本文主要是介绍论文阅读——Pyramid Grafting Network for One-Stage High Resolution Saliency Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 基本信息
- 标题
- 目前存在的问题
- 改进
- 网络结构
- CMGM模块
- 解答
- 为什么要用这两个编码器进行编码
- 另一个写的好的参考
基本信息
| 期刊 | CVPR |
|---|---|
| 年份 | 2022 |
| 论文地址 | https://arxiv.org/pdf/2204.05041.pdf |
| 代码地址 | https://github.com/iCVTEAM/PGNet |
标题
金字塔嫁接网络的一级高分辨率显著性检测
目前存在的问题
-
cosod用于低分辨率图片下表现良好,高分辨率下(1080p、2K、4K)分割结果不完整,许多细节区域丢失。随着输入分辨率的急剧增加,所提取特征的大小也随之增大,但由网络决定的感受野是固定的,使得相对感受野较小,最终导致无法捕获对SOD任务至关重要的全局语义。
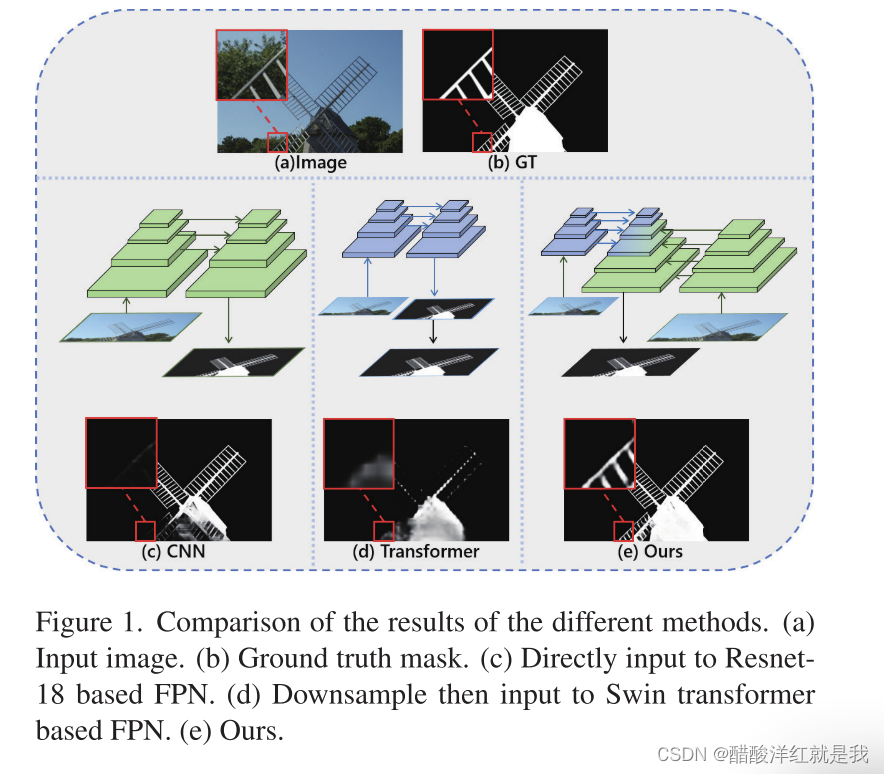
-
高分辨率下目前的两种方法HRSOD,DHQSOD都将SOD划分语义(低分辨率)阶段和详细(高分辨率)阶段,导致2个问题(1)阶段之间的语境语义迁移不一致。将前一阶段得到的中间映射输入到后一阶段,同时传递误差。此外,由于没有足够的语义支持,最后阶段的细化可能会继承甚至放大之前的错误,这意味着最终的显著性映射严重依赖于低分辨率网络的性能。(2)耗时。与单阶段方法相比,多阶段方法不仅难以并行化,而且存在参数数量增加的潜在问题,使其速度较慢。
改进
- PGNet框架使用交错连接来捕获连续语义和丰富的细节
- 引入了跨模型的嫁接模块,将信息从transformer分支转移到CNN分支,这样CNN不仅可以继承全局信息,还可以弥补两者共有的缺陷。此外,我们还设计了注意引导丢失算法来进一步促进特征嫁接。
