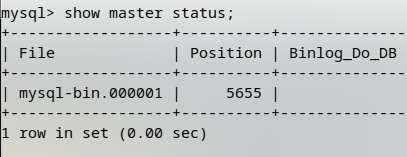
记录好上述信息,后面要用到。然后将master-1的数据库完整导出,在新建的master-2上进行数据恢复,保证要同步的数据库数据完全一致。(该步骤在前面有提到过)这里就不做截图说明了。进行到这里我默认你已经将master-2上的数据和master-1同步过了。
下面,我们开始设置master-1和master-2互为master节点。
在master-1上执行如下语句:
mysql>
change master to master_host='10.20.1.157',master_port=15588,master_user='root',master_password='root',master_log_file='mysql-bin.000001',master_log_pos=5655;
mysql>start slave;
在master-2上执行如下语句:
mysql>
change master to master_host='10.20.1.158',master_port=15588,master_user='root',master_password='root',master_log_file='mysql-bin.000004',master_log_pos=4475;
mysql>start slave;
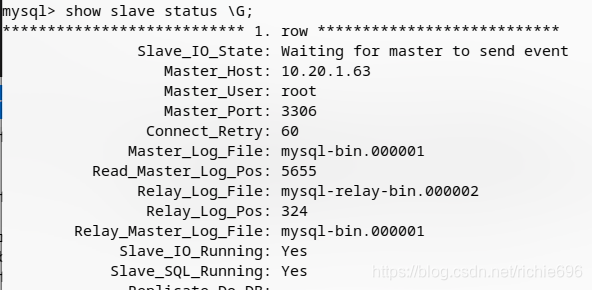
至此,配置就结束了。下面查看2台设备的slave状态。
master-1的slave状态:
master-2的slave状态:
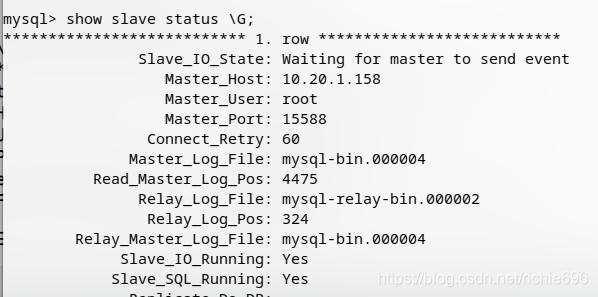
看到2个Yes,就证明已经成功了。然后在配合MMM架构方案就可以实现自动切换master,并将slave指向自动修改到新的master之上了。这个点的内容太多,就不在这里展开说了,后续会单独开一篇文章来详细说明。
2. 开启半同步复制
半同步复制需要分2个地方去配置,分别是主库和从库,下面我们就开始进行主库的配置。
2.1. 配置主库
首先,我们需要给MySQL数据库安装semi插件。
mysql>
install plugin rpl_semi_sync_master soname 'semisync_master.so';
mysql>show variables like '%semi%';
mysql>set global rpl_semi_sync_master_enabled = 1;
mysql>set global rpl_semi_sync_master_timeout = 1000;
查看安装结果。上面的第三步是开启semi插件,第四步是设置同步超时时长为1秒。
