本文主要是介绍目标检测算法改进系列之Backbone替换为RepViT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RepViT简介
轻量级模型研究一直是计算机视觉任务中的一个焦点,其目标是在降低计算成本的同时达到优秀的性能。轻量级模型与资源受限的移动设备尤其相关,使得视觉模型的边缘部署成为可能。在过去十年中,研究人员主要关注轻量级卷积神经网络(CNNs)的设计,提出了许多高效的设计原则,包括可分离卷积 [2] 、逆瓶颈结构 [3] 、通道打乱 [4] 和结构重参数化 [5] 等,产生了 MobileNets [2, 3],ShuffleNets [4] 和 RepVGG [5] 等代表性模型。
另一方面,视觉 Transformers(ViTs)成为学习视觉表征的另一种高效方案。与 CNNs 相比,ViTs 在各种计算机视觉任务中表现出了更优越的性能。然而,ViT 模型一般尺寸很大,延迟很高,不适合资源受限的移动设备。因此,研究人员开始探索 ViT 的轻量级设计。许多高效的ViTs设计原则被提出,大大提高了移动设备上 ViTs 的计算效率,产生了EfficientFormers [6] ,MobileViTs [7] 等代表性模型。这些轻量级 ViTs 在移动设备上展现出了相比 CNNs 的更强的性能和更低的延迟。
轻量级 ViTs 优于轻量级 CNNs 的原因通常归结于多头注意力模块,该模块使模型能够学习全局表征。然而,轻量级 ViTs 和轻量级 CNNs 在块结构、宏观和微观架构设计方面存在值得注意的差异,但这些差异尚未得到充分研究。这自然引出了一个问题:轻量级 ViTs 的架构选择能否提高轻量级 CNN 的性能?在这项工作中,我们结合轻量级 ViTs 的架构选择,重新审视了轻量级 CNNs 的设计。我们的旨在缩小轻量级 CNNs 与轻量级 ViTs 之间的差距,并强调前者与后者相比在移动设备上的应用潜力。
原文地址:RepViT: Revisiting Mobile CNN From ViT Perspective
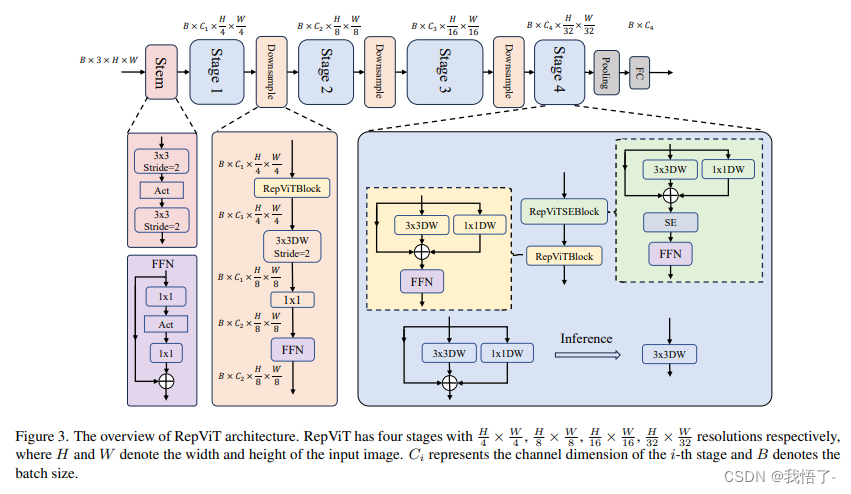
RepViT代码实现
import torch.nn as nn
import numpy as np
from timm.models.layers import SqueezeExcite
import torch__all__ = ['repvit_m1', 'repvit_m2', 'repvit_m3']def replace_batchnorm(net):for child_name, child in net.named_children():if hasattr(child, 'fuse_self'):fused = child.fuse_self()setattr(net, child_name, fused)replace_batchnorm(fused)elif isinstance(child, torch.nn.BatchNorm2d):setattr(net, child_name, torch.nn.Identity())else:replace_batchnorm(child)def _make_divisible(v, divisor, min_value=None):"""This function is taken from the original tf repo.It ensures that all layers have a channel number that is divisible by 8It can be seen here:https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py:param v::param divisor::param min_value::return:"""if min_value is None:min_value = divisornew_v = max(min_value, int(v + divisor / 2) // divisor * divisor)# Make sure that round down does not go down by more than 10%.if new_v < 0.9 * v:new_v += divisorreturn new_vclass Conv2d_BN(torch.nn.Sequential):def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,groups=1, bn_weight_init=1, resolution=-10000):super().__init__()self.add_module('c', torch.nn.Conv2d(a, b, ks, stride, pad, dilation, groups, bias=False))self.add_module('bn', torch.nn.BatchNorm2d(b))torch.nn.init.constant_(self.bn.weight, bn_weight_init)torch.nn.init.constant_(self.bn.bias, 0)@torch.no_grad()def fuse_self(self):c, bn = self._modules.values()w = bn.weight / (bn.running_var + bn.eps)**0.5w = c.weight * w[:, None, None, None]b = bn.bias - bn.running_mean * bn.weight / \(bn.running_var + bn.eps)**0.5m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups,device=c.weight.device)m.weight.data.copy_(w)m.bias.data.copy_(b)return mclass Residual(torch.nn.Module):def __init__(self, m, drop=0.):super().__init__()self.m = mself.drop = dropdef forward(self, x):if self.training and self.drop > 0:return x + self.m(x) * torch.rand(x.size(0), 1, 1, 1,device=x.device).ge_(self.drop).div(1 - self.drop).detach()else:return x + self.m(x)@torch.no_grad()def fuse_self(self):if isinstance(self.m, Conv2d_BN):m = self.m.fuse_self()assert(m.groups == m.in_channels)identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)identity = torch.nn.functional.pad(identity, [1,1,1,1])m.weight += identity.to(m.weight.device)return melif isinstance(self.m, torch.nn.Conv2d):m = self.massert(m.groups != m.in_channels)identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)identity = torch.nn.functional.pad(identity, [1,1,1,1])m.weight += identity.to(m.weight.device)return melse:return selfclass RepVGGDW(torch.nn.Module):def __init__(self, ed) -> None:super().