本文主要是介绍艾瑞白皮书解读(四)丨深度解析企业数据治理第一步:咨询环节,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2024年7月 艾瑞咨询公司对国内数据治理行业进行了研究,访问了国内多位大中型企业数据治理相关负责人,深度剖析中国企业在数字化转型过程中面临到的核心数据问题后,重磅发布《2024中国企业数据治理白皮书》(以下简称“白皮书”)。

白皮书中提到,企业数据建设是一项系统工程,需要解析业务现象背后的需求原因,针对性地实现落地,才能帮助企业善用数据资产,充分释放数据价值,进一步为实践提供指导。数据工程建设可分为咨询、落地、应用、管理四大环节。本文将围绕数据工程的咨询环节展开详细介绍。
咨询环节是企业进行数据建设闭环管理的第一步,其能力和优势体现在三方面:第一,以“业务数据地图”为抓手,翻译业务需求为数据化语言,为数据建设确立目标与路径;第二,咨询过程与成果线上化,协同用户快速完成需求确认与修正,避免信息偏差;第三,咨询成果无缝衔接至数据平台落地开发,大幅缩短数据建设周期,减少成本投入。
整体而言,咨询环节旨在帮助企业摸清数据现状、理顺数据在业务中的流向、找准数据与业务的关系,解决技术与业务脱节和咨询与落地“两张皮”难题,让数据应用少走弯路。

前文提到,咨询环节以“业务数据地图”为抓手,翻译业务需求为数据化语言。那么业务数据地图是什么?
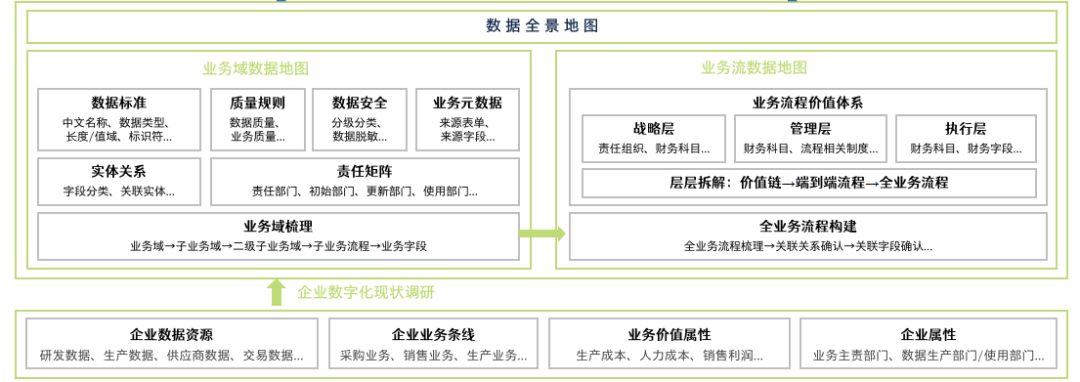
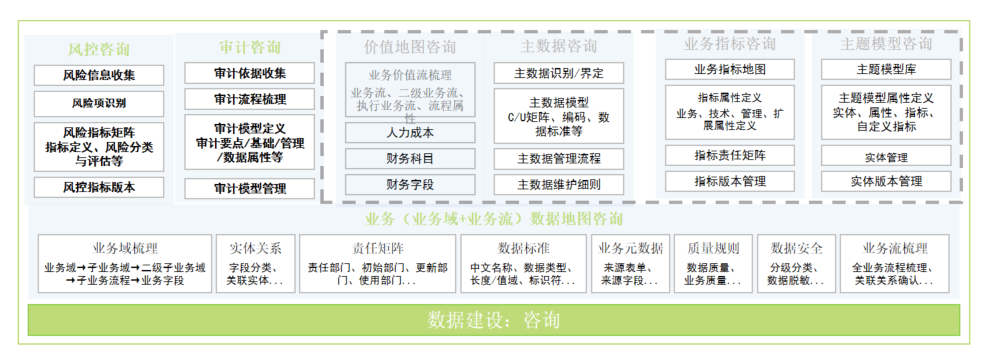
业务数据地图其实是以业务流程为出发点,构建业务流程、归属系统、责任部门、使用部门之间的业务关系地图,构建企业经营活动实体体系的一个核心调研工具。数据工程咨询以业务数据地图为工具,将企业的业务流程进行重新表述,即按照业务域梳理业务数据流,形成业务数据地图。
1
业务数据地图咨询
业务数据地图以业务为驱动,将分散在多个系统厂商在不同时期建设的信息化系统中的数据按照业务需求有序管理,为数据工程实施夯实数据基础。
业务数据地图咨询环节分为构建业务域数据地图模型和业务流数据地图模型两大环节。
- 业务域数据地图模型:从业务域梳理、实体关系、责任矩阵、数据标准、数据质量、数据安全、业务元数据维度构建业务数据地图模型。