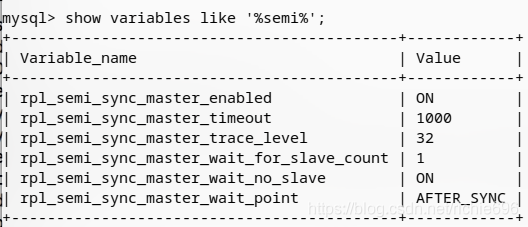
至此,主库配置基本结束。下面开始从库配置。
2.2. 配置从库
一样,给从库安装semi插件并启用。注意,主库和从库的插件不一样,看清楚。
mysql>
install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
mysql>set global rpl_semi_sync_slave_enabled = 1;
查看安装结果。
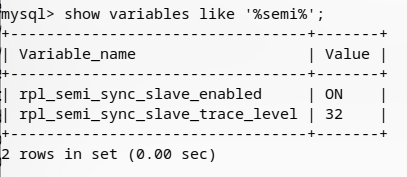
同理,将其他Slave节点按照同样方式进行配置即可。
配置完以后重启一下slave节点。
mysql>
stop slave;
mysql>start slave;
至此,配置流程就结束了,现在可以去测试一下同步效果了。
2.3. 主从不同步的处理方式
当MySQL出现集群数据不同步的时候,MySQL就会停止同步。查看Slave状态会有如下的显示:
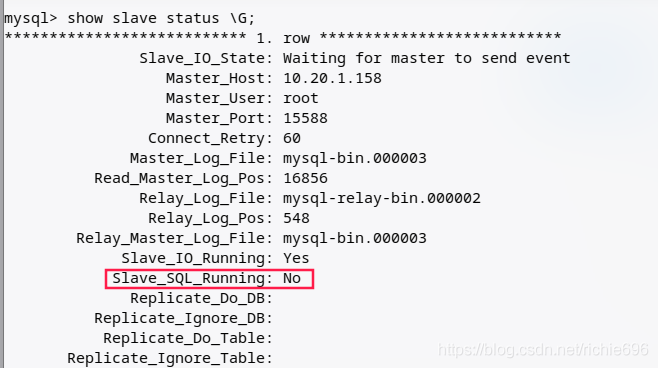
出现这种情况,一般就是Slave库出现了事务回滚,比如:Slave应该挂掉了或者对Slave节点进行了写操作,导致了主从不同,对应节点就会终止同步,出现这种情况我们需要重新对节点进行配置和同步,方法有多种,根据不同的情况使用不同的方法,具体如下:
2.3.1. 数据量较小
记录主库最新的binlog都pos位置,然后利用mysqldump从主库中导出需要同步的数据库备份,并利用各种手段从A服务器,将备份传输到B服务器,之后重新导入到Slave节点数据库中,重新change master,指定新的位置,从这个位置开始同步。
下面我们就演示一下数据量较小方案的操作过程。
先查看master的状态
mysql>
show master status;
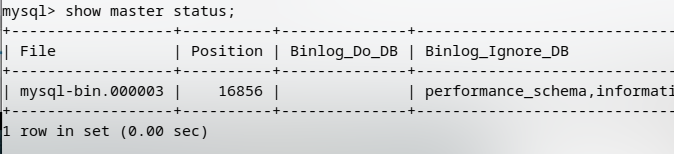
记录下File和Position的值,然后:
这是shell命令,不是mysql命令。
mysqldump --all-databases > ~/backup.sql -uroot -p
这里就导出所有库了,如果要指定库可以通过–help查看帮助命令。
将导出的备份通过SFTP或者任何手段将其传输到问题节点上,然后执行下面的命令进行导入。
mysql>
source /home/richie696/backup.sql;
等待倒入结束以后,用上面记录的File和Position重新指定和master的同步信息。首先,先进入mysql的cli,然后执行一下命令:
mysql>
stop slave;
mysql>reset slave;