__init__()self.conv = Conv2d_BN(ed, ed, 3, 1, 1, groups=ed)self.conv1 = Conv2d_BN(ed, ed, 1, 1, 0, groups=ed)self.dim = eddef forward(self, x):return self.conv(x) + self.conv1(x) + x@torch.no_grad()def fuse_self(self):conv = self.conv.fuse_self()conv1 = self.conv1.fuse_self()conv_w = conv.weightconv_b = conv.biasconv1_w = conv1.weightconv1_b = conv1.biasconv1_w = torch.nn.functional.pad(conv1_w, [1,1,1,1])identity = torch.nn.functional.pad(torch.ones(conv1_w.shape[0], conv1_w.shape[1], 1, 1, device=conv1_w.device), [1,1,1,1])final_conv_w = conv_w + conv1_w + identityfinal_conv_b = conv_b + conv1_bconv.weight.data.copy_(final_conv_w)conv.bias.data.copy_(final_conv_b)return convclass RepViTBlock(nn.Module):def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs):super(RepViTBlock, self).__init__()assert stride in [1, 2]self.identity = stride == 1 and inp == oupassert(hidden_dim == 2 * inp)if stride == 2:self.token_mixer = nn.Sequential(Conv2d_BN(inp, inp, kernel_size, stride, (kernel_size - 1) // 2, groups=inp),SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),Conv2d_BN(inp, oup, ks=1, stride=1, pad=0))self.channel_mixer = Residual(nn.Sequential(# pwConv2d_BN(oup, 2 * oup, 1, 1, 0),nn.GELU() if use_hs else nn.GELU(),# pw-linearConv2d_BN(2 * oup, oup, 1, 1, 0, bn_weight_init=0),))else:assert(self.identity)self.token_mixer = nn.Sequential(RepVGGDW(inp),SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),)self.channel_mixer = Residual(nn.Sequential(# pwConv2d_BN(inp, hidden_dim, 1, 1, 0),nn.GELU() if use_hs else nn.GELU(),# pw-linearConv2d_BN(hidden_dim, oup, 1, 1, 0, bn_weight_init=0),))def forward(self, x):return self.channel_mixer(self.token_mixer(x))class RepViT(nn.Module):def __init__(self, cfgs):super(RepViT, self).__init__()# setting of inverted residual blocksself.cfgs = cfgs# building first layerinput_channel = self.cfgs[0][2]patch_embed = torch.nn.Sequential(Conv2d_BN(3, input_channel // 2, 3, 2, 1), torch.nn.GELU(),Conv2d_BN(input_channel // 2, input_channel, 3, 2, 1))layers = [patch_embed]# building inverted residual blocksblock = RepViTBlockfor k, t, c, use_se, use_hs, s in self.cfgs:output_channel = _make_divisible(c, 8)exp_size = _make_divisible(input_channel * t, 8)layers.append(block(input_channel, exp_size, output_channel, k, s, use_se, use_hs))input_channel = output_channelself.features = nn.ModuleList(layers)self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def forward(self, x):input_size = x.size(2)scale = [4, 8, 16, 32]features = [None, None, None, None]for f in self.features:x = f(x)if input_size // x.size(2) in scale:features[scale.index(input_size // x.size(2))] = xreturn featuresdef switch_to_deploy(self):replace_batchnorm(self)def update_weight(model_dict, weight_dict):idx, temp_dict = 0, {}for k, v in weight_dict.items():# k = k[9:]if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):temp_dict[k] = vidx += 1model_dict.update(temp_dict)print(f'loading weights... {idx}/{len(model_dict)} items')return model_dictdef repvit_m1(weights=''):"""Constructs a MobileNetV3-Large model"""cfgs = [# k, t, c, SE, HS, s [3, 2, 48, 1, 0, 1],[3, 2, 48, 0, 0, 1],[3, 2, 48, 0, 0, 1],[3, 2, 96, 0, 0, 2],[3, 2, 96, 1, 0, 1],[3, 2, 96, 0, 0, 1],[3, 2, 96, 0, 0, 1],[3, 2, 192, 0, 1, 2],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 384, 0, 1, 2],[3, 2, 384, 1, 1, 1],[3, 2, 384, 0, 1, 1]]model = RepViT(cfgs)if weights:model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))return modeldef repvit_m2(weights=''):"""Constructs a MobileNetV3-Large model"""cfgs = [# k, t, c, SE, HS, s [3, 2, 64, 1, 0, 1],[3, 2, 64, 0, 0, 1],[3, 2, 64, 0, 0, 1],[3, 2, 128, 0, 0, 2],[3, 2, 128, 1, 0, 1],[3, 2, 128, 0, 0, 1],[3, 2, 128, 0, 0, 1],[3, 2, 256, 0, 1, 2],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 512, 0, 1, 2],[3, 2, 512, 1, 1, 1],[3, 2, 512, 0, 1, 1]]model = RepViT(cfgs)if