本文主要是介绍图像压缩:Transformer-based Image Compression with Variable Image Quality Objectives,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文作者:Chia-Hao Kao,Yi-Hsin Chen,Cheng Chien,Wei-Chen Chiu,Wen-Hsiao Peng
作者单位:National Yang Ming Chiao Tung University
论文链接:http://arxiv.org/abs/2309.12717v1
内容简介:
1)方向:基于Transformer的图像压缩系统
2)应用:图像压缩,可变图像质量
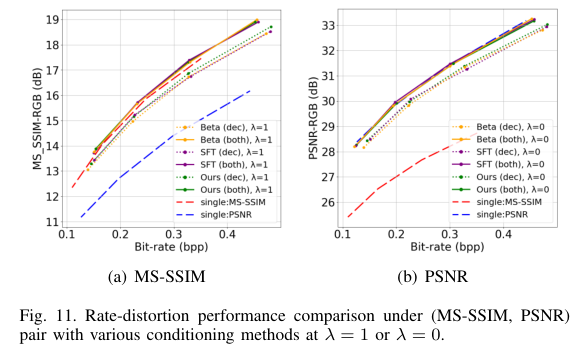
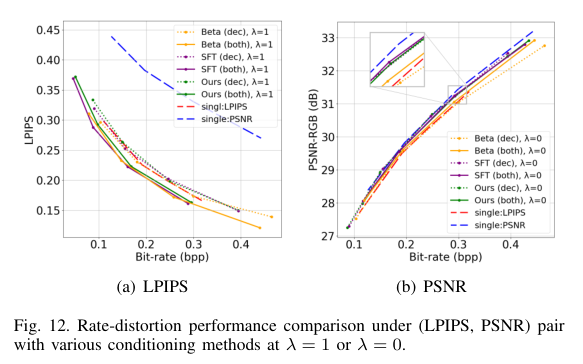
3)背景:传统的图像压缩系统在不同质量目标下的优化通常会导致重建图像具有不同的视觉特征。本方法提供了用户使用单一共享模型在两个图像质量目标之间进行权衡的灵活性。
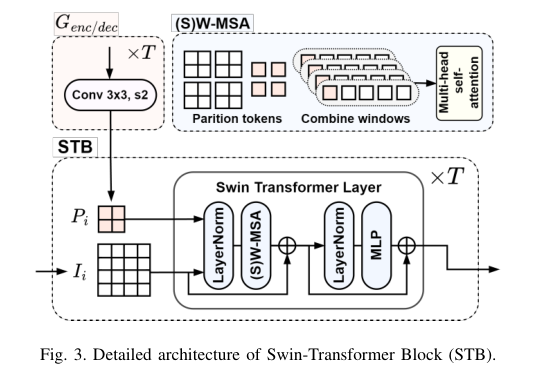
4)方法:本文提出了一种基于Transformer的图像压缩系统,允许根据用户的偏好设定不同的图像质量目标,从而获得视觉特性各异的重建图像。具体来说,作者采用了prompt-tuning技术的成功经验,引入提示记号以调节基于Transformer的自动编码器。这些提示记号是根据用户偏好和输入图像通过学习提示生成网络自适应生成的。这样的方法使得用户可以使用单一共享模型在两个图像质量目标之间进行权衡选择。说,作者
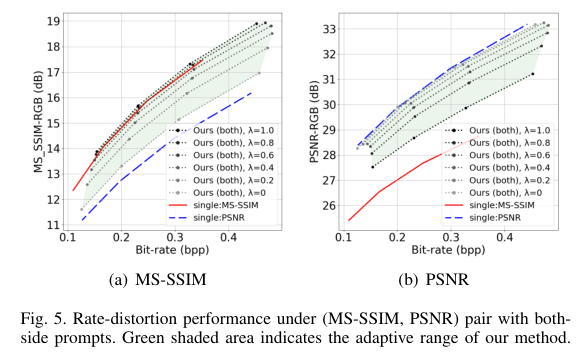
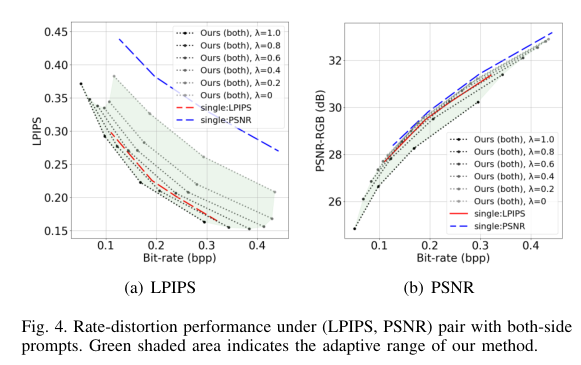
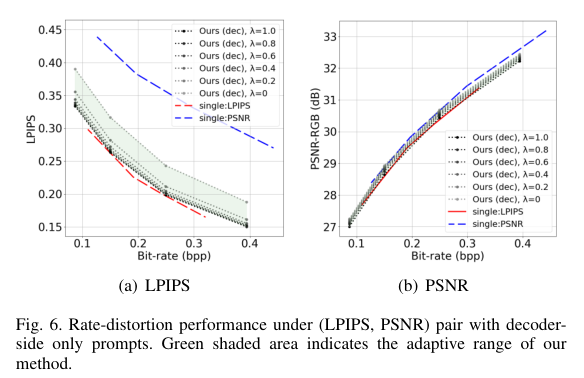
5)结果:大量实验证明了本方法在适应可变质量目标时,调整编码和/或解码过程的有效性。在提供额外灵活性的同时,我们提出的方法在速率失真性能方面与单一目标方法表现相当。






这篇关于图像压缩:Transformer-based Image Compression with Variable Image Quality Objectives的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