mysql>change master to master_host='10.20.1.158',master_port=15588,master_user='root',master_password='root',master_log_file='mysql-bin.000003',master_log_pos=16856;
mysql>start slave;
执行完以后,我们就可以查看同步状态了。
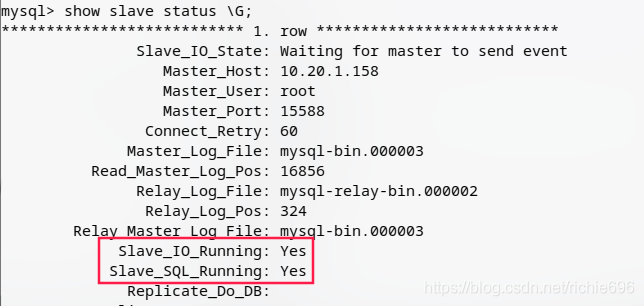
现在可以看到,已经OK了。
2.3.2. 数据量较大
如果数据量较大,通过导库的方法就有点太久了,我们可以利用mysqlbinlog导出binlog里面出问题那个时间点直到最新时间的所有这段期间内的sql语句,然后将导出的sql信息传输到slave节点上执行,以同步到当前时间节点,将不同步的数据给恢复掉,然后重新change master,指定新的位置,从这个位置开始同步。
所有的步骤都和数据量较小的方案差不多,唯一不同的是导出数据库的时候不是导出整个库,而是从binlog中导出指定时间段的sql语句,然后扔到问题slave上进行恢复操作,导出命令如下:
mysqlbinlog --start-datetime="2021-03-01 12:50:00" "/var/lib/mysql/mysql-bin.000003" > ~/backup_20210301.sql
或
mysqlbinlog --start-position="xxxx" --stop-position="xxxx" "/var/lib/mysql/mysql-bin.000003" > ~/backup_20210301.sql
将导出的sql参照数据量较小的方案继续后面的操作即可。
3. MHA高可用服务环境搭建
这里采用的是MySQL Router进行相应的环境搭建,之所以没有使用MySQL Proxy,多方面原因,MySQL Proxy已于2014年开始停止更新,MySQL官方也不再建议使用,加之MySQL服务器我使用的也是MySQL 8,使用MySQL Proxy会有各种奇葩问题,所以选择了MySQL Router,那么操作的具体步骤如下:
3.1. MySQL Router配置
我们先从官网下载的MySQL Router
下载地址:https://dev.mysql.com/downloads/router/
选择自己需要的版本并下载安装,我这里使用的是deb包,所以安装就不废话了。安装结束以后,修改**/etc/mysqlrouter/mysqlrouter.conf**该文件内容,增加路由节点配置,具体信息如下:
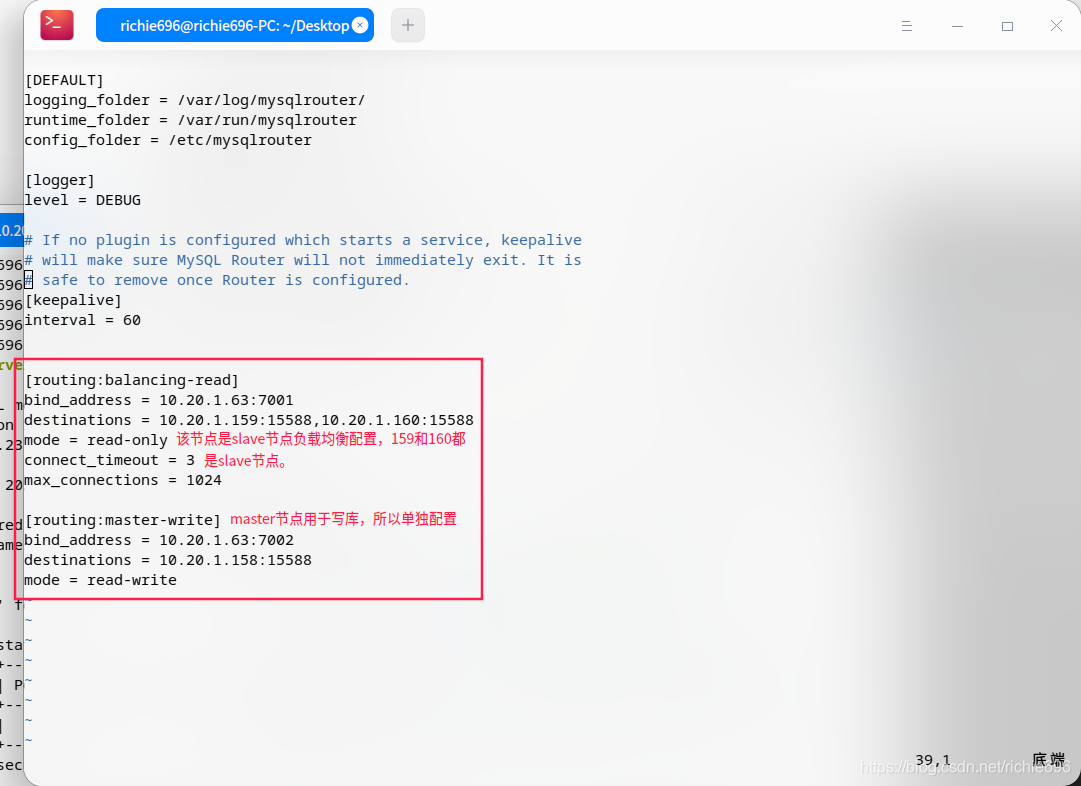
更多的其他配置可以参考官方文档:
https://dev.mysql.com/doc/mysql-router/8.0/en/mysql-router-conf-options.html
下面,可以启动mysqlrouter了,执行以下命令:
sudo mysqlrouter -c /etc/mysqlrouter/mysqlrouter.conf &
启动好以后,在终端输入命令(10.20.1.63是我物理机,也就是真机的IP,上面搭建了MySQL Router)
mysql -h10.20.1.63 --port 7002 -uroot -p
下面我们就可以通过路由的地址对集群环境操作了。
4. MHA高可用架构模式配置
4.1. mha4mysql
本章开始,我们将在上述已搭建好的主从模式基础上,建立MHA高可用架构模式,可以很好的保证MySQL的高可用性,当master挂掉以后可以有其他指定的备选master顶替,持续提供服务。MHA高可用架构的架构图如下:
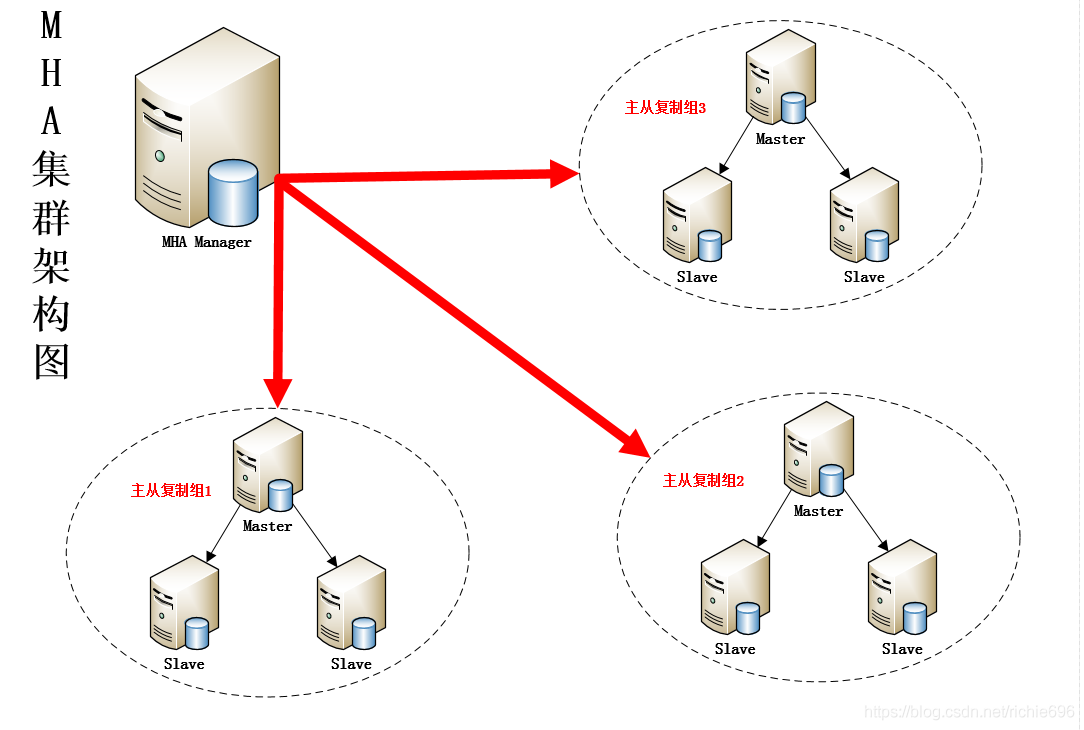
MySQL数据库的集群环境应为不像Zookeeper有自动选举的机智,所以他的主从模式集群主库通常只有1台,这样这台master就万分的重要了,他的健康关乎者整个系统的安全和稳定,而MHA架构就相当于给主从架构加了一道保险,可以实现有多台master,在主master出故障以后可以自动将指定的slave提升为master,并将其他的slave节点指向从之前故障的master指向到新的master上,以继续提供服务。这很好的解决了MySQL数据库集群在主库的宕机以后就无法提供服务的情况了。这里做一个简要的介绍,那么废话不多说直接上干货,这里采用的是mha4mysql来进行搭建,下面来讲解一下具体的搭建环境。
- 操作系统:Ubuntu Server 20.04.2
- 数据库版本:MySQL 8.0.23
- 组建版本:mha4mysql-0.58
- 服务器信息:
– 10.20.1.156(MHA Manager)
– 10.20.1.157(Master库)
– 10.20.1.158(Master备用库,没出问题的时候它就是台Slave-1)
– 10.20.1.159(Slave-2)
– 10.20.1.160(Slave-3)
下面,就开始说一下搭建的具体流程,mha4mysql的搭建流程可以说是噩梦,下面在搭建过程中除非是非常重要的地方,否则我不会特别强调什么地方容易出问题,我会将容易出问题的点总结的第三节中统一说明,以确保第二节搭建过程的顺畅,这玩意简直问题太多。
4.2. 准备工作
首先,万分重要的一点说明是,后续的操作严重推荐大家在linux的root账户下完成,否则在后面建立ssh无密码访问以后,mha4mysql在建立链接测试的时候会碰到无止境的权限问题,为了避免麻烦请尽量使用root账号。下面我们开始吧!