weights:model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))return modeldef repvit_m3(weights=''):"""Constructs a MobileNetV3-Large model"""cfgs = [# k, t, c, SE, HS, s [3, 2, 64, 1, 0, 1],[3, 2, 64, 0, 0, 1],[3, 2, 64, 1, 0, 1],[3, 2, 64, 0, 0, 1],[3, 2, 64, 0, 0, 1],[3, 2, 128, 0, 0, 2],[3, 2, 128, 1, 0, 1],[3, 2, 128, 0, 0, 1],[3, 2, 128, 1, 0, 1],[3, 2, 128, 0, 0, 1],[3, 2, 128, 0, 0, 1],[3, 2, 256, 0, 1, 2],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 512, 0, 1, 2],[3, 2, 512, 1, 1, 1],[3, 2, 512, 0, 1, 1]]model = RepViT(cfgs)if weights:model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))return modelif __name__ == '__main__':model = repvit_m1('repvit_m1_distill_300.pth')inputs = torch.randn((1, 3, 640, 640))res = model(inputs)for i in res:print(i.size())
Backbone替换
yolo.py修改
def parse_model函数
def parse_model(d, ch): # model_dict, input_channels(3)# Parse a YOLOv5 model.yaml dictionaryLOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')if act:Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()LOGGER.info(f"{colorstr('activation:')} {act}") # printna = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchorsno = na * (nc + 5) # number of outputs = anchors * (classes + 5)is_backbone = Falselayers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, argstry:t = mm = eval(m) if isinstance(m, str) else m # eval stringsexcept:passfor j, a in enumerate(args):with contextlib.suppress(NameError):try:args[j] = eval(a) if isinstance(a, str) else a # eval stringsexcept:args[j] = an = n_ = max(round(n * gd), 1) if n > 1 else n # depth gainif m in {Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)# TODO: channel, gw, gdelif m in {Detect, Segment}:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)if m is Segment:args[3] = make_divisible(args[3] * gw, 8)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2elif isinstance(m, str):t = mm = timm.create_model(m, pretrained=args[0], features_only=True)c2 = m.feature_info.channels()elif m in {repvit_m1}: #可添加更多Backbonem = m(*args)c2 = m.channelelse:c2 = ch[f]if isinstance(c2, list):is_backbone = Truem_ = mm_.backbone = Trueelse:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i + 4 if is_backbone else i, f, t, np # attach index, 'from' index, type, number paramsLOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # printsave.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []if isinstance(c2, list):ch.extend(c2)for _ in range(5 - len(ch)):ch.insert(0, 0)else:ch.append(c2)return nn.Sequential(*layers), sorted(save)
def _forward_once函数
def _forward_once(self, x, profile=False, visualize=False):y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)for _ in range(5 - len(x)):x.insert(0, None)for i_idx, i in enumerate(x):if i_idx in self.save:y.append(i)else:y.append(None)x = x[-1]else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return x
创建.yaml配置文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, repvit_m1, [False]], # 4[-1, 1, SPPF, [1024, 5]], # 5]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]], # 6[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 7[[-1, 3], 1, Concat, [1]], # cat backbone P4 8[-1, 3, C3, [512, False]], # 9[-1, 1, Conv, [256, 1, 1]], # 10[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11[[-1, 2], 1, Concat, [1]], # cat backbone P3 12[-1, 3, C3, [256, False]], # 13 (P3/8-small)[-1, 1, Conv, [256, 3, 2]], # 14[[-1, 10], 1, Concat, [1]], # cat head P4 15[-1, 3, C3, [512, False]], # 16 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]], # 17[[-1, 5], 1, Concat, [1]], # cat head P5 18[-1, 3, C3, [1024, False]], # 19 (P5/32-large)[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
这篇关于目标检测算法改进系列之Backbone替换为RepViT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







