本文主要是介绍深入理解二叉搜索树(BST),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一棵二叉搜索树(BST)是以一棵二叉树来组织的,可以用链表数据结构来表示,其中,每一个结点就是一个对象,一般地,包含数据内容key和指向孩子(也可能是父母)的指针属性。如果某个孩子结点不存在,其指针属性值为空(NIL)。
二叉搜索树中的关键字key的存储方式总是满足二叉搜索树的性质:
设x是二叉搜索树中的一个结点。如果y是x左子树中的一个结点,那么会有y.key<=x.key;如果y是x右子树中的一个节点,那么有y.key>=x.key。
二叉搜索树中的关键字key的存储方式总是满足二叉搜索树的性质:
设x是二叉搜索树中的一个结点。如果y是x左子树中的一个结点,那么会有y.key<=x.key;如果y是x右子树中的一个节点,那么有y.key>=x.key。
二叉搜索树查找:
顾名思义,二叉搜索树很多时候用来进行数据查找。这个过程从树的根结点开始,沿着一条简单路径一直向下,直到找到数据或者得到NIL值。
顾名思义,二叉搜索树很多时候用来进行数据查找。这个过程从树的根结点开始,沿着一条简单路径一直向下,直到找到数据或者得到NIL值。
如下图所示:
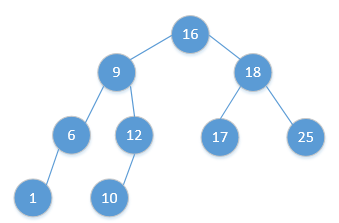
由图可以看出,对于遇到的每个结点x,都会比较x.key与k的大小,如果相等,就终止查找,否则,决定是继续往左子树还是右子树查找。因此,整个查找过程就是从根节点开始一直向下的一条路径,若假设树的高度是h,那么查找过程的时间复杂度就是O(h)。
BST查找的递归算法与非递归算法伪代码分别如下:
BST查找的递归算法与非递归算法伪代码分别如下:
//递归实现
Tree_Search(x, k):
if x == NIL or x.key == k :return x
if k < x.keyreturn Tree_Search(x.left, k)
else return Tree_Search(x.right, k)//非递归迭代实现
Tree_Search(x, k) :
while x!=NIL and k!=x.key:if k < x.keyx = x.leftelse x = x.right
return x一般来说,迭代方式的效率比递归方式高很多。
前驱和后继:
对于给定的一棵二叉搜索树,如果所有结点的key均不相同,那么结点x的前驱是指小于x.key的最大关键字的结点;而一个结点x的后继是指大于x.key的最小关键字的结点。
现在,我们考虑如何求解一个结点x的后继,(求前驱也类似,对称的结构):
对于结点x,如果其右子树不为空,那么x的后继一定是其右子树的最左边的结点。而如果x的右子树为空,并且有一个后继,那么其后继必然是x的最底层的祖先,并且后继的左孩子也是x的一个祖先,因此,为了找到这样的后继结点,只需要从x开始沿着树向上移动,直到遇到一个结点,这个结点是它的双亲的左孩子。(例如,在上图的例子中,结点12的后继结点是16.)
给出求后继结点的伪代码:
前驱和后继:
对于给定的一棵二叉搜索树,如果所有结点的key均不相同,那么结点x的前驱是指小于x.key的最大关键字的结点;而一个结点x的后继是指大于x.key的最小关键字的结点。
现在,我们考虑如何求解一个结点x的后继,(求前驱也类似,对称的结构):
对于结点x,如果其右子树不为空,那么x的后继一定是其右子树的最左边的结点。而如果x的右子树为空,并且有一个后继,那么其后继必然是x的最底层的祖先,并且后继的左孩子也是x的一个祖先,因此,为了找到这样的后继结点,只需要从x开始沿着树向上移动,直到遇到一个结点,这个结点是它的双亲的左孩子。(例如,在上图的例子中,结点12的后继结点是16.)
给出求后继结点的伪代码:
Tree_Successor(x):
if x.right != NILreturn Tree_MinNode(x.right)
y = x.p
while y!=NIL and x == y.rightx = yy = y.p
return yTree_MinNode(x):
while x.left != NILx = x.left
return xBST插入
BST的插入过程非常简单,很类似与二叉树搜索树的查找过程。当需要插入一个新结点时,从根节点开始,迭代或者递归向下移动,直到遇到一个空的指针NIL,需要插入的值即被存储在该结点位置。这里给出迭代插入算法,递归方式的比较简单。
BST的插入过程非常简单,很类似与二叉树搜索树的查找过程。当需要插入一个新结点时,从根节点开始,迭代或者递归向下移动,直到遇到一个空的指针NIL,需要插入的值即被存储在该结点位置。这里给出迭代插入算法,递归方式的比较简单。
Tree_Insert(T, z):
y = NIL
x = T.root
while x != NILy = xif z.key < x.keyx = x.leftelse x = x.right
z.p = y
if y == NILT.root = z
else if z.key < y.keyy.left = z
else y.right = z下图给出插入结点17的示意图:
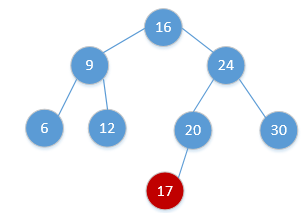
同其他搜索树类似于,二叉搜索树(BST)的插入操作的时间复杂度为O(h).