- 安装基础软件包
10.20.1.156(mha-manager)
$ sudo apt install mha4mysql-manager -y
10.20.1.157(master)、10.20.1.158(slave-1)、10.20.1.159(slave-2)、10.20.1.160(slave-3)
$ sudo apt install mha4mysql-node -y
然后我们去github上下载源码包,一会儿需要用到里面的配置文件,当然你自己手写也可以,我比较懒。
源码包下载地址:https://github.com/yoshinorim/mha4mysql-node/releases/tag/v0.58
软件包下载好后先备用。下面开始建立5台服务器之间的无密码访问。
4.3. 建立SSH无密码访问
所有的机器都需要有无密码访问,在建立并发送RSA公钥的时候除了你当前操作的服务器不用搞之外,其他的节点都需要接收到当前服务器的公钥,否则后续会出问题,这里大家一定要该用Linux的root账号切记,其他多余情况我就不说了,如果你有本事就自己折腾,我这里就因为root权限问题掉坑了,搞了整整一下午。(不说了,说多了都是泪。)
在每一台机器上都建立用于ssh访问的rsa密钥
$ ssh-keygen -t rsa
下面3步全部回车,不用输入任何内容,这里也是个坑,否则后面也容易出问题。
所有服务器的证书都建立好以后,开始进行无聊的密钥发送过程。
10.20.1.156(mha-manager)
$ ssh-copy-id 10.20.1.157
$ ssh-copy-id 10.20.1.158
$ ssh-copy-id 10.20.1.159
$ ssh-copy-id 10.20.1.160
10.20.1.157(master)
$ ssh-copy-id 10.20.1.156
$ ssh-copy-id 10.20.1.158
$ ssh-copy-id 10.20.1.159
$ ssh-copy-id 10.20.1.160
10.20.1.158(slave-1)
$ ssh-copy-id 10.20.1.156
$ ssh-copy-id 10.20.1.157
$ ssh-copy-id 10.20.1.159
$ ssh-copy-id 10.20.1.160
10.20.1.159(slave-2)
$ ssh-copy-id 10.20.1.156
$ ssh-copy-id 10.20.1.157