- 提供了一个新的具有挑战性的超高分辨率显著性检测数据集(UHRSD),包含了5,920张不同场景的图像,分辨率超过4K,并相应的像素显著性标注
网络结构
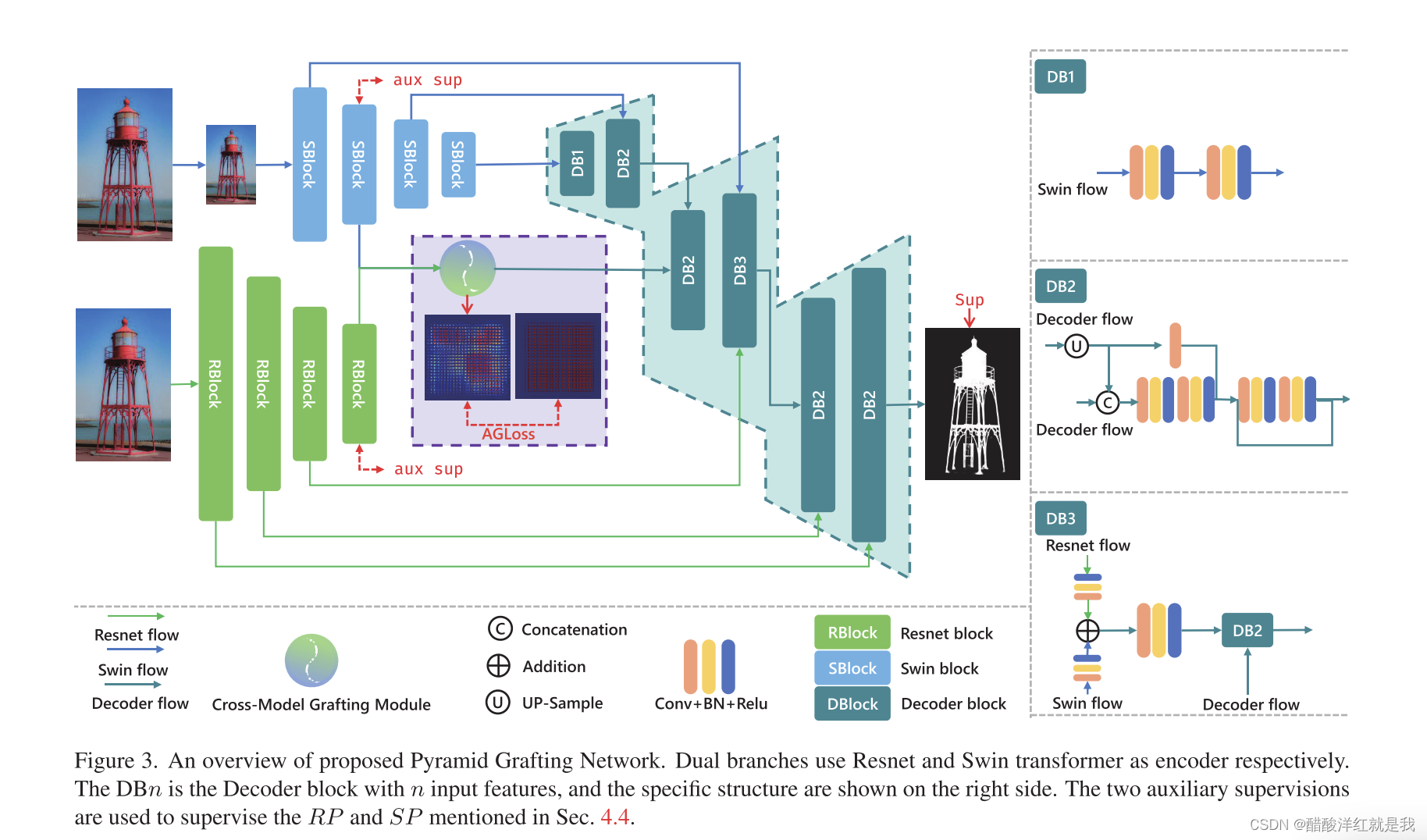
CMGM模块
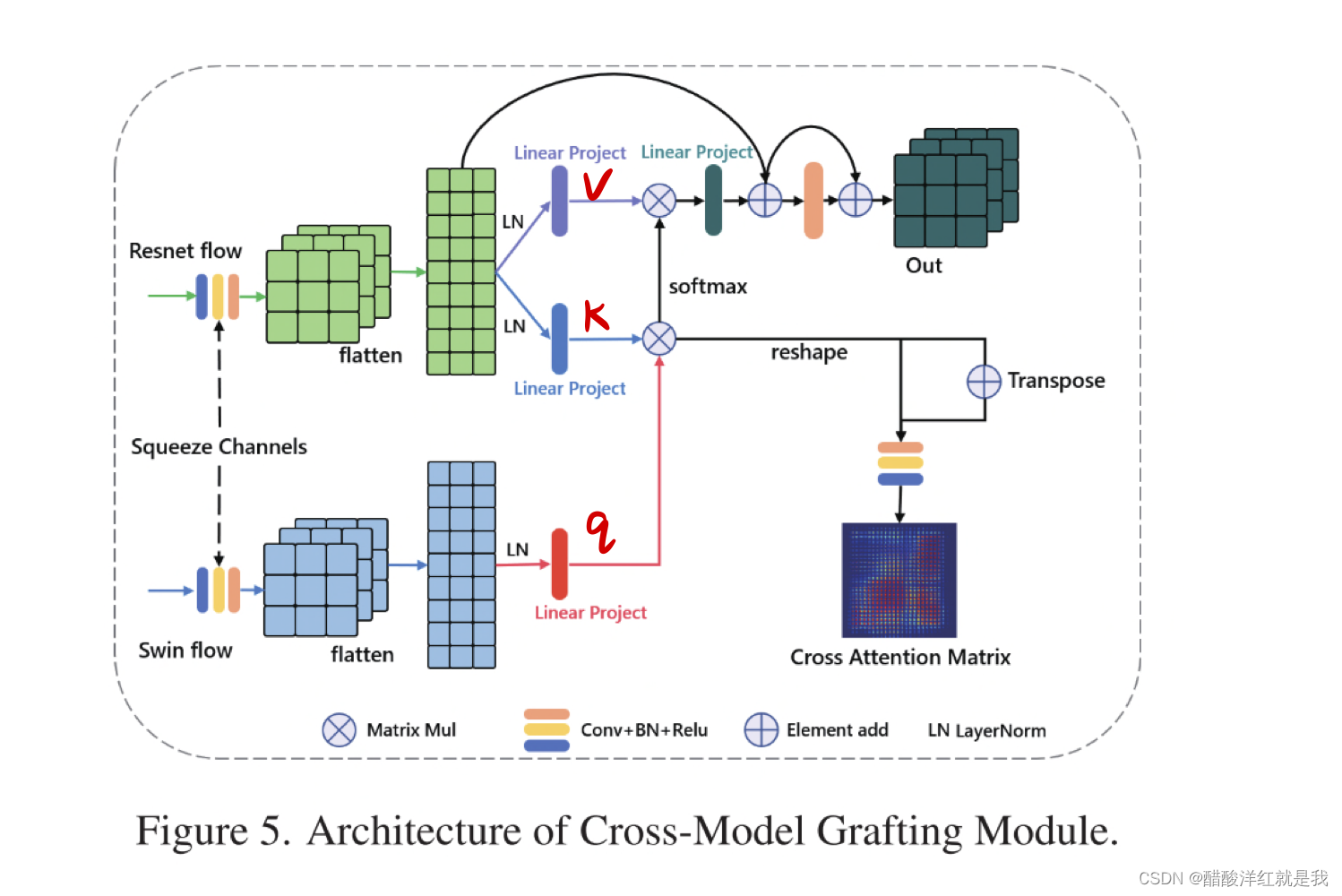
解答
为什么要用这两个编码器进行编码
选择Swin transformer和Resnet-18作为编码器。这种组合的选择是为了平衡效率和效果。一方面,transformer编码器可以在低分辨率的情况下获得准确的全局语义信息,卷积编码器可以在高分辨率的输入下获得丰富的细节。另一方面,不同模型提取的特征的可变性可能是互补的,以更准确地识别显著性
另一个写的好的参考
网址
这篇关于论文阅读——Pyramid Grafting Network for One-Stage High Resolution Saliency Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)