- 业务流数据地图模型:基于业务域数据地图的基础上,梳理各业务流之间的关联关系,明确业务流程间的数据关联关系并建立连接,按照企业实际业务过程构建业务流程地图模型。
2
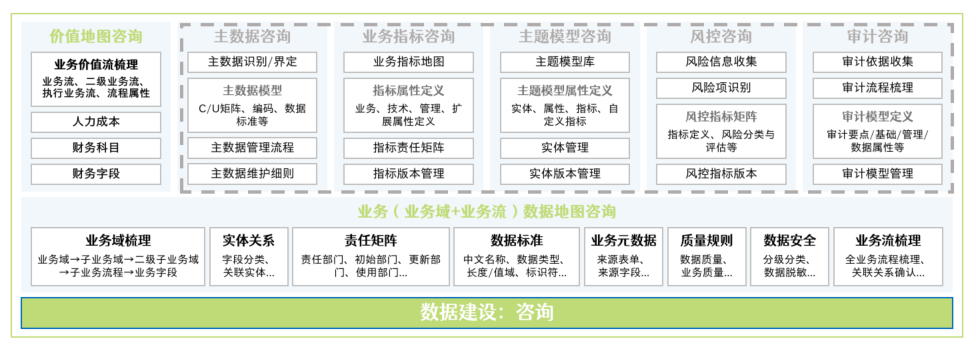
价值地图咨询
价值地图咨询,是基于业务数据地图,在业务流程中关联业务价值属性,形成企业价值地图模型的过程。
依据业务域数据地图模型和业务流数据地图模型构建价值地图模型,从业务价值流组成、流程属性、价值属性等维度进行业务价值流梳理。
咨询过程通过在线化、图形化形式或Excel形式来构建企业的核心业务流程价值体系,包括核心业务在战略层、管理层以及执行层面的各个流程环节以及每个环节的责任主体部门、是否为业财融合的关键流程、是否关联财务凭证以及每个环节是否有对应的流程制度支撑等信息。
3
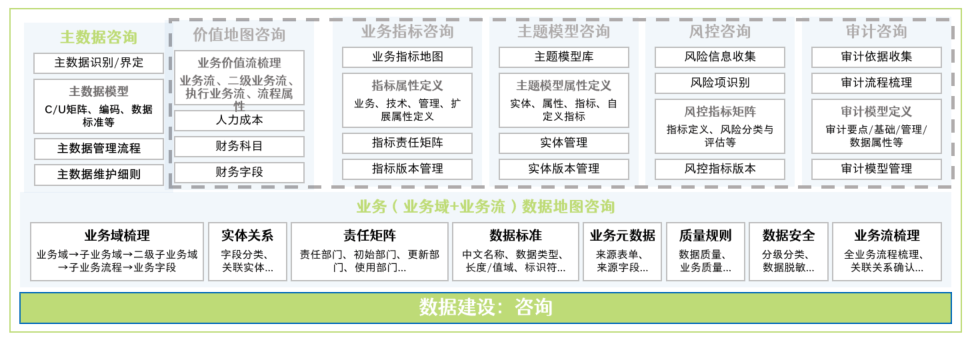
主数据咨询
主数据咨询是梳理企业各业务系统使用现状,从业务视角出发去识别内部数据流转问题的过程,对应咨询调研路径如下:
- 主数据UC矩阵形成:基于业务数据地图模型,自动识别核心主数据主题域及范围。梳理主数据在各系统中的产生和使用方式,形成主数据UC矩阵。
- 主数据模型自动识别:从业务视角出发自动识别主数据模型,包括字段、字段类型、编码规则、责任部门、来源系统、归属系统等,可一键同步为主模型。
- 主数据清洗方案制定:基于业务数据地图模型,快速制定主数据清洗方案,确保各业务系统主数据的准确性和唯一性。
- 主数据管理办法制定:基于业务数据地图模型,快速制定主数据管理办法和维护细则,从制度上为主数据建设保驾护航。
4
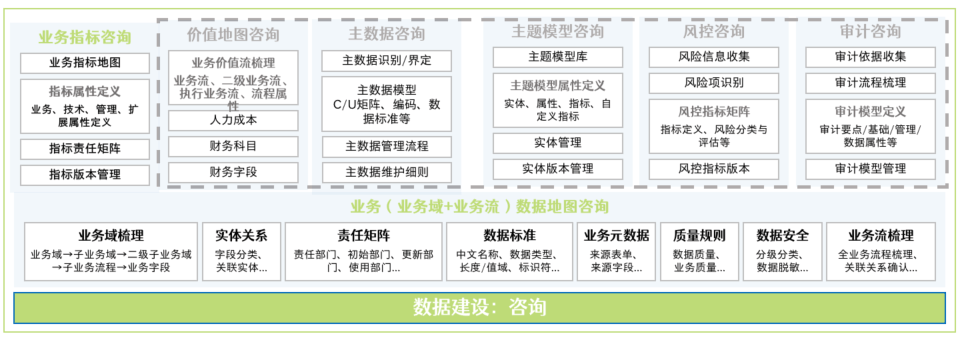
业务指标咨询
业务指标咨询是梳理指标业务、技术与管理属性,形成指标分类体系与责任矩阵等的咨询过程:
- 基于业务数据地图梳理的业务数据流程,识别各业务环节关注的指标项,形成业务指标地图。
- 梳理并定义各业务指标属性,包括业务属性、技术属性、管理属性以及扩展属性。
- 构建指标责任矩阵,包括指标提出部门/人、责任部门/人等,避免指标同名不同义、指标命名难理解等状况。
- 指标迭代版本留痕,记录指标变化,可以随时回退到上一版本,避免同一指标重复构建。
5
主题模型咨询
业务指标咨询是梳理指标业务、技术与管理属性,形成指标分类体系与责任矩阵等的咨询过程:
- 基于业务数据地图梳理的业务数据流程,识别各业务环节关注的指标项,形成业务指标地图。
- 梳理并定义各业务指标属性,包括业务属性、技术属性、管理属性以及扩展属性。
- 构建指标责任矩阵,包括指标提出部门/人、责任部门/人等,避免指标同名不同义、指标命名难理解等状况。
- 指标迭代版本留痕,记录指标变化,可以随时回退到上一版本,避免同一指标重复构建。
6
风控审计咨询
风控咨询是经过收集风险监管依据、识别潜在风险项、设计风控指标与预警规则等流程最终形成风险知识库的过程:
- 制定风控管理目标:确定重点风险管理域、风险管理预期等。
- 收集风险管理信息:基于风控目标收集风险管理信息,如政策法规/规章制度、历史风控报告等信息。
- 风险项识别与定义:基于风险管理要求识别风险指标,识别各环节风险点,定义风险逻辑。
- 风险项分类与界定:定义风险模型内容,设置阈值和预警规则等。
- 风险项分级与定责:定义不同类型风险模型的等级。
- 形成风险知识库:形成规章制度库、风险分类库、风控模型库等风险知识库。
审计咨询是基于企业审计工作现状,形成适配企业内审数字化转型要求的审计工作方案,进行审计需求调研和梳理的过程:
- 对齐审计项目目标:确定审计的方向和目标。
- 收集审计监管依据:基于审计目标收集审计依据,梳理企业当前内部审计工作参照的国家法律法规、企业内部运营管理制度。
- 审计项目要点识别:从审计目标出发,详细定义审计分类、审计内容、审计要点等。
- 审计分析模型定义:全方位定义审计模型属性,如业务属性、技术属性、管理属性等。
- 形成审计资源库:形成规章制度库、审计类别字典、疑点分类字典等审计资源库。
白皮书中强调,咨询是企业数据建设的前置工作,在咨询阶段,科学指导、分层梳理、工具利用、模式建立,是企业需要重点关注的事项。
通过业务数据地图咨询、价值地图咨询、主数据咨询、业务指标咨询、主题模型咨询、风控审计咨询共同组成数据工程-咨询环节,统筹规划、统一指挥、统一协调,且咨询成果无缝化与后续的落地进行衔接,可以保障企业数据治理项目顺利推进,缩短数据工程落地周期,大大减少企业投入成本。
这篇关于艾瑞白皮书解读(四)丨深度解析企业数据治理第一步:咨询环节的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