$ ssh-copy-id 10.20.1.158
$ ssh-copy-id 10.20.1.160
10.20.1.160(slave-3)
$ ssh-copy-id 10.20.1.156
$ ssh-copy-id 10.20.1.157
$ ssh-copy-id 10.20.1.158
$ ssh-copy-id 10.20.1.169
期间,每一台都会让你“确认”和输入对应机器的密码,非常无聊。
等全部建立完以后使用
$ ssh root@10.20.1.156/157/158/159/160
一台台的连接,连接的时候如果需要密码就证明没有配置免密成功,重新检查一下。
4.4. 写mha4mysql的配置文件
上一步结束以后,就可以开始写配置文件了,写好配置文件就是需要开始测试连接了。解压缩前面下载的源代码,然后复制其中的 /samples/conf/masterha_default.cnf 文件到 /etc/masterha/config.cnf,然后打开 /samples/conf/app1.cnf 文件,将其内容复制出来,全部合并到 /etc/masterha/config.cnf 当中,合并以后效果如下:
[server default]
# MySQL管理员账号
user=root
password=root# 需要同步的服务器root账号,这里建议用root,不要用其它
# 的,除非你能解决权限冲突导致的问题,否则不要轻易尝试。
ssh_user=root# binlog文件所在路径,上一步之所以要让你用root就是因为
# 这个目录权限指定为mysql用户,或者root用户,否则没有权
# 限访问,在后续配置过程中mha自检的时候会报错。
master_binlog_dir=/var/lib/mysql# 数据库服务器节点保存mha日志的位置
remote_workdir=/opt/masterha
# 心跳检测的间隔时间(单位:秒)
ping_interval=1# 进行MHA管理的MySQL账号
repl_password=manager
repl_user=mha# MHA Manager 本机的管理日志和工作目录
manager_workdir=/opt/masterha
manager_log=/var/log/masterha.log# Master节点配置
[server1]
hostname=10.20.1.157
port=15588# Slave-1(备选Master)节点配置
