本文主要是介绍美国各流域边界下载,并利用arcgis提取与处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、边界数据的下载
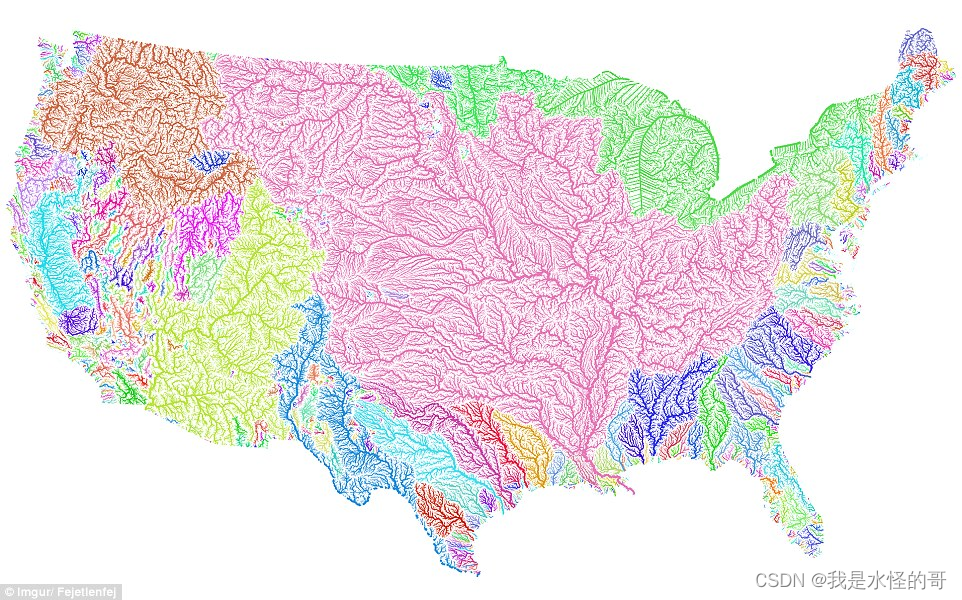
一般使用最普遍的流域边界数据是从HydroSHEDS官网下载:
HydroBASINS代表一系列矢量多边形图层,以全球尺度呈现次级流域边界。该产品的目标是提供一种无缝的全球覆盖,其中包含了不同尺度(从数十到数百万平方千米)的大小一致且分层嵌套的次级流域,同时支持一种编码方案,可用于分析集水区拓扑结构,例如上下游连通性。HydroBASINS是从15角秒分辨率的HydroSHEDS核心图层中提取的。
https://www.hydrosheds.org/products/hydrobasins
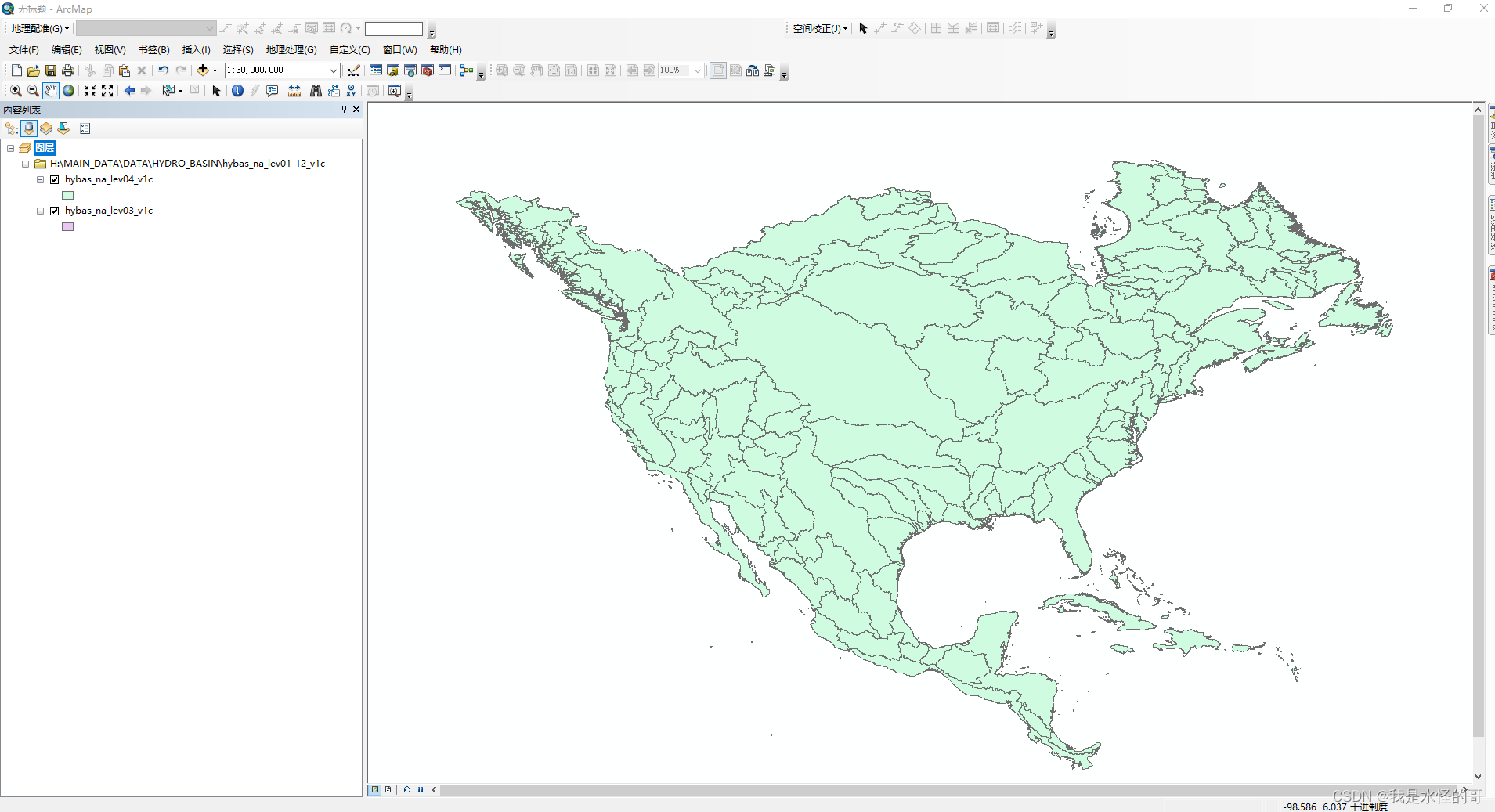
在arcgis中显示得到北美洲地区的各级流域,其中的level01-level12代表各流域的精细程度不断增加。
此外,针对于美国地区,可以在美国USGS中下载Watershed Boundary Dataset:
https://www.usgs.gov/national-hydrography/watershed-boundary-dataset
2位数水文单元边界可单独获取,每个流域都有相应的数据。例如,密苏里流域边界是一个称为WBD_10_HU2_Shape.zip的单个下载文件。此文件包括以下内容:
- WBDLine,包含所有排水线(河流)的线图层。
- 8种不同级别的水文单元多边形(WBDHU16、WBDHU14、...、WBDHU2)。
- NWIS排水线和区域数据。
- 非贡献性排水线和区域数据。
以下是美国所有2位数水文单元的直接链接,以shapefile格式提供。您可以通过将每个zip文件中的WBDHU2图层拼接在一起来重新创建国家级WBD图层。根据您发布的图像,您可能希望包括一些东海岸、墨西哥湾沿岸和落基山脉的较小子流域。我没有看到明显的模式表明哪些流域以不同的颜色编码,因此您可能需要从不同的HUC级别手动选择您需要的流域。专业提示:HUC编号越大,流域越小,即HUC-2流域最大,而HUC-16最小。
网站还提供了一个检索的在线平台:TNM Download v2

二、边界数据的下载
使用arcgis软件,我们可以将下载的边界数据进行处理和分析。我们通常需要的是包含经纬度的txt边界文件。下面以美国密西西比河流域和子流域为例,介绍如何得到边界文件。
我们提取得到了密西西比河流域的2级和4级子流域。在arcgis中,选择工具箱的【数据管理工具】---【要素】---【要素折点转点】,选择我们需要的2级数据,点击运行。

我们注意到,在属性表中并没有经纬度信息,因此需要选择数据管理工具】---【要素】---【添加XY坐标】,结果在属性表中多了经纬度信息。


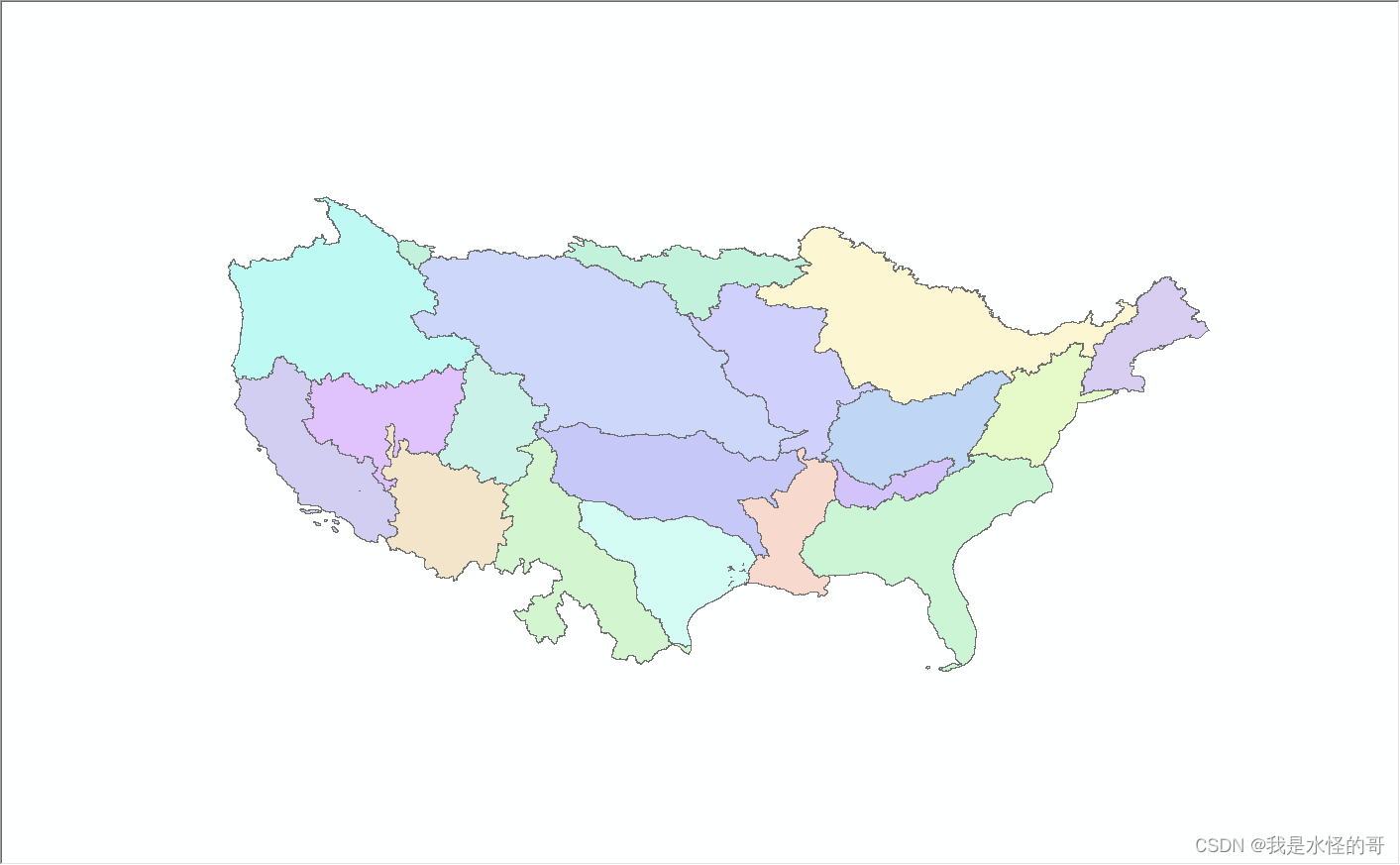
下面是整个美国地区所有流域及其子流域:
参考资料:
geospatial - Where to find USA river basins data shapefile? - Open Data Stack Exchange
感谢chatGPT对翻译的大力支持!
这篇关于美国各流域边界下载,并利用arcgis提取与处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