BST删除
二叉搜索树的结点删除比插入较为复杂,总体来说,结点的删除可归结为三种情况:
1、 如果结点z没有孩子节点,那么只需简单地将其删除,并修改父节点,用NIL来替换z;
2、 如果结点z只有一个孩子,那么将这个孩子节点提升到z的位置,并修改z的父节点,用z的孩子替换z;
3、 如果结点z有2个孩子,那么查找z的后继y,此外后继一定在z的右子树中,然后让y替换z。
二叉搜索树的结点删除比插入较为复杂,总体来说,结点的删除可归结为三种情况:
1、 如果结点z没有孩子节点,那么只需简单地将其删除,并修改父节点,用NIL来替换z;
2、 如果结点z只有一个孩子,那么将这个孩子节点提升到z的位置,并修改z的父节点,用z的孩子替换z;
3、 如果结点z有2个孩子,那么查找z的后继y,此外后继一定在z的右子树中,然后让y替换z。
这三种情况中,1和2比较简单,3相对棘手。
我们通过示意图,描述这几种情况:
情况1:

我们通过示意图,描述这几种情况:
情况1:
情况2:
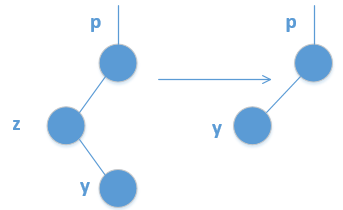
情况3:
可分为两种类型,一种是z的后继y位于其右子树中,但没有左孩子,也就是说,右孩子y是其后继。如下:
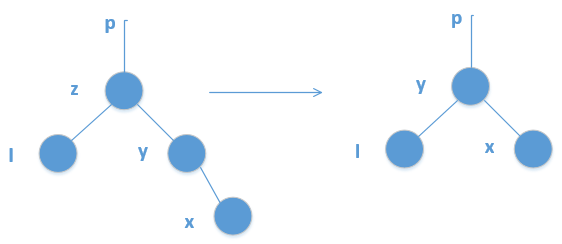
另外一种类型是,z的后继y位于z的右子树中,但并不是z的右孩子,此时,用y的右孩子替换y,然后再用y替换z。如下:
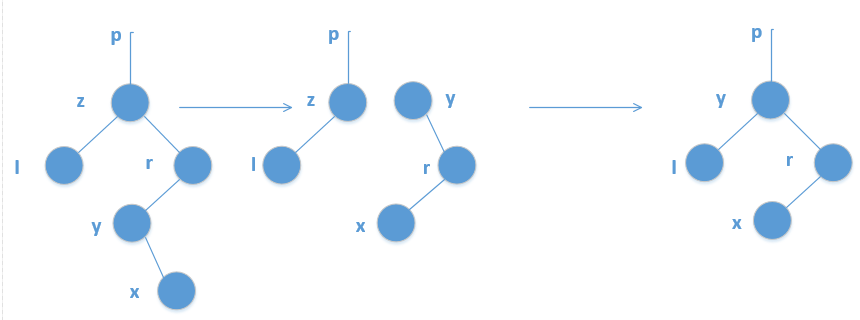
二叉树的遍历:
最后,我们考虑二叉搜索树的遍历。
二叉搜索树的性质允许通过简单的递归算法来输出树中所有的关键字,有三种方式:先序遍历、中序遍历、后序遍历。其中,先序遍历中输出根的关键字在其左右子树的关键字之前;中序遍历中输出根的关键词位于其左子树的关键字和右子树的关键字之间;后序遍历中输出根的关键字在左右子树的关键字之后。
如果x是一棵有n个结点子树的根,那么调用Preorder_Tree_Walk(x)或者Inorder_Tree_Walk(x)或者Postorder_Tree_Walk(x)需要O(n)时间。
最后,我们考虑二叉搜索树的遍历。
二叉搜索树的性质允许通过简单的递归算法来输出树中所有的关键字,有三种方式:先序遍历、中序遍历、后序遍历。其中,先序遍历中输出根的关键字在其左右子树的关键字之前;中序遍历中输出根的关键词位于其左子树的关键字和右子树的关键字之间;后序遍历中输出根的关键字在左右子树的关键字之后。
如果x是一棵有n个结点子树的根,那么调用Preorder_Tree_Walk(x)或者Inorder_Tree_Walk(x)或者Postorder_Tree_Walk(x)需要O(n)时间。
//先序遍历
Preorder_Tree_Walk(x):
if x!=NIL:print x.keyPreorder_Tree_Walk(x.left)Preorder_Tree_Walk(x.right)
//中序遍历
Inorder_Tree_Walk(x):Inorder_Tree_Walk(x.left)print x.keyInorder_Tree_Walk(x.right)//后序遍历
Postorder_Tree_Walk(x):Postorder_Tree_Walk(x.left)Postorder_Tree_Walk(x.right)print x.key这篇关于深入理解二叉搜索树(BST)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