[server2]
hostname=10.20.1.158
port=15588
# 指定该节点可作为备选节点
candidate_master=1
check_repl_delay=0# Slave-2节点配置
[server3]
hostname=10.20.1.159
port=15588
# 指定该节点不能作为备选master
no_master=1# Slave-3节点配置
[server4]
hostname=10.20.1.160
port=15588
# 指定该节点不能作为备选master
no_master=1
这里只用到最简单的参数,其他更全面的参数说明可参考下文:
https://www.cnblogs.com/xiaoboluo768/p/5973827.html
保存以后退出,下面开始进行测试。
4.5. 检查工具测试配置文件
- 检查ssh无密码访问是否成功
$ masterha_check_ssh --conf=/etc/masterha/config.cnf
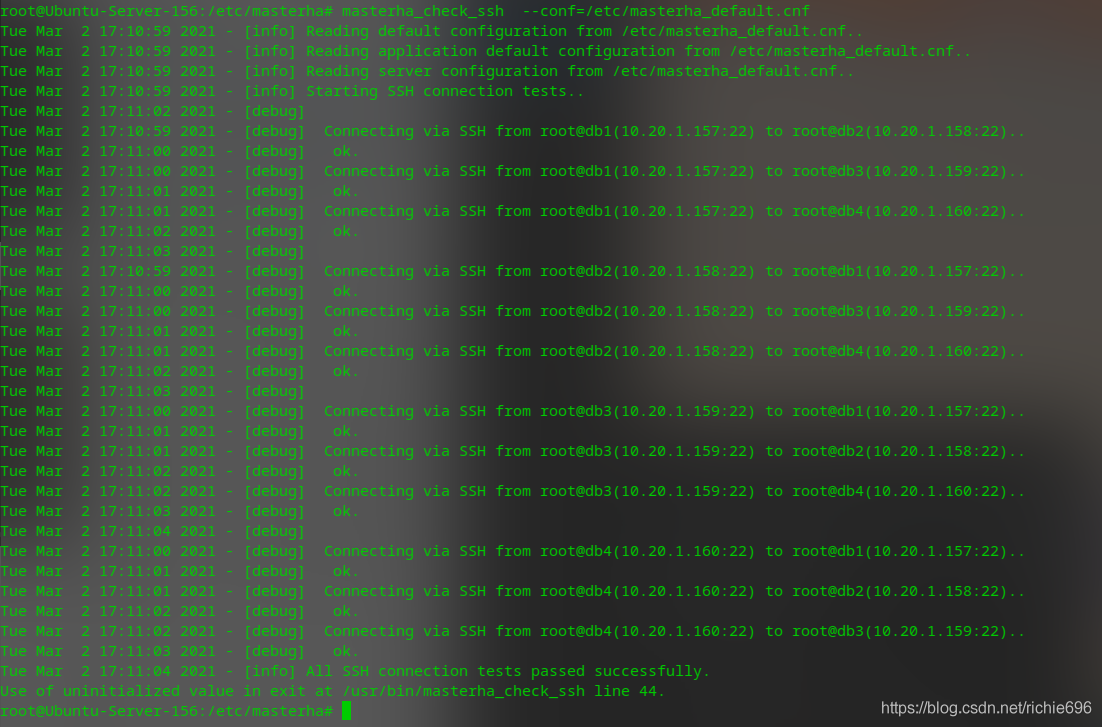 这样就证明pass了。如果没过就证明前面建立的节点有问题,根据错误提示进行拍错。
这样就证明pass了。如果没过就证明前面建立的节点有问题,根据错误提示进行拍错。
- 检查配置文件是否有错
$ masterha_check_repl --conf=/etc/masterha/config.cnf
这一步检查基本和噩梦差不多,各种错误。只能神挡杀神、佛挡杀佛了。网上有很多人总结果错误列表,我这里提供一个别人整理的,后面我会补充我碰到被人没碰到的问题。
https://blog.51cto.com/15103025/2643319
https://yq.aliyun.com/articles/291477
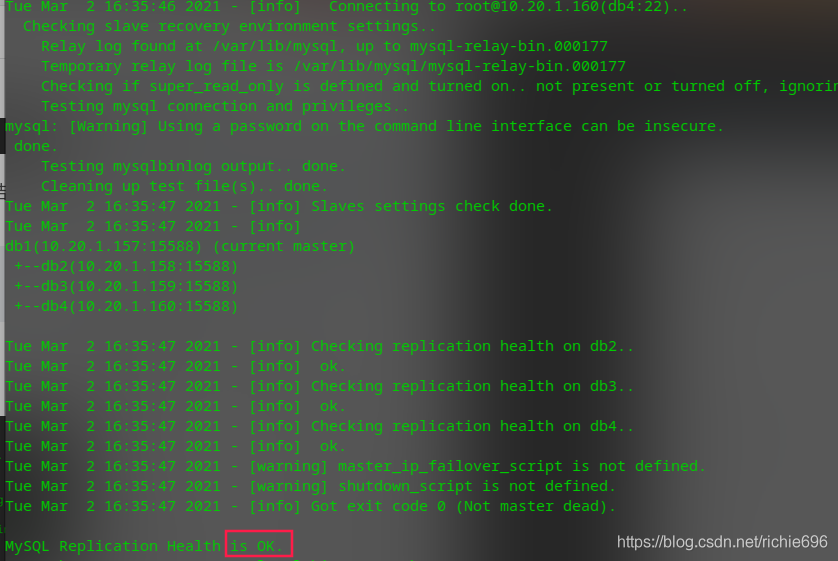 当你有幸看到“is OK”的提示,就证明你通过了,为了看这句话,我等了几个小时。
当你有幸看到“is OK”的提示,就证明你通过了,为了看这句话,我等了几个小时。
4.6. 搭建流程问题汇总
下面,汇总一下我碰到的问题,因为网上大多数的配置都是基于CentOS的,基于Debian/Ubuntu的我就没找到一个,虽然大体上没多大差别,但是也是有些许不同的,所以我来补充一下吧!
问题1: 当你看到这句错误的时候,就证明你的数据库集群环境出了问题,赶紧去检查一下吧!
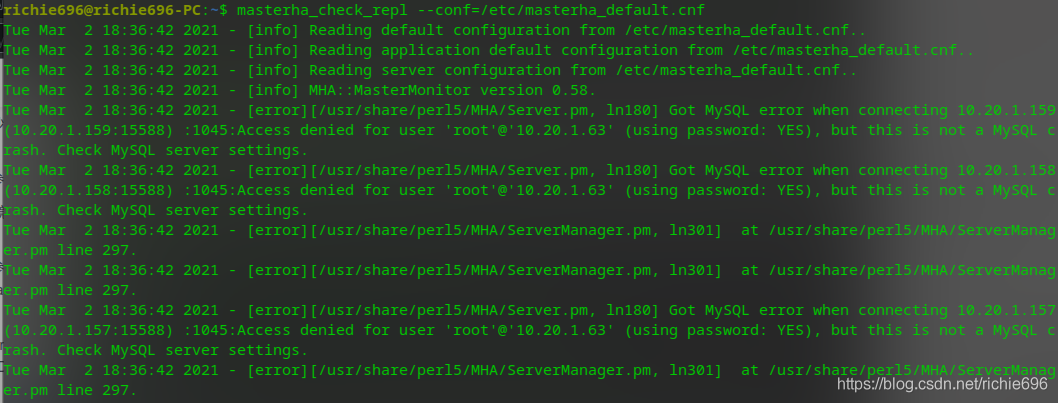
问题2: MySQL8.0数据库所有用于mha4mysql配置的账户都不能使用caching_sha2_password密码认证格式,请使用旧版本的mysql_native_password,否则无法进行认证登陆。
问题3: 如果看到这个错误,请不要怀疑,是你的MySQL版本尚未得到mha4mysql的支持,他里面的perl代码检查mysql版本的地方还不检测不到你的版本,需要修改源代码,具体步骤看下方。
Fri Mar 8 11:31:30 2019 - [error][/usr/share/perl5/MHA/MasterMonitor.pm, ln427] Error happened on checking configurations. Redundant argument in sprintf at /usr/share/perl5/MHA/NodeUtil.pm line 201.
Fri Mar 8 11:31:30 2019 - [error][/usr/share/perl5/MHA/MasterMonitor.pm, ln525] Error happened on monitoring servers.
# 原代码
#sub parse_mysql_major_version($) {
# my $str = shift;
# my $result = sprintf( '%03d%03d', $str =~ m/(\d+)/g );
# return $result;
#}# 改动后代码
sub parse_mysql_major_version($) {
my $str = shift;$str =~ /(\d+)\.(\d+)/;my $strmajor = "$1.$2";my $result = sprintf( '%03d%03d', $strmajor =~ m/(\d+)/g );return $result;
}
改完以后重新去执行吧!
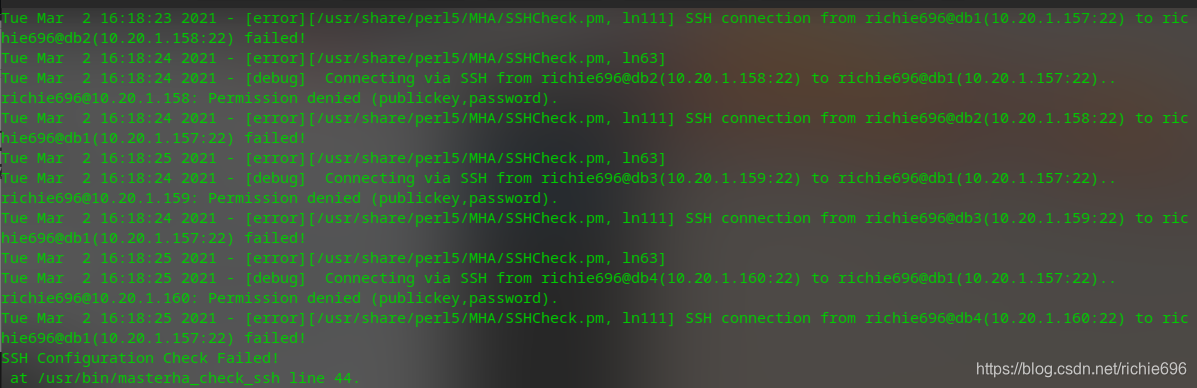
问题4: 看到这个错误的时候一般都是在 masterha_check_repl 检查配置文件的时候发生的,这里是SSH登陆节点服务器出问题导致的,但是你回去用 masterha_check_ssh 检查的时候又是正常的,可就这里过不去,如果你真的碰到了,那么恭喜你,你中招了。我前面反复说的要使用Linux root账号进行登陆和同步,否则你会碰到权限问题,导致后续无法进行,我说的就是这样。这里ssh建立成功了,但是用你提供的ssh_user账号无权限访问binlog所在目录,通常这个目录是/var/lib/mysql,这个目录只有mysql账号和root账号有权限。赶紧去修改你的ssh账号为root吧!
这篇关于MySQL8.0高级应用———集群模式配置(主从、双主、MHA高可用模式配置)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




